Complete Solution to Advanced Algorithm Analysis Assignment CP5602
VerifiedAdded on 2023/06/04
|9
|2086
|492
Homework Assignment
AI Summary
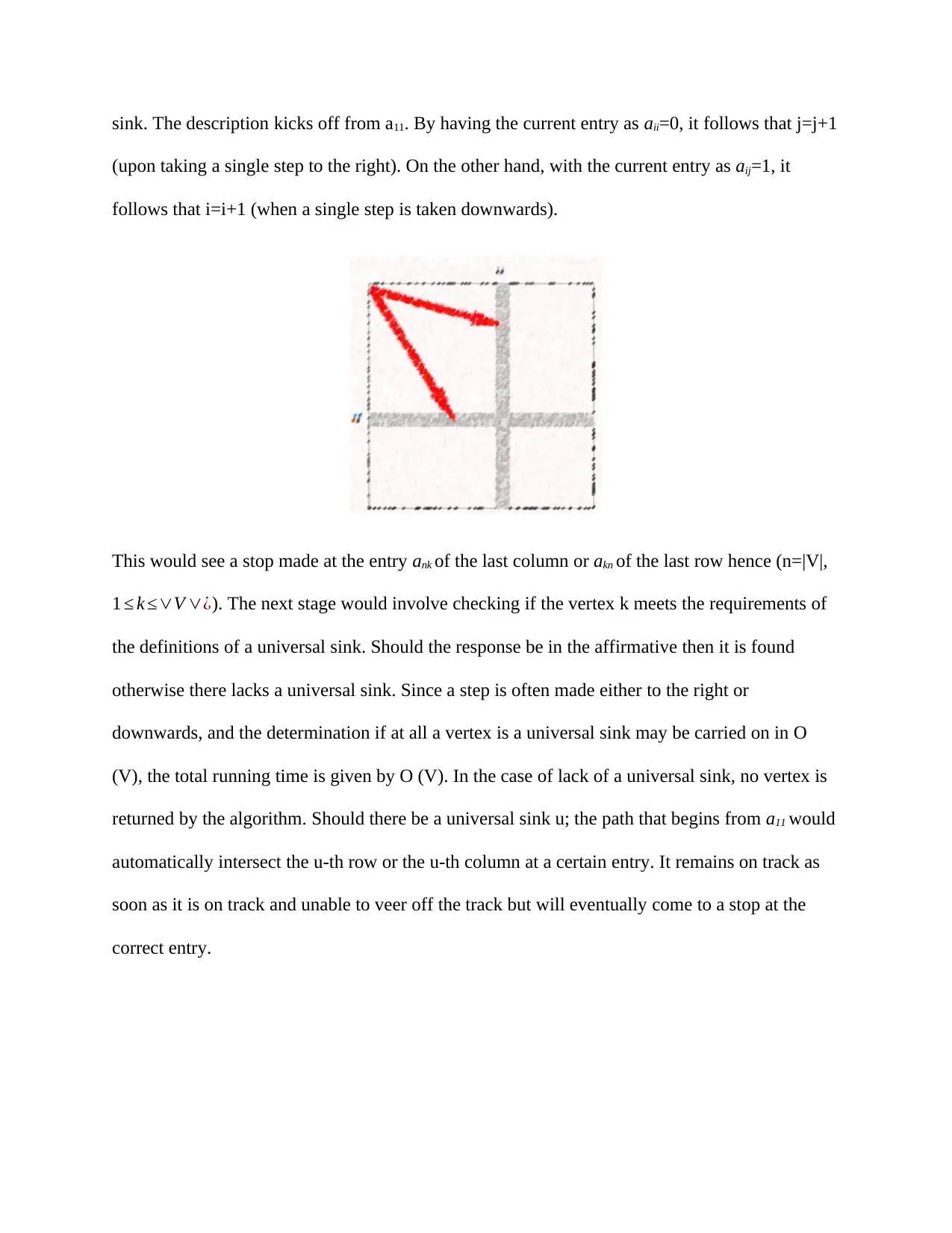
This assignment solution covers several key aspects of advanced algorithm analysis. It includes proving a property of trees with internal nodes having three children, developing an algorithm to find the k-th smallest key in two sorted arrays, analyzing a modified merge sort algorithm, solving recurrence relations using the Master Theorem and recurrence trees, and devising an algorithm to identify a universal sink in a graph represented by an adjacency matrix. The solutions provide detailed explanations and complexity analysis for each problem, with references to relevant research.








1 out of 9
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.