Report on Twitter Spam Detection Using Machine Learning Techniques
VerifiedAdded on 2022/09/28
|8
|2310
|20
Report
AI Summary
This report investigates Twitter spam detection using machine learning algorithms. It addresses the challenge of identifying spammers and fake messages on the platform. The study utilizes data mining techniques and machine learning algorithms, including Naive Bayes, KNN, and Random Forest classifiers, to analyze and classify tweets. The methodology involves data preprocessing, feature extraction, and model evaluation based on precision, recall, accuracy, and F-measure. The report also includes a literature review on existing spam detection methods and presents a detailed analysis of the algorithms, their performance, and evaluation parameters. The report concludes with a discussion of the findings and potential future research directions in the field of Twitter spam detection. The assignment was completed for the NIT3202 Data Analytics for Cyber Security course, and the student achieved 100% accuracy on their test data.

TWITTER SPAM DETECTION
ABSTRACT
The fame of internet-based life has quickly expanded in past because of the assortment of
administrations and advantages by it to the clients. Be that as it may, one next to the other it is
likewise overwhelmed with spam, malevolent messages, post phishing joins, counterfeit records
and considerably more. One of these well-known social stages is twitter, which has picked up
prevalence because of the expansion in social exercises of enlisted clients. Twitter performs
double capacities going about as a small-scale blogging OSN (online informal community), and
simultaneously as a news update stage. And this growth in twitter social media interaction has
attracted attention of cybercriminals also. In this report we are going to discuss about the
techniques of identifying such twitter spam tweets and fake messages. Scientists have proposed
different ways to deal with distinguish the group of spammers and each is not the same as the
other in interesting manner. This report introduces a different way to detect such spammers.
Problem Statement
The serious issue managed this examination is that there is no real ground truth that is enormous
for this specific investigation. We direct an investigation to break down and think about the
classifiers in MLAs, and thus we gather an informational index from Follow the hash label where
they have marked informational indexes each containing in excess of 150000 tweets and
removed nineteen highlights, from which we utilize 3 highlights for dissecting the information in
MLA and utilized 5 highlights in the following the historical backdrop of tweets by the client.
The three machine calculations are Naive Bayes, KNN and Random Forest. After the
arrangement done by the MLA, we take dataset and check an individual's past tweets to check on
the off chance that he has been routinely spamming.
INTRODUCTION
Data mining manages extraction of supportive information from huge measures of learning. A
few elective terms are becoming acclimated to realize information mining, such as mining of
information from databases, learning extraction, data investigation, and data humanities. The
information mining procedures of arrangement, bunch and affiliation encourage in separating
learning from an out estimated amount information. AI could be a rising field associated with the
investigation of huge and different data. It's an investigation of how to perceive designs and is a
hypothesis learning process in Computerized reasoning and includes methods for preparing,
contains calculations and procedures for examination of information. Twitter is a quickly
developing web-based life. Twitter is a smaller scale blogging webpage where clients can post
their messages, which is known as tweets. The significant drawback that is looked by clients
abusing these various systems administration destinations is of Spam. Spam is typically spoken
to as unsought, rehashed activities that contrarily sway others. This incorporates a few styles of
machine-driven record connections and conduct additionally as makes an endeavor to misdirects
or bamboozles people Spam legitimately or in a roundabout way abuses the definite standards of
ABSTRACT
The fame of internet-based life has quickly expanded in past because of the assortment of
administrations and advantages by it to the clients. Be that as it may, one next to the other it is
likewise overwhelmed with spam, malevolent messages, post phishing joins, counterfeit records
and considerably more. One of these well-known social stages is twitter, which has picked up
prevalence because of the expansion in social exercises of enlisted clients. Twitter performs
double capacities going about as a small-scale blogging OSN (online informal community), and
simultaneously as a news update stage. And this growth in twitter social media interaction has
attracted attention of cybercriminals also. In this report we are going to discuss about the
techniques of identifying such twitter spam tweets and fake messages. Scientists have proposed
different ways to deal with distinguish the group of spammers and each is not the same as the
other in interesting manner. This report introduces a different way to detect such spammers.
Problem Statement
The serious issue managed this examination is that there is no real ground truth that is enormous
for this specific investigation. We direct an investigation to break down and think about the
classifiers in MLAs, and thus we gather an informational index from Follow the hash label where
they have marked informational indexes each containing in excess of 150000 tweets and
removed nineteen highlights, from which we utilize 3 highlights for dissecting the information in
MLA and utilized 5 highlights in the following the historical backdrop of tweets by the client.
The three machine calculations are Naive Bayes, KNN and Random Forest. After the
arrangement done by the MLA, we take dataset and check an individual's past tweets to check on
the off chance that he has been routinely spamming.
INTRODUCTION
Data mining manages extraction of supportive information from huge measures of learning. A
few elective terms are becoming acclimated to realize information mining, such as mining of
information from databases, learning extraction, data investigation, and data humanities. The
information mining procedures of arrangement, bunch and affiliation encourage in separating
learning from an out estimated amount information. AI could be a rising field associated with the
investigation of huge and different data. It's an investigation of how to perceive designs and is a
hypothesis learning process in Computerized reasoning and includes methods for preparing,
contains calculations and procedures for examination of information. Twitter is a quickly
developing web-based life. Twitter is a smaller scale blogging webpage where clients can post
their messages, which is known as tweets. The significant drawback that is looked by clients
abusing these various systems administration destinations is of Spam. Spam is typically spoken
to as unsought, rehashed activities that contrarily sway others. This incorporates a few styles of
machine-driven record connections and conduct additionally as makes an endeavor to misdirects
or bamboozles people Spam legitimately or in a roundabout way abuses the definite standards of
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

any systems administration site. This paper in the principle centers around Examination of Spam
Identification in the Twitter by utilization of classifiers. The thought process of any spammer is
to bait his/her vindictive spam Oppressive answers to various clients. Posting copy and random
learning for tweets. Here we look at those utilizing AI calculations. There are differed
applications for AI, the first significance of that is information handling. AI along the edge of
information handling will for the most part be viably applied to such issues, as they improve the
power of the frameworks and their styles. A similar arrangement of alternatives is utilized for the
representation of each occasion, in any informational collection utilized by AI calculations.
These alternatives are frequently ceaseless, straight out or double. On the off chance that the
occasions are given with classification names or praised marks for example with the comparing
right yields, at that point the preparation is named managed learning, on the contrary hand comes
solo adapting, any place occurrences or class are unlabeled. Scientists would like to get stores of
information exploitation these regulated and unaided learning. Arrangement could be an
information preparing plays out that doles out things during a collection to concentrate on classes
or classifications. Information can be mined in different grouping approaches and AI calculations
are applied for Characterization of Spam Tweets. In Present days where there is a high increment
in the exercises of spammers, the achievement of pursuit benefits progressively and mining
apparatuses depends on the capacity break down and separate genuine tweets from the tweets
that are named spam. The classifiers utilized here are, Naive Bayes, K- Nearest Neighbor
(KNN), and Random Forest classifier. Their exhibition is then assessed dependent on exactness,
accuracy and F-measure.
CLASSIFICATION ALGORITHM
a) Naive Bayes: Naive Bayesian classifiers assume that there aren't any conditions among
the attributes. This is called prohibitive opportunity. It's made to unravel the taking care
of figuring concerned and along these lines called "unsophisticated". The classifier is in
like manner called simpleton Bayes, direct Bayes, or free Bayes.
The advantages of Naive Bayes are:
1. It utilizes a totally natural methodology. Bayes classifiers, as opposed to neural
systems, do now not have a few free.
2. Parameters that must be set. This fundamentally disentangles the format technique.
3. For the explanation that classifier returns conceivable outcomes, it is less hard to
watch these results to a tremendous assortment of obligations than if a self-assertive
scale changed into utilized.
b) KNN (K Nearest Neighbor) - The KNN (K-Closest Neighbor) calculation can be utilized
for both classification and regression. It is a nonparametric and furthermore an example
recognizer. In characterization and relapse, the information is the K nearest models in the
informational collection. The K-NN classifier is a kind of occasion-based learning. The
yield of KNN classifier is a class enrollment-based yield. Its characterized dependent on a
dominant part vote of neighbors in the informational index. The yield class is a solitary
Identification in the Twitter by utilization of classifiers. The thought process of any spammer is
to bait his/her vindictive spam Oppressive answers to various clients. Posting copy and random
learning for tweets. Here we look at those utilizing AI calculations. There are differed
applications for AI, the first significance of that is information handling. AI along the edge of
information handling will for the most part be viably applied to such issues, as they improve the
power of the frameworks and their styles. A similar arrangement of alternatives is utilized for the
representation of each occasion, in any informational collection utilized by AI calculations.
These alternatives are frequently ceaseless, straight out or double. On the off chance that the
occasions are given with classification names or praised marks for example with the comparing
right yields, at that point the preparation is named managed learning, on the contrary hand comes
solo adapting, any place occurrences or class are unlabeled. Scientists would like to get stores of
information exploitation these regulated and unaided learning. Arrangement could be an
information preparing plays out that doles out things during a collection to concentrate on classes
or classifications. Information can be mined in different grouping approaches and AI calculations
are applied for Characterization of Spam Tweets. In Present days where there is a high increment
in the exercises of spammers, the achievement of pursuit benefits progressively and mining
apparatuses depends on the capacity break down and separate genuine tweets from the tweets
that are named spam. The classifiers utilized here are, Naive Bayes, K- Nearest Neighbor
(KNN), and Random Forest classifier. Their exhibition is then assessed dependent on exactness,
accuracy and F-measure.
CLASSIFICATION ALGORITHM
a) Naive Bayes: Naive Bayesian classifiers assume that there aren't any conditions among
the attributes. This is called prohibitive opportunity. It's made to unravel the taking care
of figuring concerned and along these lines called "unsophisticated". The classifier is in
like manner called simpleton Bayes, direct Bayes, or free Bayes.
The advantages of Naive Bayes are:
1. It utilizes a totally natural methodology. Bayes classifiers, as opposed to neural
systems, do now not have a few free.
2. Parameters that must be set. This fundamentally disentangles the format technique.
3. For the explanation that classifier returns conceivable outcomes, it is less hard to
watch these results to a tremendous assortment of obligations than if a self-assertive
scale changed into utilized.
b) KNN (K Nearest Neighbor) - The KNN (K-Closest Neighbor) calculation can be utilized
for both classification and regression. It is a nonparametric and furthermore an example
recognizer. In characterization and relapse, the information is the K nearest models in the
informational collection. The K-NN classifier is a kind of occasion-based learning. The
yield of KNN classifier is a class enrollment-based yield. Its characterized dependent on a
dominant part vote of neighbors in the informational index. The yield class is a solitary

closest neighbor when the estimation of K is one. In different situations where it is basic
weighting plan, 1/d is the separation appointed to a load all things considered. The KNN
classifier comprises of Euclidean Distance is the briefest separation between any two
neighbors is constantly a straight line. The KNN calculation is touchy to the nearby
arrangement of the information.
c) Random Forest-Random forests is a collection of tree predictors so everyone depends on
the resultant estimations of an irregular vector that are tested naturally where the
circulation closeness of the considerable number of brambles is inside the woodland. The
arbitrary backwoods calculation for forecast can be clarified as:
1. Utilizing interesting examples data draws tree bootstrap.
2. For every one of the bootstrap tests produce an unprinted classification tree, by method
for following change: at every hub, rather of choosing the top of the line split among
all indicators, discretionarily example endeavor of the indicators and pick the
wonderful separation among the one's factors are expecting new data by methods for
collecting the expectations of the n-tree trees the utilization of larger part votes in
favor of sorts.
ALGORITHMS AND ANALYSIS.
For the Formulas: TP means True Positive, FP is False Positive, FN means False Negative, TN is
True Negative.
Average accuracy= tpi+Tni+fni+ fpi+tni1i=11
Precision = tp1 tp1 +fp11 i =1 1
RecallM= tpi tpi +fni 1 i = 11
F-measure =B 2+1 Precision M recall M B precision M recall M
EVALUATION PARAMETERS
Evaluation Parameters:
Precision- The precision parameter is a positive prognostic worth. It's a laid-out
measure in light of the fact that there is a normal possibility of important
recovery. = (assortment of Genuine Positives) (Number of genuine positives+
False positives) Exactness
Recall- The Recall parameter is the normal possibility of complete recovery of the
information. Recall = (Genuine positives)/(Genuine positives + False negative).
Accuracy Parameter - The accuracy parameter is characterized when there is an
appropriately ordered occasions separated by the entire assortment of occurrences
blessing inside the informational collection.
Accuracy = (Number of properly classified sample) / (Total variety of samples) .
weighting plan, 1/d is the separation appointed to a load all things considered. The KNN
classifier comprises of Euclidean Distance is the briefest separation between any two
neighbors is constantly a straight line. The KNN calculation is touchy to the nearby
arrangement of the information.
c) Random Forest-Random forests is a collection of tree predictors so everyone depends on
the resultant estimations of an irregular vector that are tested naturally where the
circulation closeness of the considerable number of brambles is inside the woodland. The
arbitrary backwoods calculation for forecast can be clarified as:
1. Utilizing interesting examples data draws tree bootstrap.
2. For every one of the bootstrap tests produce an unprinted classification tree, by method
for following change: at every hub, rather of choosing the top of the line split among
all indicators, discretionarily example endeavor of the indicators and pick the
wonderful separation among the one's factors are expecting new data by methods for
collecting the expectations of the n-tree trees the utilization of larger part votes in
favor of sorts.
ALGORITHMS AND ANALYSIS.
For the Formulas: TP means True Positive, FP is False Positive, FN means False Negative, TN is
True Negative.
Average accuracy= tpi+Tni+fni+ fpi+tni1i=11
Precision = tp1 tp1 +fp11 i =1 1
RecallM= tpi tpi +fni 1 i = 11
F-measure =B 2+1 Precision M recall M B precision M recall M
EVALUATION PARAMETERS
Evaluation Parameters:
Precision- The precision parameter is a positive prognostic worth. It's a laid-out
measure in light of the fact that there is a normal possibility of important
recovery. = (assortment of Genuine Positives) (Number of genuine positives+
False positives) Exactness
Recall- The Recall parameter is the normal possibility of complete recovery of the
information. Recall = (Genuine positives)/(Genuine positives + False negative).
Accuracy Parameter - The accuracy parameter is characterized when there is an
appropriately ordered occasions separated by the entire assortment of occurrences
blessing inside the informational collection.
Accuracy = (Number of properly classified sample) / (Total variety of samples) .
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

F-Measure - It is a proportion of a test's exactness and is characterized as the
weighted symphonious mean of the accuracy and review of the test.
F - Measure = 2 ((Precision Recall) / (Precision Recall))
METHODOLOGY
This system is mainly divided in three components i.e.
Mapping and Assembly -In “mapping and assembly” the frame work defines a
standard model for each and every object.
Pre-Filtering -In Pre-Filtering the entering object is checked by equating it with
blacklists
Classification-Semi supervised classifier SVM is trained with this data along with
blacklist and a knowledge base is created
LITERATURE REVIEW
Investigation into miniaturized scale online journals for spam identification is still in its earliest
stages and very little writing identified with the subject exist. AI procedures has been utilized by
Benevento, to recognize spammers. They distinguished two arrangements of each tweet, number
of hash labels on each tweet and so on Wang utilized a guided social chart model to investigate
companion and adherent connections among Twitter. Twitters spam approach that, if an
individual has few supporters contrasted with the measure of, he is following the record is
considered as spam was utilized to register three highlights to be specific the quantity of
companions, the quantity of adherents, and the notoriety of a client demonstrate that it takes half
a month for URLs presented in Twitter on be on its boycott. Notwithstanding the way that
Twitter itself does to forestall spamming; Twitter depends on clients to report spam. When a
report is recorded, Twitter researches it to choose to suspend a record or not. As of now, much
research is proceeding to discover a strategy to identify Twitter spamming in an effective and
robotized way. Past investigation at U.C. Berkeley demonstrates that 45% of clients on an
interpersonal organization site promptly click on URLs without uncertainty. Grier et al. gathered
more than 400 open tweets and announced that 8% of 25 million exceptional URLs presented on
twitter point to phishing, malware, and trick. Grier proposed a pattern dependent on URL
boycotting. Assessment of the setting mindful spam that could result from data that is shared on
the informal organizations is managed in. The creators presumed that setting mindful email
assaults have a high pace of progress. The paper likewise makes reference to the protection
systems taken by other informal organizations like LinkedIn and Myspace. Gathered Twitter
dataset and connections are analyzed Here the creators have discovered highlights utilizing
which substance polluters can be effectively recognized. The creators proposed a long-haul
investigation of securing informal communities utilizing nectar pots. Right around 60 nectar pots
were conveyed for seven months which brought about the reaping of in excess of 30000 spam
information. The spam order was finished utilizing AI calculations. Wang proposed another
methodology that utilized highlights from the social diagram from Twitter clients to recognize
and channel spam. In spite of the fact that these methodologies can manage the issue, another
weighted symphonious mean of the accuracy and review of the test.
F - Measure = 2 ((Precision Recall) / (Precision Recall))
METHODOLOGY
This system is mainly divided in three components i.e.
Mapping and Assembly -In “mapping and assembly” the frame work defines a
standard model for each and every object.
Pre-Filtering -In Pre-Filtering the entering object is checked by equating it with
blacklists
Classification-Semi supervised classifier SVM is trained with this data along with
blacklist and a knowledge base is created
LITERATURE REVIEW
Investigation into miniaturized scale online journals for spam identification is still in its earliest
stages and very little writing identified with the subject exist. AI procedures has been utilized by
Benevento, to recognize spammers. They distinguished two arrangements of each tweet, number
of hash labels on each tweet and so on Wang utilized a guided social chart model to investigate
companion and adherent connections among Twitter. Twitters spam approach that, if an
individual has few supporters contrasted with the measure of, he is following the record is
considered as spam was utilized to register three highlights to be specific the quantity of
companions, the quantity of adherents, and the notoriety of a client demonstrate that it takes half
a month for URLs presented in Twitter on be on its boycott. Notwithstanding the way that
Twitter itself does to forestall spamming; Twitter depends on clients to report spam. When a
report is recorded, Twitter researches it to choose to suspend a record or not. As of now, much
research is proceeding to discover a strategy to identify Twitter spamming in an effective and
robotized way. Past investigation at U.C. Berkeley demonstrates that 45% of clients on an
interpersonal organization site promptly click on URLs without uncertainty. Grier et al. gathered
more than 400 open tweets and announced that 8% of 25 million exceptional URLs presented on
twitter point to phishing, malware, and trick. Grier proposed a pattern dependent on URL
boycotting. Assessment of the setting mindful spam that could result from data that is shared on
the informal organizations is managed in. The creators presumed that setting mindful email
assaults have a high pace of progress. The paper likewise makes reference to the protection
systems taken by other informal organizations like LinkedIn and Myspace. Gathered Twitter
dataset and connections are analyzed Here the creators have discovered highlights utilizing
which substance polluters can be effectively recognized. The creators proposed a long-haul
investigation of securing informal communities utilizing nectar pots. Right around 60 nectar pots
were conveyed for seven months which brought about the reaping of in excess of 30000 spam
information. The spam order was finished utilizing AI calculations. Wang proposed another
methodology that utilized highlights from the social diagram from Twitter clients to recognize
and channel spam. In spite of the fact that these methodologies can manage the issue, another
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

spammer record may rise to substitute the sifted records. Thus, these boycotting frameworks,
likewise as occurs with messages, ought to be supplemented with substance-based
methodologies ordinarily utilized in email spam separating.
Result Analysis
Including all required library to proceed, some library are as pandas, NumPy, random forest
classifier, linear model, svm, graphviz, io.
Reading Data and proceeding for the data preprocessing.
In the above code we are giving column names to our data.
Converting spammer to “0” and non-spammer to “1”. It is easy to work on numerical data when
our features are numerical too.
Preparing features in variable X, in which column number 12 and 7 are dropped from the data.
While column umber 13 is our target which is stored in variable Y.
likewise as occurs with messages, ought to be supplemented with substance-based
methodologies ordinarily utilized in email spam separating.
Result Analysis
Including all required library to proceed, some library are as pandas, NumPy, random forest
classifier, linear model, svm, graphviz, io.
Reading Data and proceeding for the data preprocessing.
In the above code we are giving column names to our data.
Converting spammer to “0” and non-spammer to “1”. It is easy to work on numerical data when
our features are numerical too.
Preparing features in variable X, in which column number 12 and 7 are dropped from the data.
While column umber 13 is our target which is stored in variable Y.

Implementation of random forest and predicting the mean score for random forest with respect
to predicted output.
Accuracy we got 100 %
to predicted output.
Accuracy we got 100 %
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
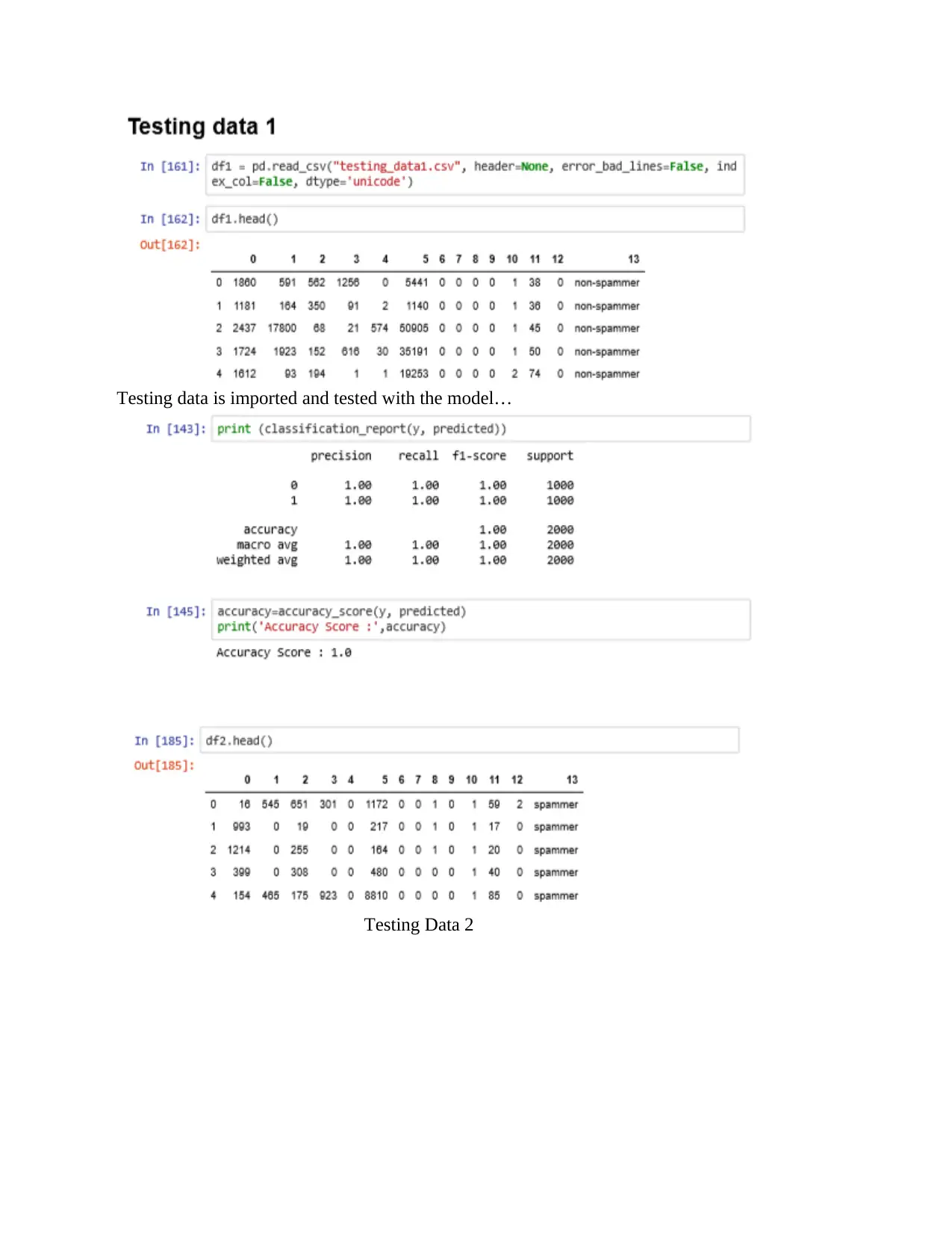
Testing data is imported and tested with the model…
Testing Data 2
Testing Data 2
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

All evaluation parameter has 100% accuracy.
CONCLUSION
As we've quite recently watched the ventures of experiences mining and system learning inside
the long-go casual correspondence region. Here we have chosen another determination help
gadget and is done for expectation of Spammer. Twitter Spam Grouping is foreseen utilizing
explicit classifiers and a similar investigation of their general execution is done. From the
assessment, we found that out of classifiers Naive Bayes, Random Forest and KNN, Arbitrary
Woods classifier performed higher than the option. The cost of expectation of Spammer is
progressed.
References
Alpaydin, E., 2010. Introduction to Machine Learning. 2nd ed. Massachusetts, United States:
MIT Press.
CONCLUSION
As we've quite recently watched the ventures of experiences mining and system learning inside
the long-go casual correspondence region. Here we have chosen another determination help
gadget and is done for expectation of Spammer. Twitter Spam Grouping is foreseen utilizing
explicit classifiers and a similar investigation of their general execution is done. From the
assessment, we found that out of classifiers Naive Bayes, Random Forest and KNN, Arbitrary
Woods classifier performed higher than the option. The cost of expectation of Spammer is
progressed.
References
Alpaydin, E., 2010. Introduction to Machine Learning. 2nd ed. Massachusetts, United States:
MIT Press.
1 out of 8
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.