IT8411 Business Intelligence - Big Data Analysis Report
VerifiedAdded on 2023/06/15
|19
|3044
|453
Report
AI Summary
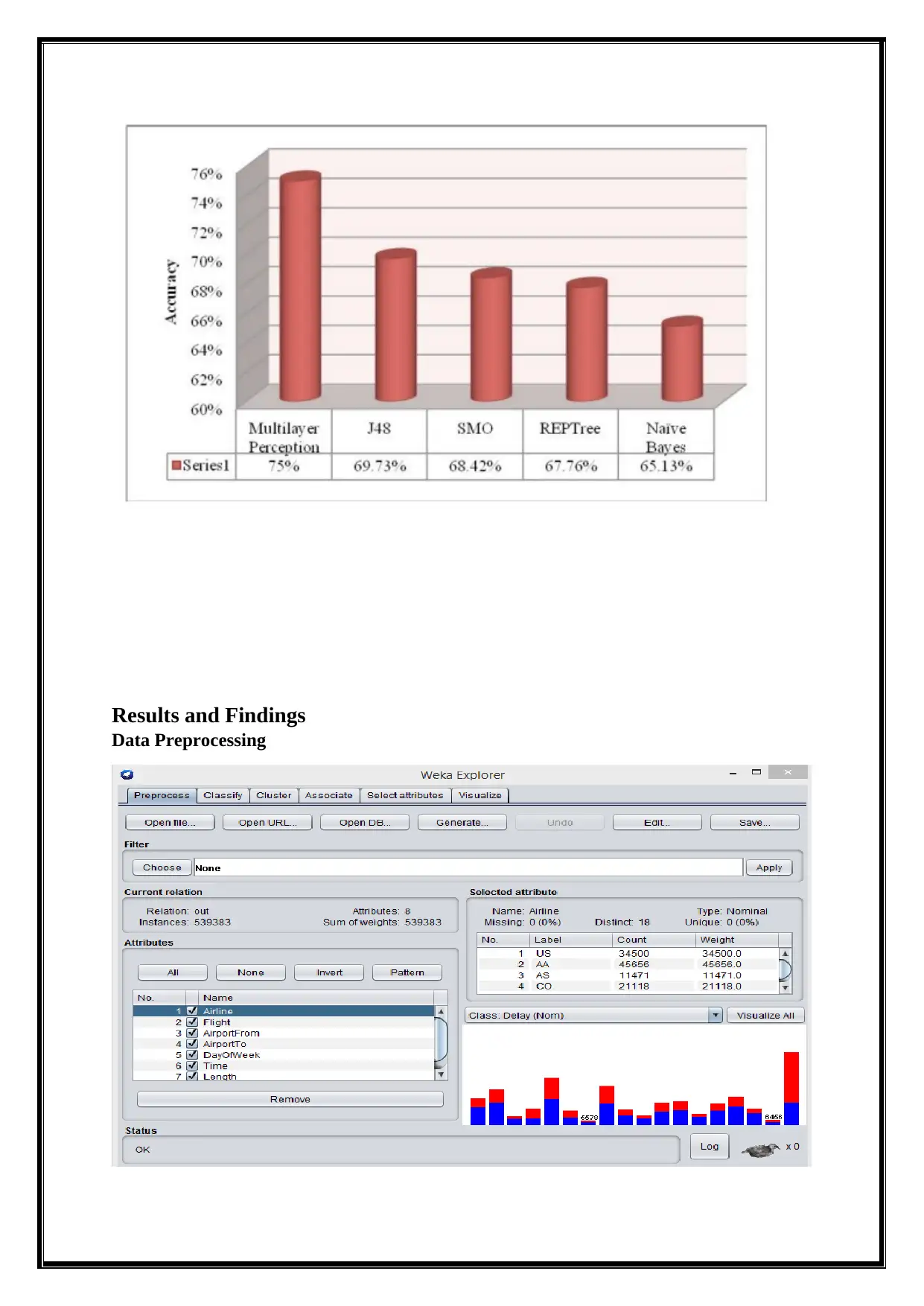
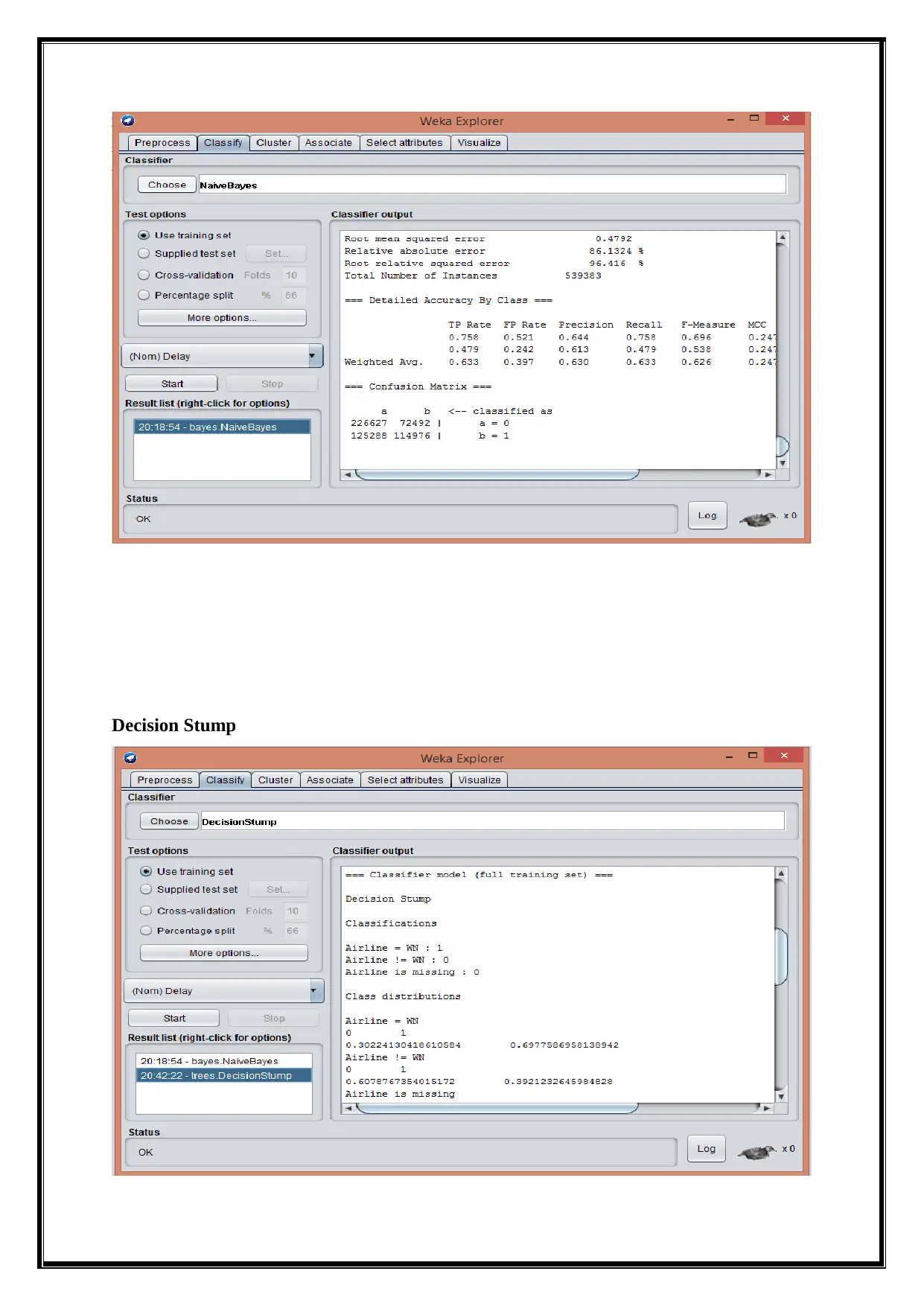
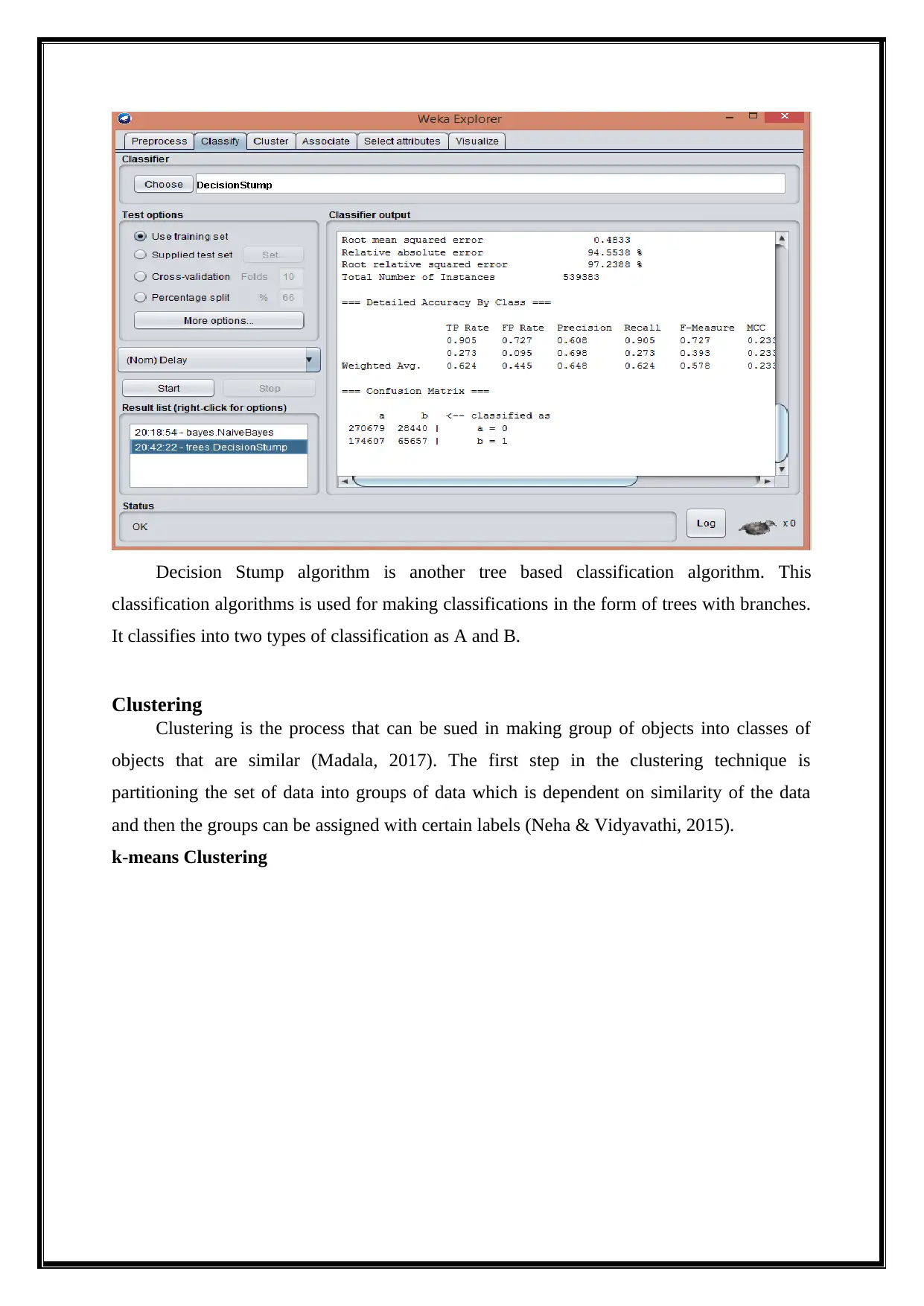
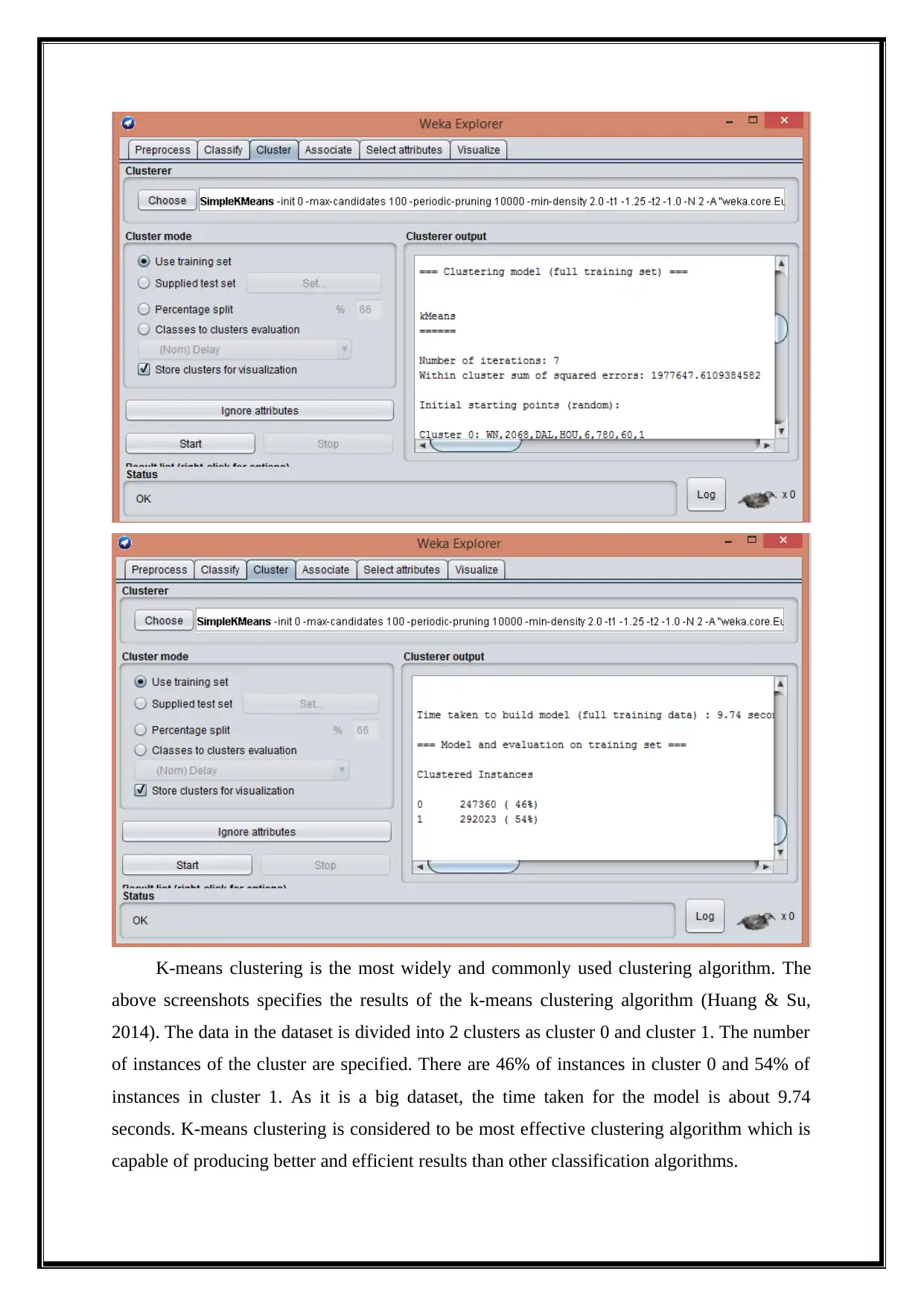
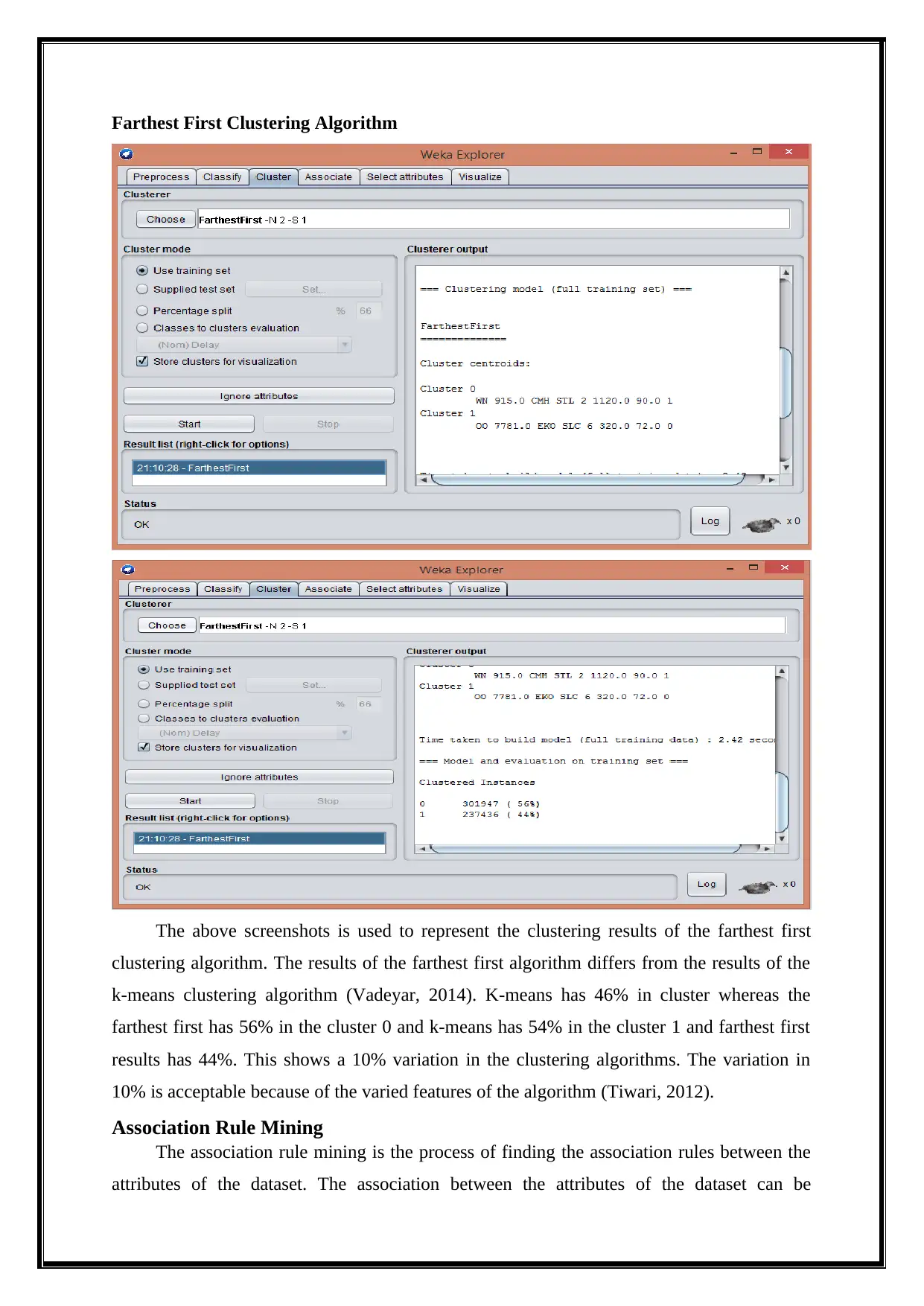
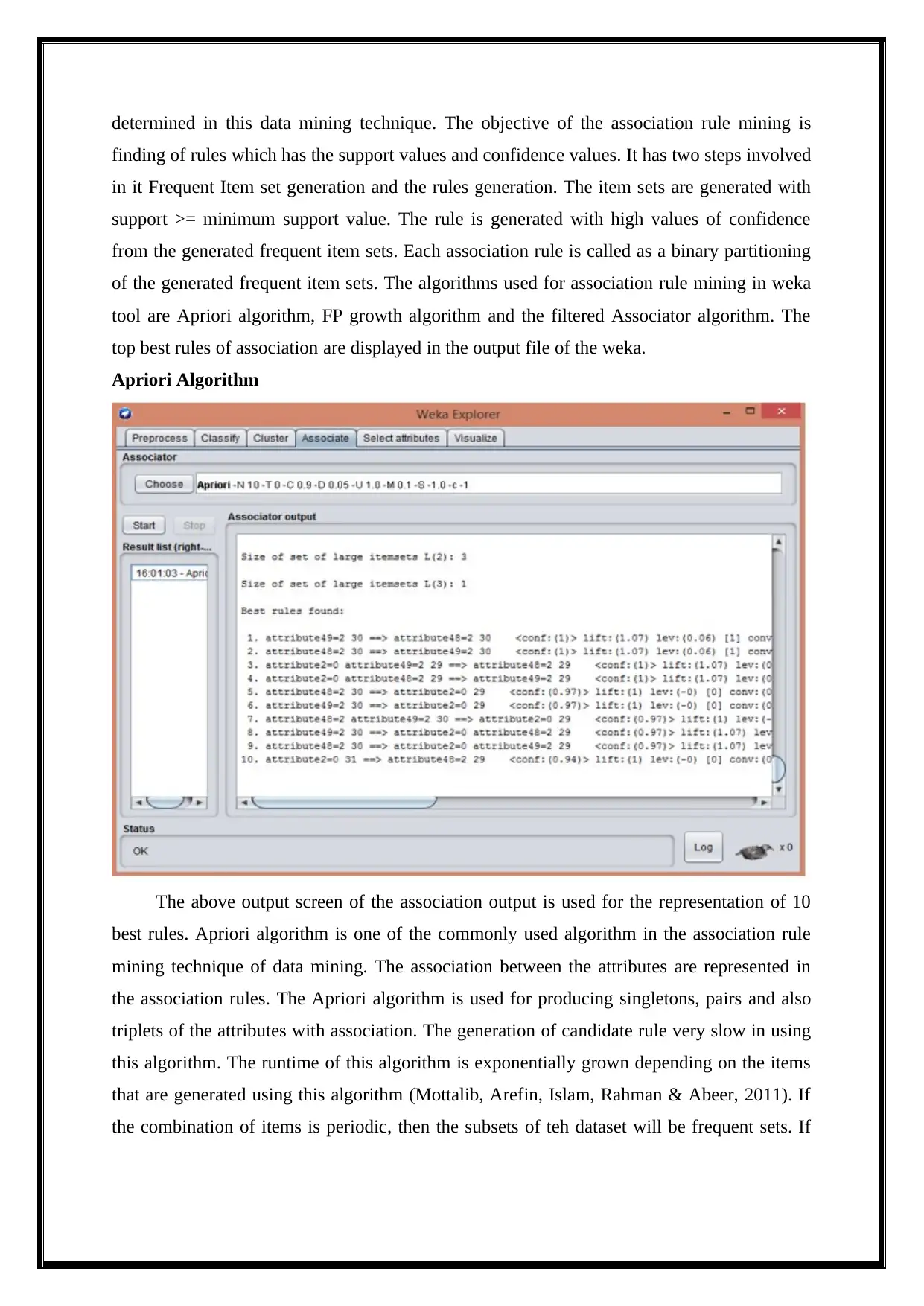
This report delves into the analysis of big data using various data mining techniques, including classification, clustering, association rule mining, and outlier detection, performed with the WEKA tool. It begins by providing a background on big data, emphasizing its characteristics of volume, velocity, and variety, and introduces biologically inspired data mining concepts like swarm intelligence. The analysis employs a dataset called Airlines.arff, and the report details the data preprocessing steps, followed by an exploration of classification algorithms such as Naive Bayes, Decision Stump, and Multilayer Perceptron, evaluating their accuracy and performance metrics. Clustering techniques, including k-means and Farthest First, are applied to group similar data points, and association rule mining, using algorithms like Apriori and Filtered Associator, identifies relationships between dataset attributes. Outlier detection methods are also implemented to find anomalies within the data. The report concludes with a summary of findings, highlighting the effectiveness of different techniques and suggesting future research directions. Desklib provides access to this and other solved assignments for students.





1 out of 19
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.