Insights Report on Business Analytics
VerifiedAdded on 2023/01/20
|12
|1782
|46
AI Summary
This insights report provides an analysis of business analytics, including visualization, presentability, and key information derived. It also offers recommendations for improvement.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Running head: BUSINESS ANALYTICS 1
Business Analytics
Student Name
Professor’s Name
University Name
Date
Business Analytics
Student Name
Professor’s Name
University Name
Date
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

BUSINESS ANALYTICS 2
Question 1: CASE ANALYSIS SCENARIO
I. Insights Report Overall Features
a) Visualization
A good visualization is important since it enables the report being presented
visually attractive, easy to navigate through and hence makes the process of retrieving
information very simple. The insight report uses a simple, clear and to the point
visualization. It is blended with a good combination of colors that inhibit from being
too boring or too much overwhelming. Additionally, it uses pictorial representations
such as bar graphs, histograms and maps to summarize the textual content. This
makes it easier for the reader to retrieve the information needed in a simple, manner
as well as analyze the trends and patterns from the graphical displays.
b) Presentability
Data presentation is a very important aspect of statistics since it simplifies the
process of understanding the data. In this case various method of data presentation
have been used. Use of fonts of different sizes is evident. Larger fonts are used for
titles and headings while small texts are used for detailing and description. Where
emphasis is needed, a different font color is used. Graphical representations inform of
left sided histograms, and bar graphs is evident. The graphs have been used to
summarize all the information in words as well as assist the reader in analyzing the
patterns and the trends.
c) Information Provided
The information provided by the insights report is straight to the point. Detailed
information is provided in fewest words possible and supported by a graphical
Question 1: CASE ANALYSIS SCENARIO
I. Insights Report Overall Features
a) Visualization
A good visualization is important since it enables the report being presented
visually attractive, easy to navigate through and hence makes the process of retrieving
information very simple. The insight report uses a simple, clear and to the point
visualization. It is blended with a good combination of colors that inhibit from being
too boring or too much overwhelming. Additionally, it uses pictorial representations
such as bar graphs, histograms and maps to summarize the textual content. This
makes it easier for the reader to retrieve the information needed in a simple, manner
as well as analyze the trends and patterns from the graphical displays.
b) Presentability
Data presentation is a very important aspect of statistics since it simplifies the
process of understanding the data. In this case various method of data presentation
have been used. Use of fonts of different sizes is evident. Larger fonts are used for
titles and headings while small texts are used for detailing and description. Where
emphasis is needed, a different font color is used. Graphical representations inform of
left sided histograms, and bar graphs is evident. The graphs have been used to
summarize all the information in words as well as assist the reader in analyzing the
patterns and the trends.
c) Information Provided
The information provided by the insights report is straight to the point. Detailed
information is provided in fewest words possible and supported by a graphical

BUSINESS ANALYTICS 3
display. The insights report avoids being too much wordy and only provide the
relevant information. This makes it easier for the reader to retrieve vital information
easily and objectively.
II. Key Information Derived from Insight Report
The key objective of this insight report is to understand how the Australian retail
sector is responding to adopting innovative measures to promote their undertakings.
Therefore, the key information that can be derived from the insight report is the over
view information about the Australian retail market, the performance of the entities based
on adoption or rejection of the innovation techniques, the information innovative
techniques embraced, the dynamics of innovation and the expected returns of the
investment.
The overview information on Australian market based on the data collected can
be used to determine if the data is effective and decide whether it can be used in the
analysis and the study, the information on investment, returns of investment, and
performance based on adoption or rejection of innovative technique can be used to decide
whether it worthy to adopt an innovative technique or not and as well decide of the best
innovative technique to adopt.
III. Summarization Abstract
The Australian retail sector is adopting various innovative techniques by adopting
innovative techniques that aid them to maximize opportunities, increase customer
experience, and maintain or grow their performances while inhibiting or combating the
pressures of competition. Analysis performed on data collected on behalf of the
CommBank indicate that 87% of the retailers in Australia are adopting innovative
techniques or are innovation improves. 71% of this population comprise of multi-channel
retailers. The analysis also shows that the retailers who have accepted to adopt the
display. The insights report avoids being too much wordy and only provide the
relevant information. This makes it easier for the reader to retrieve vital information
easily and objectively.
II. Key Information Derived from Insight Report
The key objective of this insight report is to understand how the Australian retail
sector is responding to adopting innovative measures to promote their undertakings.
Therefore, the key information that can be derived from the insight report is the over
view information about the Australian retail market, the performance of the entities based
on adoption or rejection of the innovation techniques, the information innovative
techniques embraced, the dynamics of innovation and the expected returns of the
investment.
The overview information on Australian market based on the data collected can
be used to determine if the data is effective and decide whether it can be used in the
analysis and the study, the information on investment, returns of investment, and
performance based on adoption or rejection of innovative technique can be used to decide
whether it worthy to adopt an innovative technique or not and as well decide of the best
innovative technique to adopt.
III. Summarization Abstract
The Australian retail sector is adopting various innovative techniques by adopting
innovative techniques that aid them to maximize opportunities, increase customer
experience, and maintain or grow their performances while inhibiting or combating the
pressures of competition. Analysis performed on data collected on behalf of the
CommBank indicate that 87% of the retailers in Australia are adopting innovative
techniques or are innovation improves. 71% of this population comprise of multi-channel
retailers. The analysis also shows that the retailers who have accepted to adopt the

BUSINESS ANALYTICS 4
innovative technique are adopting it in different ways; 48% of innovation adopters invest
in sales and marketing while 55% invest in websites and other digital platforms. Those
who have accepted to invest in innovation expect return on investment within an year of
investment.
IV. Recommendations for Improvement
The recommendations for improvement of the insight report would be to store it
in an editable format that would allow future adjustment be easily made, be customizable
so that a reader would only and navigate through the information he/she needed rather
than going through the entire report, have a conclusion summarizing the analysis and
giving recommendation for further studies. Additionally, the length is quite big for an
insight report, it should be made shorter so as to limit the possibility of a reader boredom
midway through the reading.
Question2: Regression Analysis.
I. Applications of Regression
Regression is used in statistics to show the relationship between the independent
and the dependent variable. In real world analytics regression is used to predict the
unforeseen upcoming happenings (Lock, 2013). For example, regression analysis can be
used to show the relationship between the products sold in a given business entity and the
number of customers expected in the premises for the given product. Besides, regression
analysis is used to fine tune operations of a business entity by checking the relationship
between quality obtained and the other factors that are likely to affect the quality.
II. Data for Weight and Height
The table below shows heights and weights obtained from 10 different friends.
innovative technique are adopting it in different ways; 48% of innovation adopters invest
in sales and marketing while 55% invest in websites and other digital platforms. Those
who have accepted to invest in innovation expect return on investment within an year of
investment.
IV. Recommendations for Improvement
The recommendations for improvement of the insight report would be to store it
in an editable format that would allow future adjustment be easily made, be customizable
so that a reader would only and navigate through the information he/she needed rather
than going through the entire report, have a conclusion summarizing the analysis and
giving recommendation for further studies. Additionally, the length is quite big for an
insight report, it should be made shorter so as to limit the possibility of a reader boredom
midway through the reading.
Question2: Regression Analysis.
I. Applications of Regression
Regression is used in statistics to show the relationship between the independent
and the dependent variable. In real world analytics regression is used to predict the
unforeseen upcoming happenings (Lock, 2013). For example, regression analysis can be
used to show the relationship between the products sold in a given business entity and the
number of customers expected in the premises for the given product. Besides, regression
analysis is used to fine tune operations of a business entity by checking the relationship
between quality obtained and the other factors that are likely to affect the quality.
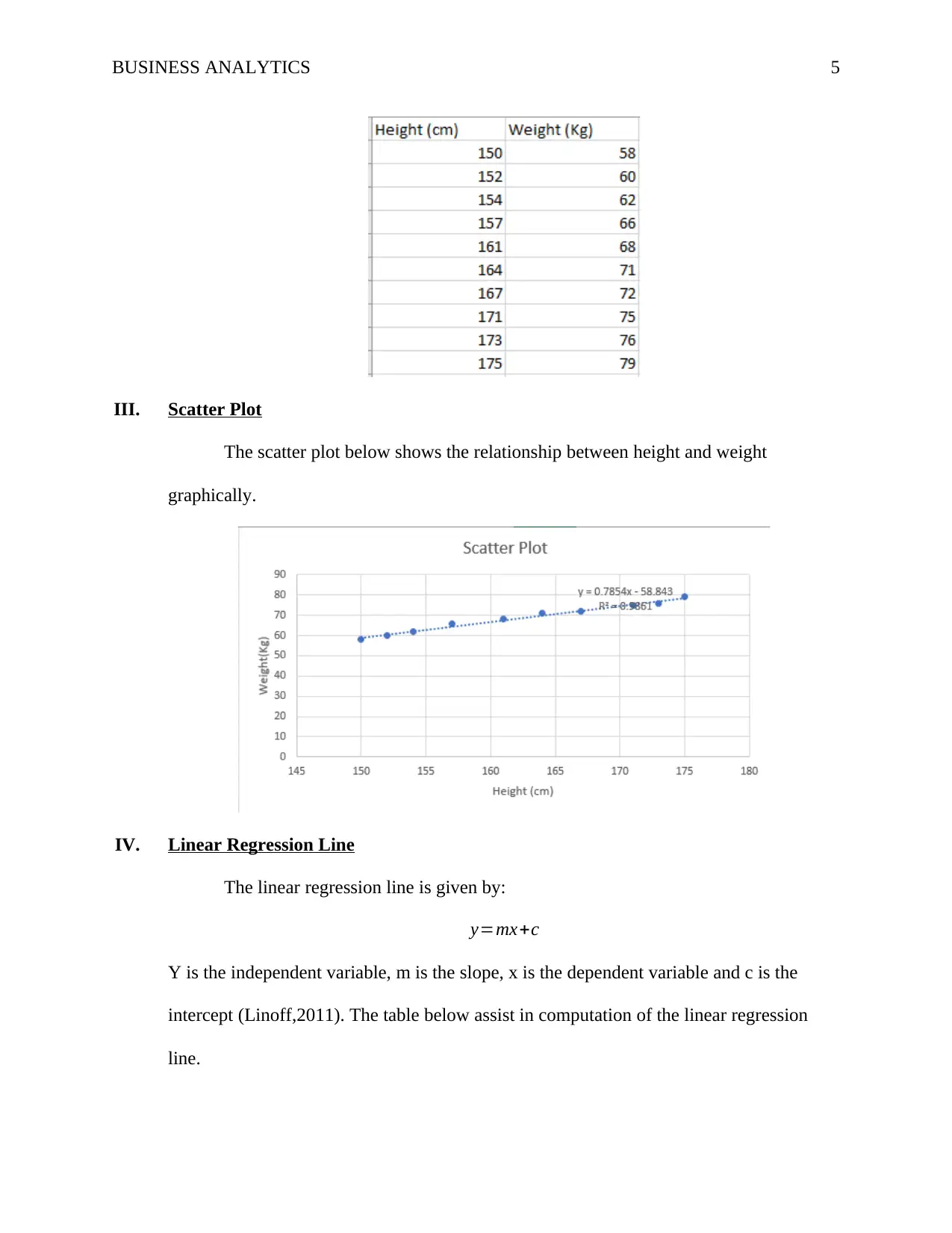
II. Data for Weight and Height
The table below shows heights and weights obtained from 10 different friends.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.
BUSINESS ANALYTICS 5
III. Scatter Plot
The scatter plot below shows the relationship between height and weight
graphically.
IV. Linear Regression Line
The linear regression line is given by:
y=mx+c
Y is the independent variable, m is the slope, x is the dependent variable and c is the
intercept (Linoff,2011). The table below assist in computation of the linear regression
line.
III. Scatter Plot
The scatter plot below shows the relationship between height and weight
graphically.
IV. Linear Regression Line
The linear regression line is given by:
y=mx+c
Y is the independent variable, m is the slope, x is the dependent variable and c is the
intercept (Linoff,2011). The table below assist in computation of the linear regression
line.

BUSINESS ANALYTICS 6
The slope (m) is the coefficient of the independent variable indicating by how
much the variable affects the dependent variable. It is determined by:
m= n ( Σx y ) −( Σ x)( Σ y )
n ( Σ x2 ) −¿ ¿
m= ( 10 ) ( 112144 )−(1624)(687)
10 ( 264470 )−¿ ¿
m= 5752
7324
m=0.7854
The intercept is the value of dependent variable when the independent variable is
at nil. It determined by:
c= ( Σ y ) ( Σ x2 ) −( Σ x)( Σ xy )
n ( Σ x2 )−¿ ¿
c= ( 687 ) ( 264470 ) −(1624)(112144)
10 ( 264470 ) −¿ ¿
c=−430966
7324
c=−58.843
The regression equation therefore becomes:
The slope (m) is the coefficient of the independent variable indicating by how
much the variable affects the dependent variable. It is determined by:
m= n ( Σx y ) −( Σ x)( Σ y )
n ( Σ x2 ) −¿ ¿
m= ( 10 ) ( 112144 )−(1624)(687)
10 ( 264470 )−¿ ¿
m= 5752
7324
m=0.7854
The intercept is the value of dependent variable when the independent variable is
at nil. It determined by:
c= ( Σ y ) ( Σ x2 ) −( Σ x)( Σ xy )
n ( Σ x2 )−¿ ¿
c= ( 687 ) ( 264470 ) −(1624)(112144)
10 ( 264470 ) −¿ ¿
c=−430966
7324
c=−58.843
The regression equation therefore becomes:

BUSINESS ANALYTICS 7
y=0.7854 x−58.843
V. Coefficient of determination
The r-square value is determined as follows:
r =n ( Σx y )−(Σ x )(Σ y )
√¿ ¿ ¿
r = ( 10 ) ( 112144 )−(1624)(687)
√ [ 10 ( 264470 )− (1624 )2 ] [10 ( 47655 )− ( 687 )2 ]
r = 5752
5792.343567
r =0.9931
The r-squared value is therefore:
r2=0.99312
r2=0.9861
The value obtained indicates that 98.61% of the relationship between the variables is
explained by the regression model created. The r value shows there is a strong positive
linear relationship between the variable’s height and weight.
VI. Analytic Tool Application
Microsoft excel is the analytic tool chosen to carry out the regression analysis and
hence determine the linear regression equation as well as the value of R-squared. The
results are as shown below:
y=0.7854 x−58.843
V. Coefficient of determination
The r-square value is determined as follows:
r =n ( Σx y )−(Σ x )(Σ y )
√¿ ¿ ¿
r = ( 10 ) ( 112144 )−(1624)(687)
√ [ 10 ( 264470 )− (1624 )2 ] [10 ( 47655 )− ( 687 )2 ]
r = 5752
5792.343567
r =0.9931
The r-squared value is therefore:
r2=0.99312
r2=0.9861
The value obtained indicates that 98.61% of the relationship between the variables is
explained by the regression model created. The r value shows there is a strong positive
linear relationship between the variable’s height and weight.
VI. Analytic Tool Application
Microsoft excel is the analytic tool chosen to carry out the regression analysis and
hence determine the linear regression equation as well as the value of R-squared. The
results are as shown below:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
BUSINESS ANALYTICS 8
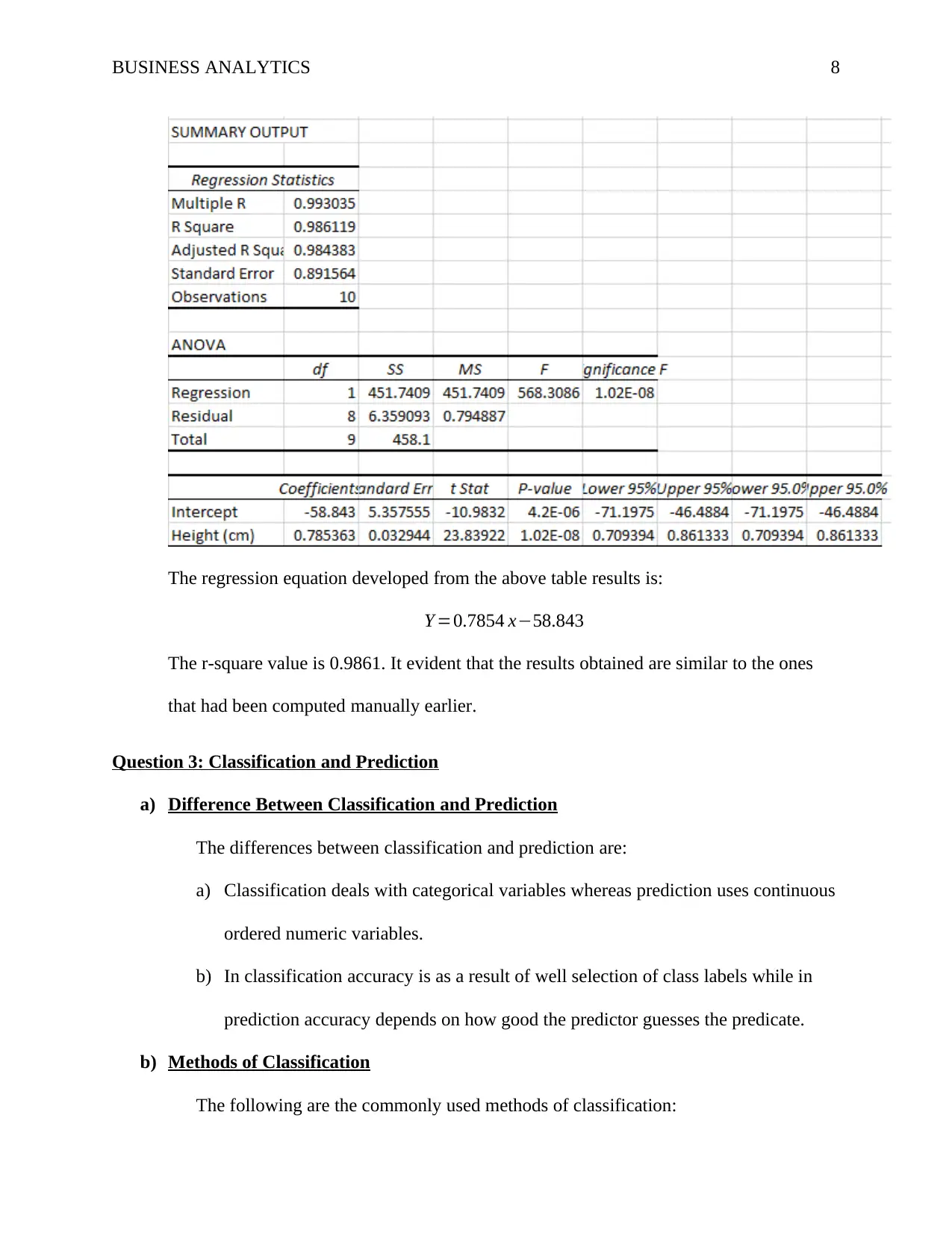
The regression equation developed from the above table results is:
Y =0.7854 x−58.843
The r-square value is 0.9861. It evident that the results obtained are similar to the ones
that had been computed manually earlier.
Question 3: Classification and Prediction
a) Difference Between Classification and Prediction
The differences between classification and prediction are:
a) Classification deals with categorical variables whereas prediction uses continuous
ordered numeric variables.
b) In classification accuracy is as a result of well selection of class labels while in
prediction accuracy depends on how good the predictor guesses the predicate.
b) Methods of Classification
The following are the commonly used methods of classification:
The regression equation developed from the above table results is:
Y =0.7854 x−58.843
The r-square value is 0.9861. It evident that the results obtained are similar to the ones
that had been computed manually earlier.
Question 3: Classification and Prediction
a) Difference Between Classification and Prediction
The differences between classification and prediction are:
a) Classification deals with categorical variables whereas prediction uses continuous
ordered numeric variables.
b) In classification accuracy is as a result of well selection of class labels while in
prediction accuracy depends on how good the predictor guesses the predicate.
b) Methods of Classification
The following are the commonly used methods of classification:

BUSINESS ANALYTICS 9
a. Naïve Bayes Classification: Here the dataset dedicated for training is perused
through or scanned such that all records with similar predictor values are found
(Shao, 2010). Observations are assigned the most prevalent group. When the
predictor value becomes equal to predictor value of a group, the observation is
placed to the class.
b. Neural Network method: Neural networks process records each at a time and
compares them with a known classification of records (Rumsey, 2015). Any
occurring errors from the classification are fed back to the network to modify the
algorithm.
c. K-Nearest Neighbors Method: The training dataset is sub-divided into groups
with k observations using the Euclidean Distance Measure and Neighbors
exhibiting similar properties are determined.
d. Logistic Regression Method: This regression different from the normal
regression which is applied in forecasting or predicting responses. It is strictly
applied when the response variable is dichotomous.
e. Decision trees: The method uses a flow diagram that resembles a tree. The
branches represent result of a test performed on an attribute, non-leaf node
indicates the test performed and the leaf node represents the class label.
f. Discriminant Analysis: Linear functions consisting of the predictor variable are
created and used for prediction of observation classes using an unknown class.
c) Develop Algebraic Equation from Neural Network
a) Algebraic Equation
a. Naïve Bayes Classification: Here the dataset dedicated for training is perused
through or scanned such that all records with similar predictor values are found
(Shao, 2010). Observations are assigned the most prevalent group. When the
predictor value becomes equal to predictor value of a group, the observation is
placed to the class.
b. Neural Network method: Neural networks process records each at a time and
compares them with a known classification of records (Rumsey, 2015). Any
occurring errors from the classification are fed back to the network to modify the
algorithm.
c. K-Nearest Neighbors Method: The training dataset is sub-divided into groups
with k observations using the Euclidean Distance Measure and Neighbors
exhibiting similar properties are determined.
d. Logistic Regression Method: This regression different from the normal
regression which is applied in forecasting or predicting responses. It is strictly
applied when the response variable is dichotomous.
e. Decision trees: The method uses a flow diagram that resembles a tree. The
branches represent result of a test performed on an attribute, non-leaf node
indicates the test performed and the leaf node represents the class label.
f. Discriminant Analysis: Linear functions consisting of the predictor variable are
created and used for prediction of observation classes using an unknown class.
c) Develop Algebraic Equation from Neural Network
a) Algebraic Equation

BUSINESS ANALYTICS 10
Given the following neural network that has got one hidden layer, the
equation of the output can be determined as follows:
The equations of the hidden are:
h1=σ (i1 w1 +i2 w3 +b1 )
h2 =σ ( i1 w2+ i2 w4 +b2 )
The value of the output y1 is determined after solving for h1 and h2 and substituting
into the equation of the output below:
y1=σ ( h1 w5 +h2 w6 )
b) Working Principle of Neural Networks
The operation of the neural network is pretty much similar to that of the
brain. The neural networks scan a record individual at each particular time and
learns by comparing it with a known classification. Any error or distinction from
the initial classification is fed back to the network so that it can modify the
algorithm. The process is carried out iteratively until the desired classification
accuracy is reached.
d) Applications of Clustering in Business Analytics.
Given the following neural network that has got one hidden layer, the
equation of the output can be determined as follows:
The equations of the hidden are:
h1=σ (i1 w1 +i2 w3 +b1 )
h2 =σ ( i1 w2+ i2 w4 +b2 )
The value of the output y1 is determined after solving for h1 and h2 and substituting
into the equation of the output below:
y1=σ ( h1 w5 +h2 w6 )
b) Working Principle of Neural Networks
The operation of the neural network is pretty much similar to that of the
brain. The neural networks scan a record individual at each particular time and
learns by comparing it with a known classification. Any error or distinction from
the initial classification is fed back to the network so that it can modify the
algorithm. The process is carried out iteratively until the desired classification
accuracy is reached.
d) Applications of Clustering in Business Analytics.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

BUSINESS ANALYTICS 11
Clustering is the process of grouping objects, observations or records with similar
characteristics. In real world analytics it is applied in the following areas:
Segmentation of products: In this case products with similar physical characteristics are
grouped together it ease the process of identification, pricing and to promote
attractiveness.
Market research: In this case consumers of products are grouped based on either their
purchase capabilities or based on their demand needs, then a market for the products they
can purchase or need is set-up based on these clusters.
Promotion of Quality: in this scenario the clustering is used to determine the presence of
defective products or fraud transaction. Products and transactions that meet a certain
criterion are consider okay and placed in one cluster, those that to meet the set standards
fall outside this cluster and are thus considered suspicious.
Clustering is the process of grouping objects, observations or records with similar
characteristics. In real world analytics it is applied in the following areas:
Segmentation of products: In this case products with similar physical characteristics are
grouped together it ease the process of identification, pricing and to promote
attractiveness.
Market research: In this case consumers of products are grouped based on either their
purchase capabilities or based on their demand needs, then a market for the products they
can purchase or need is set-up based on these clusters.
Promotion of Quality: in this scenario the clustering is used to determine the presence of
defective products or fraud transaction. Products and transactions that meet a certain
criterion are consider okay and placed in one cluster, those that to meet the set standards
fall outside this cluster and are thus considered suspicious.

BUSINESS ANALYTICS 12
References
Linoff, G. (2011). Data analysis using SQL and Excel. Indianapolis, Ind.: Wiley Pub.
Lock, R. (2013). Statistics: Unlocking the power of data. Wiley.
Rumsey, D. (2015). Intermediate statistics for dummies (1st ed). Hoboken, N.J.: Wiley.
Shao, J. (2010). Mathematical statistics (2nd ed). New York: Springer.
References
Linoff, G. (2011). Data analysis using SQL and Excel. Indianapolis, Ind.: Wiley Pub.
Lock, R. (2013). Statistics: Unlocking the power of data. Wiley.
Rumsey, D. (2015). Intermediate statistics for dummies (1st ed). Hoboken, N.J.: Wiley.
Shao, J. (2010). Mathematical statistics (2nd ed). New York: Springer.
1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.