Business Analytics Assignment 3
VerifiedAdded on 2023/03/30
|9
|982
|100
AI Summary
This assignment focuses on topics such as Commbank Retail Business Insight Report, Regression Analysis, and Classification and Regression. It includes insights from the report, examples of regression analysis, and the difference between classification and prediction. The assignment also discuss...
Read More
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Business Analytics Assignment 3
Student’s Name
Institution Affiliation
Student’s Name
Institution Affiliation
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Question 1. Commbank Retail Business Insight Report
i. Comment on Insight of the report the
Quality of visualization is good as the charts and graph are clear and interactive: They are simple
to understand. Also, the report is presentable as the quality organization in the report is good;
findings and section are well organized. The information provided in the report is critical to the
Commbank as it’s a survey reveals more about the quality of its clients. This can be used in
improving the services it offers
ii. Key information from the report.
Innovation performance among the retailers
Returns from innovation among the retailer, putting into consideration the
expenses incurred and the benefits or profit reaped.
Investment in technology; how have retailers invested in technology
iii. Abstract of the report
The report reveals the changes that are taking place in the Australian retail sector. The
participants (retail investors) are becoming more innovative and they are embracing technology
in the running of their businesses. They are doing this to maximizing the available business
opportunities in Australia. The report reveals the performance of innovation among retailer
investors. Also, it shows the benefits the retailers are obtaining when they become innovative
and use technology in the management and running of their businesses.
i. Comment on Insight of the report the
Quality of visualization is good as the charts and graph are clear and interactive: They are simple
to understand. Also, the report is presentable as the quality organization in the report is good;
findings and section are well organized. The information provided in the report is critical to the
Commbank as it’s a survey reveals more about the quality of its clients. This can be used in
improving the services it offers
ii. Key information from the report.
Innovation performance among the retailers
Returns from innovation among the retailer, putting into consideration the
expenses incurred and the benefits or profit reaped.
Investment in technology; how have retailers invested in technology
iii. Abstract of the report
The report reveals the changes that are taking place in the Australian retail sector. The
participants (retail investors) are becoming more innovative and they are embracing technology
in the running of their businesses. They are doing this to maximizing the available business
opportunities in Australia. The report reveals the performance of innovation among retailer
investors. Also, it shows the benefits the retailers are obtaining when they become innovative
and use technology in the management and running of their businesses.

iv. Improvement that needs to be made
The organization of topics/sections in the report should be improved to make every finding
clearly visible and easier to identify.
Question 2: Regression Analysis
i. An example where regression Analysis can be used
Can be used to develop a model that can be used to forecast demand of a
product, say Car using price as an explanatory variable
ii. Data of height and weight of 10 friend
No. Height (feet) Weight(Kg)
1. 5.0 49
2. 6.0 75
3. 5.15 55
4. 5.8 70
5. 5.9 73
6. 5.30 51
7. 5.83 72
The organization of topics/sections in the report should be improved to make every finding
clearly visible and easier to identify.
Question 2: Regression Analysis
i. An example where regression Analysis can be used
Can be used to develop a model that can be used to forecast demand of a
product, say Car using price as an explanatory variable
ii. Data of height and weight of 10 friend
No. Height (feet) Weight(Kg)
1. 5.0 49
2. 6.0 75
3. 5.15 55
4. 5.8 70
5. 5.9 73
6. 5.30 51
7. 5.83 72
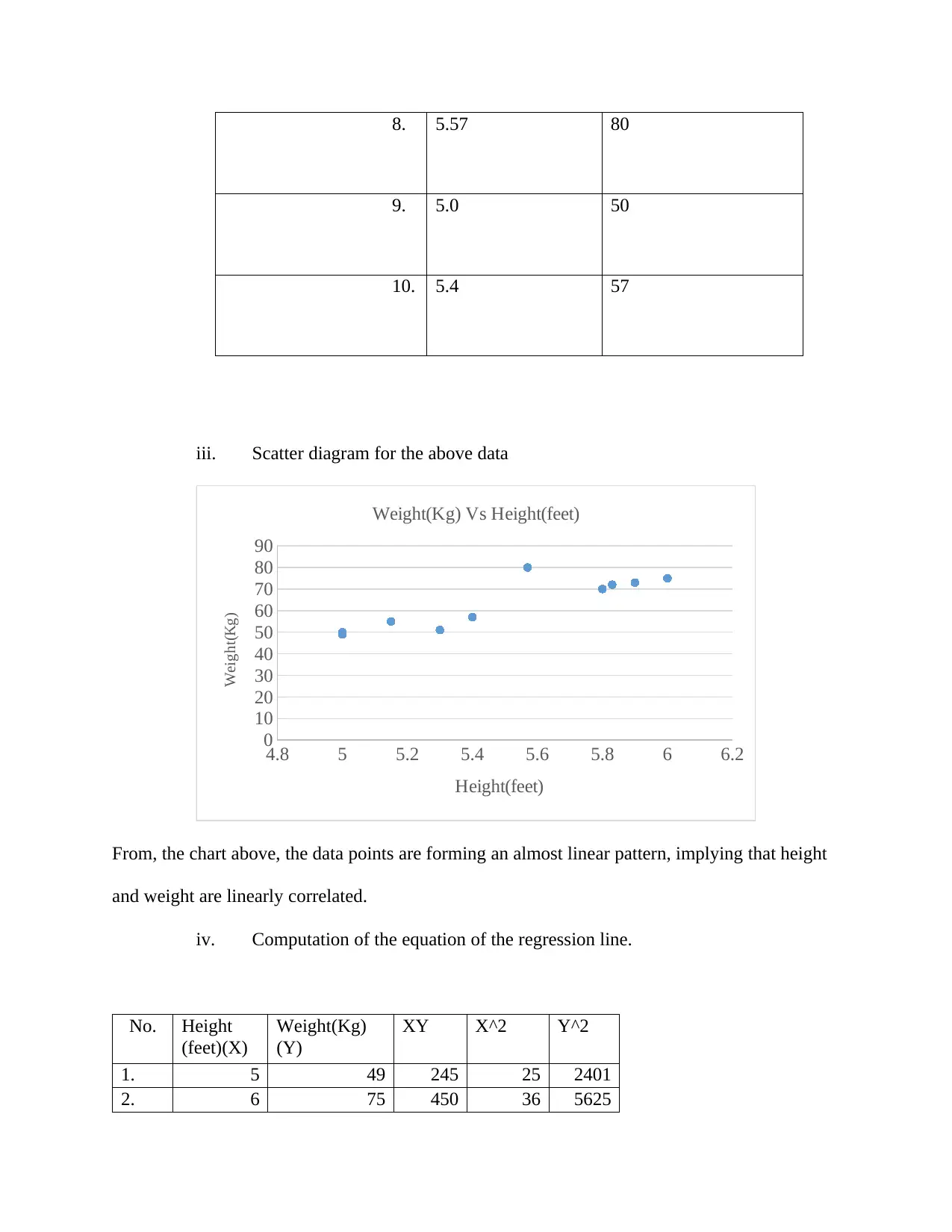
8. 5.57 80
9. 5.0 50
10. 5.4 57
iii. Scatter diagram for the above data
4.8 5 5.2 5.4 5.6 5.8 6 6.2
0
10
20
30
40
50
60
70
80
90
Weight(Kg) Vs Height(feet)
Height(feet)
Weight(Kg)
From, the chart above, the data points are forming an almost linear pattern, implying that height
and weight are linearly correlated.
iv. Computation of the equation of the regression line.
No. Height
(feet)(X)
Weight(Kg)
(Y)
XY X^2 Y^2
1. 5 49 245 25 2401
2. 6 75 450 36 5625
9. 5.0 50
10. 5.4 57
iii. Scatter diagram for the above data
4.8 5 5.2 5.4 5.6 5.8 6 6.2
0
10
20
30
40
50
60
70
80
90
Weight(Kg) Vs Height(feet)
Height(feet)
Weight(Kg)
From, the chart above, the data points are forming an almost linear pattern, implying that height
and weight are linearly correlated.
iv. Computation of the equation of the regression line.
No. Height
(feet)(X)
Weight(Kg)
(Y)
XY X^2 Y^2
1. 5 49 245 25 2401
2. 6 75 450 36 5625
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

3. 5.15 55 283.25 26.5225 3025
4. 5.8 70 406 33.64 4900
5. 5.9 73 430.7 34.81 5329
6. 5.3 51 270.3 28.09 2601
7. 5.83 72 419.76 33.9889 5184
8. 5.57 80 445.6 31.0249 6400
9. 5 50 250 25 2500
10. 5.4 57 307.8 29.16 3249
Total 54.95 632 3508.4
1
303.236
3
41214
The regression line is given by Y =a+bX
b=
n∑❑
❑
XY −(∑❑
❑
X )(∑❑
❑
Y )
n ( ∑❑
❑
X2
)−(∑❑
❑
X )2
=10 ( 3508.41 ) −(54.95)(632)
10 ( 303.2363 ) −(54.95)2 =27.6583
a=
∑❑
❑
Y −b ∑❑
❑
X
n =632−27.6583(54.95)
10 =−88.7825
v. R-squared
R2=
( n∑❑
❑
XY −( ∑❑
❑
X )( ∑❑
❑
Y )
❑
√( n ( ∑❑
❑
X2
) −( ∑❑
❑
X )
2
)( n ( ∑❑
❑
Y 2
) −( ∑❑
❑
Y )
2
) )
2
¿ ( 10 ( 3508.41 )− ( 54.95 ) ( 632 )
❑
√ (10 ( 303.2363 )− ( 54.95 )2 )∗(10 ( 41214 )− ( 632 )2 ) )2
¿ ( 0.8796 )2
¿ 0.7737
4. 5.8 70 406 33.64 4900
5. 5.9 73 430.7 34.81 5329
6. 5.3 51 270.3 28.09 2601
7. 5.83 72 419.76 33.9889 5184
8. 5.57 80 445.6 31.0249 6400
9. 5 50 250 25 2500
10. 5.4 57 307.8 29.16 3249
Total 54.95 632 3508.4
1
303.236
3
41214
The regression line is given by Y =a+bX
b=
n∑❑
❑
XY −(∑❑
❑
X )(∑❑
❑
Y )
n ( ∑❑
❑
X2
)−(∑❑
❑
X )2
=10 ( 3508.41 ) −(54.95)(632)
10 ( 303.2363 ) −(54.95)2 =27.6583
a=
∑❑
❑
Y −b ∑❑
❑
X
n =632−27.6583(54.95)
10 =−88.7825
v. R-squared
R2=
( n∑❑
❑
XY −( ∑❑
❑
X )( ∑❑
❑
Y )
❑
√( n ( ∑❑
❑
X2
) −( ∑❑
❑
X )
2
)( n ( ∑❑
❑
Y 2
) −( ∑❑
❑
Y )
2
) )
2
¿ ( 10 ( 3508.41 )− ( 54.95 ) ( 632 )
❑
√ (10 ( 303.2363 )− ( 54.95 )2 )∗(10 ( 41214 )− ( 632 )2 ) )2
¿ ( 0.8796 )2
¿ 0.7737

vi. Using another analytic tool to find iv and v
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.87958
9
R Square
0.77367
6
Adjusted R
Square
0.74538
6
Standard
Error
5.99784
4
Observations 10
ANOVA
df SS MS F
Significa
nce F
Regression 1 983.80 983.80 27.347 0.000793
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.87958
9
R Square
0.77367
6
Adjusted R
Square
0.74538
6
Standard
Error
5.99784
4
Observations 10
ANOVA
df SS MS F
Significa
nce F
Regression 1 983.80 983.80 27.347 0.000793
69 69 62
Residual 8
287.79
31
35.974
13
Total 9 1271.6
Coeffici
ents
Stand
ard
Error t Stat
P-
value
Lower
95%
Upper
95%
Lower
95.0%
Upper
95.0%
Intercept -88.7825
29.124
39
-
3.0483
9
0.0158
6 -155.944
-
21.621
6
-
155.94
4
-
21.621
6
Height (feet)
27.6583
3
5.2889
11
5.2294
95
0.0007
93 15.46208
39.854
58
15.462
08
39.854
58
The equation will be
y=−88.783+27.658 x , where x=height∧ y=weight
The value of R2 0.7737
The value of iv and v are similar to those in vi
Question 3: Classification and Regression
i. Difference between classification and prediction
According to Han, Pei, and Kamber(2011), classification is a data analysis task whereas
prediction is the identification of data values upon describing other correlated data values
ii. Examples for classification methods
Association method
Decision tree induction
Bayesian
iii. Algebraic equation for y in terms of input values i1, i2, and weight w
y1=H1 w5 + H2 w6
H1=i1 w1 +i2 w3 +b1
Residual 8
287.79
31
35.974
13
Total 9 1271.6
Coeffici
ents
Stand
ard
Error t Stat
P-
value
Lower
95%
Upper
95%
Lower
95.0%
Upper
95.0%
Intercept -88.7825
29.124
39
-
3.0483
9
0.0158
6 -155.944
-
21.621
6
-
155.94
4
-
21.621
6
Height (feet)
27.6583
3
5.2889
11
5.2294
95
0.0007
93 15.46208
39.854
58
15.462
08
39.854
58
The equation will be
y=−88.783+27.658 x , where x=height∧ y=weight
The value of R2 0.7737
The value of iv and v are similar to those in vi
Question 3: Classification and Regression
i. Difference between classification and prediction
According to Han, Pei, and Kamber(2011), classification is a data analysis task whereas
prediction is the identification of data values upon describing other correlated data values
ii. Examples for classification methods
Association method
Decision tree induction
Bayesian
iii. Algebraic equation for y in terms of input values i1, i2, and weight w
y1=H1 w5 + H2 w6
H1=i1 w1 +i2 w3 +b1
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

H2=i1 w2 +i2 w4 + b2
Therefore,
y1=w5 ( i1 w1+i2 w3 +b1 ) +w6 (i1 w2+i2 w4 +b2 )
The neural network is used in classification to solve problems by creating prediction functions
that are very unique such that no other algorithm can do it.
iv. Three examples of how clustering can be used in business analytics
Used to perform segmentation for example in products in a shop can be
clustered in the hierarchical group depending on their similarities.
Can be used to identify anomalies, for instance, fraud transaction in
businesses. Where items/transaction that falls out of the scrutinized cluster is
to be identified.
Can be used to split a large data set of data into simple sets that are easier to
analyze.
Therefore,
y1=w5 ( i1 w1+i2 w3 +b1 ) +w6 (i1 w2+i2 w4 +b2 )
The neural network is used in classification to solve problems by creating prediction functions
that are very unique such that no other algorithm can do it.
iv. Three examples of how clustering can be used in business analytics
Used to perform segmentation for example in products in a shop can be
clustered in the hierarchical group depending on their similarities.
Can be used to identify anomalies, for instance, fraud transaction in
businesses. Where items/transaction that falls out of the scrutinized cluster is
to be identified.
Can be used to split a large data set of data into simple sets that are easier to
analyze.

References
Han, J., Pei, J., & Kamber, M. (2011). Data mining: concepts and techniques. Elsevier.
Han, J., Pei, J., & Kamber, M. (2011). Data mining: concepts and techniques. Elsevier.
1 out of 9
Related Documents

Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.