Business Analytics Assignment: CommBank Retail Insights and Regression
VerifiedAdded on 2023/01/20
|9
|1156
|88
Homework Assignment
AI Summary
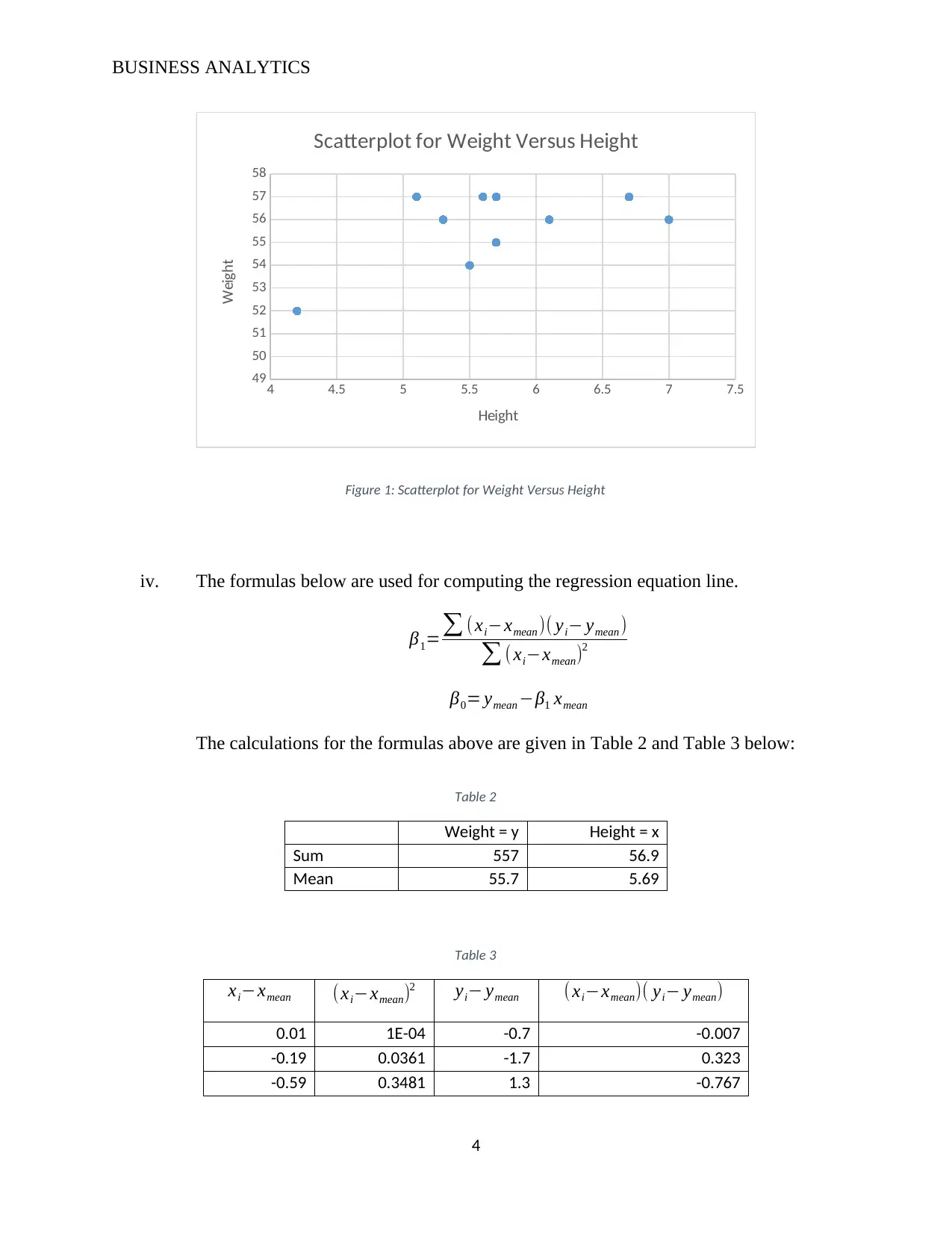
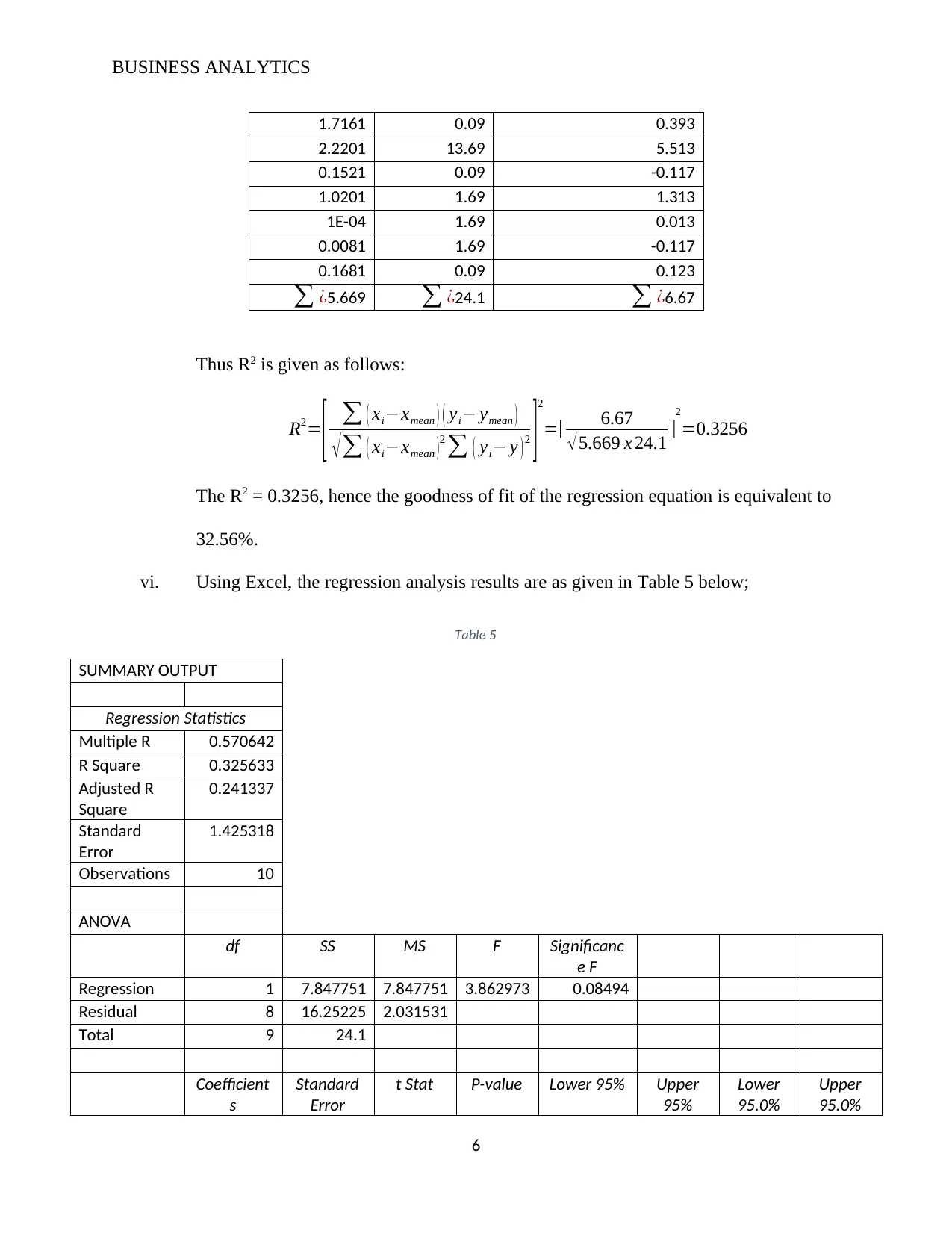
This assignment analyzes the CommBank Retail Business Insights Report, evaluating its visualizations, key information, and presentability, while also suggesting improvements. It then delves into regression analysis, providing an example of its application, collecting and analyzing height and weight data, computing the regression equation, and calculating the R-squared value. Finally, the assignment explores classification methods, including K-means clustering and neural networks, and discusses their applications in business analytics, such as customer segmentation and credit analysis. The assignment covers a range of analytical techniques relevant to business decision-making, including the use of statistical tools and the interpretation of data.







1 out of 9


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.