Data Analysis of Netflix Viewers: Assignment and Report
VerifiedAdded on 2023/01/04
|11
|2016
|40
Homework Assignment
AI Summary
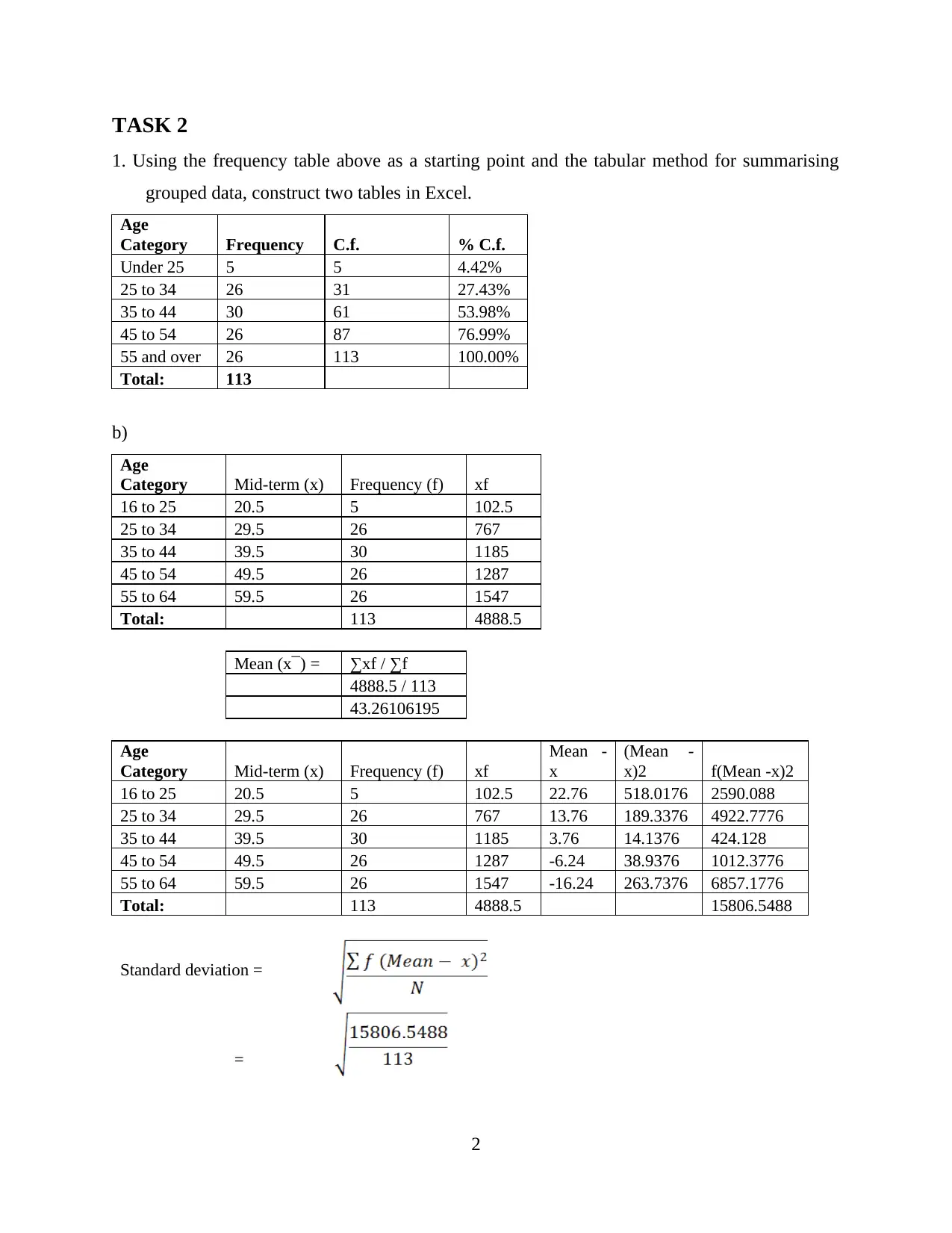
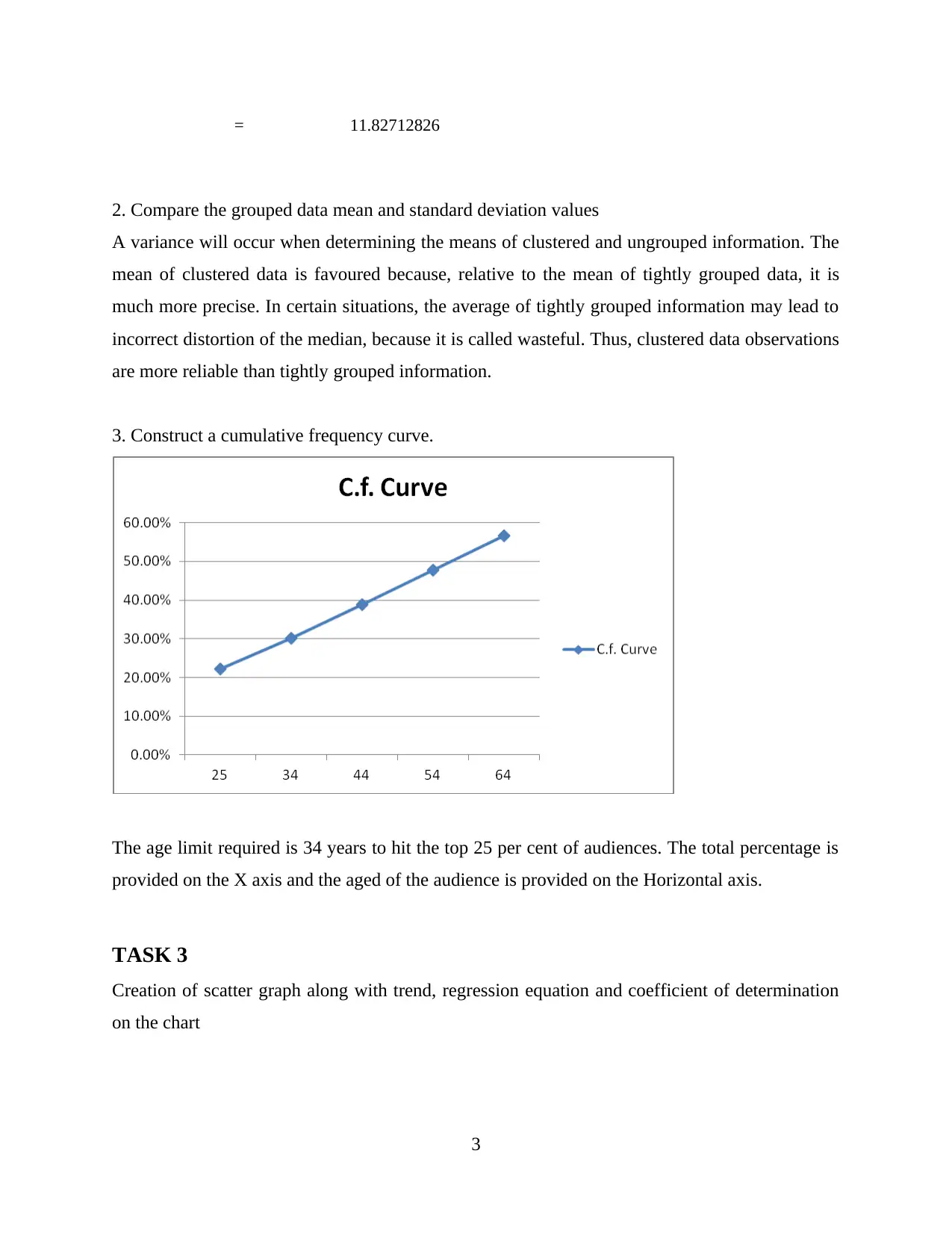
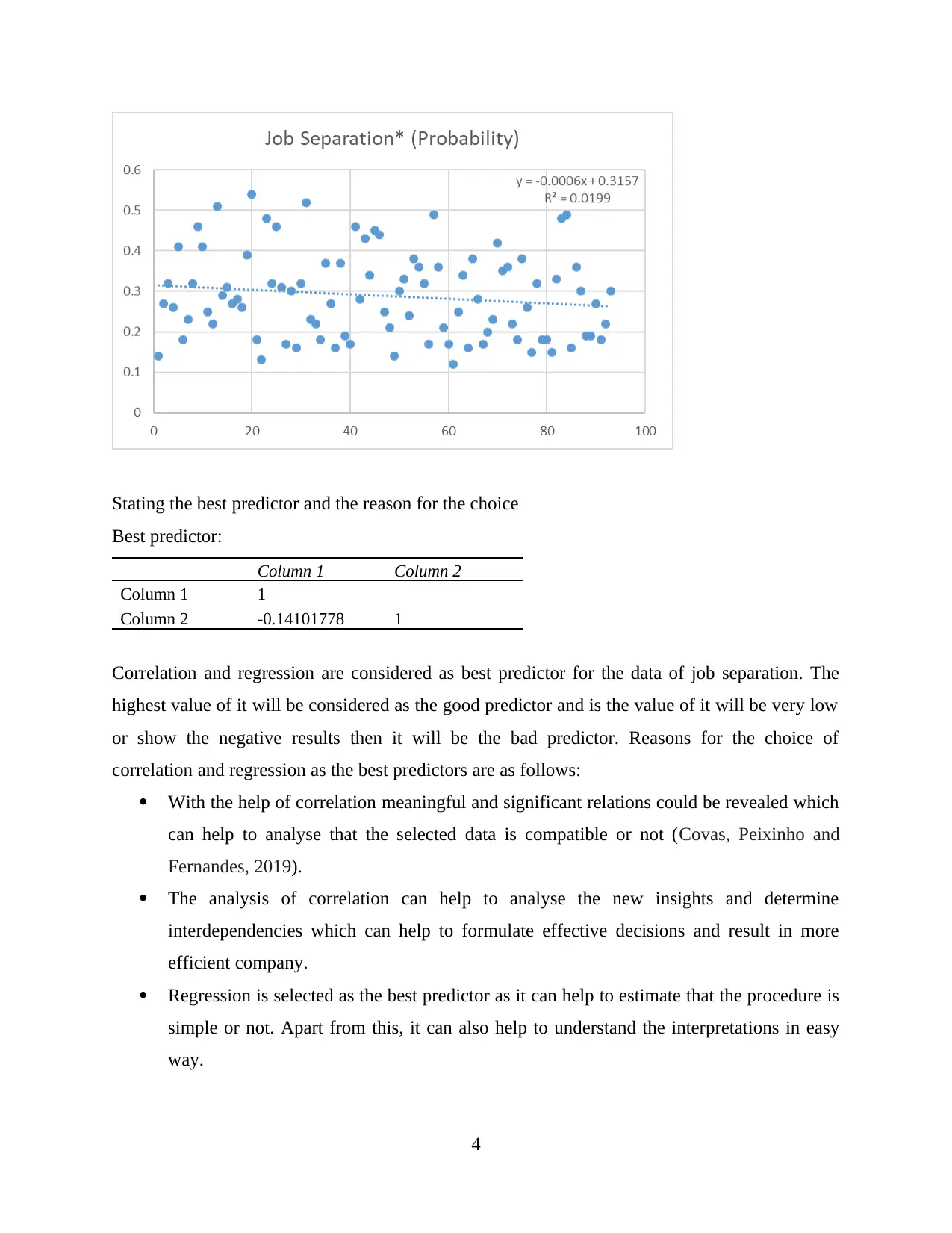
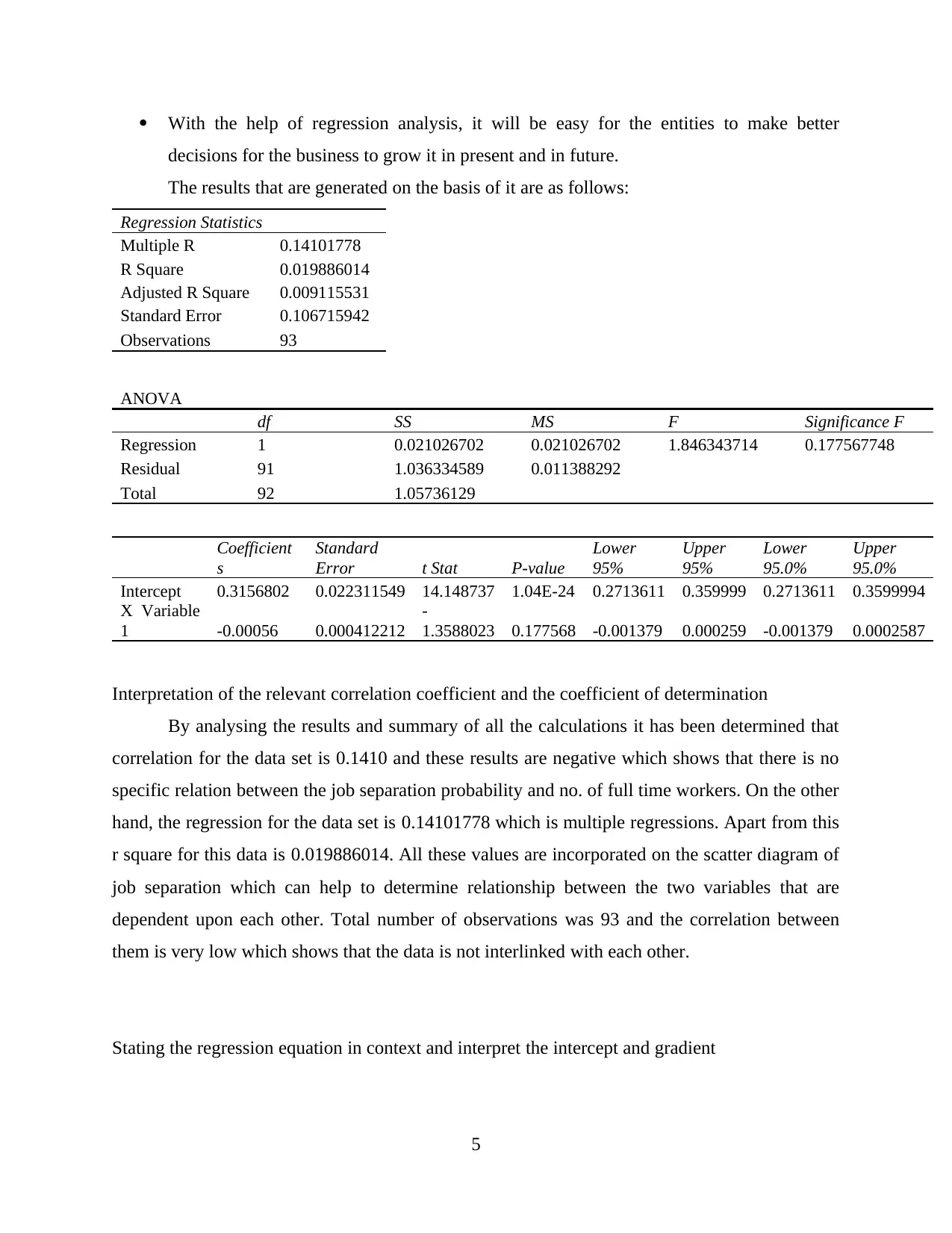
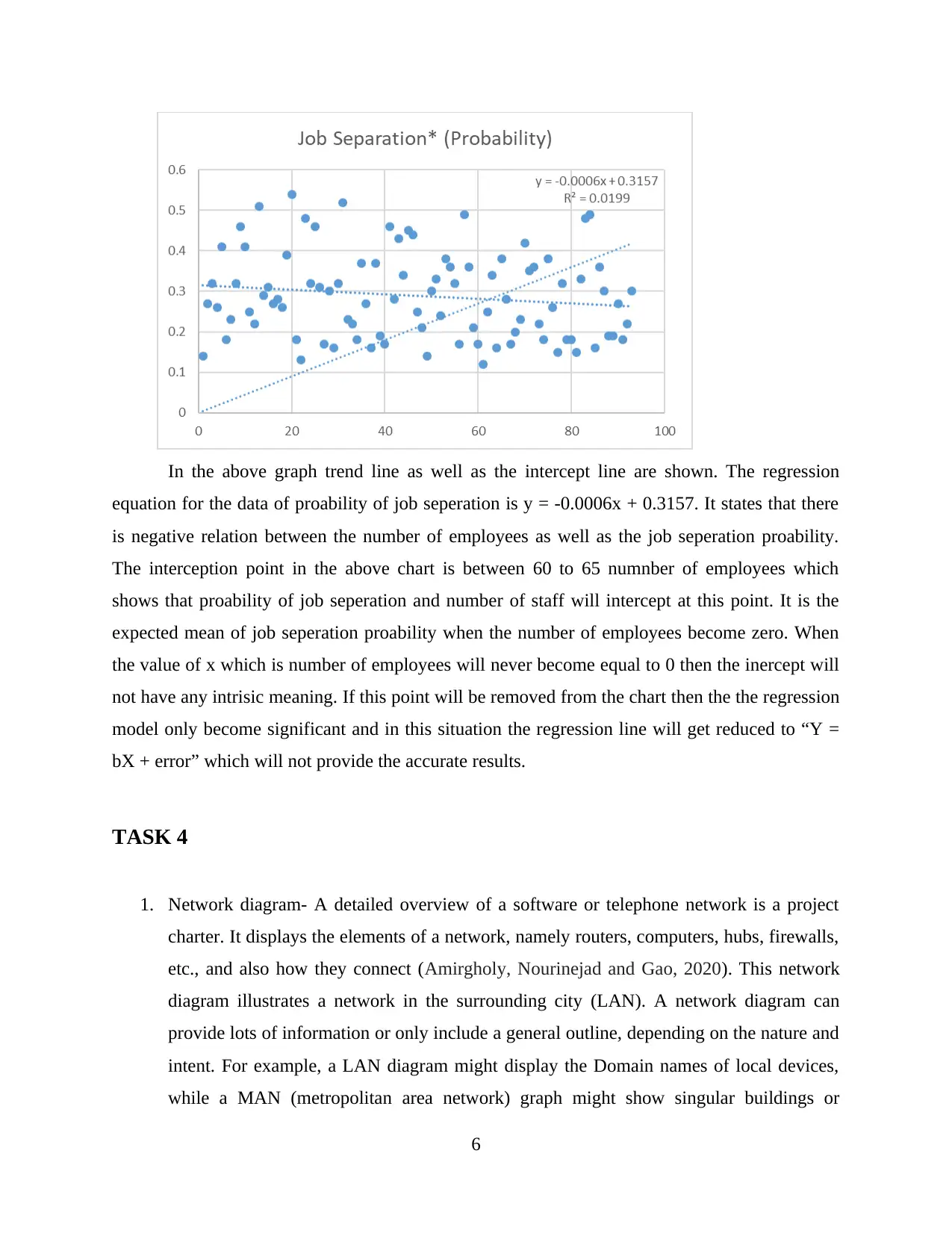
This assignment presents a comprehensive analysis of Netflix viewer data, encompassing various statistical methods and practical applications. The analysis begins with calculating descriptive statistics such as mean, standard deviation, and coefficient of variance to understand the age distribution of Netflix viewers. It then progresses to creating frequency tables and cumulative frequency curves to analyze grouped data, comparing grouped and ungrouped data means and standard deviations. A significant portion of the assignment focuses on creating scatter graphs, calculating regression equations, and determining the coefficient of determination to identify the best predictor of job separation. The report interprets the correlation coefficient and regression equation within the context of the data. Furthermore, the assignment includes the construction of network diagrams and critical path analysis to illustrate network structures and project timelines. The student reflects on the assignment, highlighting strengths, challenges, and areas for improvement, providing a detailed overview of the process and findings.






1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
© 2024 | Zucol Services PVT LTD | All rights reserved.