Techniques to Detect AI Generated Content
Discover effective techniques to detect AI-generated content and ensure authenticity in your writing.

I. Introduction
The rise of artificial intelligence (AI) has ushered in a new era of content creation. AI-generated content (AIGC), encompassing text, images, audio, and video, is rapidly proliferating across various sectors (Cao et al., 2023). This surge in AI-driven content production has profound implications, impacting fields from academia and journalism to marketing and entertainment. In academia, the ease and speed of AI content generation pose significant challenges to traditional assessments and research practices. The increasing prevalence of AI-generated content necessitates robust detection methods to maintain academic integrity. The ability to easily generate high-quality essays, research papers, or even code raises serious concerns about plagiarism and the fairness of academic evaluations. Ensuring that assessment accurately reflects a student's original work is paramount, highlighting the critical need for effective AI content detection tools. However, detecting AI-generated content is a formidable challenge. AI models are constantly evolving, becoming more sophisticated and adept at mimicking human writing styles. This creates a dynamic “arms race,” where AI generators become more advanced, necessitating the continuous development and refinement of detection techniques. The ability to reliably distinguish between human-generated and AI-generated content will require a multifaceted approach, incorporating a range of methodologies and a deep understanding of the underlying mechanisms of AI text generation.
II. Understanding AI-Generated Content
What is AI-generated content?
AI-generated content (AIGC) refers to any text, image, audio, or video created by artificial intelligence algorithms, as opposed to being produced by a human. While both human and AI-generated content aim to communicate information or create artistic expression, key differences exist. Human writing typically reflects individual experiences, perspectives, and unique thought processes, often exhibiting inconsistencies and idiosyncrasies. It involves a complex interplay of cognitive functions, including planning, memory, and emotion, resulting in a nuanced and often unpredictable output. In contrast, AIGC, while capable of mimicking human writing styles, relies on statistical patterns and probabilities learned from vast datasets. This leads to a potentially more uniform and predictable style, often lacking the genuine originality and subjective depth found in human writing. AIGC might be grammatically correct and semantically coherent, but it may lack the subtle nuances, unexpected turns of phrase, and personal voice that characterize human creativity.
Types of AI models
Large language models (LLMs) like GPT (Generative Pre-trained Transformer) and LLaMA (Large Language Model Meta AI) are the primary engines driving AIGC. These models are trained on massive datasets of text and code, learning to predict the probability of the next word in a sequence given the preceding words. This predictive ability allows them to generate human-like text by statistically modeling the patterns and relationships within the training data. The training data encompasses a wide range of sources, including books, articles, websites, and code repositories. By analyzing these diverse sources, LLMs acquire a broad understanding of language, allowing them to generate text on various topics and in different styles. They mimic human writing by statistically predicting the most likely sequence of words based on the input and their learned patterns, effectively creating text that appears coherent and fluent, although potentially lacking originality or genuine understanding.
Potential use cases (legitimate and illegitimate)
AI-generated content offers legitimate uses across diverse fields. In academia, it can assist with tasks like summarizing research papers, generating outlines, and improving writing style. In creative writing, it can help overcome writer's block or explore different stylistic approaches. However, the potential for illegitimate use, particularly in academia, is significant. Students might use LLMs to generate entire essays or research papers, presenting them as their original work, which constitutes plagiarism and undermines the principles of academic integrity. The ease of generating high-quality AIGC raises concerns about the fairness of academic evaluations, as it becomes difficult to distinguish between genuine student work and AI-generated submissions. The ethical implications extend beyond plagiarism to broader questions regarding authorship, originality, and the authenticity of academic research. The misuse of AIGC in academia threatens the validity of assessment, undermines the learning process, and erodes trust in academic credentials.
III. Techniques for Detecting AI-Generated Content
A. Statistical and Probabilistic Methods
These methods leverage the statistical properties of text to differentiate between human-written and AI-generated content. AI, trained on massive datasets, tends to exhibit certain predictable patterns in its output. One initial technique was GLTR which provides a statistical detection and visualization of the generated text (Gehrmann et al., 2019).
-
Perplexity & Burstiness: Perplexity measures how well a probability distribution predicts a sample. In the context of AI-generated text, lower perplexity indicates higher predictability. AI tends to generate text with lower perplexity than humans. Burstiness examines the variations in sentence complexity and length. Human writing exhibits more burstiness, alternating between short and complex sentences, while AI-generated text often maintains a more uniform style.
-
Cross-entropy & Kullback-Leibler (KL) Divergence: These methods compare the probability distributions of human-written and AI-generated text. Cross entropy measures the average number of bits needed to encode text from one distribution using another. KL Divergence quantifies the difference between two probability distributions. A larger KL divergence suggests a greater difference between the writing styles, potentially indicating AI authorship.
-
N-gram analysis: This technique analyzes the frequency of sequences of n words (N-grams) in a text. AI, due to its training data and probabilistic nature, may overuse certain phrases or exhibit distinct N-gram frequencies compared to human writing. By comparing N-gram frequencies between suspected AI text and a corpus of human-written text, we can identify potential discrepancies and flags for AI generation.
-
Fano Factor: The Fano Factor measures the variability or "burstiness" of token generation. It's calculated as the variance of the number of tokens generated in a given time window divided by the mean. A higher Fano Factor suggests more variability, which is characteristic of human writing. AI-generated text often exhibits a lower Fano Factor, indicating a more consistent and less varied output in terms of token generation.
B. Linguistic and Stylistic Features
While statistical methods offer a quantitative approach, analyzing linguistic and stylistic features provides a qualitative lens for detecting AI-generated content. These features delve into the nuances of language use, often revealing subtle differences between human and AI-authored text (Opara, 2024).
- Sentence structure and syntax analysis: Human writing exhibits greater variability in sentence structure and complexity. We naturally mix short, declarative sentences with longer, more complex ones. AI, while improving, tends towards a more uniform and predictable sentence structure, often favoring shorter, simpler sentences. Analyzing sentence length distribution, the presence of complex clauses, and syntactic patterns can help distinguish between human and AI-generated text.
- Readability scores (Flesch-Kincaid, etc.): Readability formulas, like Flesch-Kincaid, assess text complexity based on factors like sentence length and syllable count. AI-generated text often scores highly on readability scales, appearing deceptively simple and clear. While this can be a helpful indicator, relying solely on readability scores is insufficient, as simple human-written text can also achieve high scores. Furthermore, advanced AI models are increasingly capable of mimicking more complex sentence structures, potentially rendering readability scores less effective.
- Lexical richness and diversity: This refers to the range and variety of vocabulary used in a text. Humans tend to use a broader vocabulary and incorporate synonyms and related terms naturally. AI, while having access to vast lexicons, may exhibit less lexical diversity, potentially overusing certain words or phrases and lacking the nuanced vocabulary choices a human writer would employ. Analyzing the type-token ratio (unique words divided by total words) and the use of sophisticated vocabulary can reveal these differences.
- Semantic analysis and coherence: A key aspect of human writing is the logical flow of ideas and the maintenance of coherence throughout the text. AI sometimes struggles with maintaining consistent meaning and logical connections between sentences and paragraphs. Analyzing semantic relationships between sentences, identifying logical fallacies, and assessing the overall coherence of the argument can expose weaknesses in AI-generated text.
Pronoun resolution and coreference: Accurately using and resolving pronouns (he, she, it, they, etc.) to their corresponding nouns (referents) is a complex linguistic task. AI often makes mistakes in pronoun resolution, leading to ambiguity or incorrect referencing. Similarly, coreference, which involves identifying all expressions that refer to the same entity in a text, is another area where AI can falter. Examining instances of unclear or incorrect pronoun usage and coreference errors can be a telltale sign of AI authorship.
Sentiment analysis and emotional consistency: While AI can generate text with a specified emotional tone, maintaining consistent sentiment and emotional depth throughout a longer piece can be challenging. Humans naturally express a range of emotions and nuances in their writing, whereas AI-generated text might exhibit abrupt shifts in sentiment or lack the subtle emotional cues present in human-written content. Analyzing the emotional arc of a text and identifying inconsistencies in sentiment can be a valuable detection technique.
C. Machine Learning-Based Detectors
Machine learning offers powerful tools for detecting AI-generated content, leveraging algorithms trained on vast datasets to identify subtle patterns indicative of synthetic text. These methods broadly fall into supervised and unsupervised learning approaches.
Supervised learning approaches involve training a classifier on a labeled dataset containing both human-written and AI-generated text examples. The classifier learns to distinguish between the two categories based on specific features extracted from the text. These features can range from simple statistical measures (like word frequency and sentence length) to more complex representations derived from pre-trained language models like BERT. BERT embeddings, for example, capture semantic information and contextual relationships within the text, allowing the classifier to discern nuanced differences between human and AI writing styles.
Transformer-based detectors leverage the power of transformer models, like RoBERTa and GPT, which have demonstrated exceptional performance in various natural language processing tasks. These detectors can be fine-tuned on labeled datasets of human and AI-generated text, similar to supervised learning approaches. Fine-tuning adapts the pre-trained model to the specific task of AI detection, enabling it to learn subtle distinctions between the two writing styles.
IV. Deep Dive into Academic-Level AI Detection
The rise of AI-generated content poses a significant challenge to academic integrity. Let’s explore how institutions are adapting to this challenge by integrating AI detection into their frameworks and developing advanced techniques to enhance accuracy and combat evasion tactics.
Academic Papers and Plagiarism
The use of AI writing tools to generate academic papers raises serious concerns about plagiarism. Traditional plagiarism detection software primarily focuses on identifying copied text from existing sources. However, AI-generated content is original in the sense that it isn't directly copied, making it more difficult to detect with traditional methods. Companies like Desklib have recognized this challenge and are actively integrating AI detection capabilities into their platforms. Institutions are also exploring how to incorporate these detectors into their academic integrity policies and procedures. This includes educating students about the ethical implications of using AI writing tools for academic work and establishing clear guidelines on permissible and impermissible uses.
Text Chunking and Overlap for Contextual AI Detection
Detecting AI-generated content in longer academic papers presents unique challenges. Analyzing a lengthy document as a single unit can dilute the subtle indicators of AI authorship. Text chunking, the process of dividing a document into smaller segments, offers a more granular approach. By analyzing these smaller chunks, detectors can pick up on localized patterns and inconsistencies that might be missed in a holistic analysis. Furthermore, incorporating context overlap between chunks enhances accuracy. This overlap ensures that the analysis considers the surrounding text, providing crucial contextual information and preventing the misclassification of short, potentially ambiguous passages. Desklib’s AI Content Detector uses this technique to detect AI-generated content with a very high accuracy.
Addressing Adversarial Attacks
As AI detection methods improve, so too do techniques designed to circumvent them. Adversarial attacks involve subtly manipulating AI-generated text to make it appear more human-like and evade detection. These manipulations can include inserting typos, altering sentence structures, or strategically replacing words with synonyms leading to huge drops in detection accuracies of many AI Detectors (Perkins et al., 2024). Researchers are developing more robust detection algorithms that are less susceptible to manipulation. These include methods that focus on deeper semantic analysis and stylistic features that are harder to mimic artificially. Furthermore, incorporating techniques like watermarking or embedding subtle, invisible markers in AI-generated text could provide a more definitive way to identify its origin, making it significantly harder to bypass detection through adversarial attacks. This ongoing “arms race” between generation and detection underscores the need for continuous research and development in this field.
V. Tools and Platforms for AI Detection
While AI Detectors are not completely reliable, efforts were made to create tools and platforms to address the growing need for AI-generated content detection. Here are a few prominent examples:
OpenAI's GPT-3/4 Detectors: OpenAI released a fine-tuned version RoBERTa based classifier for GPT-2 output detection and found ~95% detection rate (Solaiman et al., 2019). However they discontinued it due to its low accuracy.
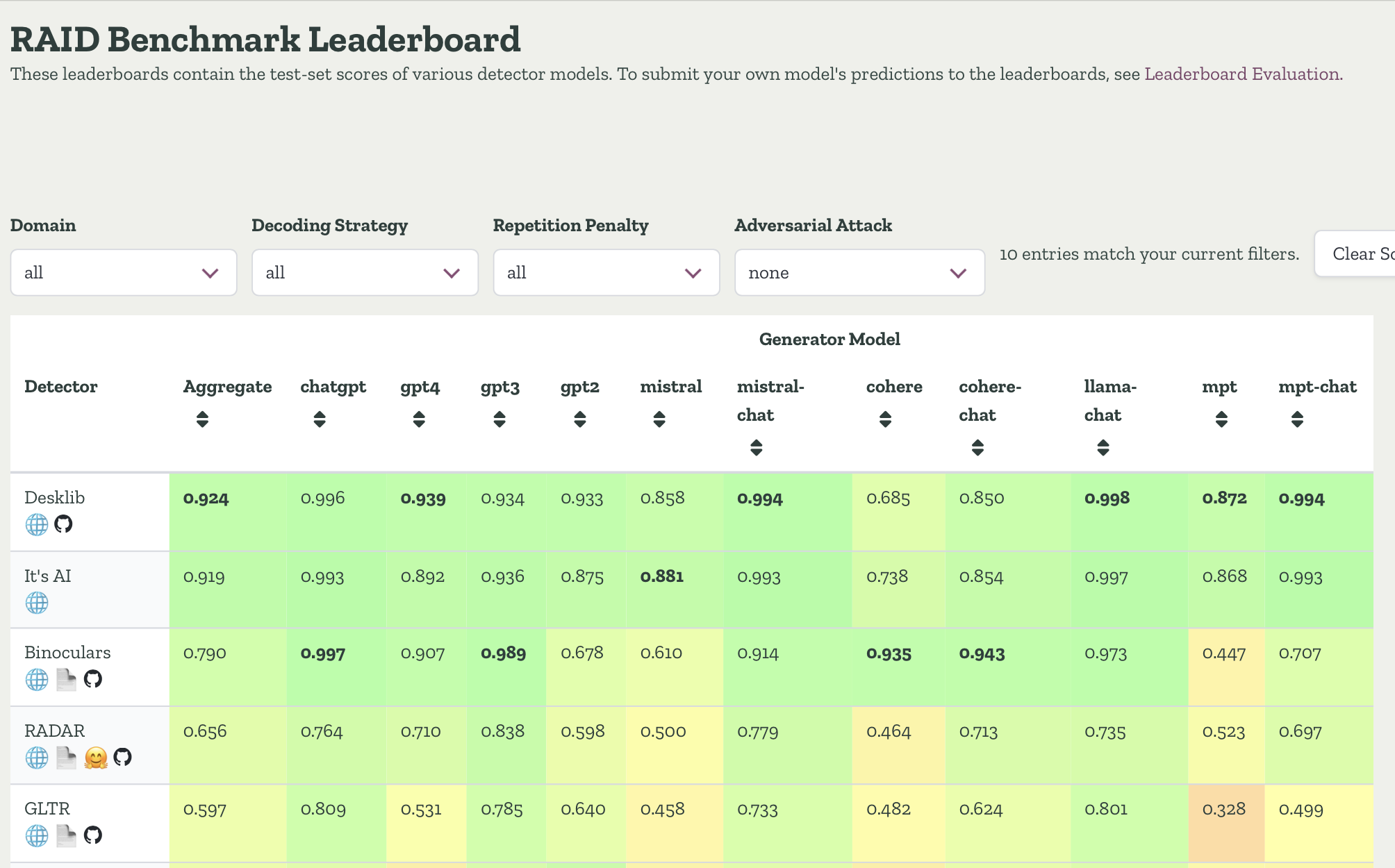 RAID Benchmark: Desklib at the top with 92.4% overall accuracy
RAID Benchmark: Desklib at the top with 92.4% overall accuracy
Desklib AI Detector: Desklib offers state-of-the-art AI content detector designed for detecting lengthy academic content with highest accuracy. According to RAID Benchmark which is largest and most challenging benchmark dataset for machine-generated text detectors (Dugan et al., 2024), it is the most accurate AI Detector. It currently ranks no 1 on the leaderboard as the most accurate AI Detector.
Turnitin's AI Detection Module: Turnitin has integrated AI writing detection capabilities into its platform providing educators with a similarity score indicating the likelihood of AI involvement, allowing them to investigate further and engage in conversations with students.
VI. Technical Challenges and Limitations
While AI content detection tools offer a promising solution to the challenges posed by AI-generated text, they are not without their limitations. Understanding these limitations is crucial for responsible implementation and interpretation of results.
- False Positives and Negatives: A significant challenge lies in the risk of false positives, where human-written text is mistakenly flagged as AI-generated. This can have serious consequences, particularly in academic settings, where students might be unfairly accused of using AI. Conversely, false negatives, where AI-generated text is misidentified as human-written, undermine the efficacy of detection tools (Abdali et al., 2024). These errors can arise from various factors, including the inherent probabilistic nature of language models and the diversity of human writing styles. A text written by a non-native speaker, for instance, might exhibit unusual sentence structures or vocabulary choices that trigger a false positive. A study based on evaluating 16 publicly available AI Detectors states that many detectors are ineffective at distinguishing between GPT-4 papers and those written by undergraduate students (Walters, 2023).
- Adversarial Attacks: The dynamic between AI generation and detection has an "arms race" quality. As detection techniques improve, so do methods for circumventing them. Adversarial attacks involve subtly manipulating AI-generated text to evade detection algorithms. These manipulations might include inserting typos, altering punctuation, or slightly rephrasing sentences. Such attacks pose a significant challenge to the long-term effectiveness of current detection tools (Perkins et al., 2024).
- Rapid Advancement of AI Models: The field of AI is rapidly evolving, with new and more sophisticated language models emerging constantly. This rapid advancement poses a continuous challenge for detection techniques. Detectors trained on older models may be less effective against newer, more sophisticated ones. Consequently, detection tools need to be constantly updated and adapted to keep pace with the evolving landscape of AI generation. This requires ongoing research and development, as well as access to the latest AI models for training and evaluation.
- Ethical Considerations: The use of AI detection tools raises several ethical considerations. Balancing the need for academic integrity with academic freedom and creative expression is paramount. Over-reliance on detection tools could stifle creativity and penalize students who write in unconventional styles. Furthermore, there's the potential for bias in detection algorithms. If training data primarily consists of text from a specific demographic, the detector may be more prone to misclassifying text from underrepresented groups. Transparency in the development and deployment of these tools is essential to mitigate potential biases and ensure fair and equitable assessment. The ethical implications of AI detection require careful consideration and ongoing discussion to ensure responsible use.
VII. Future of AI Detection in Academia: An Ongoing Arms Race
The future of AI detection in academia is characterized by a constant "arms race" between increasingly sophisticated AI writing tools and the development of ever[1]more advanced detection methods. As generative models become more adept at mimicking human language, detection techniques must evolve to keep pace. This dynamic creates a continuous cycle of innovation and adaptation, with neither side holding a permanent advantage.
This ongoing battle necessitates exploration of next-generation techniques. One promising avenue lies in leveraging advancements in natural language understanding (NLU). Moving beyond surface-level statistical analysis, NLU-based detectors can analyze the deeper meaning and context of text, potentially identifying subtle inconsistencies and logical flaws that current methods might miss. Furthermore, multi-modal detection, which incorporates other data sources like audio and video alongside text, could prove valuable in identifying AI-generated content presented in multimedia formats.
Another significant area of research focuses on watermarking and embedding. This approach involves subtly altering the generated text in a way that is imperceptible to human readers but detectable by algorithms. Think of it as a digital fingerprint embedded within the text itself. This could provide a reliable and robust method for identifying AI-generated content, even as generation models become more sophisticated (Kirchenbauer et al., 2024). Various techniques are being explored, including adding imperceptible perturbations to word frequencies, embedding specific syntactic structures, or even manipulating the underlying statistical properties of the text. However, the challenge lies in creating watermarks that are both robust to adversarial attacks and do not compromise the quality and readability of the generated text.
The future of AI detection relies on continuous research and development, adapting to the evolving landscape of AI-generated content. The development and implementation of these advanced techniques will play a crucial role in maintaining academic integrity and ensuring fair evaluation in the age of AI.
VIII. Conclusion
The proliferation of AI-generated content presents both exciting opportunities and significant challenges, particularly within academia. As we've explored, various techniques, from statistical analysis and linguistic feature examination to sophisticated machine learning models, offer promising avenues for detecting AI-generated text. However, these methods are not without limitations. False positives and negatives remain a concern, and the rapid evolution of AI models necessitates continuous adaptation of detection strategies. Furthermore, adversarial attacks designed to bypass detection algorithms pose an ongoing challenge.
The "arms race" between AI generation and detection underscores the critical importance of ongoing research and development. Exploring next-generation techniques like natural language understanding, multi-modal detection, and robust watermarking methods holds the key to more accurate and reliable detection. Moreover, the development of open benchmarks and datasets, like the RAID Benchmark, are crucial for evaluating and comparing different detection methods and driving progress in the field.
Addressing the challenges of AI-generated content requires a collaborative approach. Open communication and cooperation between researchers, educators, technology developers, and policymakers are essential. We must also carefully consider the ethical implications of AI detection, ensuring that these tools are used responsibly and equitably. Balancing the need for academic integrity with academic freedom and creative expression is paramount. As we move forward, a thoughtful and collaborative approach, informed by ethical considerations, will be crucial in shaping the future of AI detection and ensuring its positive contribution to education and research.
References and Further Reading
Abdali, S., Anarfi, R., Barberan, C. J., & He, J. (2024). Decoding the ai pen: Techniques and challenges in detecting ai-generated text. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 6428– 6436. https://doi.org/10.1145/3637528.3671463
Cao, Y., Li, S., Liu, Y., Yan, Z., Dai, Y., Yu, P. S., & Sun, L. (2023). A comprehensive survey of ai-generated content (Aigc): A history of generative ai from gan to chatgpt (arXiv:2303.04226). arXiv. https://doi.org/10.48550/arXiv.2303.04226
Dugan, L., Hwang, A., Trhlik, F., Ludan, J. M., Zhu, A., Xu, H., Ippolito, D., & Callison-Burch, C. (2024). Raid: A shared benchmark for robust evaluation of machine-generated text detectors (arXiv:2405.07940). arXiv. https://doi.org/10.48550/arXiv.2405.07940
Gehrmann, S., Strobelt, H., & Rush, A. M. (2019). Gltr: Statistical detection and visualization of generated text(arXiv:1906.04043). arXiv. https://doi.org/10.48550/arXiv.1906.04043
Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., & Goldstein, T. (2024). A watermark for large language models(arXiv:2301.10226). arXiv. https://doi.org/10.48550/arXiv.2301.10226
Opara, C. (2024). Styloai: Distinguishing ai-generated content with stylometric analysis (arXiv:2405.10129; Version 1). arXiv. https://doi.org/10.48550/arXiv.2405.10129
Perkins, M., Roe, J., Vu, B. H., Postma, D., Hickerson, D., McGaughran, J., & Khuat, H. Q. (2024). Genai detection tools, adversarial techniques and implications for inclusivity in higher education. International Journal of Educational Technology in Higher Education, 21(1), 53. https://doi.org/10.1186/s41239-024-00487-w
Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., McCain, M., Newhouse, A., Blazakis, J., McGuffie, K., & Wang, J. (2019). Release strategies and the social impacts of language models (arXiv:1908.09203). arXiv. https://doi.org/10.48550/arXiv.1908.09203
Walters, W. H. (2023). The effectiveness of software designed to detect ai generated writing: A comparison of 16 ai text detectors. Open Information Science, 7(1). https://doi.org/10.1515/opis-2022-0158
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.