EMAT30007 Applied Statistics: Linear Models for Sugar Consumption
VerifiedAdded on 2023/01/18
|23
|3217
|47
Homework Assignment
AI Summary
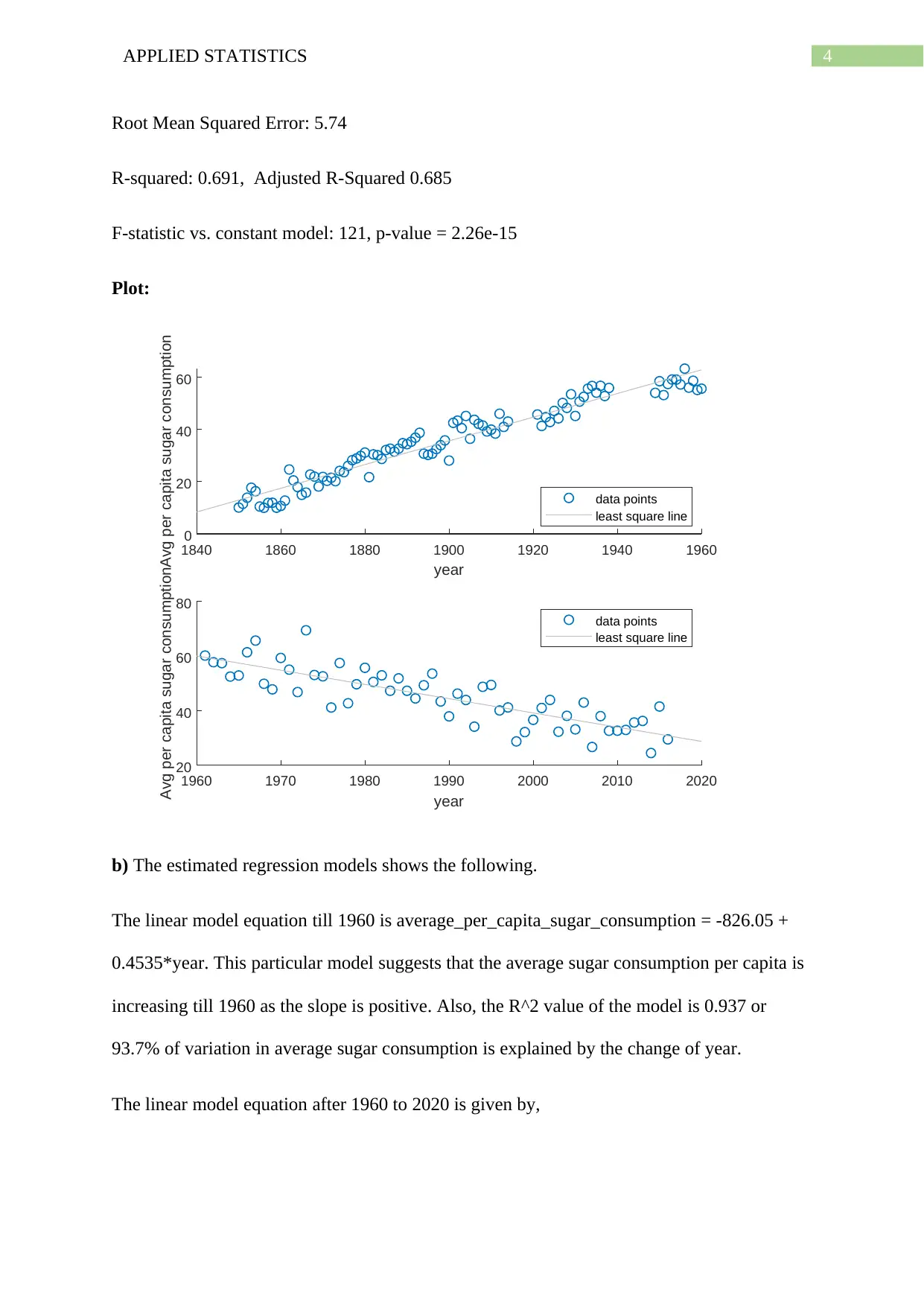
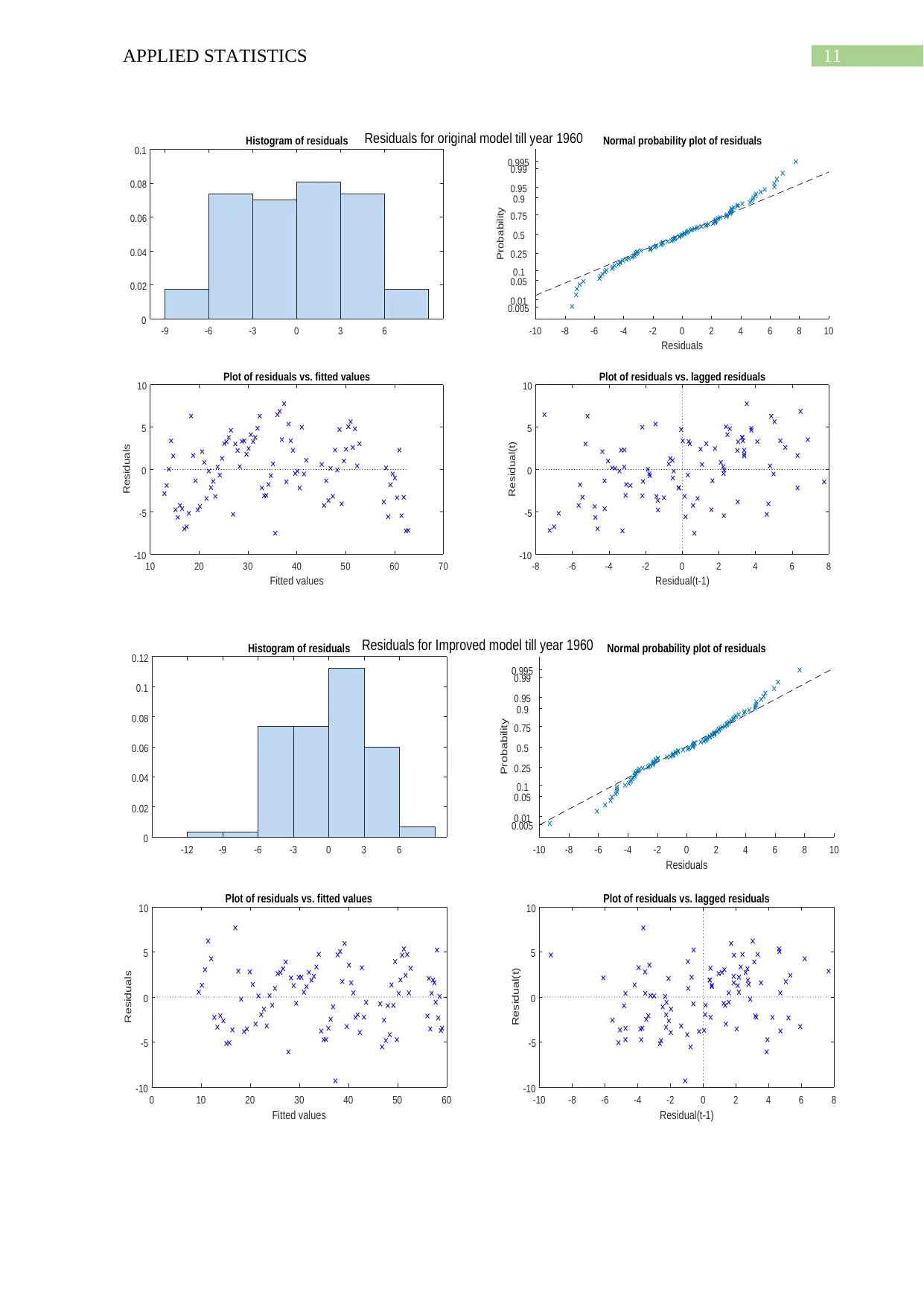
This document presents a comprehensive solution to an applied statistics assignment, focusing on the analysis of sugar consumption data using linear models. The assignment utilizes MATLAB to build and evaluate various linear regression models. The analysis begins by plotting raw data and fitting linear models to different time periods, examining the equations, R-squared values, and interpretations of the models. The solution then proceeds to improve the models by incorporating quadratic and cubic terms, performing residual analysis to assess model fit and identify areas for improvement. The predicted values for sugar consumption are calculated using the improved models, and the results are compared to historical evidence. Furthermore, the assignment explores the impact of including a quadratic term in a single linear model and compares the results to the previous models. The solution also covers the model parameters, residual plots, and interpretations of the results. Finally, the assignment incorporates Bayesian modeling to the data and examines the impact of prior distributions on the model's parameters.










1 out of 23
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.