Quantitative Methods Report: Statistical Analysis of Business Data
VerifiedAdded on 2023/01/13
|25
|4812
|88
Report
AI Summary
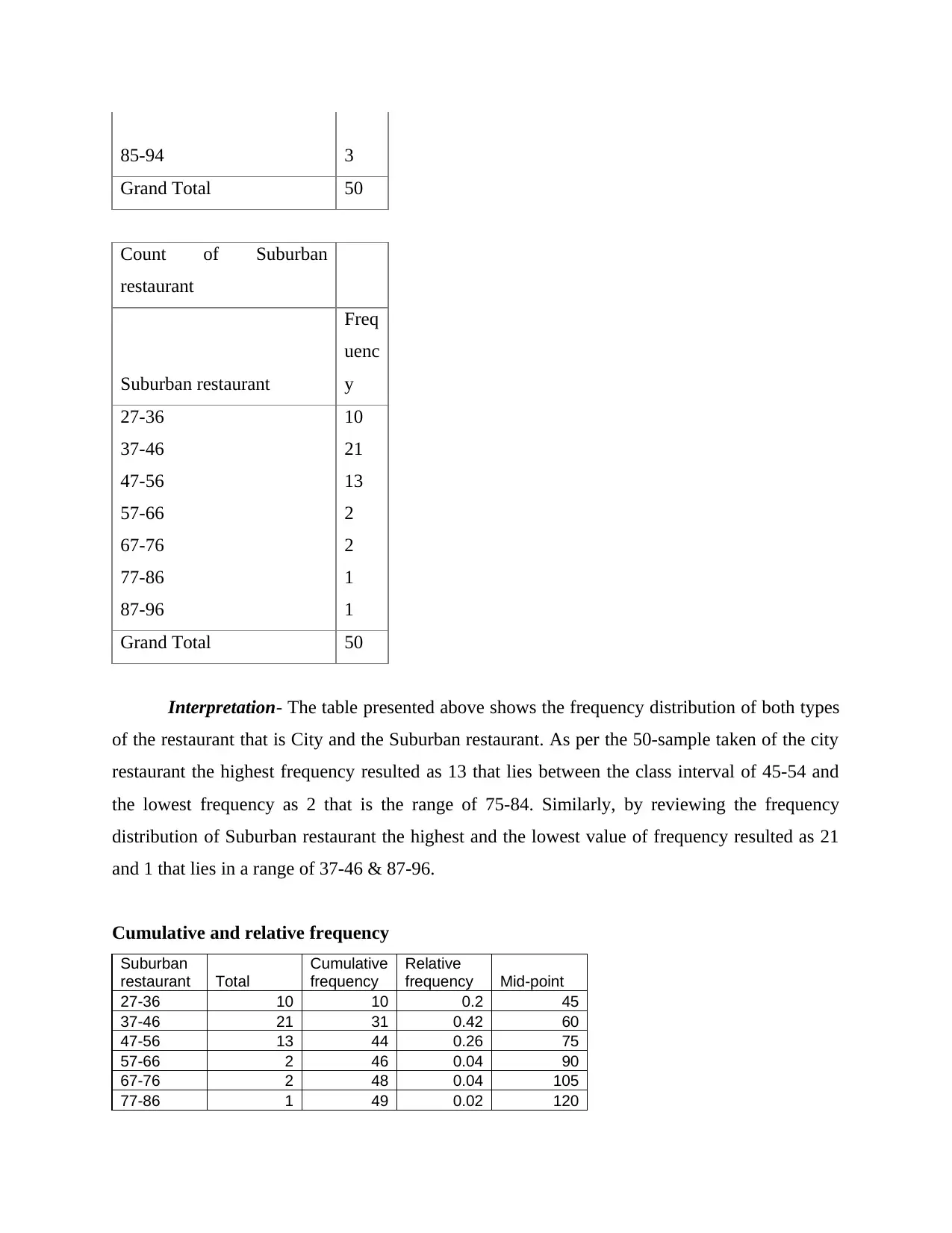
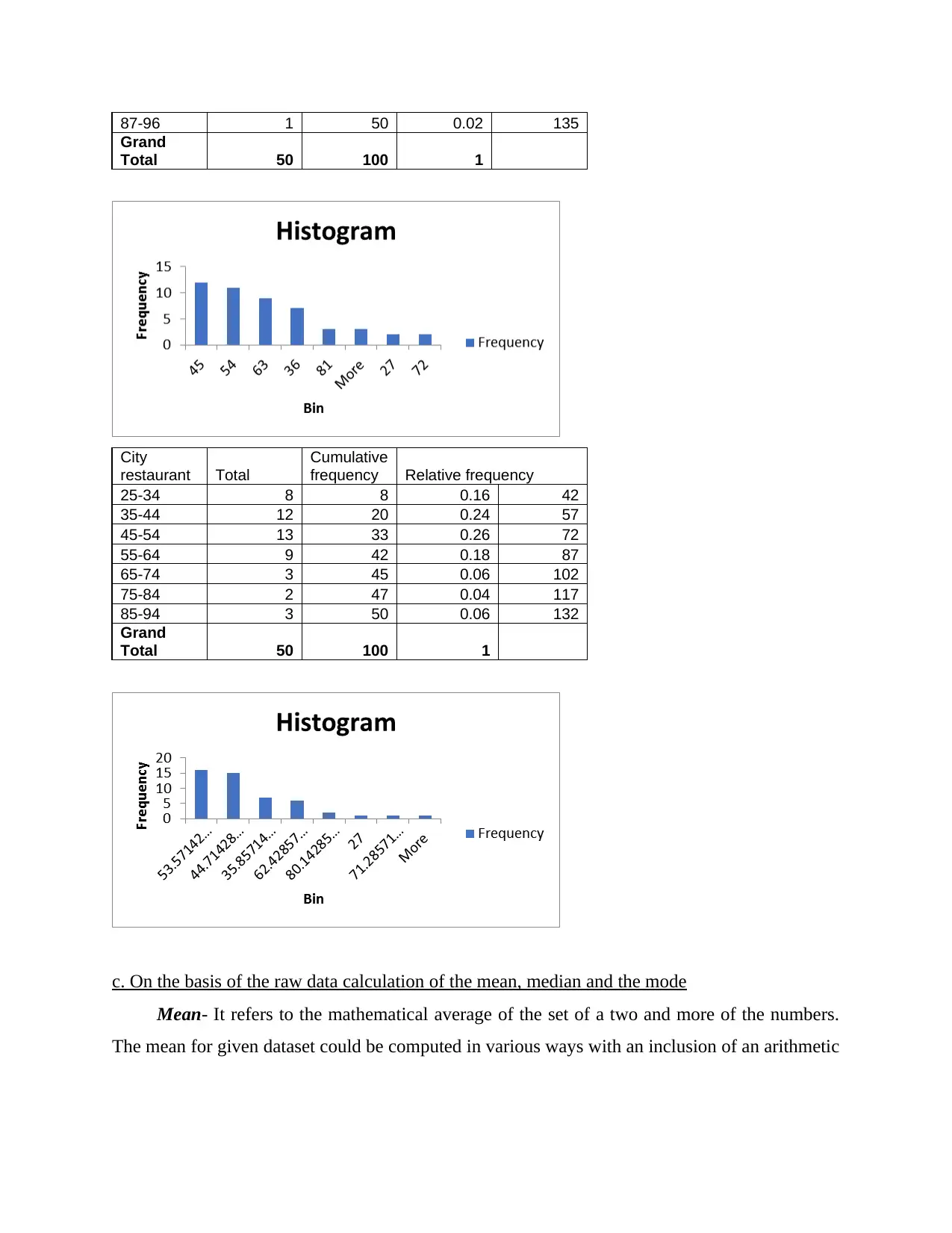
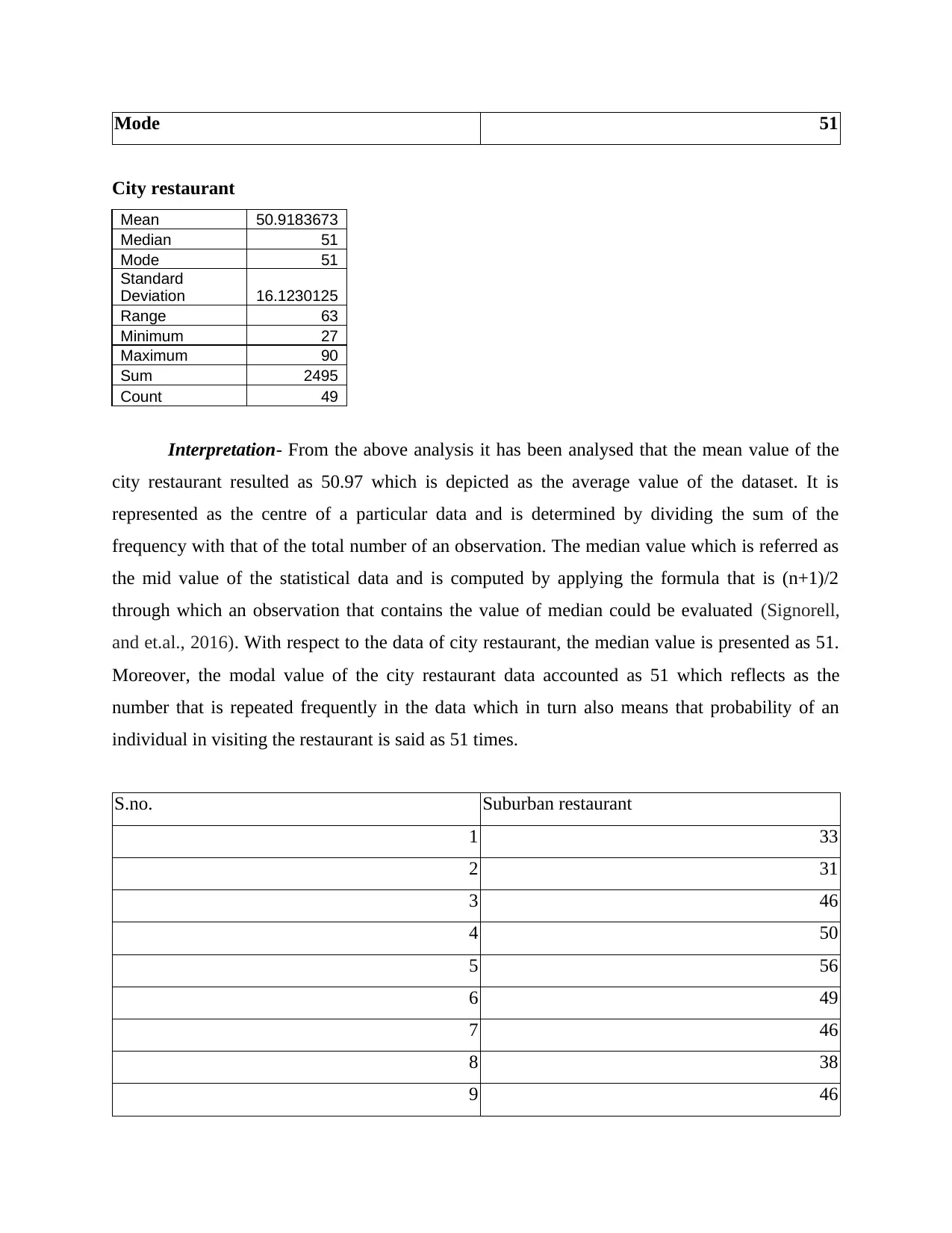
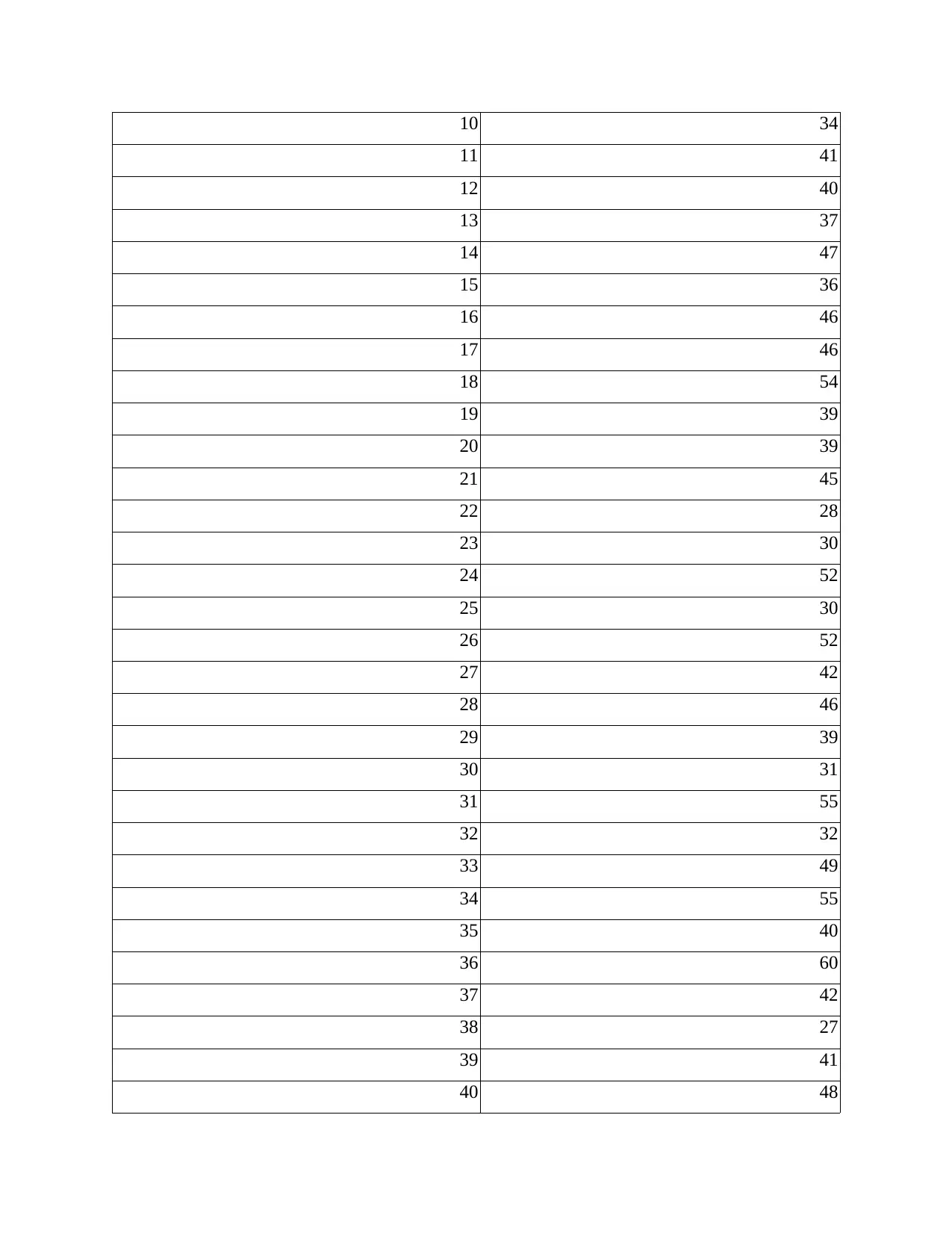
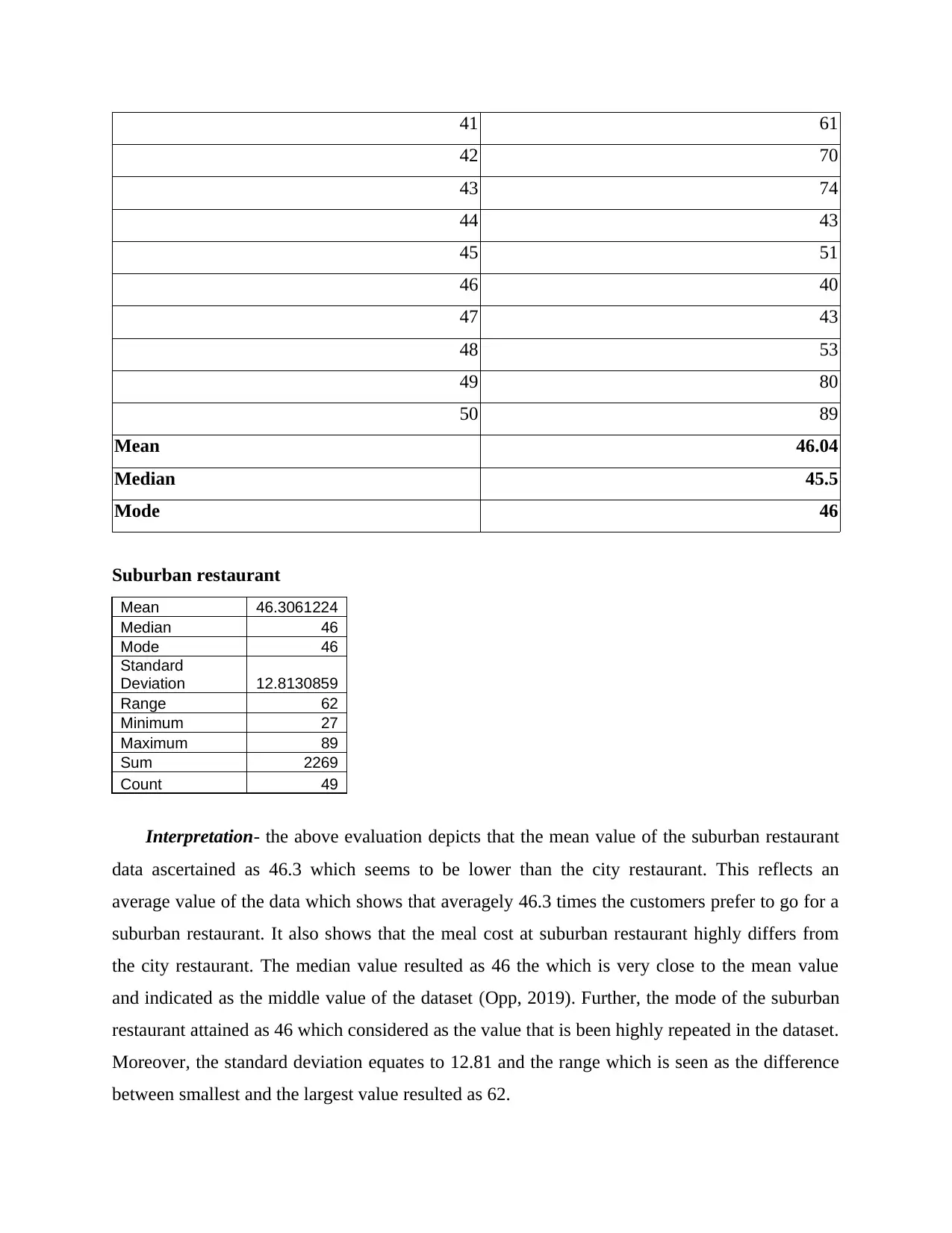
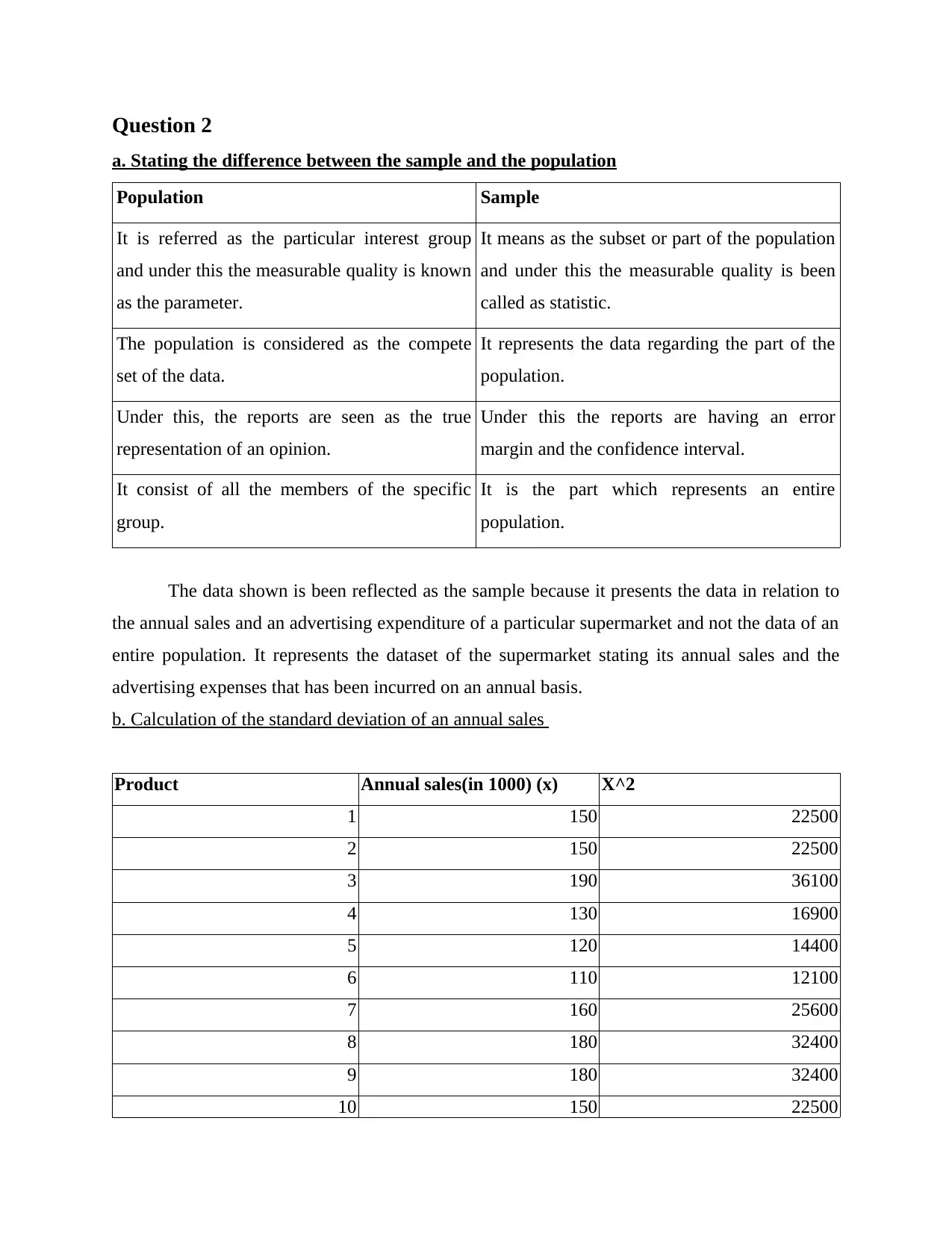
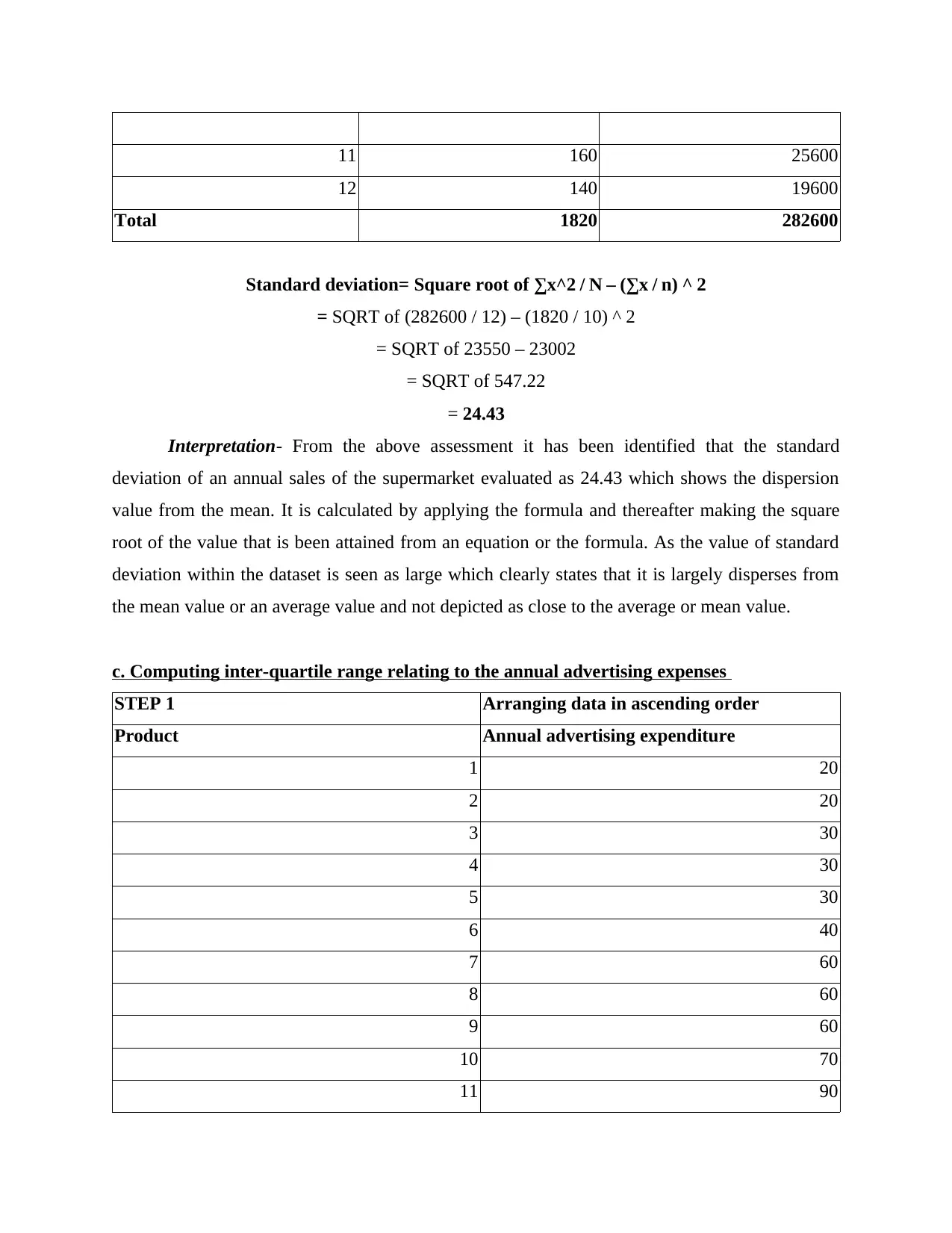
This report provides a comprehensive analysis of numerical data using various quantitative methods. It begins with an introduction to statistical tools and their application in data analysis. The report then delves into frequency distribution, presenting tables and interpretations for city and suburban restaurants. It proceeds to calculate the mean, median, and mode for both restaurant types. Further analysis includes the calculation of standard deviation for annual sales, the inter-quartile range for advertising expenses, and the coefficient of correlation. The report also conducts a regression analysis to examine the relationship between advertising expenditure and sales, interpreting the results and evaluating the coefficient of determination. Additionally, it explores probability calculations related to recruitment and training and discusses the applicability of the z-test. The report concludes with a summary of findings and references.




1 out of 25
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.