A Data Science Project: Predicting Stock Market Prices with Big Data
VerifiedAdded on 2023/01/11
|16
|4619
|51
Project
AI Summary
This project report investigates the use of big data analytics and machine learning techniques to predict short-term stock market prices. The study focuses on collecting data from multiple web APIs, including Yahoo, Wikimedia, Quandl, and Google Trends, and preprocessing it for analysis. The report explores the application of random forest algorithms for stock price forecasting, highlighting the importance of feature extraction and data preparation. Experiments were conducted using data from 2013 to 2016, and the results are presented and analyzed. The project also covers the model and implementation, including data collection, data preparation, and the selection of random forest algorithms for stock price prediction. The report evaluates the experimental outcomes and performance of the models, providing insights into the accuracy and effectiveness of the proposed approach. The project's goal is to develop a system that can accurately predict stock prices, leveraging various data sources and machine learning strategies. The code for the project is available on GitHub for further exploration and use by professionals.

BIG DATA ANALYTICS
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Table of Contents
ABSTRACT....................................................................................................................................3
INTRODUCTION...........................................................................................................................4
Background and motivation.........................................................................................................4
Project goal and requirements analysis........................................................................................5
MODEL AND IMPLEMENTATION.............................................................................................5
Data collection and preparation...................................................................................................5
Models and algorithms chosen....................................................................................................6
Programming implementation.....................................................................................................6
EXPERIMENTS..............................................................................................................................7
Description of experiments conducted........................................................................................7
Evidences of the experimental outcomes and presentation of results.........................................9
ANALYSIS....................................................................................................................................11
Experimental result analysis and performance evaluation........................................................11
Conclusions made......................................................................................................................12
CONCLUSIONS...........................................................................................................................12
REFERENCES..............................................................................................................................14
ABSTRACT....................................................................................................................................3
INTRODUCTION...........................................................................................................................4
Background and motivation.........................................................................................................4
Project goal and requirements analysis........................................................................................5
MODEL AND IMPLEMENTATION.............................................................................................5
Data collection and preparation...................................................................................................5
Models and algorithms chosen....................................................................................................6
Programming implementation.....................................................................................................6
EXPERIMENTS..............................................................................................................................7
Description of experiments conducted........................................................................................7
Evidences of the experimental outcomes and presentation of results.........................................9
ANALYSIS....................................................................................................................................11
Experimental result analysis and performance evaluation........................................................11
Conclusions made......................................................................................................................12
CONCLUSIONS...........................................................................................................................12
REFERENCES..............................................................................................................................14

ABSTRACT
The main objective of this project report is to find the best model for expecting short term stock
market prices. During the research towards consideration of various methods and factors to
implement, we discovered that methods such as random forest, support vector machine were not
exploited fully. In this report, we will present and explore an increasingly practical strategy for
monitoring stock market development with greater precision. The main thing we considered was
the exchange rate database of the previous year. The database was pre-prepared and modified for
correct analysis. Therefore, our report will also focus on preprocessing raw dataset information.
Furthermore, after preparing the information, we will examine the use of irregular spindle arrays,
a vector support tool on the database and its results. In addition, the proposed project report
examines the use of the expectations framework in real life situations and issues related to the
accuracy of the general characteristics presented. The additional document presents an AI model
for predicting the life span of a security in a volatile market. Stock dividend forecasts will be a
wonderful resource for stock exchange centers and will provide immediate answers to the
problems that stock speculators face.
The main objective of this project report is to find the best model for expecting short term stock
market prices. During the research towards consideration of various methods and factors to
implement, we discovered that methods such as random forest, support vector machine were not
exploited fully. In this report, we will present and explore an increasingly practical strategy for
monitoring stock market development with greater precision. The main thing we considered was
the exchange rate database of the previous year. The database was pre-prepared and modified for
correct analysis. Therefore, our report will also focus on preprocessing raw dataset information.
Furthermore, after preparing the information, we will examine the use of irregular spindle arrays,
a vector support tool on the database and its results. In addition, the proposed project report
examines the use of the expectations framework in real life situations and issues related to the
accuracy of the general characteristics presented. The additional document presents an AI model
for predicting the life span of a security in a volatile market. Stock dividend forecasts will be a
wonderful resource for stock exchange centers and will provide immediate answers to the
problems that stock speculators face.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

INTRODUCTION
Background and motivation
The stock market is dominated by numerous buyers and stock traders. Stocks (also known as
shares) usually talk about property claims with a specific person or a collection of individuals.
The attempt to calculate the future estimate of the currency exchange is known as the expectation
of the stock exchange (Fama, 1965). The forecast needs to be strong, accurate and effective. The
framework must operate as real situations unfold and should be appropriate to the qualified
circumstances. The framework should also consider all factors that affect the value and
performance of the stock. There are different strategies and methods to update the prediction
framework such as Basic Analysis, Technical Analysis, Machine Learning and Time series
method of structuring (Kara et al., 2011). With the advance of computer time, the expectation
has soared in the mechanical field (Gidofalvi, 2001, p.1).
Conventional techniques for anticipating AI use calculations such as backward
propagation, known as reproductive errors. Recently, many scientists are using multiple group
learning methods. It would use low costs and delays to expect future highs while another system
would use massive to predict future highs. These projections were used to model inventory costs.
The monetary exchange value forecasts for short-term windows define all signals as a
configuration procedure (Cootner, 1964; Fama et al., 1969). The development of valuable stocks
over time directly as a rule building cycle. Generally people who buy single stocks that have a
cost to go up faster than later. The vulnerability in financial exchange offers people the resources
put in stock. In this way, it is necessary to foresee in detail the exchange of securities that can be
used in real situations (Geva and Zahavi, 2014). The techniques used to predict securities include
temporal average forecasts combined with a dedicated study, AI that presents and provides for
variable financial exchange. The securities exchange model databases contain subtleties such as
the opening value of the final value, the information and various factors that should predict the
factor of an element that is a cost on a given day (Bollen et al., 2011). The resulting model used
standard expectation methods such as multivariable analysis with a projected time resolution
model. The pre-exchange financial statement will come out when the case is treated as a new
Background and motivation
The stock market is dominated by numerous buyers and stock traders. Stocks (also known as
shares) usually talk about property claims with a specific person or a collection of individuals.
The attempt to calculate the future estimate of the currency exchange is known as the expectation
of the stock exchange (Fama, 1965). The forecast needs to be strong, accurate and effective. The
framework must operate as real situations unfold and should be appropriate to the qualified
circumstances. The framework should also consider all factors that affect the value and
performance of the stock. There are different strategies and methods to update the prediction
framework such as Basic Analysis, Technical Analysis, Machine Learning and Time series
method of structuring (Kara et al., 2011). With the advance of computer time, the expectation
has soared in the mechanical field (Gidofalvi, 2001, p.1).
Conventional techniques for anticipating AI use calculations such as backward
propagation, known as reproductive errors. Recently, many scientists are using multiple group
learning methods. It would use low costs and delays to expect future highs while another system
would use massive to predict future highs. These projections were used to model inventory costs.
The monetary exchange value forecasts for short-term windows define all signals as a
configuration procedure (Cootner, 1964; Fama et al., 1969). The development of valuable stocks
over time directly as a rule building cycle. Generally people who buy single stocks that have a
cost to go up faster than later. The vulnerability in financial exchange offers people the resources
put in stock. In this way, it is necessary to foresee in detail the exchange of securities that can be
used in real situations (Geva and Zahavi, 2014). The techniques used to predict securities include
temporal average forecasts combined with a dedicated study, AI that presents and provides for
variable financial exchange. The securities exchange model databases contain subtleties such as
the opening value of the final value, the information and various factors that should predict the
factor of an element that is a cost on a given day (Bollen et al., 2011). The resulting model used
standard expectation methods such as multivariable analysis with a projected time resolution
model. The pre-exchange financial statement will come out when the case is treated as a new
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

transmission, but will work well when rewarded as an order (Abdullah and Ganapathy, 2000).
The point is to structure a model that will benefit from market data using artificial intelligence
systems and look to future examples in actions that deserve to be converted into events
(Schumaker and Chen 2009).
Project goal and requirements analysis
The overarching goal of this report is to develop a system of financial experts who rely on the
strategies of the shooters who use multiple sources of information and can more accurately
predict stock costs in different periods. To support the use of our common monetary framework
and comparative approaches, we make all of our code freely available at:
https://github.com/martinwg/stockprediction. Please note that our code and documentation
provides professionals and experts with equipment and programming packages to scan any stock
related information (and not just the stocks inspected for our audit of the stock). situation), to the
usefulness of our monetary framework. The rest of this document is done as follows. In section
2, we give subtleties to both the development of the “knowledge base” and the “level of man-
made consciousness”. We will discuss our process leading to Section 3. Finally, we present a
summary of the main commitments and limitations of this work in Section 4, just as some ideas
for study in the future.
MODEL AND IMPLEMENTATION
Data collection and preparation
The data is collected through four web APIs, namely the Yahoo YQL API, the Wikimedia
RESTful API, the Quandl database and the Google Trend API. Four information provisions are
included that include: (a) affordable market data on stocks, including opening / closing costs,
trading volume, NASDAQ and DJIA listings, among others other; (b) the number of unique
visitors to the relevant Wikipedia pages per day; (c) daily currency news counts on the provision
of rewards and valuation scores as a proportion of bullish and bearish value expenditures are
determined as a factual inventory of the news organization's motivation and cynicism and (d) a
daily model of the combined topics related to the stock they viewed on Google. Scientists
typically receive special signals that reflect the difference in value after a short time (Stochastic
Oscillator, MACD, Chande Pulse Oscillator and so on) from the R TTR package (Ulrich 2016)
The point is to structure a model that will benefit from market data using artificial intelligence
systems and look to future examples in actions that deserve to be converted into events
(Schumaker and Chen 2009).
Project goal and requirements analysis
The overarching goal of this report is to develop a system of financial experts who rely on the
strategies of the shooters who use multiple sources of information and can more accurately
predict stock costs in different periods. To support the use of our common monetary framework
and comparative approaches, we make all of our code freely available at:
https://github.com/martinwg/stockprediction. Please note that our code and documentation
provides professionals and experts with equipment and programming packages to scan any stock
related information (and not just the stocks inspected for our audit of the stock). situation), to the
usefulness of our monetary framework. The rest of this document is done as follows. In section
2, we give subtleties to both the development of the “knowledge base” and the “level of man-
made consciousness”. We will discuss our process leading to Section 3. Finally, we present a
summary of the main commitments and limitations of this work in Section 4, just as some ideas
for study in the future.
MODEL AND IMPLEMENTATION
Data collection and preparation
The data is collected through four web APIs, namely the Yahoo YQL API, the Wikimedia
RESTful API, the Quandl database and the Google Trend API. Four information provisions are
included that include: (a) affordable market data on stocks, including opening / closing costs,
trading volume, NASDAQ and DJIA listings, among others other; (b) the number of unique
visitors to the relevant Wikipedia pages per day; (c) daily currency news counts on the provision
of rewards and valuation scores as a proportion of bullish and bearish value expenditures are
determined as a factual inventory of the news organization's motivation and cynicism and (d) a
daily model of the combined topics related to the stock they viewed on Google. Scientists
typically receive special signals that reflect the difference in value after a short time (Stochastic
Oscillator, MACD, Chande Pulse Oscillator and so on) from the R TTR package (Ulrich 2016)

until fifth bring our information provision. The information at that stage will enter two
consecutive pre-processing stages: (a) cleaning the information; who governs the virtues of
absent and wrong; (b) change of information; which requires some artificial intelligence models,
such as cloud systems. A volume reduction strategy is implemented to reduce information
asymmetry and to retain the most important and relevant data. In Phase 2, we preview the value
of the stock with different times (games) using four AI collection methods. Modified forgetting
of cross-approval (LOOCV) is used to limit the bias associated with the study. These models are
analyzed and evaluated according to the modified LOOCV using three evaluation rules.
Models and algorithms chosen
Random forest algorithm calculations are used for currency exchange forecasts. Having been
named one of the few who want to use and adapt AI calculations, it offers great precision in the
report. This is usually used in order guarantees. Due to the high volatility in the exchange of
securities, the prospectus specifications are highly tentative. In the forecast of the exchange of
securities we are using arbitrary forest classifications that have the corresponding hyper limits
starting from the tree of choice. The chosen device has a tree model. He will take the option
based on potential returns, which include factors such as event performance, cost of activities
and convenience. The arbitrary calculation of the secondary woods speaks of a calculation in
which it selects various ideas and ambitions badly to collect some chosen trees and subsequently
takes the total of the few decisions of the chosen tree. The information is part of the sections
responsible for searching for names or properties. The collection of information that we used
came from the financial exchanges of the previous year collected from the open database
accessible from the web, 80% of the information was used to prepare the tool and the remaining
20% to verify the information. The basic methodology of the guided learning model is to
familiarize with the examples and links in the information from the preparation set and then
recreate them for the test information.
Programming implementation
The first step is to convert this raw information into prepared information. This culminated in the
use of the extremes, because in the rough information collected there are a number of features,
but only a couple of these attributes are worth the end goal to expect. Then the first step involves
extraction, in which the main features are extracted from the full range of features accessible in
consecutive pre-processing stages: (a) cleaning the information; who governs the virtues of
absent and wrong; (b) change of information; which requires some artificial intelligence models,
such as cloud systems. A volume reduction strategy is implemented to reduce information
asymmetry and to retain the most important and relevant data. In Phase 2, we preview the value
of the stock with different times (games) using four AI collection methods. Modified forgetting
of cross-approval (LOOCV) is used to limit the bias associated with the study. These models are
analyzed and evaluated according to the modified LOOCV using three evaluation rules.
Models and algorithms chosen
Random forest algorithm calculations are used for currency exchange forecasts. Having been
named one of the few who want to use and adapt AI calculations, it offers great precision in the
report. This is usually used in order guarantees. Due to the high volatility in the exchange of
securities, the prospectus specifications are highly tentative. In the forecast of the exchange of
securities we are using arbitrary forest classifications that have the corresponding hyper limits
starting from the tree of choice. The chosen device has a tree model. He will take the option
based on potential returns, which include factors such as event performance, cost of activities
and convenience. The arbitrary calculation of the secondary woods speaks of a calculation in
which it selects various ideas and ambitions badly to collect some chosen trees and subsequently
takes the total of the few decisions of the chosen tree. The information is part of the sections
responsible for searching for names or properties. The collection of information that we used
came from the financial exchanges of the previous year collected from the open database
accessible from the web, 80% of the information was used to prepare the tool and the remaining
20% to verify the information. The basic methodology of the guided learning model is to
familiarize with the examples and links in the information from the preparation set and then
recreate them for the test information.
Programming implementation
The first step is to convert this raw information into prepared information. This culminated in the
use of the extremes, because in the rough information collected there are a number of features,
but only a couple of these attributes are worth the end goal to expect. Then the first step involves
extraction, in which the main features are extracted from the full range of features accessible in
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

the raw data sets. The drawing of the highlights starts from a basic condition of the calculated
information and the realization of features or ambitions. These ambitions are intended to be light
and not excessive, boosting the subsequent levels of learning and profitability. Extraction of peak
times is a process of magnitude reduction, in which the basic configuration of raw factors is
reduced to appropriate points that are continuously sensitive to the simplicity of managers, and
certainly and completely represents the main field of education.
The element extraction process is followed by an ordering procedure in which the
information received after the element extraction is part of two unique segments. Order is the
problem of seeing which set of classes another idea occupies. Preparation information collection
is used to prepare the model while test information is used to predict the model's accuracy. The
separation is performed in such a way that the preparation information maintains a higher
standard than the test information.
The random forest algorithm uses an arbitrary combination of trees to distribute
information. As for the laity, from the total number of trees chosen in the forest, a handful of
chosen trees find unique clues in the information. This is called information separation. For this
scenario, since the final objective of the proposed framework is to predict the cost of the stock by
disseminating its actual information.
EXPERIMENTS
Description of experiments conducted
The information is collected from January 2013 to December 2016 daily. The figure below
shows a representation of the relational framework of the five provisions of the reference points,
in which the extremes are clustered using the various leveled assembled calculations (so the
highest places with high links close together) and the screens show the dimensions of connecting
seismic connections between the highest views. Soft blue suggests a strong positive connection,
while soft red represents strong negative relations and white shading proves that there is no
connection between the two perspectives. The bright blue squares on the corner to corner show
that the top spots fall into some large groups and within each group the upper views show a solid
linearity. For example, the different costs (open, closed, high or low) in the same period are close
to each other in most cases and thus appear to fall into a similar group. There are also side effects
information and the realization of features or ambitions. These ambitions are intended to be light
and not excessive, boosting the subsequent levels of learning and profitability. Extraction of peak
times is a process of magnitude reduction, in which the basic configuration of raw factors is
reduced to appropriate points that are continuously sensitive to the simplicity of managers, and
certainly and completely represents the main field of education.
The element extraction process is followed by an ordering procedure in which the
information received after the element extraction is part of two unique segments. Order is the
problem of seeing which set of classes another idea occupies. Preparation information collection
is used to prepare the model while test information is used to predict the model's accuracy. The
separation is performed in such a way that the preparation information maintains a higher
standard than the test information.
The random forest algorithm uses an arbitrary combination of trees to distribute
information. As for the laity, from the total number of trees chosen in the forest, a handful of
chosen trees find unique clues in the information. This is called information separation. For this
scenario, since the final objective of the proposed framework is to predict the cost of the stock by
disseminating its actual information.
EXPERIMENTS
Description of experiments conducted
The information is collected from January 2013 to December 2016 daily. The figure below
shows a representation of the relational framework of the five provisions of the reference points,
in which the extremes are clustered using the various leveled assembled calculations (so the
highest places with high links close together) and the screens show the dimensions of connecting
seismic connections between the highest views. Soft blue suggests a strong positive connection,
while soft red represents strong negative relations and white shading proves that there is no
connection between the two perspectives. The bright blue squares on the corner to corner show
that the top spots fall into some large groups and within each group the upper views show a solid
linearity. For example, the different costs (open, closed, high or low) in the same period are close
to each other in most cases and thus appear to fall into a similar group. There are also side effects
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
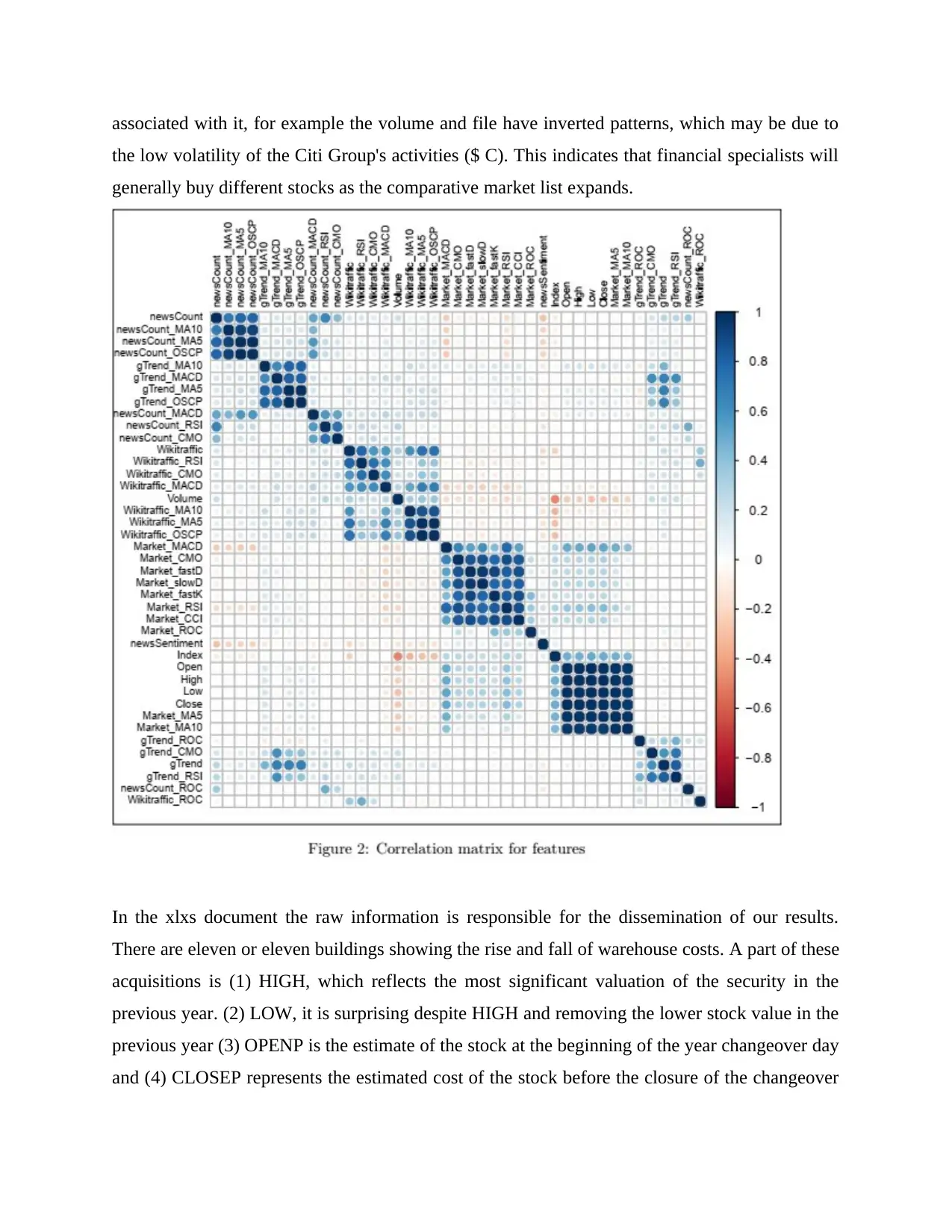
associated with it, for example the volume and file have inverted patterns, which may be due to
the low volatility of the Citi Group's activities ($ C). This indicates that financial specialists will
generally buy different stocks as the comparative market list expands.
In the xlxs document the raw information is responsible for the dissemination of our results.
There are eleven or eleven buildings showing the rise and fall of warehouse costs. A part of these
acquisitions is (1) HIGH, which reflects the most significant valuation of the security in the
previous year. (2) LOW, it is surprising despite HIGH and removing the lower stock value in the
previous year (3) OPENP is the estimate of the stock at the beginning of the year changeover day
and (4) CLOSEP represents the estimated cost of the stock before the closure of the changeover
the low volatility of the Citi Group's activities ($ C). This indicates that financial specialists will
generally buy different stocks as the comparative market list expands.
In the xlxs document the raw information is responsible for the dissemination of our results.
There are eleven or eleven buildings showing the rise and fall of warehouse costs. A part of these
acquisitions is (1) HIGH, which reflects the most significant valuation of the security in the
previous year. (2) LOW, it is surprising despite HIGH and removing the lower stock value in the
previous year (3) OPENP is the estimate of the stock at the beginning of the year changeover day
and (4) CLOSEP represents the estimated cost of the stock before the closure of the changeover
day. There are several features, for example YCP, LTP, TRADE, VOLUME and VALUE, but
the four mentioned above play a vital role in what we have found.
Evidences of the experimental outcomes and presentation of results
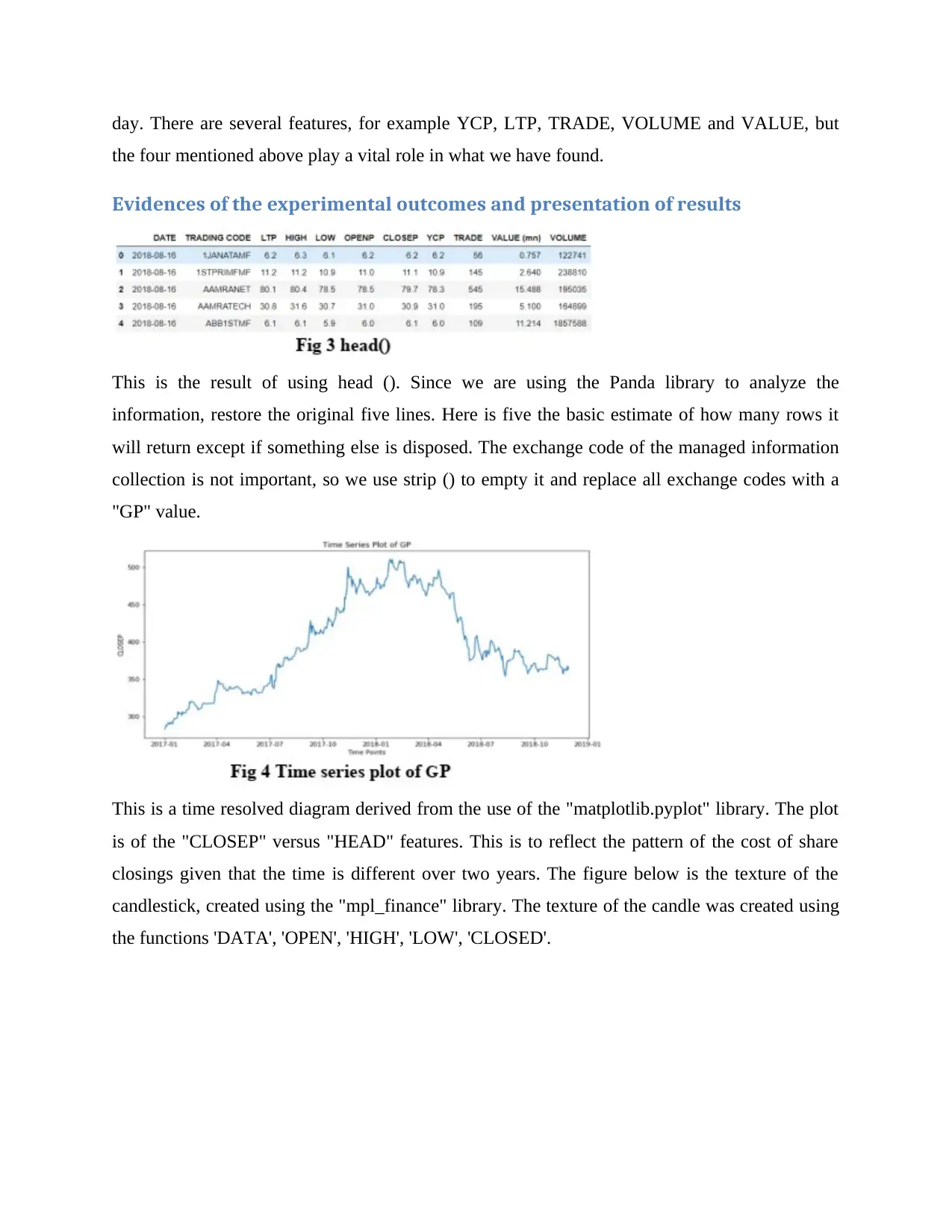
This is the result of using head (). Since we are using the Panda library to analyze the
information, restore the original five lines. Here is five the basic estimate of how many rows it
will return except if something else is disposed. The exchange code of the managed information
collection is not important, so we use strip () to empty it and replace all exchange codes with a
"GP" value.
This is a time resolved diagram derived from the use of the "matplotlib.pyplot" library. The plot
is of the "CLOSEP" versus "HEAD" features. This is to reflect the pattern of the cost of share
closings given that the time is different over two years. The figure below is the texture of the
candlestick, created using the "mpl_finance" library. The texture of the candle was created using
the functions 'DATA', 'OPEN', 'HIGH', 'LOW', 'CLOSED'.
the four mentioned above play a vital role in what we have found.
Evidences of the experimental outcomes and presentation of results
This is the result of using head (). Since we are using the Panda library to analyze the
information, restore the original five lines. Here is five the basic estimate of how many rows it
will return except if something else is disposed. The exchange code of the managed information
collection is not important, so we use strip () to empty it and replace all exchange codes with a
"GP" value.
This is a time resolved diagram derived from the use of the "matplotlib.pyplot" library. The plot
is of the "CLOSEP" versus "HEAD" features. This is to reflect the pattern of the cost of share
closings given that the time is different over two years. The figure below is the texture of the
candlestick, created using the "mpl_finance" library. The texture of the candle was created using
the functions 'DATA', 'OPEN', 'HIGH', 'LOW', 'CLOSED'.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

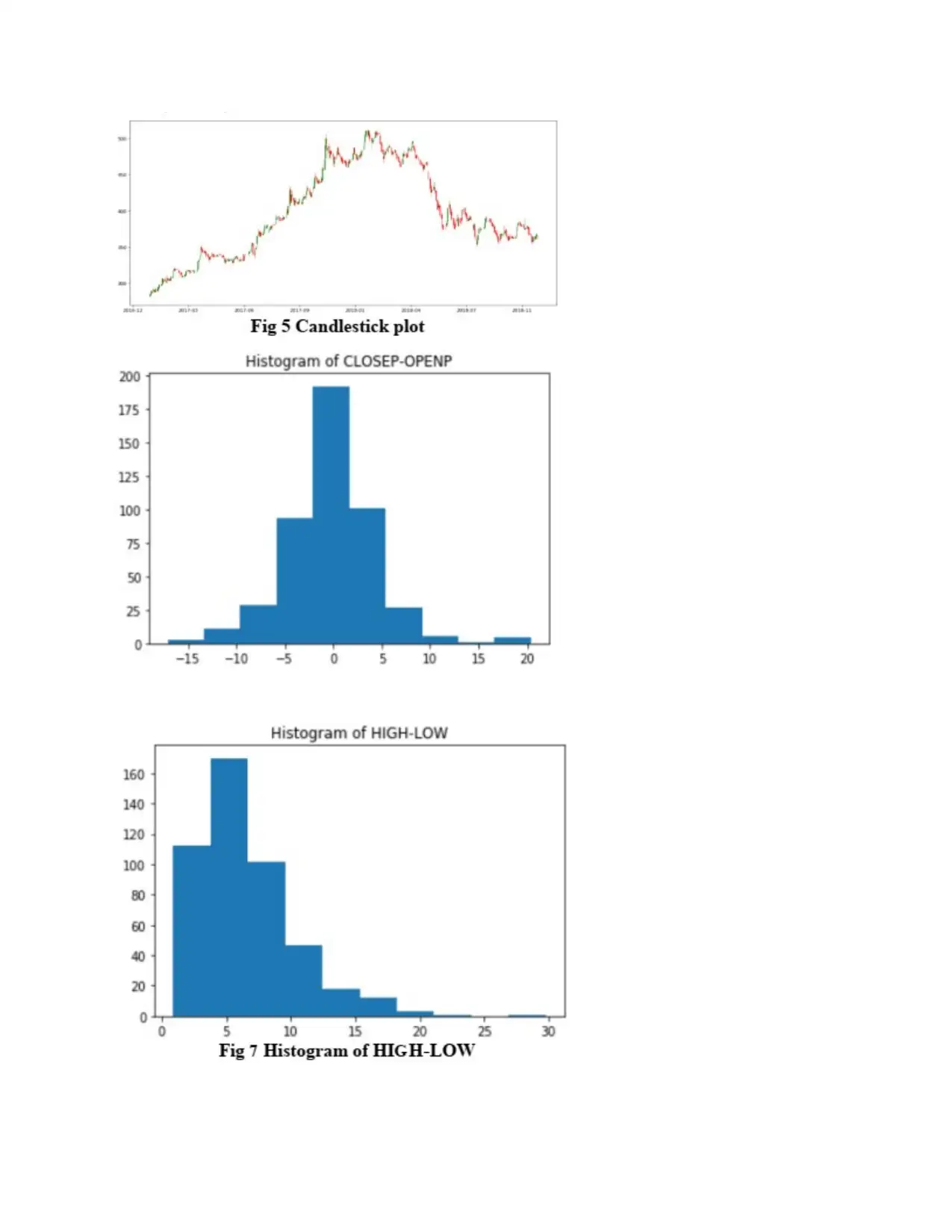
Both figures and histograms are plotted between "CLOSEP" and "OPENP" and the "HIGH" and
"LOW" indicators. This is because we assume that the current closing cost and the opening cost
combined with the highest and lowest cost of the stock a year ago will affect the costs. the stock
in the future. Despite such an idea we shared a philosophy according to which "in case the
current CLOSEP is more relevant than yesterday's CLOSEP, at that point we add the value 1 to
DEX the function or, apparently, we assign the value - 1 to DEX. so that the entire collection of
information is managed and after using the header () we take a brief look at the information
received to date.
The next step involved variable marking and target location, along with setting the train size.
Using sklearn libraries we introduce the SVC classification and respond to the preparation
information. The preparation of the model with the information and the execution of the test
information through the prepared model involved the reception of the disordered laser as
follows:
Alongside this, we use the matching data to prepare another model. This model uses the Random
Forest Classifier which has a place with the troupe strategy. The trees chosen with the goal that
makes "n_estimator" have a default estimate of 10 as this is a result of 0.20. In any case, the
estimate of "n_estimator" changes to 100 in the 0.22 change. As a result of adjusting the model
with the information and running it with the expected information, we found that this has an
accuracy score of 0.808. To summarize, the accuracy of the SVC model in the test set is 0.787
while the accuracy score of the inorganic wood grader is determined at 0.808.
"LOW" indicators. This is because we assume that the current closing cost and the opening cost
combined with the highest and lowest cost of the stock a year ago will affect the costs. the stock
in the future. Despite such an idea we shared a philosophy according to which "in case the
current CLOSEP is more relevant than yesterday's CLOSEP, at that point we add the value 1 to
DEX the function or, apparently, we assign the value - 1 to DEX. so that the entire collection of
information is managed and after using the header () we take a brief look at the information
received to date.
The next step involved variable marking and target location, along with setting the train size.
Using sklearn libraries we introduce the SVC classification and respond to the preparation
information. The preparation of the model with the information and the execution of the test
information through the prepared model involved the reception of the disordered laser as
follows:
Alongside this, we use the matching data to prepare another model. This model uses the Random
Forest Classifier which has a place with the troupe strategy. The trees chosen with the goal that
makes "n_estimator" have a default estimate of 10 as this is a result of 0.20. In any case, the
estimate of "n_estimator" changes to 100 in the 0.22 change. As a result of adjusting the model
with the information and running it with the expected information, we found that this has an
accuracy score of 0.808. To summarize, the accuracy of the SVC model in the test set is 0.787
while the accuracy score of the inorganic wood grader is determined at 0.808.

ANALYSIS
Experimental result analysis and performance evaluation
Expected investment costs and estimated output are the "fantasy" of each speculator. In this
document, researcher present a collection-based approach to anticipating the value of stocks 1
day in advance using various sources of information. In light of results, it has assumed that
MAPE by 1 day ≤ 0.75% may be educational for speculators. We make our code publicly
accessible for further evaluation and submission to various stocks. Since report does not need a
financial expert who may have point-to-point (none) information about R, researcher provide a
tutorial exercise on how to modify / modify our code to anticipate the cost of securities the US
later. The educational exercise is enabled on https://github.com/martinwg/stockprediction. The
didactic exercise covers all the subtleties from the setup and introduction of R to the performance
of our code. Note that our code shows the key advances the speculator should take to scan the
information online, as it includes R keys for checking balance news and titles a Wikipedia page
relevant to the stock.
Conclusions made
It can be concluded that; in recent years, there has been an increasing number of articles on the
use of handmade reasoning for robotic exchange options (see for example the Metz study on
Wired (2016)). In this way, it is essential to reveal two major differences in motivation and to
step back from our promises and efforts that emerged in Metz (2016). First of all, we have
achieved the subtleties behind our approach. Although simplicity is important in terms of
academic research, it does not provide a similar task in terms of arbitrage as any advantage is lost
when methods are accessible. Be that as it may, we accept that the pieces of knowledge from our
study can be summarized. In particular, it is necessary: (a) to consider the performance of the
stock over a certain number of periods; and (b) the merging of unusual information sources can
improve the performance of a prospectus. Secondly, our main frame does not exclude dynamic
boosts or motors. This is specifically indicated by the general (general) goal of this study to
provide a financial expert: (a) a modern intelligence-driven figure of consciousness, or (b)
knowledge that in specific indicators that should be considered before choosing the profitability
option. These estimates or pieces of knowledge can be linked together as part of a larger model
Experimental result analysis and performance evaluation
Expected investment costs and estimated output are the "fantasy" of each speculator. In this
document, researcher present a collection-based approach to anticipating the value of stocks 1
day in advance using various sources of information. In light of results, it has assumed that
MAPE by 1 day ≤ 0.75% may be educational for speculators. We make our code publicly
accessible for further evaluation and submission to various stocks. Since report does not need a
financial expert who may have point-to-point (none) information about R, researcher provide a
tutorial exercise on how to modify / modify our code to anticipate the cost of securities the US
later. The educational exercise is enabled on https://github.com/martinwg/stockprediction. The
didactic exercise covers all the subtleties from the setup and introduction of R to the performance
of our code. Note that our code shows the key advances the speculator should take to scan the
information online, as it includes R keys for checking balance news and titles a Wikipedia page
relevant to the stock.
Conclusions made
It can be concluded that; in recent years, there has been an increasing number of articles on the
use of handmade reasoning for robotic exchange options (see for example the Metz study on
Wired (2016)). In this way, it is essential to reveal two major differences in motivation and to
step back from our promises and efforts that emerged in Metz (2016). First of all, we have
achieved the subtleties behind our approach. Although simplicity is important in terms of
academic research, it does not provide a similar task in terms of arbitrage as any advantage is lost
when methods are accessible. Be that as it may, we accept that the pieces of knowledge from our
study can be summarized. In particular, it is necessary: (a) to consider the performance of the
stock over a certain number of periods; and (b) the merging of unusual information sources can
improve the performance of a prospectus. Secondly, our main frame does not exclude dynamic
boosts or motors. This is specifically indicated by the general (general) goal of this study to
provide a financial expert: (a) a modern intelligence-driven figure of consciousness, or (b)
knowledge that in specific indicators that should be considered before choosing the profitability
option. These estimates or pieces of knowledge can be linked together as part of a larger model
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 16
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.