Data Integration and Analysis: Patient Ratings and Mortality Rates
VerifiedAdded on 2022/08/20
|15
|3256
|10
Project
AI Summary
This project focuses on the integration and analysis of big data within the healthcare domain. The study integrates two datasets: patient ratings of hospital services and changes in mortality rates in the United States. The data integration process involves data extraction, dimension reduction, filtration, and mutation to create a unified dataset. Correlation and cluster analyses are applied to identify relationships between patient satisfaction and mortality trends. The correlation analysis reveals a weak positive relationship between patient survey ratings and mortality rate changes. Cluster analysis is used to group states based on these variables. The project identifies potential beneficiaries of the analysis, including psychologists, policymakers, and researchers. It also discusses limitations, assumptions, and new approaches to data integration theories, such as ETL, highlighting its shortcomings in data cleaning. The project aims to provide insights into the connection between patient experiences and health outcomes, offering valuable information for healthcare improvements. The project incorporates data from the Centers for Medicare & Medicaid Services (2020) and IHME (2019).

Big Data Integration
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Big Data Integration
Contents
Introduction.................................................................................................................................................3
Data Integration...........................................................................................................................................4
Data.........................................................................................................................................................4
Data Integration Processes.......................................................................................................................4
Data Extraction....................................................................................................................................4
Dimension Reduction..........................................................................................................................5
Filtration..............................................................................................................................................6
Mutation..............................................................................................................................................6
New Information from Analysis..................................................................................................................7
Analysis Results......................................................................................................................................7
Possible Beneficiaries of New Information.............................................................................................9
Limitations and Assumptions................................................................................................................10
New Approaches in Data Integration Theories..........................................................................................10
Conclusion.................................................................................................................................................12
References.................................................................................................................................................13
Appendix: State Initials.............................................................................................................................15
2
Contents
Introduction.................................................................................................................................................3
Data Integration...........................................................................................................................................4
Data.........................................................................................................................................................4
Data Integration Processes.......................................................................................................................4
Data Extraction....................................................................................................................................4
Dimension Reduction..........................................................................................................................5
Filtration..............................................................................................................................................6
Mutation..............................................................................................................................................6
New Information from Analysis..................................................................................................................7
Analysis Results......................................................................................................................................7
Possible Beneficiaries of New Information.............................................................................................9
Limitations and Assumptions................................................................................................................10
New Approaches in Data Integration Theories..........................................................................................10
Conclusion.................................................................................................................................................12
References.................................................................................................................................................13
Appendix: State Initials.............................................................................................................................15
2

Big Data Integration
Introduction
In the field of big data, one of the most crucial stages id the data integration stage. Data
integration refers to the process of effectively combining the data from different sources to form
a single data set ready for the analysis stage (Halaweh & El, 2014). Although not all applications
of big data require the use of data integration (for instance in single source big data applications),
using data from different sources and thereby applying data integration presents the best way of
harnessing the capabilities of big data (Revels & Nussbaumer, 2013).
Since data integration allows for the use of data from multiple sources in big data
approaches, is also by extension allows for the deriving of inferences based on multiple
perspectives. The incorporation of data from multiple sources broadens the view from the
analysis results in the big data approach. Having this broaden view enables decision making to
be more efficient, with as much information possible available for the decision maker.
This study is interested in the application of data integration, and subsequent analysis of
the resultant dataset, in the context of health. The study involves the integration of data from two
different sources to obtain a single dataset for the analysis process. The first dataset is on the
patient ratings of services in hospitals with the second one being on the change in mortality rate.
The data integration idea in this case is to end up with similar data points for both datasets
allowing the datasets to be correlated.
The analysis process involves the application of correlation and cluster analyses.
Correlation analysis is a big data approach that is interested in obtaining information on how two
or more variables are related with focus being on the type of relationship (positive or negative)
and the strength of the relationship (Everitt & Skrondal, 2010; Howitt & Cramer, 2010). Cluster
analysis is a categorizing algorithm that generates groups of items by utilizing available data and
3
Introduction
In the field of big data, one of the most crucial stages id the data integration stage. Data
integration refers to the process of effectively combining the data from different sources to form
a single data set ready for the analysis stage (Halaweh & El, 2014). Although not all applications
of big data require the use of data integration (for instance in single source big data applications),
using data from different sources and thereby applying data integration presents the best way of
harnessing the capabilities of big data (Revels & Nussbaumer, 2013).
Since data integration allows for the use of data from multiple sources in big data
approaches, is also by extension allows for the deriving of inferences based on multiple
perspectives. The incorporation of data from multiple sources broadens the view from the
analysis results in the big data approach. Having this broaden view enables decision making to
be more efficient, with as much information possible available for the decision maker.
This study is interested in the application of data integration, and subsequent analysis of
the resultant dataset, in the context of health. The study involves the integration of data from two
different sources to obtain a single dataset for the analysis process. The first dataset is on the
patient ratings of services in hospitals with the second one being on the change in mortality rate.
The data integration idea in this case is to end up with similar data points for both datasets
allowing the datasets to be correlated.
The analysis process involves the application of correlation and cluster analyses.
Correlation analysis is a big data approach that is interested in obtaining information on how two
or more variables are related with focus being on the type of relationship (positive or negative)
and the strength of the relationship (Everitt & Skrondal, 2010; Howitt & Cramer, 2010). Cluster
analysis is a categorizing algorithm that generates groups of items by utilizing available data and
3
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Big Data Integration
homogeneity levels of the data points (Beibei, Bo, Weiwei, & Ying, 2017; Daie & Li, 2016;
Malki & Rizk, 2016; Nakyoung, Sangdon, Joohyung, & Jun, 2018; Ren & Ying, 2010). In
addition, the possible beneficiaries of the inferences drawn from this study are identified. New
approaches for data integration theories are also explored, and their usefulness to the
stakeholders evaluated.
Data Integration
Data
Two datasets are utilized in this study for the analysis and eventual derivation of
inferences. The first dataset is on the patient ratings of services at hospitals in the United States
of America extracted from (Centers for Medicare & Medicaid Services, 2020). This dataset has
456 072 observations on a total of 23 attributes. The second dataset is on the mortality rates in
the United States of America from the years 1980 through to the year 2014 extracted from
(IHME, 2019). This dataset has 67 074 observations on 30 attributes.
Data Integration Processes
Data Extraction
The first stage of the data integration in this case was the extraction process where data
was collected from the Centers for Medicare & Medicaid Services (2020) and IHME (2019)
sources. The availability of download links in both the sources eliminated the need for applying
web-scrapping algorithms for the data extraction. The datasets were therefore obtained through
4
homogeneity levels of the data points (Beibei, Bo, Weiwei, & Ying, 2017; Daie & Li, 2016;
Malki & Rizk, 2016; Nakyoung, Sangdon, Joohyung, & Jun, 2018; Ren & Ying, 2010). In
addition, the possible beneficiaries of the inferences drawn from this study are identified. New
approaches for data integration theories are also explored, and their usefulness to the
stakeholders evaluated.
Data Integration
Data
Two datasets are utilized in this study for the analysis and eventual derivation of
inferences. The first dataset is on the patient ratings of services at hospitals in the United States
of America extracted from (Centers for Medicare & Medicaid Services, 2020). This dataset has
456 072 observations on a total of 23 attributes. The second dataset is on the mortality rates in
the United States of America from the years 1980 through to the year 2014 extracted from
(IHME, 2019). This dataset has 67 074 observations on 30 attributes.
Data Integration Processes
Data Extraction
The first stage of the data integration in this case was the extraction process where data
was collected from the Centers for Medicare & Medicaid Services (2020) and IHME (2019)
sources. The availability of download links in both the sources eliminated the need for applying
web-scrapping algorithms for the data extraction. The datasets were therefore obtained through
4
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Big Data Integration
downloading from the Centers for Medicare & Medicaid Services (2020) and IHME (2019)
sources.
Dimension Reduction
The second stage of the data integration was the dimension reduction process. Dimension
reduction refers to the process of reducing the number of variables in a dataset in order to remain
with the most relevant to the study (Douglas, William, & Samuel, 2012). Although there are
statistical approaches (such as principal analysis) that are used to determine which variables are
significant in a study, convenience and preference approaches can be applied to dimension
reduction. This form of dimension reduction is referred to as variable selection.
Variable selection is applied when the researcher is already aware of the variables of
interest in a study (may be based on prior information available to the researcher) (Fawcett &
Provost, 2013). For this case, in the first data set from Centers for Medicare & Medicaid Services
(2020), there are two variables of interest: State and Patient Survey Star Rating, reducing the
number of variables from 23 to 2 in this data set. In the second data set from IHME (2019), there
are also two variables of interest; Location and % Change in Mortality Rate, 1980-2014,
reducing the number of variables from 30 to 2 in this data set. Variable selection was achieved
through the deleting of the columns containing variables that will not be used in the study. This
process eliminated the obstacle of having too many variables in both data sets that will not be
relevant for the analysis phrase.
5
downloading from the Centers for Medicare & Medicaid Services (2020) and IHME (2019)
sources.
Dimension Reduction
The second stage of the data integration was the dimension reduction process. Dimension
reduction refers to the process of reducing the number of variables in a dataset in order to remain
with the most relevant to the study (Douglas, William, & Samuel, 2012). Although there are
statistical approaches (such as principal analysis) that are used to determine which variables are
significant in a study, convenience and preference approaches can be applied to dimension
reduction. This form of dimension reduction is referred to as variable selection.
Variable selection is applied when the researcher is already aware of the variables of
interest in a study (may be based on prior information available to the researcher) (Fawcett &
Provost, 2013). For this case, in the first data set from Centers for Medicare & Medicaid Services
(2020), there are two variables of interest: State and Patient Survey Star Rating, reducing the
number of variables from 23 to 2 in this data set. In the second data set from IHME (2019), there
are also two variables of interest; Location and % Change in Mortality Rate, 1980-2014,
reducing the number of variables from 30 to 2 in this data set. Variable selection was achieved
through the deleting of the columns containing variables that will not be used in the study. This
process eliminated the obstacle of having too many variables in both data sets that will not be
relevant for the analysis phrase.
5

Big Data Integration
Filtration
The third stage of the data integration was the filtration process. Filtration refers to the
specification of the criteria to be met by the desired data points in a data set and applying the
criteria to reduce the data points (Shaffer, 2011). In the first dataset from Centers for Medicare &
Medicaid Services (2020), we are faced with an obstacle of some of the entries on the Patient
Survey Star Rating variable being either Not Applicable or Not Available. These entries cannot
be used for the analysis process and have to removed from the dataset. Using the filtration tool in
MS Excel, the data points with either Not Applicable or Not Available entries on the Patient
Survey Star Rating variable were excluded from the first dataset.
Mutation
The fourth stage of the data integration is the mutation process. Mutation in data analysis
refers to the transformation of data to form either completely new data points and new variables
or simply new variables with the same data points as in the original data set (Minelli, Chambers,
& Diraj, 2013). The mutation process involves the use of arithmetic process and/or mathematical
formulae to create the new variables. Where there is need for creation of new data points, the
mutation process extends to grouping of data points based on a categorical variable to make the
new data points with single entries of each category of the categorical variable. The arithmetic
process and/or mathematical formulae are then applied to create the new variables.
In this case, we are faced with the obstacle of difference in data points between the data
sets from the Centers for Medicare & Medicaid Services (2020) and IHME (2019) sources even
after the processes from stage 1 to 3 of data integration. It is necessary to overcome the
6
Filtration
The third stage of the data integration was the filtration process. Filtration refers to the
specification of the criteria to be met by the desired data points in a data set and applying the
criteria to reduce the data points (Shaffer, 2011). In the first dataset from Centers for Medicare &
Medicaid Services (2020), we are faced with an obstacle of some of the entries on the Patient
Survey Star Rating variable being either Not Applicable or Not Available. These entries cannot
be used for the analysis process and have to removed from the dataset. Using the filtration tool in
MS Excel, the data points with either Not Applicable or Not Available entries on the Patient
Survey Star Rating variable were excluded from the first dataset.
Mutation
The fourth stage of the data integration is the mutation process. Mutation in data analysis
refers to the transformation of data to form either completely new data points and new variables
or simply new variables with the same data points as in the original data set (Minelli, Chambers,
& Diraj, 2013). The mutation process involves the use of arithmetic process and/or mathematical
formulae to create the new variables. Where there is need for creation of new data points, the
mutation process extends to grouping of data points based on a categorical variable to make the
new data points with single entries of each category of the categorical variable. The arithmetic
process and/or mathematical formulae are then applied to create the new variables.
In this case, we are faced with the obstacle of difference in data points between the data
sets from the Centers for Medicare & Medicaid Services (2020) and IHME (2019) sources even
after the processes from stage 1 to 3 of data integration. It is necessary to overcome the
6
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Big Data Integration
difference in data points in data integration in order to merge the data sets into one (Yinying,
2016).
In both the data sets from the Centers for Medicare & Medicaid Services (2020) and
IHME (2019) sources, the categorical variables: State and Location are mutated to form a new
categorical variable State in the integrated dataset. In the first data set from Centers for Medicare
& Medicaid Services (2020), the average value of the Patient Survey Star Rating for each state is
obtained to form the variable Patient Survey Star Rating in the integrated data set. In the second
data set from IHME (2019), the average value for the % Change in Mortality Rate, 1980-2014
for each of the state is obtained to form the variable % Change in Mortality Rate, 1980-2014 in
the integrated dataset.
New Information from Analysis
Analysis Results
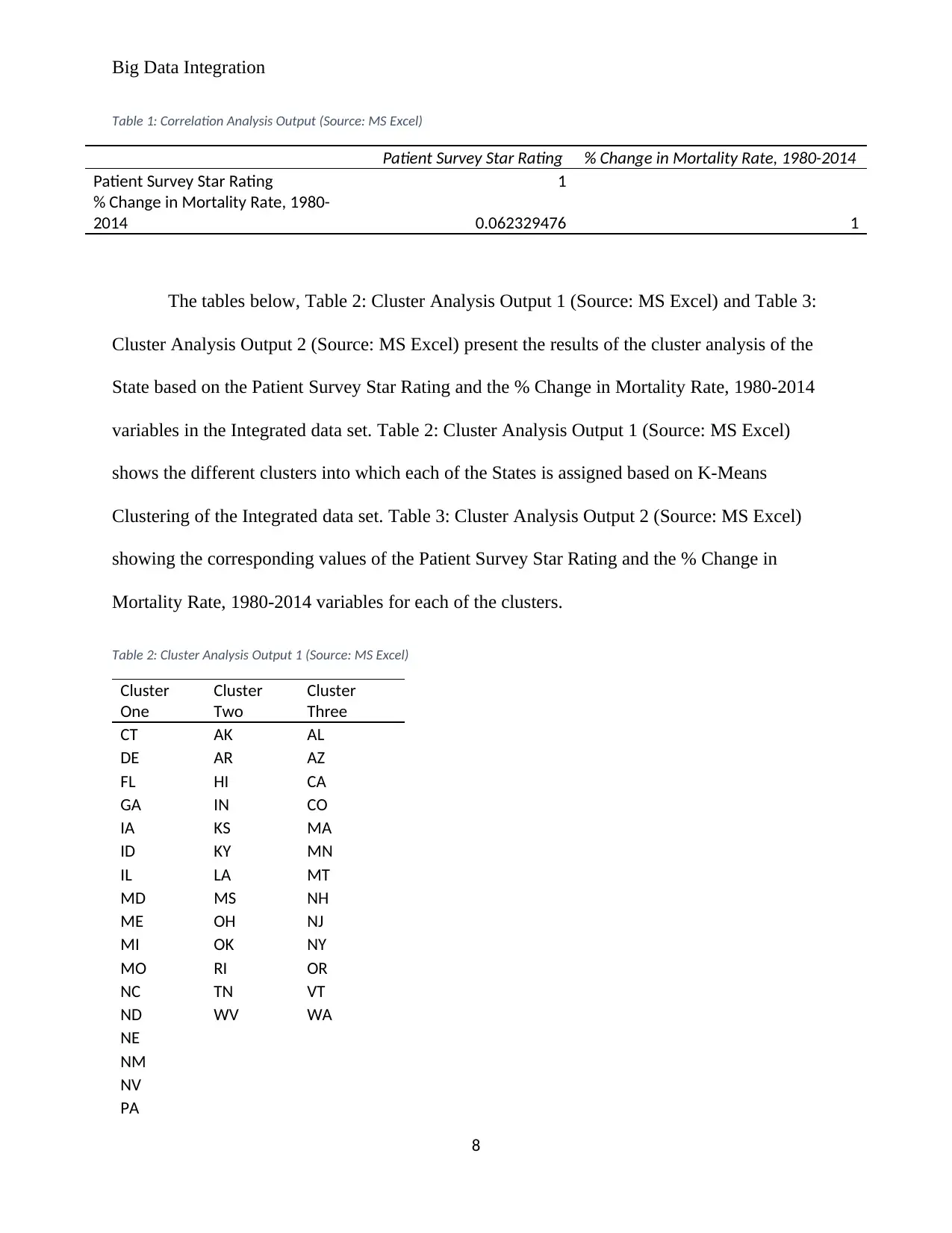
The table below, Table 1: Correlation Analysis Output (Source: MS Excel) presents the
results of the correlation analysis between the Patient Survey Star Rating and the % Change in
Mortality Rate, 1980-2014 variables in the Integrated data set. The analysis from the table gives
the correlation between the two variables as 0.0623, which points at a positive relationship since
the value is positive. This implies that states with high % Change in Mortality Rate between
1980-2014 are more likely to have high Patient Survey Star Rating. However, the value is small;
hence, this relationship is significantly weak.
7
difference in data points in data integration in order to merge the data sets into one (Yinying,
2016).
In both the data sets from the Centers for Medicare & Medicaid Services (2020) and
IHME (2019) sources, the categorical variables: State and Location are mutated to form a new
categorical variable State in the integrated dataset. In the first data set from Centers for Medicare
& Medicaid Services (2020), the average value of the Patient Survey Star Rating for each state is
obtained to form the variable Patient Survey Star Rating in the integrated data set. In the second
data set from IHME (2019), the average value for the % Change in Mortality Rate, 1980-2014
for each of the state is obtained to form the variable % Change in Mortality Rate, 1980-2014 in
the integrated dataset.
New Information from Analysis
Analysis Results
The table below, Table 1: Correlation Analysis Output (Source: MS Excel) presents the
results of the correlation analysis between the Patient Survey Star Rating and the % Change in
Mortality Rate, 1980-2014 variables in the Integrated data set. The analysis from the table gives
the correlation between the two variables as 0.0623, which points at a positive relationship since
the value is positive. This implies that states with high % Change in Mortality Rate between
1980-2014 are more likely to have high Patient Survey Star Rating. However, the value is small;
hence, this relationship is significantly weak.
7
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
Big Data Integration
Table 1: Correlation Analysis Output (Source: MS Excel)
Patient Survey Star Rating % Change in Mortality Rate, 1980-2014
Patient Survey Star Rating 1
% Change in Mortality Rate, 1980-
2014 0.062329476 1
The tables below, Table 2: Cluster Analysis Output 1 (Source: MS Excel) and Table 3:
Cluster Analysis Output 2 (Source: MS Excel) present the results of the cluster analysis of the
State based on the Patient Survey Star Rating and the % Change in Mortality Rate, 1980-2014
variables in the Integrated data set. Table 2: Cluster Analysis Output 1 (Source: MS Excel)
shows the different clusters into which each of the States is assigned based on K-Means
Clustering of the Integrated data set. Table 3: Cluster Analysis Output 2 (Source: MS Excel)
showing the corresponding values of the Patient Survey Star Rating and the % Change in
Mortality Rate, 1980-2014 variables for each of the clusters.
Table 2: Cluster Analysis Output 1 (Source: MS Excel)
Cluster
One
Cluster
Two
Cluster
Three
CT AK AL
DE AR AZ
FL HI CA
GA IN CO
IA KS MA
ID KY MN
IL LA MT
MD MS NH
ME OH NJ
MI OK NY
MO RI OR
NC TN VT
ND WV WA
NE
NM
NV
PA
8
Table 1: Correlation Analysis Output (Source: MS Excel)
Patient Survey Star Rating % Change in Mortality Rate, 1980-2014
Patient Survey Star Rating 1
% Change in Mortality Rate, 1980-
2014 0.062329476 1
The tables below, Table 2: Cluster Analysis Output 1 (Source: MS Excel) and Table 3:
Cluster Analysis Output 2 (Source: MS Excel) present the results of the cluster analysis of the
State based on the Patient Survey Star Rating and the % Change in Mortality Rate, 1980-2014
variables in the Integrated data set. Table 2: Cluster Analysis Output 1 (Source: MS Excel)
shows the different clusters into which each of the States is assigned based on K-Means
Clustering of the Integrated data set. Table 3: Cluster Analysis Output 2 (Source: MS Excel)
showing the corresponding values of the Patient Survey Star Rating and the % Change in
Mortality Rate, 1980-2014 variables for each of the clusters.
Table 2: Cluster Analysis Output 1 (Source: MS Excel)
Cluster
One
Cluster
Two
Cluster
Three
CT AK AL
DE AR AZ
FL HI CA
GA IN CO
IA KS MA
ID KY MN
IL LA MT
MD MS NH
ME OH NJ
MI OK NY
MO RI OR
NC TN VT
ND WV WA
NE
NM
NV
PA
8

Big Data Integration
SC
SD
TX
UT
VA
WI
WY
Table 3: Cluster Analysis Output 2 (Source: MS Excel)
Centroid 1 2 3
Patient Survey Star Rating 3.243689 3.319041 3.193873
% Change in Mortality Rate, 1980-
2014 -63.1279 -56.9369 -68.4869
Possible Beneficiaries of New Information
Four main groups would benefit from the inferences drawn from the analysis in this study
as well as the potential further analysis in the same area of study. These groups are
psychologists, policy makers in health sector and researchers. Psychologists get a better
understanding of the relationship between a society's experience of death and there opinion on
the medical services. The policy makers in the health sector can better plan for health in the
different states by considering the similarity that exist between the states in similar clusters. The
inferences drawn for the analysis contribute to the existing body of knowledge on perception of
medical service by patients. Hence, making it an import reference material for researchers in the
field.
Limitations and Assumptions
The main limitation of the analysis process in this study is the difference in the data
collection process of the data in the Centers for Medicare & Medicaid Services (2020) and
9
SC
SD
TX
UT
VA
WI
WY
Table 3: Cluster Analysis Output 2 (Source: MS Excel)
Centroid 1 2 3
Patient Survey Star Rating 3.243689 3.319041 3.193873
% Change in Mortality Rate, 1980-
2014 -63.1279 -56.9369 -68.4869
Possible Beneficiaries of New Information
Four main groups would benefit from the inferences drawn from the analysis in this study
as well as the potential further analysis in the same area of study. These groups are
psychologists, policy makers in health sector and researchers. Psychologists get a better
understanding of the relationship between a society's experience of death and there opinion on
the medical services. The policy makers in the health sector can better plan for health in the
different states by considering the similarity that exist between the states in similar clusters. The
inferences drawn for the analysis contribute to the existing body of knowledge on perception of
medical service by patients. Hence, making it an import reference material for researchers in the
field.
Limitations and Assumptions
The main limitation of the analysis process in this study is the difference in the data
collection process of the data in the Centers for Medicare & Medicaid Services (2020) and
9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Big Data Integration
IHME (2019) sources, with the former being cross-sectional data and the latter being
longitudinal data. Longitudinal data refers to data collected over different periods repeatedly on
the same attribute while cross sectional data refers to data collected at a given point in time
(Minelli, Chambers, & Diraj, 2013). In the integrated data, the Patient Survey Star Rating
represents average on data collected only once while the % Change in Mortality Rate, 1980-2014
represent average on aggregated data from 1980 to 2014. If the Patient Survey Star Rating also
represented average on aggregated data from 1980 to 2014 then the findings would be a better
measure of the relationship and the clustering.
For the correlation analysis, the data was assumed to have followed a normal distribution,
have no outliers and to have both linearity and homoscedasticity. The K Means clustering
assumed that the clusters and similar (in terms of size) and spherical.
New Approaches in Data Integration Theories
The ETL (Extract-Transform-Load) data integration theory lacks in detailing since it
completely ignores the data-cleaning phrase of data integration. This theory assumed that data
cleaning is part of data transformation, however the cleaning process involves the removal of
either data points (filtering) or variables (dimension reduction and variable selection) while the
transformation process involves modifying of the existing data points and variables. Hence, a
new model of the ETL (Extract-Transform-Load) data integration theory would look like Figure
1: ECTL Data Integration Theory below. This theory would be crucial in providing a more
elaborate approach to data integration.
10
IHME (2019) sources, with the former being cross-sectional data and the latter being
longitudinal data. Longitudinal data refers to data collected over different periods repeatedly on
the same attribute while cross sectional data refers to data collected at a given point in time
(Minelli, Chambers, & Diraj, 2013). In the integrated data, the Patient Survey Star Rating
represents average on data collected only once while the % Change in Mortality Rate, 1980-2014
represent average on aggregated data from 1980 to 2014. If the Patient Survey Star Rating also
represented average on aggregated data from 1980 to 2014 then the findings would be a better
measure of the relationship and the clustering.
For the correlation analysis, the data was assumed to have followed a normal distribution,
have no outliers and to have both linearity and homoscedasticity. The K Means clustering
assumed that the clusters and similar (in terms of size) and spherical.
New Approaches in Data Integration Theories
The ETL (Extract-Transform-Load) data integration theory lacks in detailing since it
completely ignores the data-cleaning phrase of data integration. This theory assumed that data
cleaning is part of data transformation, however the cleaning process involves the removal of
either data points (filtering) or variables (dimension reduction and variable selection) while the
transformation process involves modifying of the existing data points and variables. Hence, a
new model of the ETL (Extract-Transform-Load) data integration theory would look like Figure
1: ECTL Data Integration Theory below. This theory would be crucial in providing a more
elaborate approach to data integration.
10
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Big Data Integration
Figure 1: ECTL Data Integration Theory
Another approach involves the introduction of a pre-filtering stage, which focuses on
removing any null and incorrect entries in the datasets. The pre-filtering stage would
immediately follow the data extraction stage. This would increase clarity in the analysis stage
with regards to the variables and data points to include and exclude. It prevents the loss of data,
which might occur if filtration is done after or simultaneously with variable selection and
mutation. Figure 2: Pre-Filtration Data Integration Theory below represents this approach.
11
Figure 1: ECTL Data Integration Theory
Another approach involves the introduction of a pre-filtering stage, which focuses on
removing any null and incorrect entries in the datasets. The pre-filtering stage would
immediately follow the data extraction stage. This would increase clarity in the analysis stage
with regards to the variables and data points to include and exclude. It prevents the loss of data,
which might occur if filtration is done after or simultaneously with variable selection and
mutation. Figure 2: Pre-Filtration Data Integration Theory below represents this approach.
11

Big Data Integration
Figure 2: Pre-Filtration Data Integration Theory
Conclusion
The analysis in this study concludes that there is a positive correlation between the
patient ratings of hospitals in the different states in the United States of America and the
percentage change in mortality in those states. However, the strength of this correlation is
significantly weak. The analysis also reveal that with respect to the patient ratings of hospitals in
the different states in the United States of America and the percentage change in mortality in
those states, the states can be grouped into three clusters as seen in Table 2: Cluster Analysis
Output 1 (Source: MS Excel) above. The inference drawn from the analysis in this study have
been shown to be beneficial to psychologists, health policy makers and researchers. The study
has also shown that modifications need to be made to current data integration theories in order to
make them more elaborate and efficient.
12
Figure 2: Pre-Filtration Data Integration Theory
Conclusion
The analysis in this study concludes that there is a positive correlation between the
patient ratings of hospitals in the different states in the United States of America and the
percentage change in mortality in those states. However, the strength of this correlation is
significantly weak. The analysis also reveal that with respect to the patient ratings of hospitals in
the different states in the United States of America and the percentage change in mortality in
those states, the states can be grouped into three clusters as seen in Table 2: Cluster Analysis
Output 1 (Source: MS Excel) above. The inference drawn from the analysis in this study have
been shown to be beneficial to psychologists, health policy makers and researchers. The study
has also shown that modifications need to be made to current data integration theories in order to
make them more elaborate and efficient.
12
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 15


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.