Applied Statistics 13 Assignment: Regression and Error Analysis
VerifiedAdded on 2022/12/19
|12
|711
|63
Homework Assignment
AI Summary
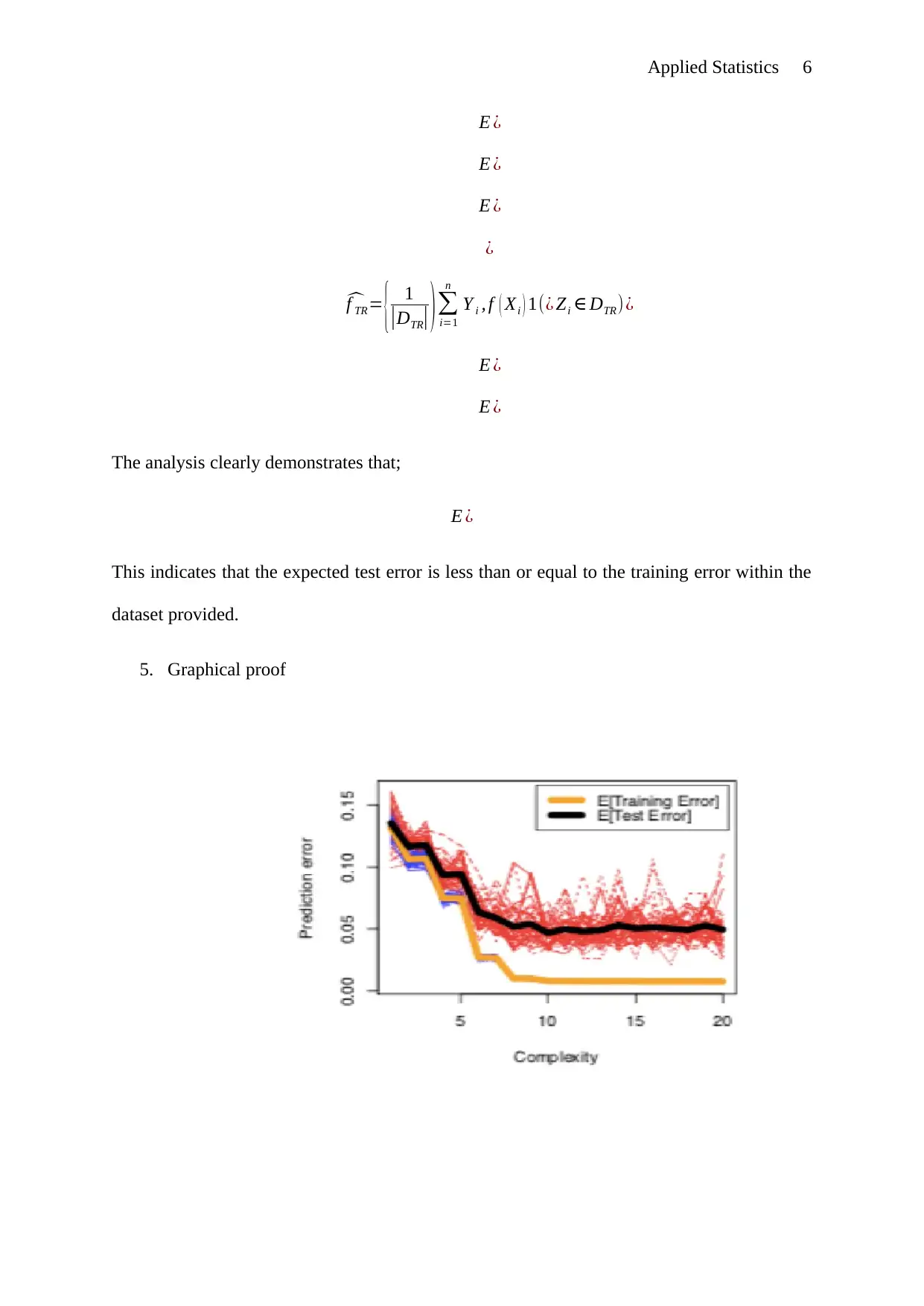
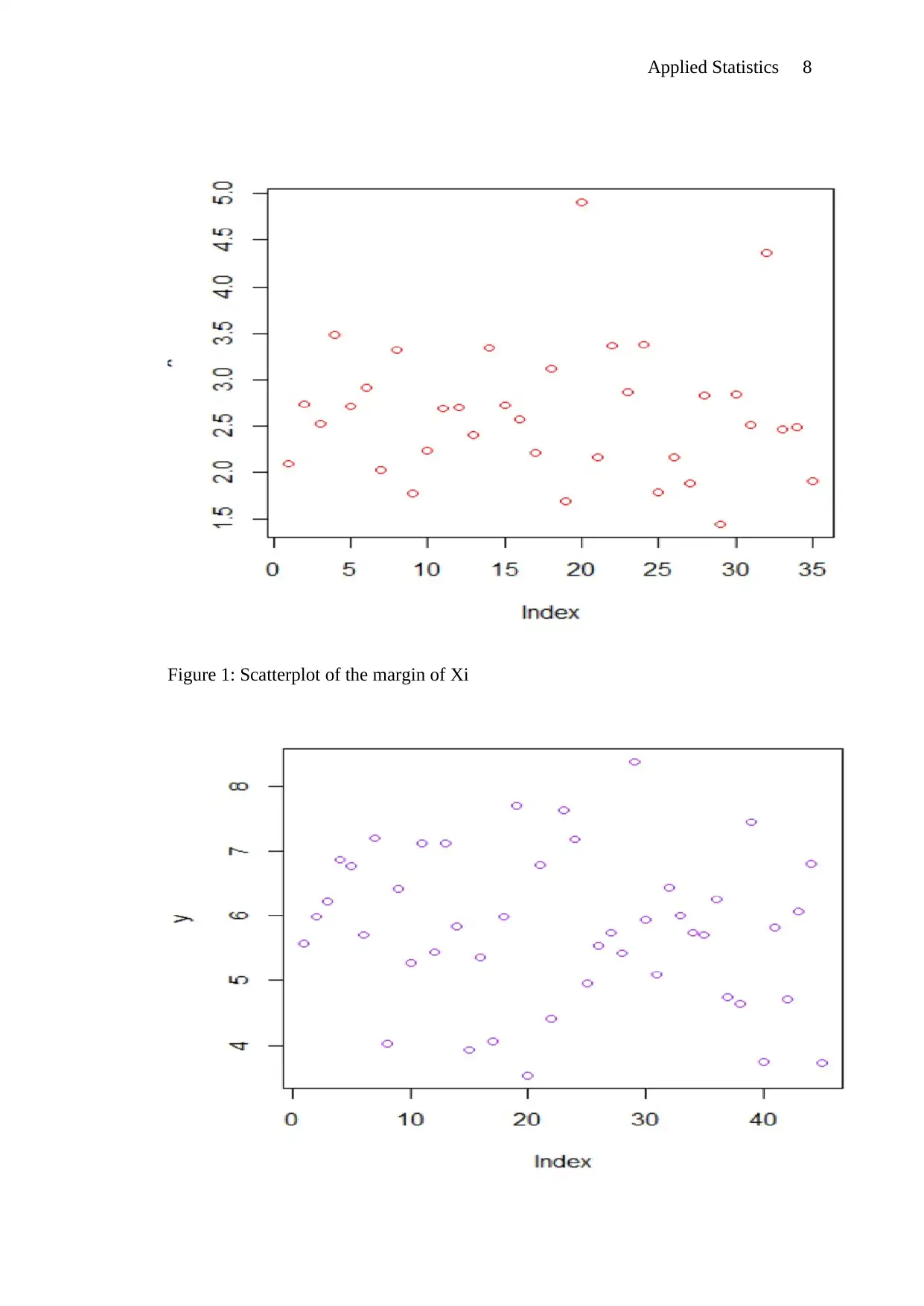
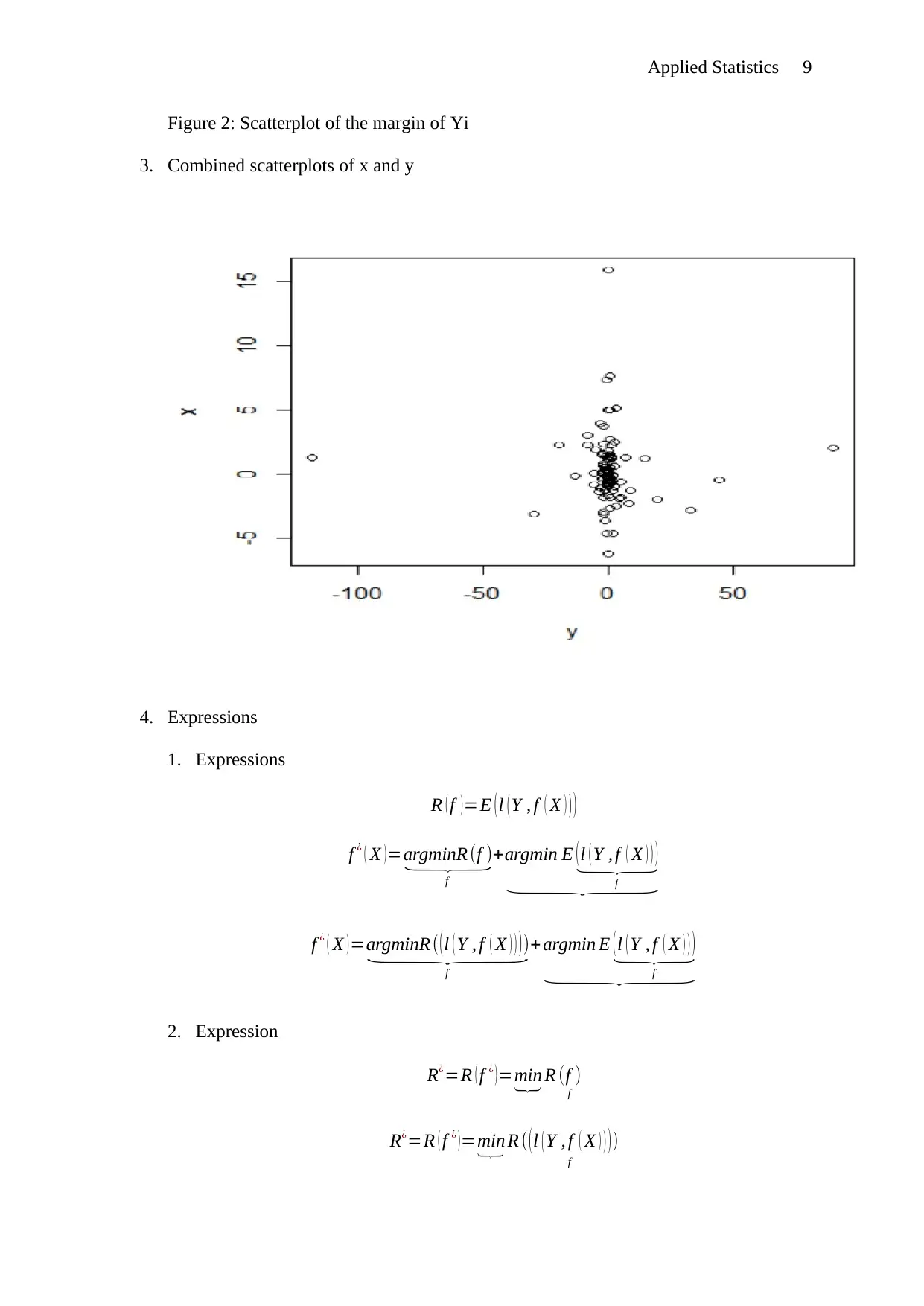
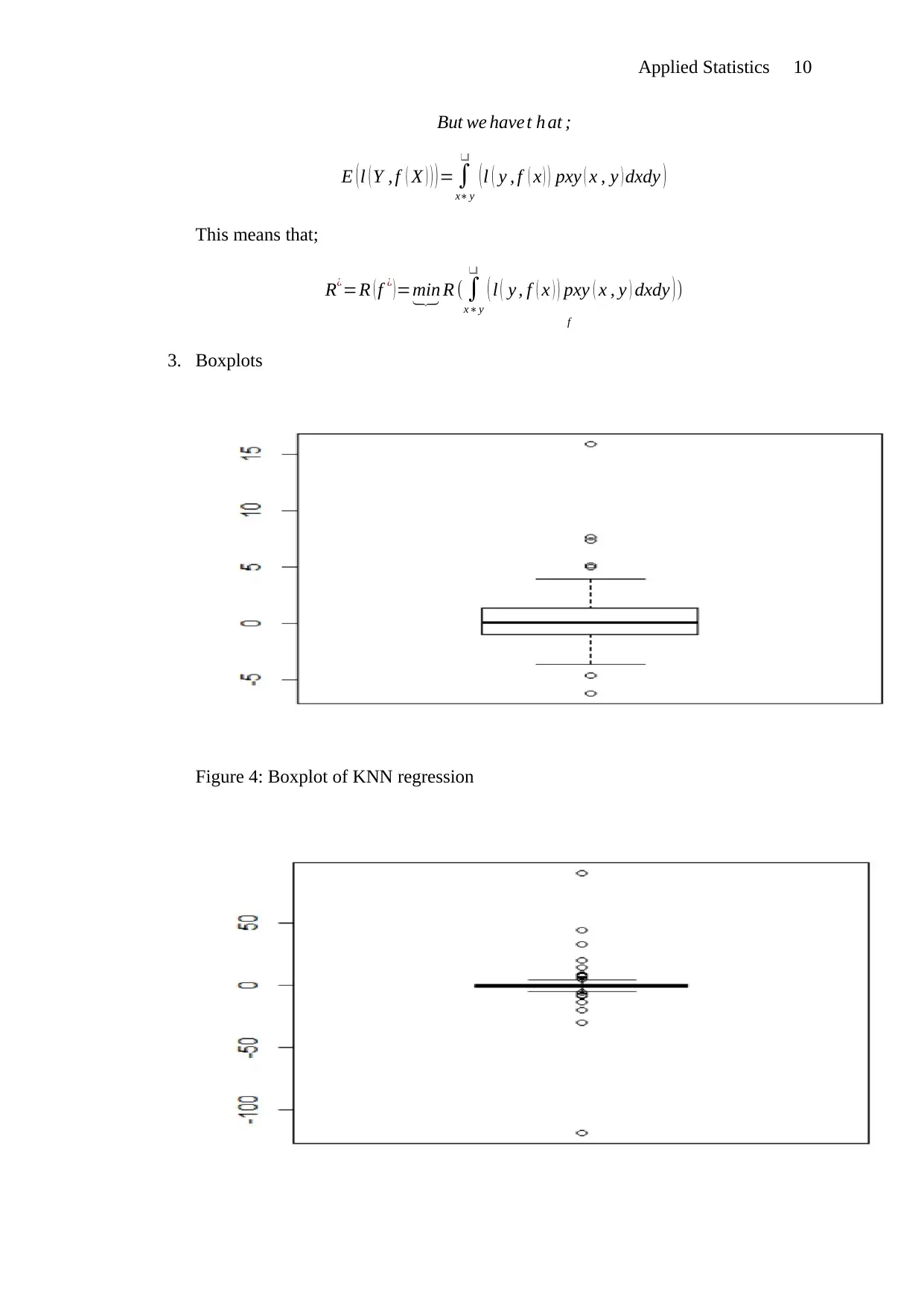
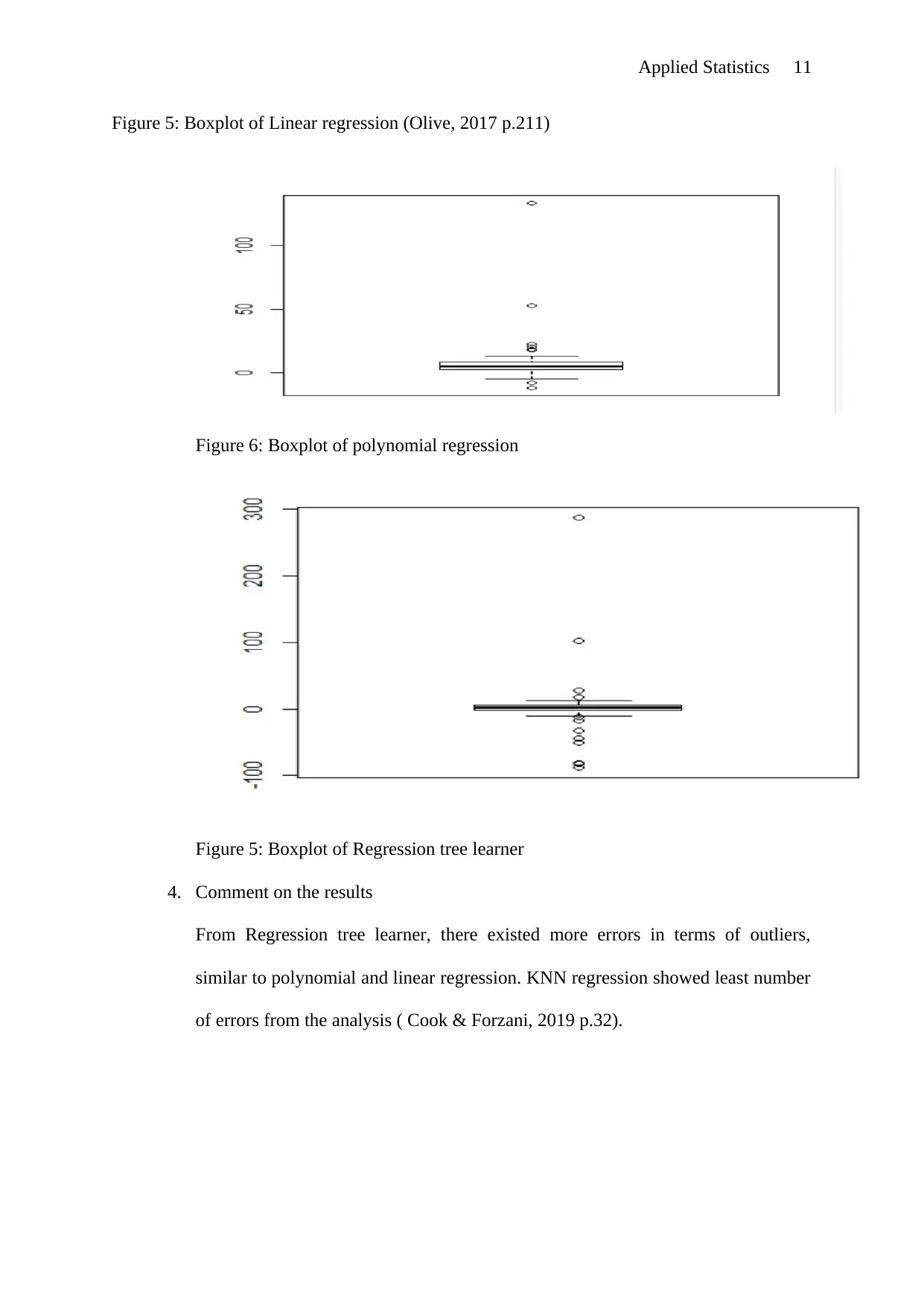
This document provides solutions to an Applied Statistics assignment. The assignment addresses three key questions. Question 1 focuses on the role of in the analysis, explaining its function and limitations as a predictor. Question 2 offers multiple proofs demonstrating the relationship between expected test error and training error. The proofs include mathematical derivations and comparisons. Question 3 involves the analysis of regression techniques. It includes scatterplots of marginal distributions, expressions, and boxplots comparing KNN regression, linear regression, polynomial regression, and regression tree learner. The analysis reveals error characteristics of each method, with the KNN regression showing the fewest outliers.







1 out of 12


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.