HA1011 Applied Quantitative Methods: Business Statistics Assignment
VerifiedAdded on 2023/04/04
|10
|1073
|193
Homework Assignment
AI Summary
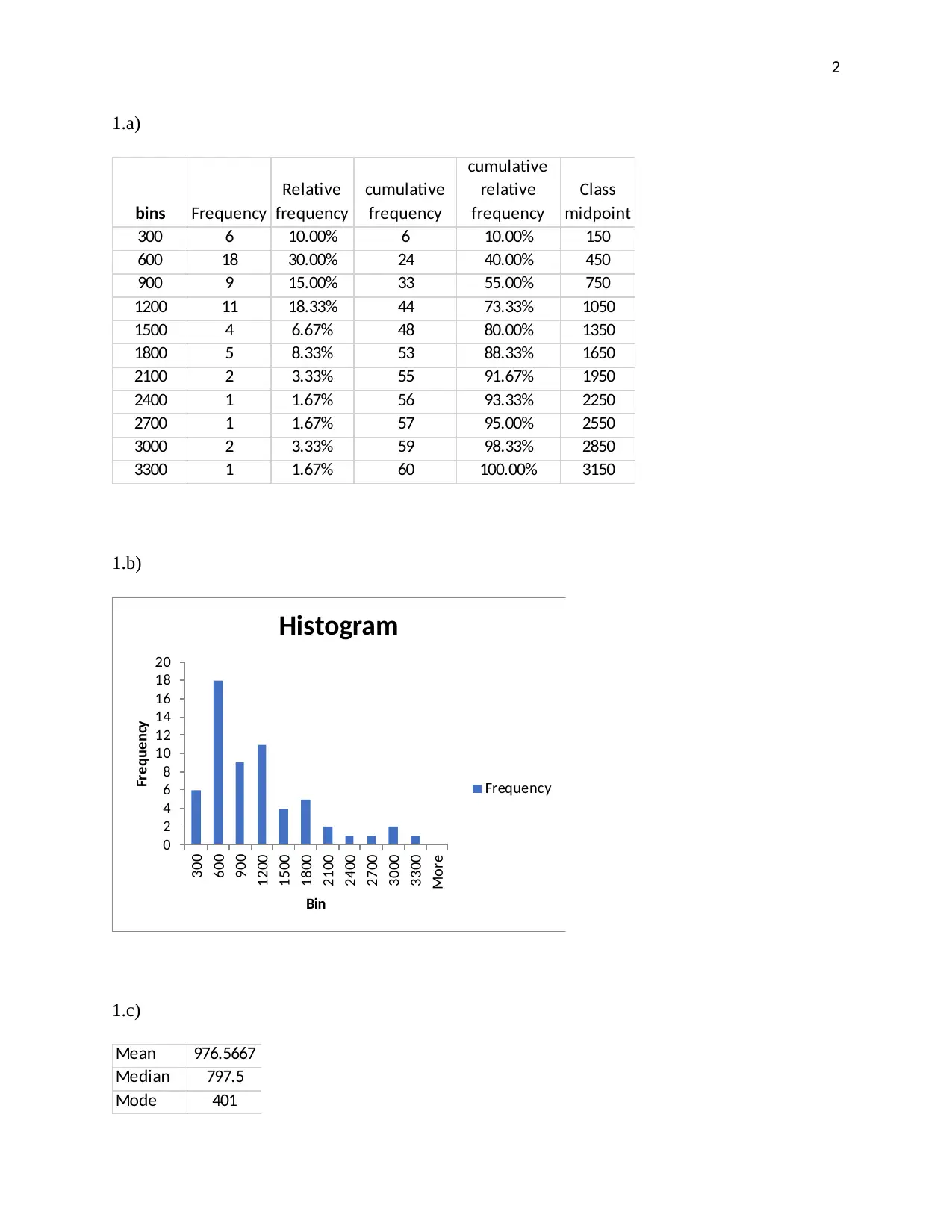
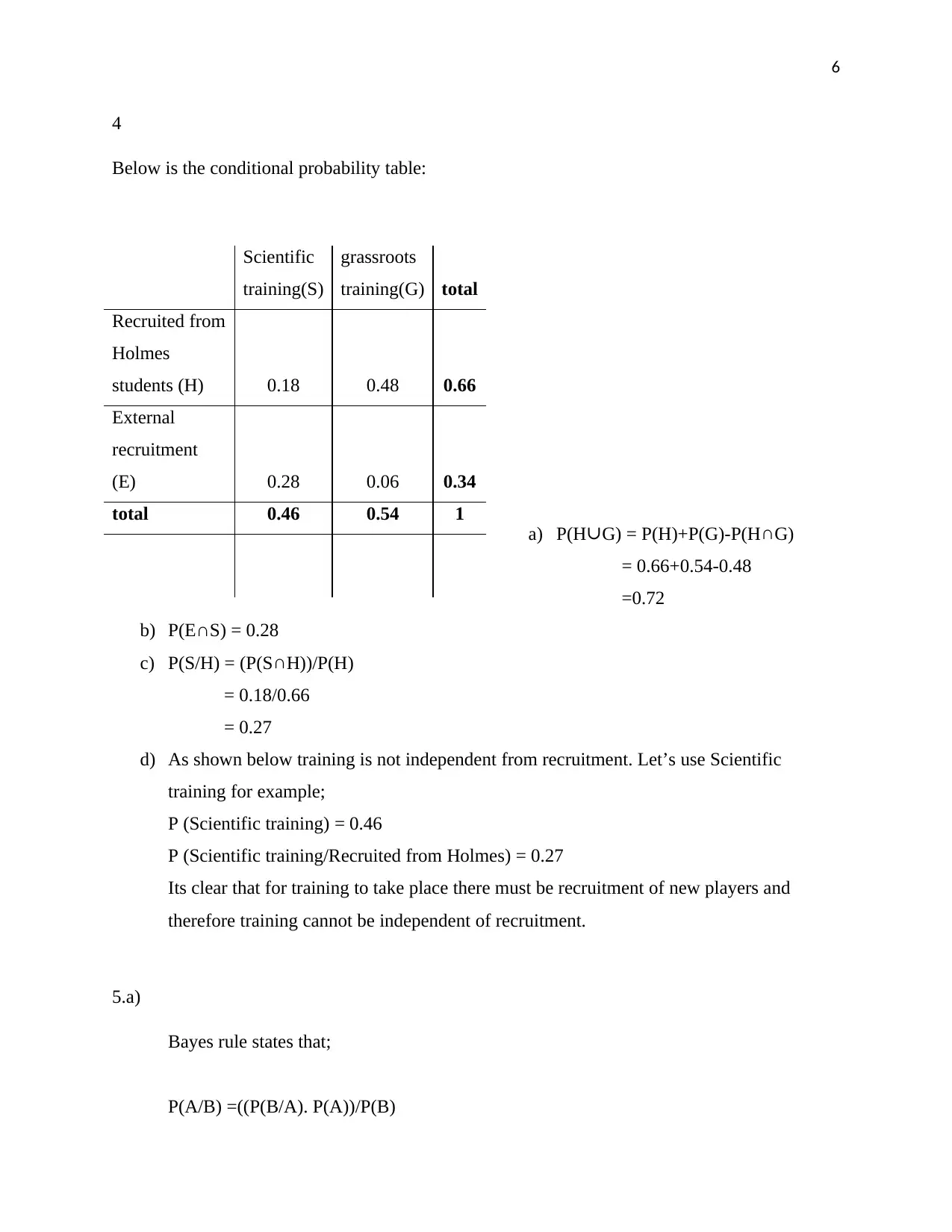
This assignment solution covers various statistical concepts applied to business scenarios. It includes creating frequency distributions, calculating mean, median, and mode, and interpreting standard deviation and interquartile range. The solution also addresses correlation analysis between weekly attendance and chocolate bar sales, constructing a regression equation, and applying conditional probability and Bayes' rule. Furthermore, it involves binomial and Poisson probability calculations, along with normal distribution problems related to sales projections. The assignment concludes with hypothesis testing and probability calculations related to investor commitment. Desklib offers a wealth of similar solved assignments and study resources for students.








1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.