Data Mining Project: WEKA Analysis of Breast-cancer, Diabetes, Iris
VerifiedAdded on 2022/09/28
|13
|1214
|16
Project
AI Summary
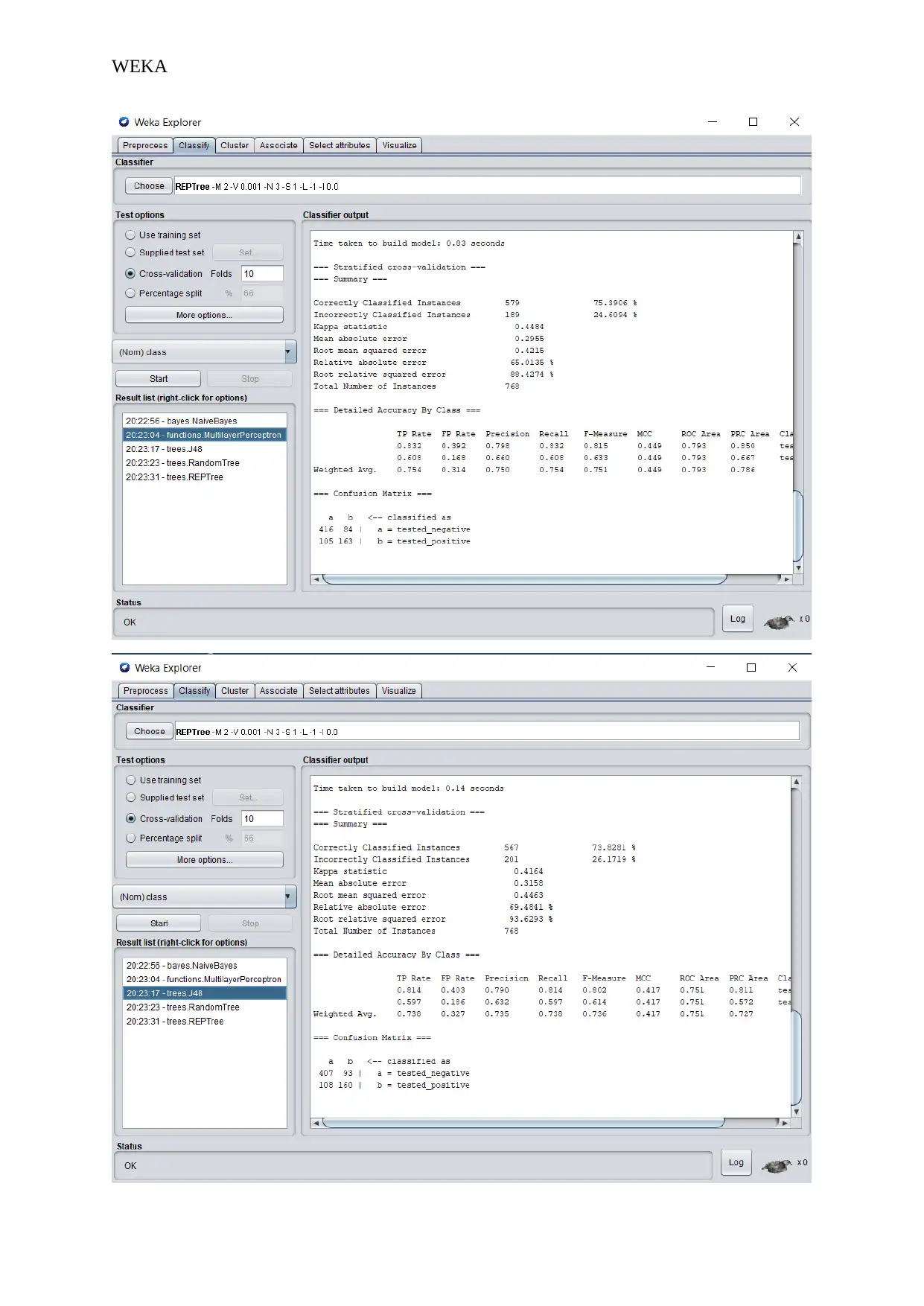
This project evaluates the performance of five classification algorithms (Multilayer Perceptron, Naive Bayes, J48, Random Forest, and REPTree) on three datasets: Breast-cancer, Diabetes, and Iris. The analysis uses WEKA with default settings and 10-fold cross-validation. The study focuses on key performance metrics, including correctly and incorrectly classified instances, kappa statistics, true and false positive rates, precision, recall, F-measure, and ROC area. The results show varying performance across datasets, with the Iris dataset generally yielding the best results. The report highlights how the performance of algorithms varies depending on the dataset and the importance of considering multiple evaluation metrics beyond simple classification accuracy. The project provides insights into the variability and flexibility inherent in data science applications.











1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.