Financial Analysis Homework: Stock and Index Performance Evaluation
VerifiedAdded on 2021/06/17
|8
|1540
|157
Homework Assignment
AI Summary
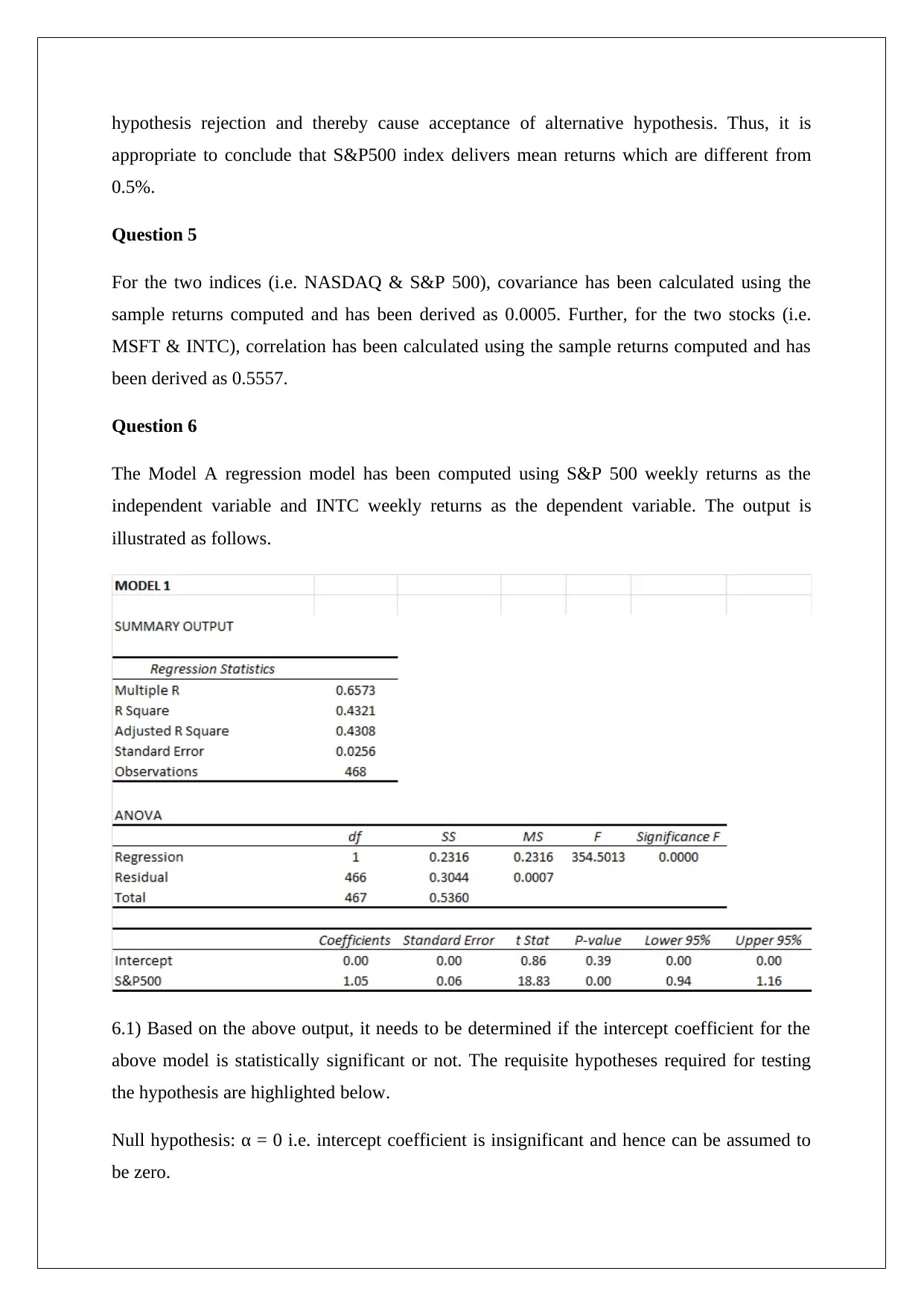
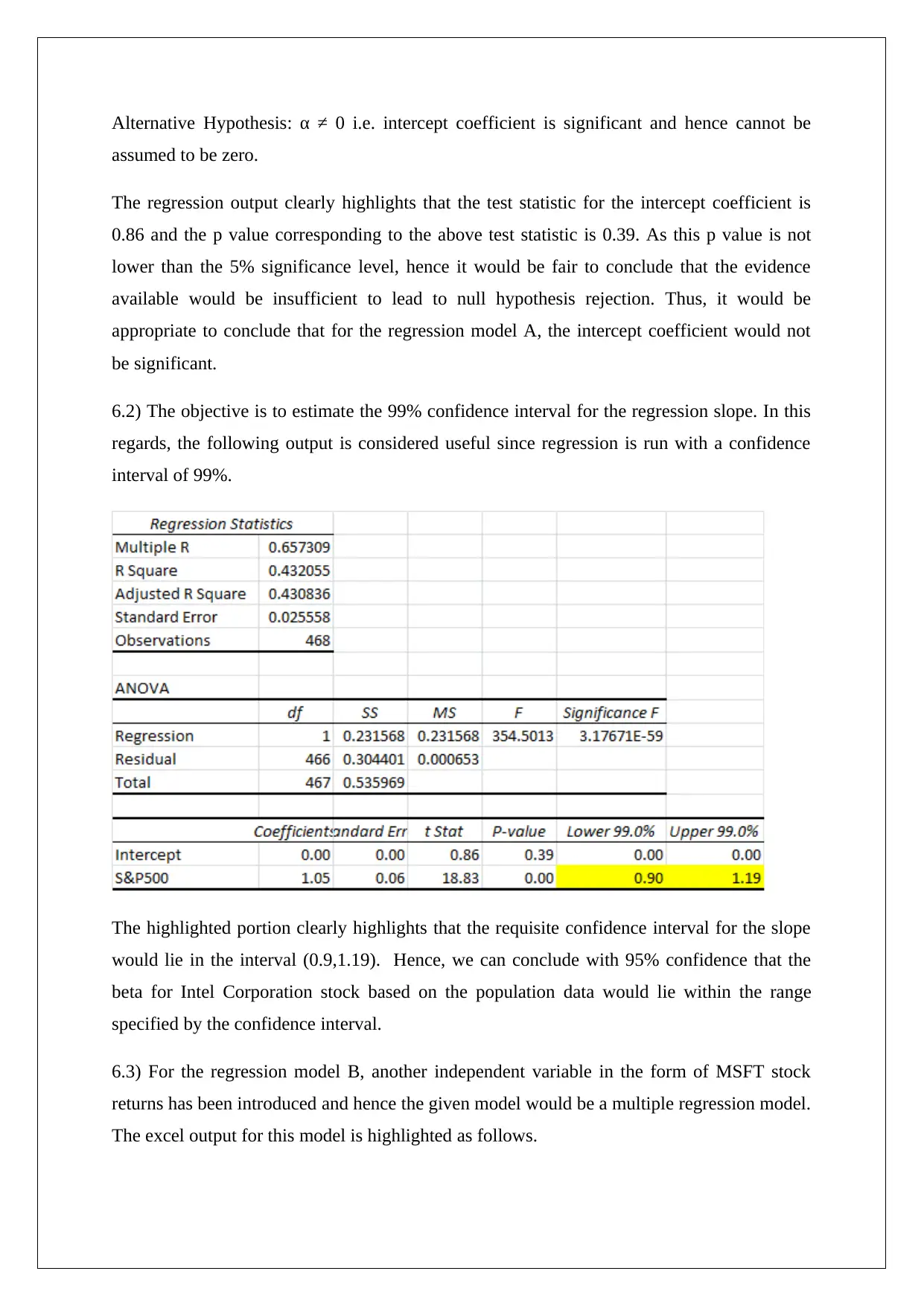
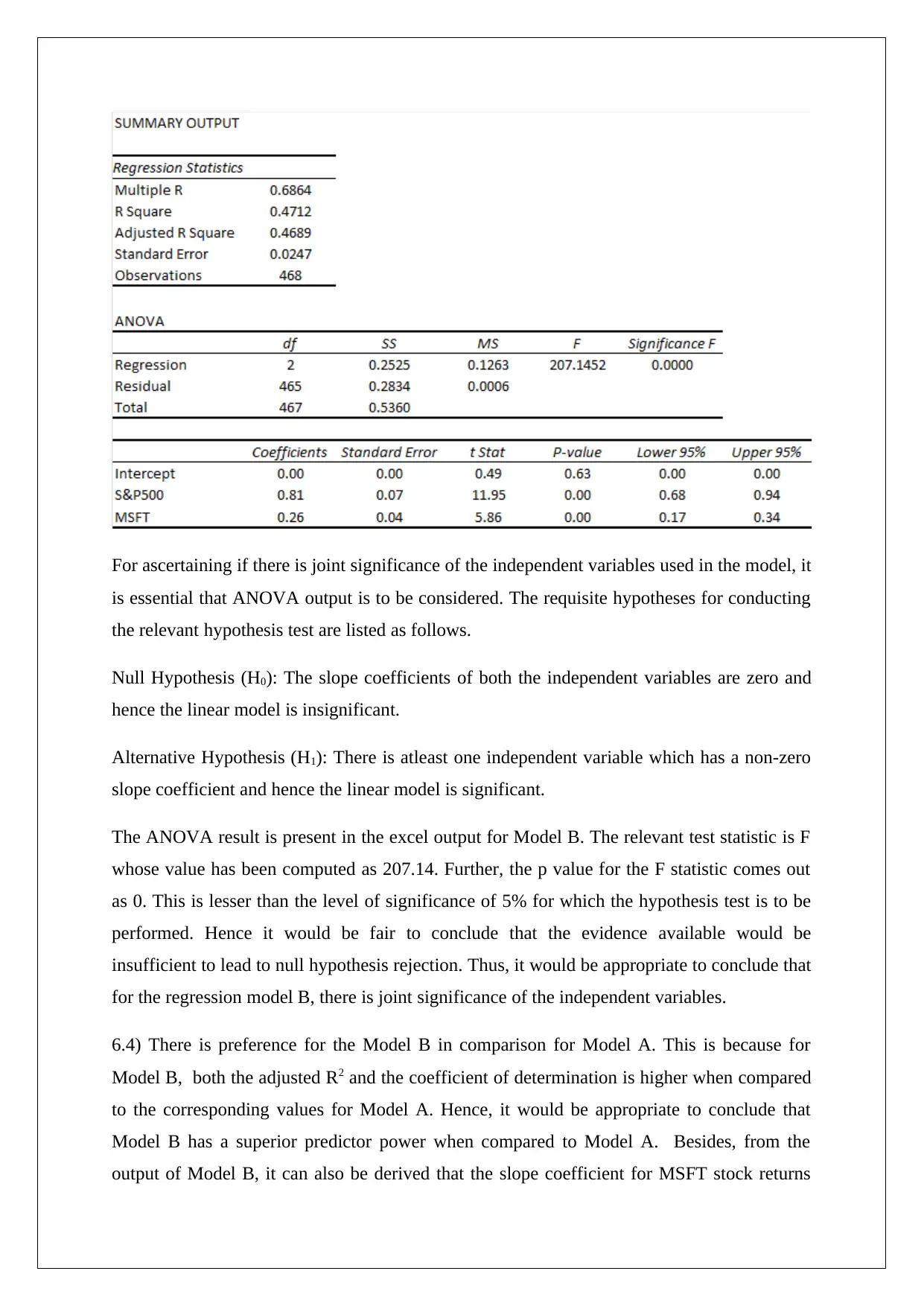
This homework assignment analyzes the performance of two stocks (MSFT and INTC) and two indices (NASDAQ and S&P 500) using provided data. The solution calculates weekly holding period returns, assesses relative risk using risk per unit return, and determines empirical probabilities of negative returns and returns exceeding a threshold. Hypothesis tests are conducted to evaluate the mean returns of NASDAQ and S&P 500. Covariance and correlation are computed for the indices and stocks, respectively. Two regression models are analyzed: Model A examines the relationship between S&P 500 and INTC returns, while Model B incorporates MSFT returns. The analysis includes assessing the significance of intercept and slope coefficients, constructing confidence intervals, and comparing the predictive power of the models based on adjusted R-squared and the coefficient of determination. The solution concludes with a preference for Model B due to its superior predictor power.





1 out of 8
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.