Data Analysis Report: Ranking Toughest Sports - Data Analysis
VerifiedAdded on 2022/08/23
|11
|1193
|19
Report
AI Summary
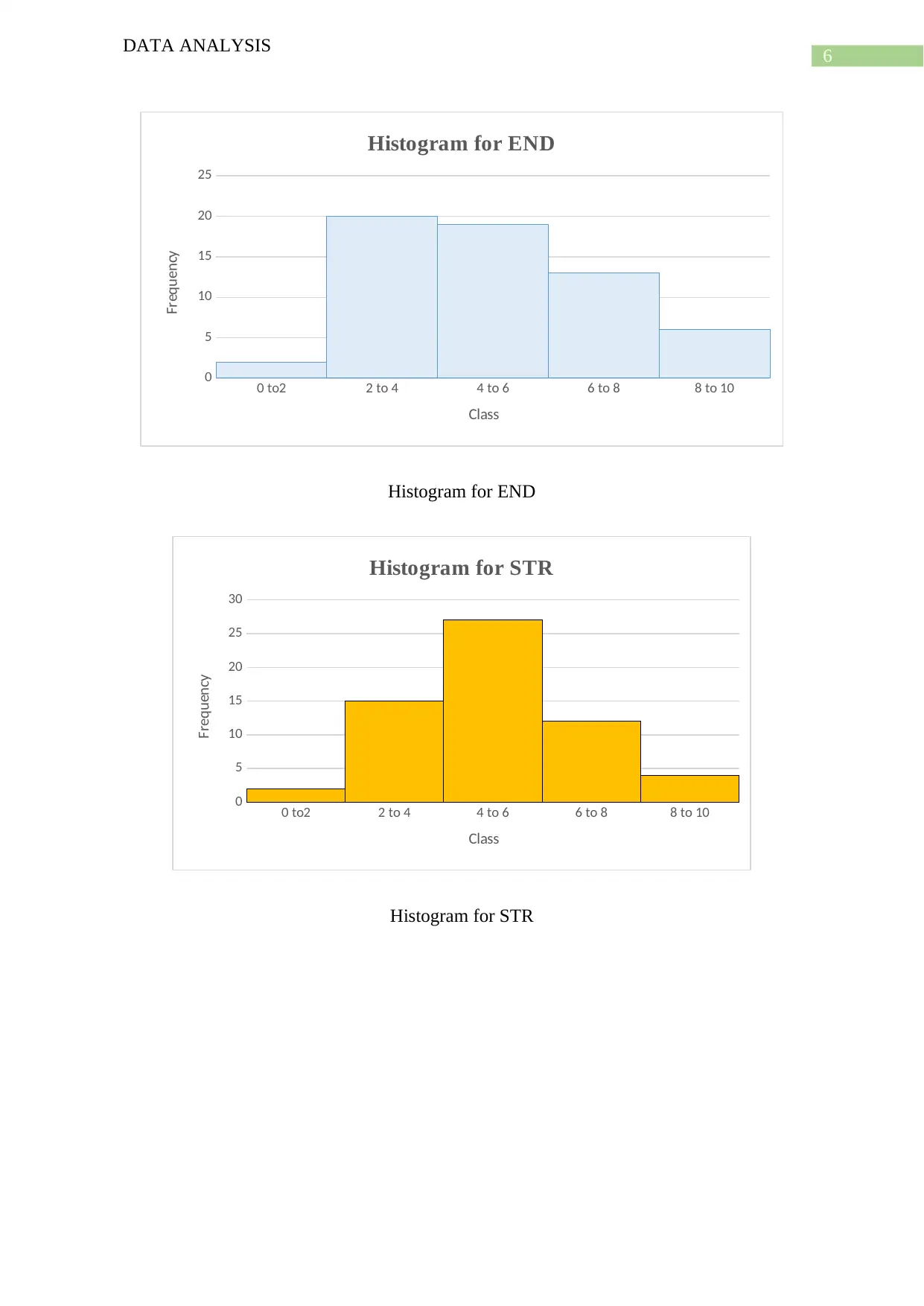
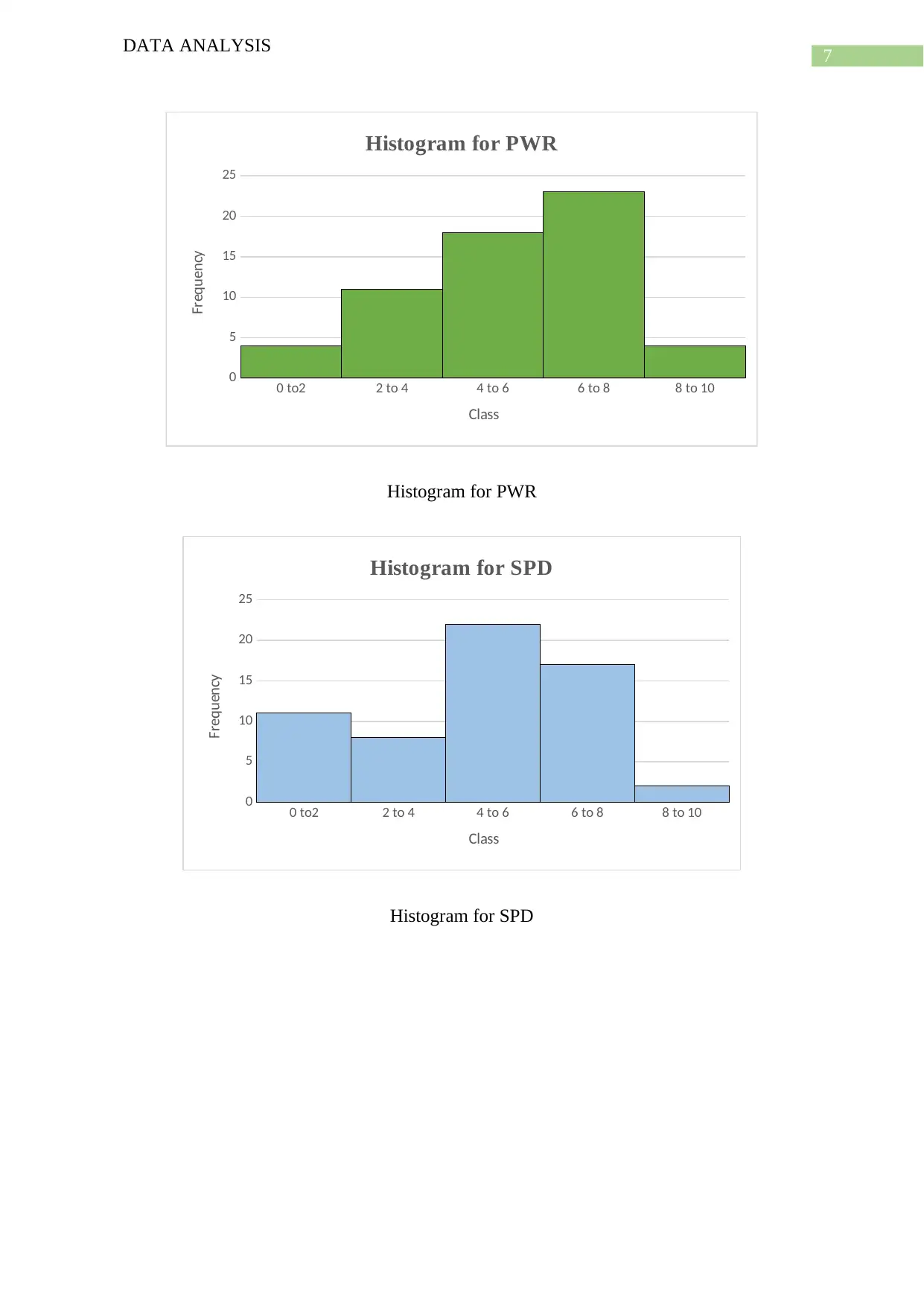
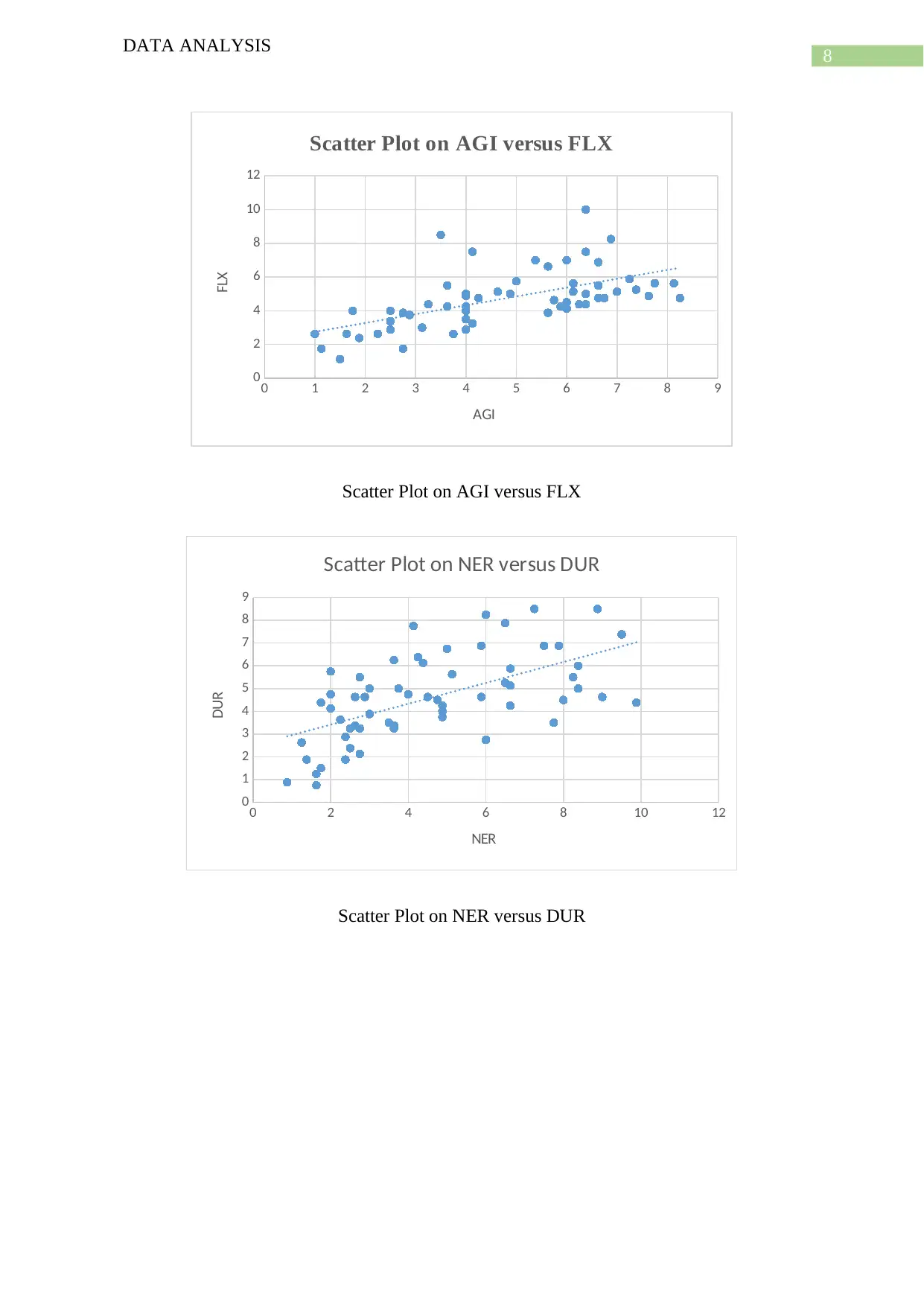
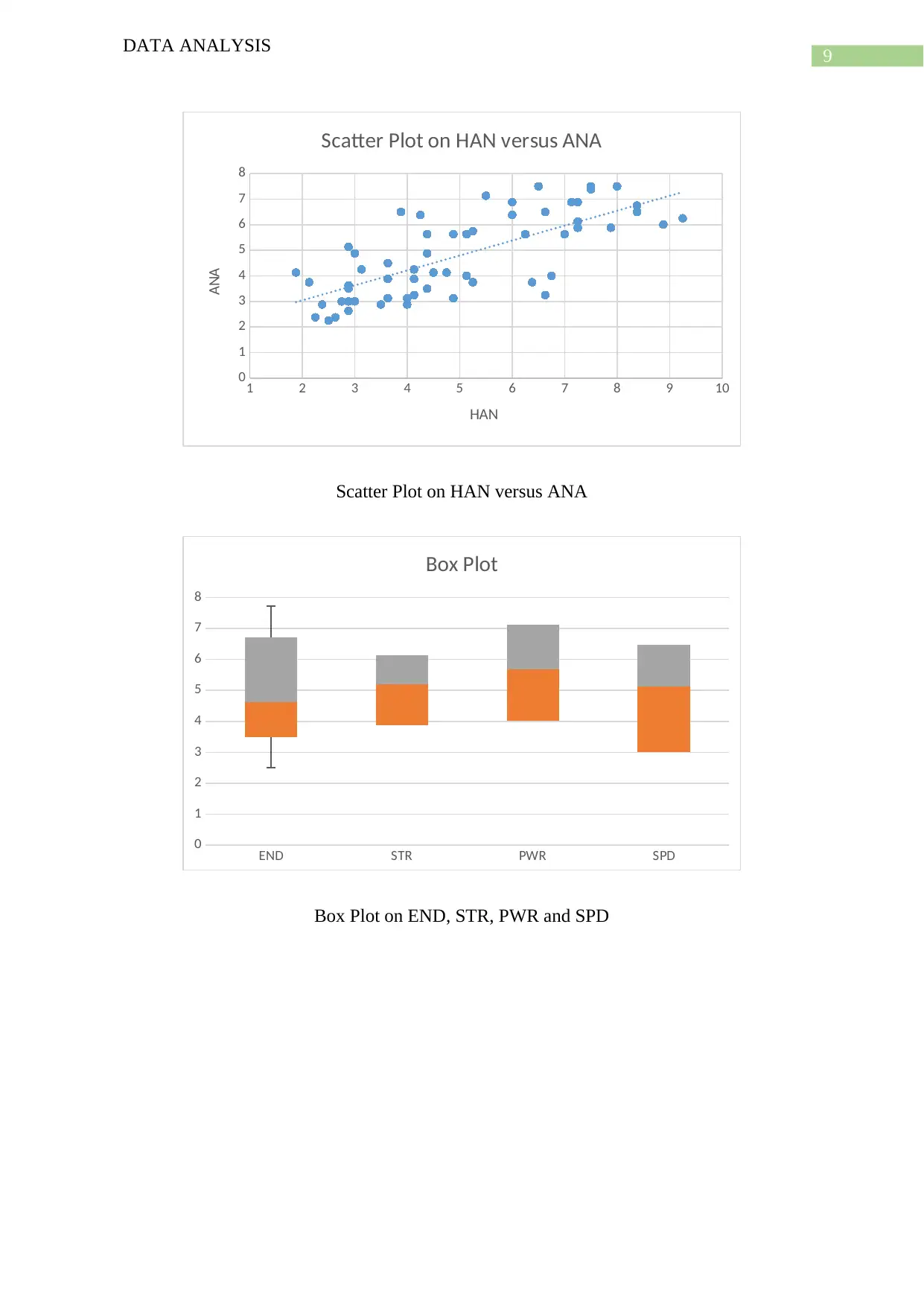
This report presents a comprehensive data analysis of a project ranking the toughest sports based on various skill categories. The analysis begins with a data cleaning procedure to address inaccurate or corrupt data, followed by an examination of data consistency and the use of a data dictionary. The report then delves into descriptive statistics for ten quantitative variables across sixty observations, including mean, median, mode, variance, standard deviation, and range. Histograms, scatter plots, and box plots are used to visualize the data and identify relationships between variables, such as the positive correlation between AGI and FLX. The report also discusses the skewness of different variables. The analysis employs multiple regression analysis to determine the degree of difficulty for each sport. The project aims to rank sports from 1st to 60th based on their demands on athletic skills, providing a detailed methodology and results, along with relevant references.







1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.