Deep Learning in AI and Machine Vision: Project at UEL
VerifiedAdded on 2021/08/17
|11
|3943
|132
Project
AI Summary
This project report delves into the realm of Artificial Intelligence and Machine Vision, specifically focusing on deep learning and Convolutional Neural Networks (CNNs) for image recognition. The report begins with an abstract that introduces deep learning as a key AI innovation for extracting higher-level representations from raw data, highlighting its applications in various fields like image processing and web systems. The introduction provides an overview of deep learning's potential in enhancing web knowledge by efficiently mining vast amounts of data. The report then outlines the structures and learning algorithms for different deep learning models, including neural networks and training algorithms. It also covers the classification of CNN layers, including convolution, activation, and pooling. Furthermore, the project includes simulations using Matlab, utilizing a dataset of four shapes to train and test a CNN model. The results obtained demonstrate the effectiveness of CNNs in image recognition. The architecture, training options, and the process of training, validation, and testing the system are described in detail. The report concludes by highlighting the significance of CNNs as essential tools for deep learning and their suitability for image recognition, particularly in advancements like automated driving and facial recognition.

ARTIFICIAL INTELLIGENCE AND MACHINE VISION
Dpenkumar Rajanikant Patel, Satvindere Kaur, Santoshkumar
Rameshbhai Gajera, Dhruvilkumar Manharbhai Patel
u1956326@uel.ac.uk, u1956387@uel.ac.uk, u1957976@uel.ac.uk,
u1962877@uel.ac.uk
Abstract: Deep learning is an Artificial Intelligence innovation that naturally separates more
significant level portrayals from crude information by gathering different layers of neuron-like units.
This stacking takes into account separating portrayals of progressively complex highlights without
tedious, component building. Ongoing achievement of profound learning has indicated that it
outflanks best in class frameworks in picture handling, voice acknowledgment, web search, proposal
frameworks, and so forth. We additionally spread uses of deep learning for picture and video
preparing, language and content information examination, social information investigation, and
wearable IoT sensor information with an accentuation in the area of Website frameworks. Graphical
delineations and models could be significant in examining a lot of Web information.
1. Introduction:
Deep learning has immense potential to
improve the knowledge of the web and
web administration frameworks by
productively and viably mining enormous
amounts of information from the Web.
This instructional exercise gives the nuts
and bolts of deep learning just as its key
developments.
1.1. Sections
We give the inspiration and hidden
thoughts of profound learning and depict
the structures and learning calculations for
different profound learning models. The
instructional exercise comprises of five
sections. (Jung, Pages 1525–1526)
i. The initial segment presents the
rudiments of neural systems, and
their structures. At that point we
clarify the preparation calculation
by means of back propagation,
which is a typical technique for
preparing counterfeit neural
systems including profound neural
systems. We will underline how
every one of these ideas can be
utilized in various Web information
investigation.
ii. In the second piece of instructional
exercise, we depict the learning
calculations for profound neural
systems and related thoughts, for
example, contrastive difference,
wake-rest calculations, and Monte
Carlo reproduction. We at that
point portray different sorts of
profound designs, including,
profound conviction systems
stacked auto encrypts,
convolutional neural systems, and
profound hyper networks.
iii. In the third part, we present more
subtleties of recursive neural
systems, which can learn organized
tree yields just as vector portrayals
expressions and sentences. We first
show how preparing the recursive
neural system can be accomplished
by an adjusted variant of back-
engendering calculation presented
Dpenkumar Rajanikant Patel, Satvindere Kaur, Santoshkumar
Rameshbhai Gajera, Dhruvilkumar Manharbhai Patel
u1956326@uel.ac.uk, u1956387@uel.ac.uk, u1957976@uel.ac.uk,
u1962877@uel.ac.uk
Abstract: Deep learning is an Artificial Intelligence innovation that naturally separates more
significant level portrayals from crude information by gathering different layers of neuron-like units.
This stacking takes into account separating portrayals of progressively complex highlights without
tedious, component building. Ongoing achievement of profound learning has indicated that it
outflanks best in class frameworks in picture handling, voice acknowledgment, web search, proposal
frameworks, and so forth. We additionally spread uses of deep learning for picture and video
preparing, language and content information examination, social information investigation, and
wearable IoT sensor information with an accentuation in the area of Website frameworks. Graphical
delineations and models could be significant in examining a lot of Web information.
1. Introduction:
Deep learning has immense potential to
improve the knowledge of the web and
web administration frameworks by
productively and viably mining enormous
amounts of information from the Web.
This instructional exercise gives the nuts
and bolts of deep learning just as its key
developments.
1.1. Sections
We give the inspiration and hidden
thoughts of profound learning and depict
the structures and learning calculations for
different profound learning models. The
instructional exercise comprises of five
sections. (Jung, Pages 1525–1526)
i. The initial segment presents the
rudiments of neural systems, and
their structures. At that point we
clarify the preparation calculation
by means of back propagation,
which is a typical technique for
preparing counterfeit neural
systems including profound neural
systems. We will underline how
every one of these ideas can be
utilized in various Web information
investigation.
ii. In the second piece of instructional
exercise, we depict the learning
calculations for profound neural
systems and related thoughts, for
example, contrastive difference,
wake-rest calculations, and Monte
Carlo reproduction. We at that
point portray different sorts of
profound designs, including,
profound conviction systems
stacked auto encrypts,
convolutional neural systems, and
profound hyper networks.
iii. In the third part, we present more
subtleties of recursive neural
systems, which can learn organized
tree yields just as vector portrayals
expressions and sentences. We first
show how preparing the recursive
neural system can be accomplished
by an adjusted variant of back-
engendering calculation presented
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

previously. These changes permit
the calculation to chip away at tree
structures. At that point we will
introduce its applications to
sentence examination including
labeling, and opinion investigation.
iv. The fourth part talks about the
neural systems used to create word
embeddings, for example, DSSM
for profound semantic similitude,
Word2Vec, and object discovery in
pictures, for example, Alex Net and
Google Net. We will clarify in
detail the uses of these profound
learning procedures in the
examination of different
interpersonal organization
information. By this point, the
crowd ought to have an away form
of how to construct a profound
learning system for word, sentence
and report level assignments.
v. The fifth piece of the instructional
exercise will cover other
application instances of profound
learning. These incorporate item
division and activity
acknowledgment from recordings,
web information investigation, and
wearable/IoT sensor information
displaying for brilliant
administrations. (Jung, Pages
1525–1526)
1.2. Related Works
AI innovation utilizing profound neural
systems is critical in light of the fact that it
outperforms human execution in numerous
territories. Attributable to the specific
consideration being paid to fake neural
systems, a few methodologies have been
created to deal with induction steps that
are executed on surmising motors by
developing and preparing neural systems.
Induction advances utilizing cloud
and adapting for the most part
utilize cloud‐based derivation
motors, for example, Google's
TPU, yet they utilize comparative
equipment (for the most part the
GPU). Conversely, induction
procedures for gadgets at edge
focuses depend on streamlined
equipment quickening agents and
require uncommon enhancement
strategies. (Cho, 22 September
2019)
Caffe: This is among the soonest grown
profound learning systems; it was grown
essentially at Berkeley Vision and
Learning Center. It’s additionally C plus
plus library with idle interface, that it
utilizes as default app while displaying
convolutional neural system. One of an
essential benefit of utilizing this library is
that it can straightforwardly utilize
numerous pretrained systems from Caffe
Structured Zoo. FB discharged a light
weighted measured profound educating
system, Caffe, fabricate a high qualified
performance open educating structure
utilizing Caffe. (Yoo, 23 September 2019)
Torch: It is based upon Lau deep running
system created with enormous players,
e.g.; Google, Facebook, and Twitter. It is
equal handling utilizes the C/C++ library
and CUDA for GPU preparing.
Furthermore, Torch Pytorch execution,
known as Pythons, is picking up
prominence and is being well received.
Theano: It’s helpful in numerical figuring
using CPUs and GPUs. a low-quality
library and could streamline forms by
legitimately making profound educating
model or with applying wrapper library in
this. In any case, in contrast to other
broadened learning structures, it isn't
versatile and needs help for different CPUs
and GPUs.
the calculation to chip away at tree
structures. At that point we will
introduce its applications to
sentence examination including
labeling, and opinion investigation.
iv. The fourth part talks about the
neural systems used to create word
embeddings, for example, DSSM
for profound semantic similitude,
Word2Vec, and object discovery in
pictures, for example, Alex Net and
Google Net. We will clarify in
detail the uses of these profound
learning procedures in the
examination of different
interpersonal organization
information. By this point, the
crowd ought to have an away form
of how to construct a profound
learning system for word, sentence
and report level assignments.
v. The fifth piece of the instructional
exercise will cover other
application instances of profound
learning. These incorporate item
division and activity
acknowledgment from recordings,
web information investigation, and
wearable/IoT sensor information
displaying for brilliant
administrations. (Jung, Pages
1525–1526)
1.2. Related Works
AI innovation utilizing profound neural
systems is critical in light of the fact that it
outperforms human execution in numerous
territories. Attributable to the specific
consideration being paid to fake neural
systems, a few methodologies have been
created to deal with induction steps that
are executed on surmising motors by
developing and preparing neural systems.
Induction advances utilizing cloud
and adapting for the most part
utilize cloud‐based derivation
motors, for example, Google's
TPU, yet they utilize comparative
equipment (for the most part the
GPU). Conversely, induction
procedures for gadgets at edge
focuses depend on streamlined
equipment quickening agents and
require uncommon enhancement
strategies. (Cho, 22 September
2019)
Caffe: This is among the soonest grown
profound learning systems; it was grown
essentially at Berkeley Vision and
Learning Center. It’s additionally C plus
plus library with idle interface, that it
utilizes as default app while displaying
convolutional neural system. One of an
essential benefit of utilizing this library is
that it can straightforwardly utilize
numerous pretrained systems from Caffe
Structured Zoo. FB discharged a light
weighted measured profound educating
system, Caffe, fabricate a high qualified
performance open educating structure
utilizing Caffe. (Yoo, 23 September 2019)
Torch: It is based upon Lau deep running
system created with enormous players,
e.g.; Google, Facebook, and Twitter. It is
equal handling utilizes the C/C++ library
and CUDA for GPU preparing.
Furthermore, Torch Pytorch execution,
known as Pythons, is picking up
prominence and is being well received.
Theano: It’s helpful in numerical figuring
using CPUs and GPUs. a low-quality
library and could streamline forms by
legitimately making profound educating
model or with applying wrapper library in
this. In any case, in contrast to other
broadened learning structures, it isn't
versatile and needs help for different CPUs
and GPUs.

Kera’s: this was created as rearranged
GUI for proficient NS development and it
could be designed for working with Tensor
flow or Theano. It’s written in Python and
is low weighted and simple to understand.
It most prominent bit of leeway is which it
tends to get utilized to make CNN from 2
lines of code. (Yoo, 23 September 2019)
1.3. Interworking Architecture
Procedure of a computerized reasoning
neural system can be generally isolated
into a learning motor and a surmising
motor for deciding the yield information
from the given information, as appeared in
Figure 1. The learning motor decides the
working capacities and parameters in the
neural system with the goal that the client
can produce the ideal yield through
example input information. The derivation
motor plays out a progression of
procedures that can create yield
information from new information
utilizing the neural system structure data
learned through the learning motor. (Cho
C. , 12 oct 2019)
Figure:1 Isolated learning and induction
frameworks.
Many induction and learning motors
comprise of solitary set. Every one of
them can be isolated yet the structure
of the capacity strategy for the
educated neural system, which relies
upon the item utilized, designer, and
different elements, might be diverse
between the learning motor and
deduction motor. In this manner,
different neural system derivation
motors are being created. Every
induction motor has its own neural
system stockpiling design.
To take care of this issue, inter
working structure is essential between
educating framework structure and
induction structure. Image shows that
present system position structure,
interworking issues, and requirement
for a CNN system design. (Cho C. , 12
oct 2019)
Figure:2 Need of normalizing neural
systems.
2. Methodologies:
A CNN can have layers that each make
sense of how to perceive different
features of an image. Channels are
applied to every readiness picture at
different objectives, and the yield of
each convolved picture is used as the
commitment to the accompanying
layer. The channels can start as
amazingly fundamental features, for
instance, brightness and edges, and
GUI for proficient NS development and it
could be designed for working with Tensor
flow or Theano. It’s written in Python and
is low weighted and simple to understand.
It most prominent bit of leeway is which it
tends to get utilized to make CNN from 2
lines of code. (Yoo, 23 September 2019)
1.3. Interworking Architecture
Procedure of a computerized reasoning
neural system can be generally isolated
into a learning motor and a surmising
motor for deciding the yield information
from the given information, as appeared in
Figure 1. The learning motor decides the
working capacities and parameters in the
neural system with the goal that the client
can produce the ideal yield through
example input information. The derivation
motor plays out a progression of
procedures that can create yield
information from new information
utilizing the neural system structure data
learned through the learning motor. (Cho
C. , 12 oct 2019)
Figure:1 Isolated learning and induction
frameworks.
Many induction and learning motors
comprise of solitary set. Every one of
them can be isolated yet the structure
of the capacity strategy for the
educated neural system, which relies
upon the item utilized, designer, and
different elements, might be diverse
between the learning motor and
deduction motor. In this manner,
different neural system derivation
motors are being created. Every
induction motor has its own neural
system stockpiling design.
To take care of this issue, inter
working structure is essential between
educating framework structure and
induction structure. Image shows that
present system position structure,
interworking issues, and requirement
for a CNN system design. (Cho C. , 12
oct 2019)
Figure:2 Need of normalizing neural
systems.
2. Methodologies:
A CNN can have layers that each make
sense of how to perceive different
features of an image. Channels are
applied to every readiness picture at
different objectives, and the yield of
each convolved picture is used as the
commitment to the accompanying
layer. The channels can start as
amazingly fundamental features, for
instance, brightness and edges, and
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

augmentation in multifaceted nature to
features that especially portray the
subject.
CNNs perform highlight recognizable
proof and order of pictures, content,
sound, and recording.
Just as other neural systems, this is
made out of information layer, a yield
layer, and many concealed layers in the
middle.
Figure:3 Neural Network.
These layers perform tasks that change the
information with the aim of learning
highlights explicit to the information.
Three of the most widely recognized layers
are: convolution, actuation, and pooling.
Convolution gets the info pictures through
a lot of convolutional channels, every one
of which enacts certain highlights from
pictures.
Amended straight unit considers quicker
and increasingly powerful preparing by
mapping negative qualities to zero and
keeping up positive qualities. This is once
in a while alluded to as actuation, in light
of the fact that solitary initiated highlights
are conveyed forward into following layer.
Pooling: rearranges yield by performing
nonlinear down sampling and decreasing
quantity of parameters that system needs
to learn.
So tasks are rehashed more than tens or
several layers, with each layer figuring out
how to distinguish various highlights.
se activities are rehashed more than tens or
many layers, with each layer figuring out
how to distinguish various highlights.
2.1. Classification of layers:
In the wake of learning highlights in
numerous layers, the design of a CNN
movements to arrangement.
Near last layer is a totally related layer that
yields a vector of K estimations where K is
amount of classes that framework will
have alternative to envision. This vector
contains probabilities for each class of any
image being described.
The last layer of the CNN configuration
uses a request layer, for instance, SoftMax
to give the plan yield.
2.2. Equipment Acceleration using
GPUs:
A convolutional neural system is prepared
on hundreds, thousands, or even a huge
number of pictures. When working with a
lot of information and complex system
designs, GPUs can essentially speed the
preparing time to prepare a model. When
CNN is prepared, it very well may be
utilized progressively applications, for
example, walker recognition in cutting
edge driver help frameworks.
3.Simulation:
The dataset used for training the model
contains 15800 pictures of four shapes;
square, star, circle, and triangle. Each
picture is of 200x200 pixels. There are
3720 images per each shape used; this
dataset was retrieved from Kaggle
database (Johannes Rieke., Jun 12, 2017).
Figure:4 Dataset samples.
features that especially portray the
subject.
CNNs perform highlight recognizable
proof and order of pictures, content,
sound, and recording.
Just as other neural systems, this is
made out of information layer, a yield
layer, and many concealed layers in the
middle.
Figure:3 Neural Network.
These layers perform tasks that change the
information with the aim of learning
highlights explicit to the information.
Three of the most widely recognized layers
are: convolution, actuation, and pooling.
Convolution gets the info pictures through
a lot of convolutional channels, every one
of which enacts certain highlights from
pictures.
Amended straight unit considers quicker
and increasingly powerful preparing by
mapping negative qualities to zero and
keeping up positive qualities. This is once
in a while alluded to as actuation, in light
of the fact that solitary initiated highlights
are conveyed forward into following layer.
Pooling: rearranges yield by performing
nonlinear down sampling and decreasing
quantity of parameters that system needs
to learn.
So tasks are rehashed more than tens or
several layers, with each layer figuring out
how to distinguish various highlights.
se activities are rehashed more than tens or
many layers, with each layer figuring out
how to distinguish various highlights.
2.1. Classification of layers:
In the wake of learning highlights in
numerous layers, the design of a CNN
movements to arrangement.
Near last layer is a totally related layer that
yields a vector of K estimations where K is
amount of classes that framework will
have alternative to envision. This vector
contains probabilities for each class of any
image being described.
The last layer of the CNN configuration
uses a request layer, for instance, SoftMax
to give the plan yield.
2.2. Equipment Acceleration using
GPUs:
A convolutional neural system is prepared
on hundreds, thousands, or even a huge
number of pictures. When working with a
lot of information and complex system
designs, GPUs can essentially speed the
preparing time to prepare a model. When
CNN is prepared, it very well may be
utilized progressively applications, for
example, walker recognition in cutting
edge driver help frameworks.
3.Simulation:
The dataset used for training the model
contains 15800 pictures of four shapes;
square, star, circle, and triangle. Each
picture is of 200x200 pixels. There are
3720 images per each shape used; this
dataset was retrieved from Kaggle
database (Johannes Rieke., Jun 12, 2017).
Figure:4 Dataset samples.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Simulation was done with the help of
Matlab. A code was made to do the
following tasks in Matlab and after that
results were obtained. Simulation was
based on CNN.
Loading of the dataset on Matlab.
Resetting the dataset of all shapes
in equal numbers.
Verify pictures labels.
Characterize the system design
based on CNN.
Setting 70 percent dataset for
training, 10 percent dataset for
validation and 20 percent dataset
for testing the system.
First the system was trained, its
parameter was set. The whole
process took some time. Training
process was based on CNN; it used
randomly 70 percent of the entire
dataset to train the system. The
CPU consumption increases during
the training process, because it
continued the iterations until the
desired results were achieved.
After training, validation was
started to check the training
outcome, this took less time
because validation dataset was only
10 percent of the entire dataset.
After validation was completed, it
compared the result with the
training outcomes and accuracy
was computed.
In the last after all the training and
the validation outcomes, the trained
model was tested with 20 percent
of the dataset. Testing was done in
order to verify the system accuracy,
for the purpose Confusion Matrix
was used in order to verify the
trained model accuracy.
3. Results Obtained:
Convolutional neural systems are basic
devices for profound learning, and are
particularly appropriate for picture
acknowledgment.
NNs give an ideal engineering to
picture acknowledgment and example
recognition. Joined with propels in
GPUs and equal processing, CNNs are
a key innovation fundamental new
improvement in computerized driving
and facial acknowledgment.
Indicate Training Sets, Validation Sets
and Testing Sets:
From almost 15800 pictures, 70 percent is
set for training, 10 percent for validations
and 20 percent for testing.
Architecture:
Characterize the convolution neural system
engineering.
Determine Training Options:
In the wake of characterizing the system
structure, determine the preparation
alternatives. Train the system utilizing
stochastic slope plummet with energy with
an underlying learning pace of 0.01. Set
the most extreme number of ages to 4. An
age is a full preparing cycle on the whole
preparing informational index. Screen the
system precision during preparing by
indicating approval information and
approval recurrence. Mix the information
at each age. The product prepares the
system
on the preparation information and
ascertains the exactness on the approval
information at standard interims during
preparing. The approval information isn't
utilized to refresh the system loads.
Train Network Using Training Data:
Matlab. A code was made to do the
following tasks in Matlab and after that
results were obtained. Simulation was
based on CNN.
Loading of the dataset on Matlab.
Resetting the dataset of all shapes
in equal numbers.
Verify pictures labels.
Characterize the system design
based on CNN.
Setting 70 percent dataset for
training, 10 percent dataset for
validation and 20 percent dataset
for testing the system.
First the system was trained, its
parameter was set. The whole
process took some time. Training
process was based on CNN; it used
randomly 70 percent of the entire
dataset to train the system. The
CPU consumption increases during
the training process, because it
continued the iterations until the
desired results were achieved.
After training, validation was
started to check the training
outcome, this took less time
because validation dataset was only
10 percent of the entire dataset.
After validation was completed, it
compared the result with the
training outcomes and accuracy
was computed.
In the last after all the training and
the validation outcomes, the trained
model was tested with 20 percent
of the dataset. Testing was done in
order to verify the system accuracy,
for the purpose Confusion Matrix
was used in order to verify the
trained model accuracy.
3. Results Obtained:
Convolutional neural systems are basic
devices for profound learning, and are
particularly appropriate for picture
acknowledgment.
NNs give an ideal engineering to
picture acknowledgment and example
recognition. Joined with propels in
GPUs and equal processing, CNNs are
a key innovation fundamental new
improvement in computerized driving
and facial acknowledgment.
Indicate Training Sets, Validation Sets
and Testing Sets:
From almost 15800 pictures, 70 percent is
set for training, 10 percent for validations
and 20 percent for testing.
Architecture:
Characterize the convolution neural system
engineering.
Determine Training Options:
In the wake of characterizing the system
structure, determine the preparation
alternatives. Train the system utilizing
stochastic slope plummet with energy with
an underlying learning pace of 0.01. Set
the most extreme number of ages to 4. An
age is a full preparing cycle on the whole
preparing informational index. Screen the
system precision during preparing by
indicating approval information and
approval recurrence. Mix the information
at each age. The product prepares the
system
on the preparation information and
ascertains the exactness on the approval
information at standard interims during
preparing. The approval information isn't
utilized to refresh the system loads.
Train Network Using Training Data:
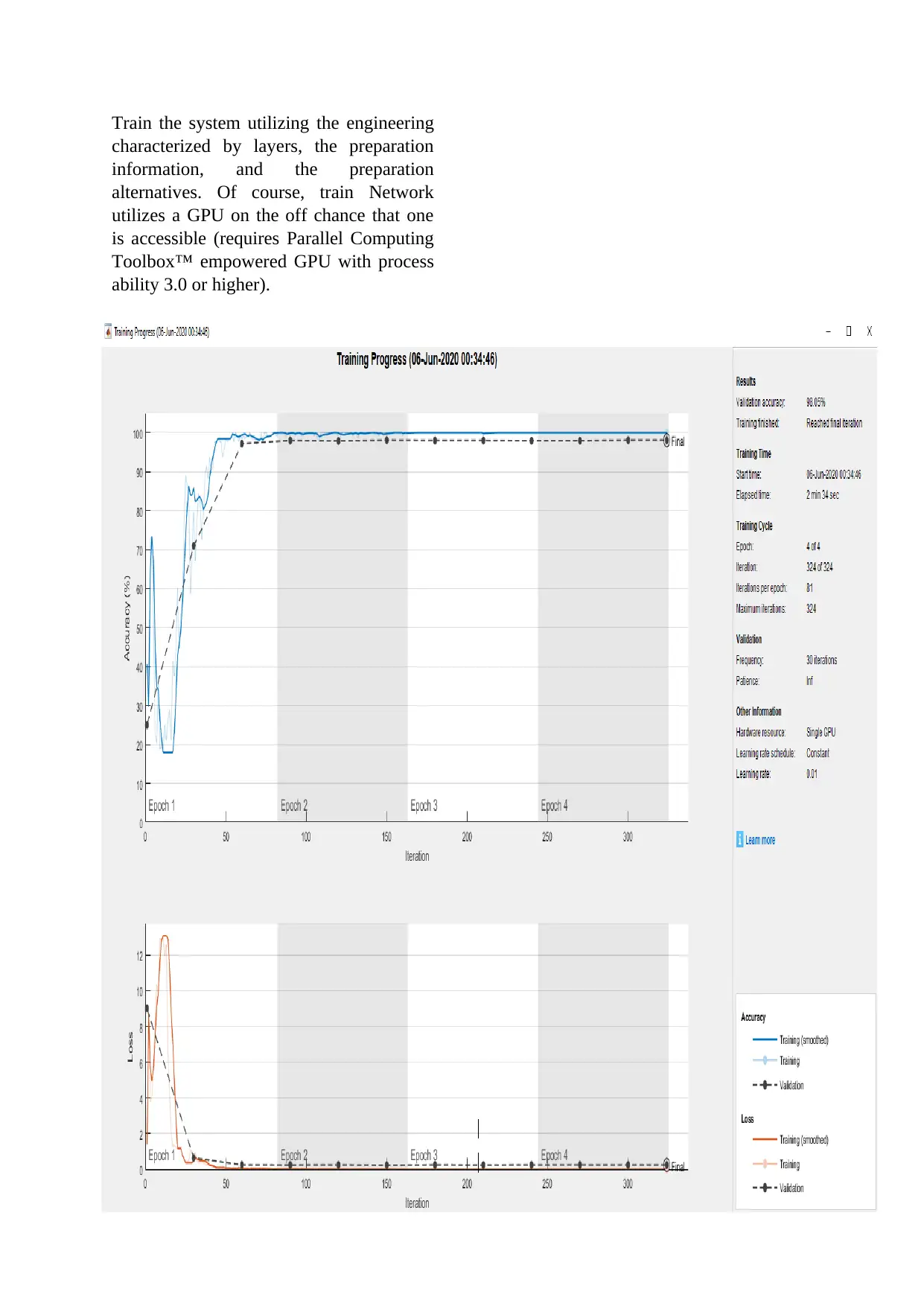
Train the system utilizing the engineering
characterized by layers, the preparation
information, and the preparation
alternatives. Of course, train Network
utilizes a GPU on the off chance that one
is accessible (requires Parallel Computing
Toolbox™ empowered GPU with process
ability 3.0 or higher).
characterized by layers, the preparation
information, and the preparation
alternatives. Of course, train Network
utilizes a GPU on the off chance that one
is accessible (requires Parallel Computing
Toolbox™ empowered GPU with process
ability 3.0 or higher).
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Figure:5 Training and Validation simulation.
Characterize Validation Images and
Compute Accuracy:
Foresee the marks of the approval
information utilizing the prepared system,
and figure the last approval exactness.
Precision is the part of names that the
system predicts effectively.
Else, it utilizes a CPU.
You can likewise determine the execution
condition by utilizing the 'Execution
Environment' name-esteem pair contention
of training Options.
The preparation progress plot shows the
smaller than normal cluster misfortune and
exactness and the approval misfortune and
precision. Graph shows the training
process results:
For this situation, over 98.19% of the
anticipated marks coordinate the genuine
names of the approval set.
The accuracy achieved in the above system
is shown below in the form of confusion
matrix:
The digit classes with most elevated
exactness have a mean near zero and little
change. Matrix gives the target class
calculations and output class calculations.
Now we can test the performance of the
network by evaluating the accuracy on the
validation data using confusion matrix.
4. Critical analysis of the result:
4.1. Analysis through Graph: Obtained
graph shows that the accuracy achieved
while training increases as the number of
iterations increase. Accuracy percentage
started from 25% and reached 80% in the
first 3 iterations.
Then the graph line moves towards 95%
when it reaches toward 75 iterations.
After 80 iterations graph is stabilized until
the final position (324 iterations). Result
shows that validation accuracy is 98.2%
until it reaches final iteration.
The starting time of the training was 11-
may-2020 23:33:45 and training took 1
min and 45 seconds to be completed.
Iterations per Epoch were 81 and
frequency of the training is calculated to
be 30 iterations.
The other graph shows the loss which was
2 at the beginning and suddenly increased
to 11 only in 20-30 iterations.
After that a great fall can be seen in the
graph which starts from 11 to 0 until the
50th iteration.
Then the graph is stabilized till the final
destination within 324 iterations.
Sno Accuracy Percent
1 Validation 98.05
2 Testing 97.55
Table 1: Accuracy results by comparing
with training.
4.2. Analysis through Matrix: Confusion
matrix is describing the overall
performance of the Convolutional Neural
Network based shape detector system.
Characterize Validation Images and
Compute Accuracy:
Foresee the marks of the approval
information utilizing the prepared system,
and figure the last approval exactness.
Precision is the part of names that the
system predicts effectively.
Else, it utilizes a CPU.
You can likewise determine the execution
condition by utilizing the 'Execution
Environment' name-esteem pair contention
of training Options.
The preparation progress plot shows the
smaller than normal cluster misfortune and
exactness and the approval misfortune and
precision. Graph shows the training
process results:
For this situation, over 98.19% of the
anticipated marks coordinate the genuine
names of the approval set.
The accuracy achieved in the above system
is shown below in the form of confusion
matrix:
The digit classes with most elevated
exactness have a mean near zero and little
change. Matrix gives the target class
calculations and output class calculations.
Now we can test the performance of the
network by evaluating the accuracy on the
validation data using confusion matrix.
4. Critical analysis of the result:
4.1. Analysis through Graph: Obtained
graph shows that the accuracy achieved
while training increases as the number of
iterations increase. Accuracy percentage
started from 25% and reached 80% in the
first 3 iterations.
Then the graph line moves towards 95%
when it reaches toward 75 iterations.
After 80 iterations graph is stabilized until
the final position (324 iterations). Result
shows that validation accuracy is 98.2%
until it reaches final iteration.
The starting time of the training was 11-
may-2020 23:33:45 and training took 1
min and 45 seconds to be completed.
Iterations per Epoch were 81 and
frequency of the training is calculated to
be 30 iterations.
The other graph shows the loss which was
2 at the beginning and suddenly increased
to 11 only in 20-30 iterations.
After that a great fall can be seen in the
graph which starts from 11 to 0 until the
50th iteration.
Then the graph is stabilized till the final
destination within 324 iterations.
Sno Accuracy Percent
1 Validation 98.05
2 Testing 97.55
Table 1: Accuracy results by comparing
with training.
4.2. Analysis through Matrix: Confusion
matrix is describing the overall
performance of the Convolutional Neural
Network based shape detector system.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
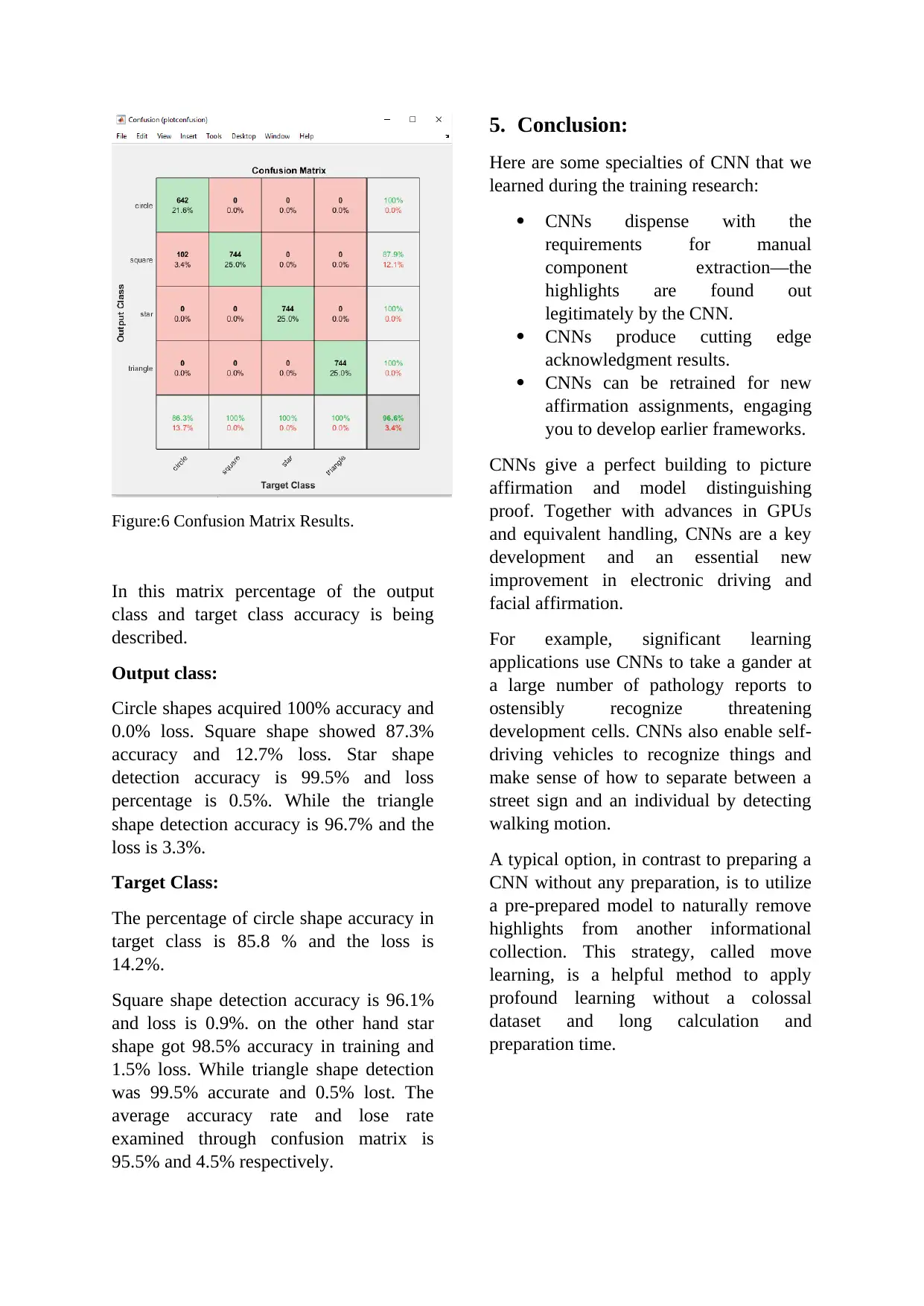
Figure:6 Confusion Matrix Results.
In this matrix percentage of the output
class and target class accuracy is being
described.
Output class:
Circle shapes acquired 100% accuracy and
0.0% loss. Square shape showed 87.3%
accuracy and 12.7% loss. Star shape
detection accuracy is 99.5% and loss
percentage is 0.5%. While the triangle
shape detection accuracy is 96.7% and the
loss is 3.3%.
Target Class:
The percentage of circle shape accuracy in
target class is 85.8 % and the loss is
14.2%.
Square shape detection accuracy is 96.1%
and loss is 0.9%. on the other hand star
shape got 98.5% accuracy in training and
1.5% loss. While triangle shape detection
was 99.5% accurate and 0.5% lost. The
average accuracy rate and lose rate
examined through confusion matrix is
95.5% and 4.5% respectively.
5. Conclusion:
Here are some specialties of CNN that we
learned during the training research:
CNNs dispense with the
requirements for manual
component extraction—the
highlights are found out
legitimately by the CNN.
CNNs produce cutting edge
acknowledgment results.
CNNs can be retrained for new
affirmation assignments, engaging
you to develop earlier frameworks.
CNNs give a perfect building to picture
affirmation and model distinguishing
proof. Together with advances in GPUs
and equivalent handling, CNNs are a key
development and an essential new
improvement in electronic driving and
facial affirmation.
For example, significant learning
applications use CNNs to take a gander at
a large number of pathology reports to
ostensibly recognize threatening
development cells. CNNs also enable self-
driving vehicles to recognize things and
make sense of how to separate between a
street sign and an individual by detecting
walking motion.
A typical option, in contrast to preparing a
CNN without any preparation, is to utilize
a pre-prepared model to naturally remove
highlights from another informational
collection. This strategy, called move
learning, is a helpful method to apply
profound learning without a colossal
dataset and long calculation and
preparation time.
In this matrix percentage of the output
class and target class accuracy is being
described.
Output class:
Circle shapes acquired 100% accuracy and
0.0% loss. Square shape showed 87.3%
accuracy and 12.7% loss. Star shape
detection accuracy is 99.5% and loss
percentage is 0.5%. While the triangle
shape detection accuracy is 96.7% and the
loss is 3.3%.
Target Class:
The percentage of circle shape accuracy in
target class is 85.8 % and the loss is
14.2%.
Square shape detection accuracy is 96.1%
and loss is 0.9%. on the other hand star
shape got 98.5% accuracy in training and
1.5% loss. While triangle shape detection
was 99.5% accurate and 0.5% lost. The
average accuracy rate and lose rate
examined through confusion matrix is
95.5% and 4.5% respectively.
5. Conclusion:
Here are some specialties of CNN that we
learned during the training research:
CNNs dispense with the
requirements for manual
component extraction—the
highlights are found out
legitimately by the CNN.
CNNs produce cutting edge
acknowledgment results.
CNNs can be retrained for new
affirmation assignments, engaging
you to develop earlier frameworks.
CNNs give a perfect building to picture
affirmation and model distinguishing
proof. Together with advances in GPUs
and equivalent handling, CNNs are a key
development and an essential new
improvement in electronic driving and
facial affirmation.
For example, significant learning
applications use CNNs to take a gander at
a large number of pathology reports to
ostensibly recognize threatening
development cells. CNNs also enable self-
driving vehicles to recognize things and
make sense of how to separate between a
street sign and an individual by detecting
walking motion.
A typical option, in contrast to preparing a
CNN without any preparation, is to utilize
a pre-prepared model to naturally remove
highlights from another informational
collection. This strategy, called move
learning, is a helpful method to apply
profound learning without a colossal
dataset and long calculation and
preparation time.

This methodology gives us the most
command over the system and can create
amazing outcomes, yet it requires a
comprehension of the structure of a neural
system and the numerous alternatives for
layer types and arrangement.
While results can sometimes surpass move
learning, this strategy will in general
require more pictures for preparation, as
the new system needs numerous instances
of the item to comprehend the variety of
highlights. Preparation times are regularly
more, and there are such a large number of
blends of system layers that it tends to be
overpowering to arrange a system without
any preparation. Commonly, while
building a system and arranging the layers,
it assists with referencing other system
arrangements to exploit what specialists
have demonstrated fruitful.
There are numerous approaches to
compute the characterization precision on
the ImageNet approval set and various
sources utilize various techniques. Now
and again an outfit of different models is
utilized and now and then each picture is
assessed on various occasions utilizing
numerous harvests. Once in a while the
main 5 exactness rather than the norm
(top-1) precision is cited. In light of these
distinctions, it is regularly impractical to
legitimately analyze the errors from
various sources.
Attempt highlights extraction when your
new informational index is extremely little.
Since you just train a basic classifier on the
separated highlights, preparation is quick.
It is additionally improbable that tweaking
further layers of the system improves the
exactness since there is little information
to gain from.
In the event that your information is
fundamentally the same as the first
information, the more explicit highlights
extricated further in the system are
probably going to be helpful for the new
undertaking.
On the off chance that your information is
altogether different from the first
information, the highlights separated
further in the system may be less valuable
for your errand. Give preparing the last
classifier shot progressively broad
highlights extricated from a previous
system layer. In the event that the new
informational collection is enormous, at
that point you can likewise have a go at
preparing a system without any
preparation. The basic learning’s of this
research report are:
Load and investigate picture
information.
Characterize the system
engineering.
Indicate preparing choices.
Train the system.
Foresee the marks of new
information and ascertain the
arrangement precision.
You should determine the size of the
pictures in the information layer of the
system.
Train the system utilizing the engineering
characterized by layers, the preparation
information, and the preparation
alternatives. Of course, train Network
utilizes a GPU in the event that one is
accessible.
The preparation progress plot shows the
smaller than expected group misfortune
and exactness and the approval misfortune
and precision. For more data on the
preparation progress plot, see Monitor
Deep Learning Training Progress. The
misfortune is the cross-entropy misfortune.
The exactness is the level of pictures that
the system characterizes accurately.
command over the system and can create
amazing outcomes, yet it requires a
comprehension of the structure of a neural
system and the numerous alternatives for
layer types and arrangement.
While results can sometimes surpass move
learning, this strategy will in general
require more pictures for preparation, as
the new system needs numerous instances
of the item to comprehend the variety of
highlights. Preparation times are regularly
more, and there are such a large number of
blends of system layers that it tends to be
overpowering to arrange a system without
any preparation. Commonly, while
building a system and arranging the layers,
it assists with referencing other system
arrangements to exploit what specialists
have demonstrated fruitful.
There are numerous approaches to
compute the characterization precision on
the ImageNet approval set and various
sources utilize various techniques. Now
and again an outfit of different models is
utilized and now and then each picture is
assessed on various occasions utilizing
numerous harvests. Once in a while the
main 5 exactness rather than the norm
(top-1) precision is cited. In light of these
distinctions, it is regularly impractical to
legitimately analyze the errors from
various sources.
Attempt highlights extraction when your
new informational index is extremely little.
Since you just train a basic classifier on the
separated highlights, preparation is quick.
It is additionally improbable that tweaking
further layers of the system improves the
exactness since there is little information
to gain from.
In the event that your information is
fundamentally the same as the first
information, the more explicit highlights
extricated further in the system are
probably going to be helpful for the new
undertaking.
On the off chance that your information is
altogether different from the first
information, the highlights separated
further in the system may be less valuable
for your errand. Give preparing the last
classifier shot progressively broad
highlights extricated from a previous
system layer. In the event that the new
informational collection is enormous, at
that point you can likewise have a go at
preparing a system without any
preparation. The basic learning’s of this
research report are:
Load and investigate picture
information.
Characterize the system
engineering.
Indicate preparing choices.
Train the system.
Foresee the marks of new
information and ascertain the
arrangement precision.
You should determine the size of the
pictures in the information layer of the
system.
Train the system utilizing the engineering
characterized by layers, the preparation
information, and the preparation
alternatives. Of course, train Network
utilizes a GPU in the event that one is
accessible.
The preparation progress plot shows the
smaller than expected group misfortune
and exactness and the approval misfortune
and precision. For more data on the
preparation progress plot, see Monitor
Deep Learning Training Progress. The
misfortune is the cross-entropy misfortune.
The exactness is the level of pictures that
the system characterizes accurately.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

In PC vision and picture handling, shape
detection is an extremely critical wonder
and this paper presents a method that
utilizes different shapes by recognizing the
edges in pictures utilizing CNN approach.
CNN strategy is utilized into this issue
since it is far more predominant than the
customary slope-based strategies for edge
identification. The CNN based technique is
incredible and gives exact edge maps
paying little mind to the brightening and
clamor states of pictures.
Along these lines, this methodology for
edge recognition is dependable when
contrasted with past strategies as its
exhibition is autonomous of light settings
and commotion states of caught pictures.
Moreover, CNN based strategy is liberated
from manual component extraction not at
all like the traditional methodologies
which make this methodology basic and
quick. We have explored four kinds of
shapes for distinguishing the edges and
results demonstrated improved outcomes
when contrasted with the old-style
techniques where execution debases when
the geometry of edges in the pictures
shifts. In future, we are engaged to fuse
distinctive edge administrators into our
procedure so as to check the impact of
CNN coordinate with numerous
administrators on the conclusive outcomes.
References:
[1] Seungmok Yoo, Seokjin Yoon, 22
September 2019, Volume41, Issue6,
Pages 760-770.
https://onlinelibrary.wiley.com/doi/
10.4218/etrij.2018-0135
[2] Kyomin Jung, Deep Learning for
the Web, May 2015, Pages 1525–1526.
https://dl.acm.org/doi/abs/
10.1145/2742740.2741982
[3] Smeschke , June 2017 , “Four
Shapes”; Dataset.
https://www.kaggle.com/smeschke/
four-shapes
[4] Russakovsky, O., Deng, J., Su, H.,
et al. “ImageNet Large Scale Visual
Recognition Challenge.” International
Journal of Computer Vision (IJCV).
Vol 115, Issue 3, 2015, pp. 211–252
https://arxiv.org/pdf/1409.0575.pdf
[5] Yung-Cheol Byun,” Edge
Detection using CNN”, Journal of
ACM digital library; January 2019;
Pages 75–78.
https://dl.acm.org/doi/abs/
10.1145/3314527.3314544
[6] Johannes Rieke,” Object detection
with neural networks — a simple tutorial
using keras”; Jun 12, 2017.
https://towardsdatascience.com/object-
detection-with-neural-networks-
a4e2c46b4491
detection is an extremely critical wonder
and this paper presents a method that
utilizes different shapes by recognizing the
edges in pictures utilizing CNN approach.
CNN strategy is utilized into this issue
since it is far more predominant than the
customary slope-based strategies for edge
identification. The CNN based technique is
incredible and gives exact edge maps
paying little mind to the brightening and
clamor states of pictures.
Along these lines, this methodology for
edge recognition is dependable when
contrasted with past strategies as its
exhibition is autonomous of light settings
and commotion states of caught pictures.
Moreover, CNN based strategy is liberated
from manual component extraction not at
all like the traditional methodologies
which make this methodology basic and
quick. We have explored four kinds of
shapes for distinguishing the edges and
results demonstrated improved outcomes
when contrasted with the old-style
techniques where execution debases when
the geometry of edges in the pictures
shifts. In future, we are engaged to fuse
distinctive edge administrators into our
procedure so as to check the impact of
CNN coordinate with numerous
administrators on the conclusive outcomes.
References:
[1] Seungmok Yoo, Seokjin Yoon, 22
September 2019, Volume41, Issue6,
Pages 760-770.
https://onlinelibrary.wiley.com/doi/
10.4218/etrij.2018-0135
[2] Kyomin Jung, Deep Learning for
the Web, May 2015, Pages 1525–1526.
https://dl.acm.org/doi/abs/
10.1145/2742740.2741982
[3] Smeschke , June 2017 , “Four
Shapes”; Dataset.
https://www.kaggle.com/smeschke/
four-shapes
[4] Russakovsky, O., Deng, J., Su, H.,
et al. “ImageNet Large Scale Visual
Recognition Challenge.” International
Journal of Computer Vision (IJCV).
Vol 115, Issue 3, 2015, pp. 211–252
https://arxiv.org/pdf/1409.0575.pdf
[5] Yung-Cheol Byun,” Edge
Detection using CNN”, Journal of
ACM digital library; January 2019;
Pages 75–78.
https://dl.acm.org/doi/abs/
10.1145/3314527.3314544
[6] Johannes Rieke,” Object detection
with neural networks — a simple tutorial
using keras”; Jun 12, 2017.
https://towardsdatascience.com/object-
detection-with-neural-networks-
a4e2c46b4491
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

1 out of 11

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.