BUS708 Assignment: Statistical Modelling of Fuel Prices in Australia
VerifiedAdded on 2023/04/04
|9
|2011
|445
Report
AI Summary
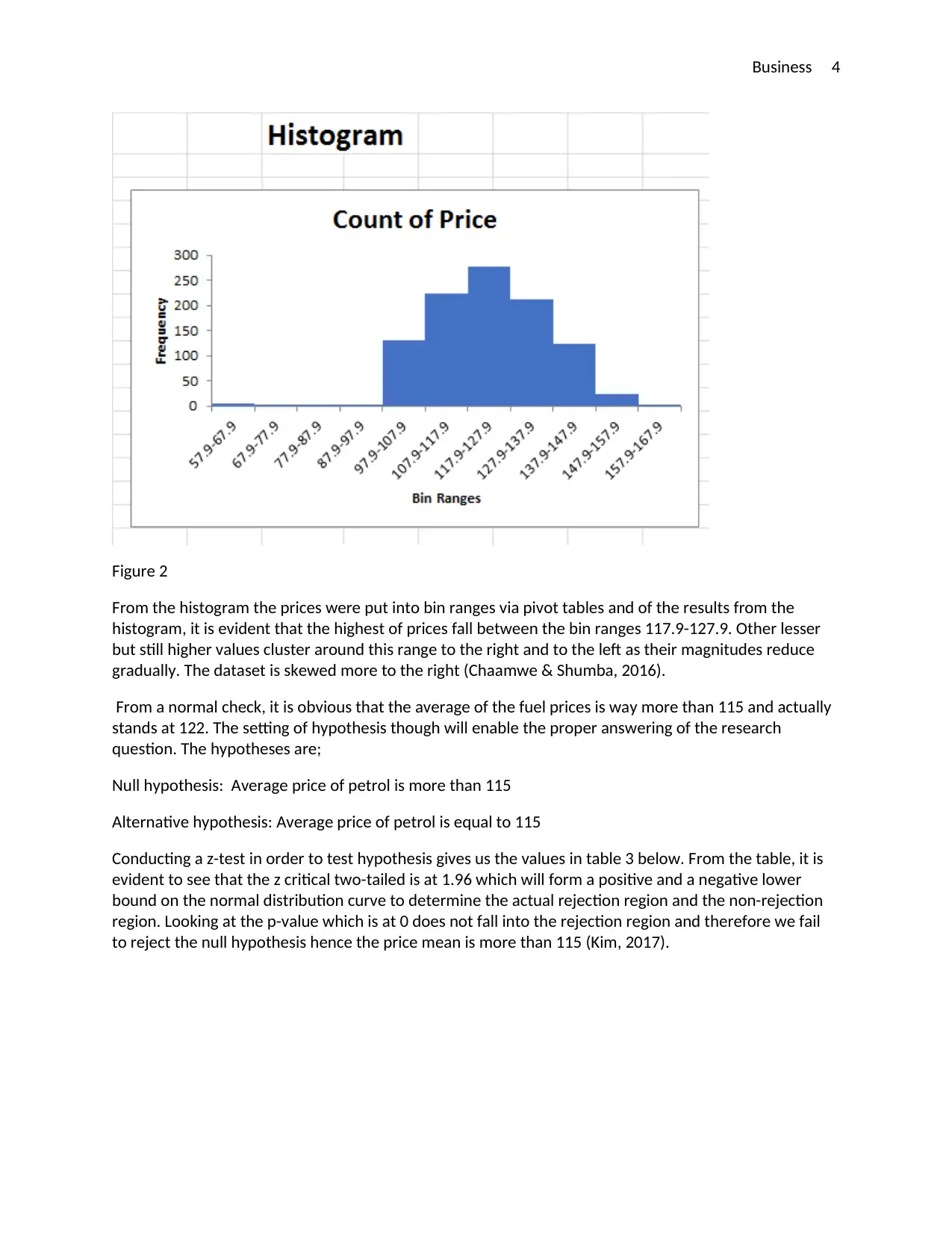
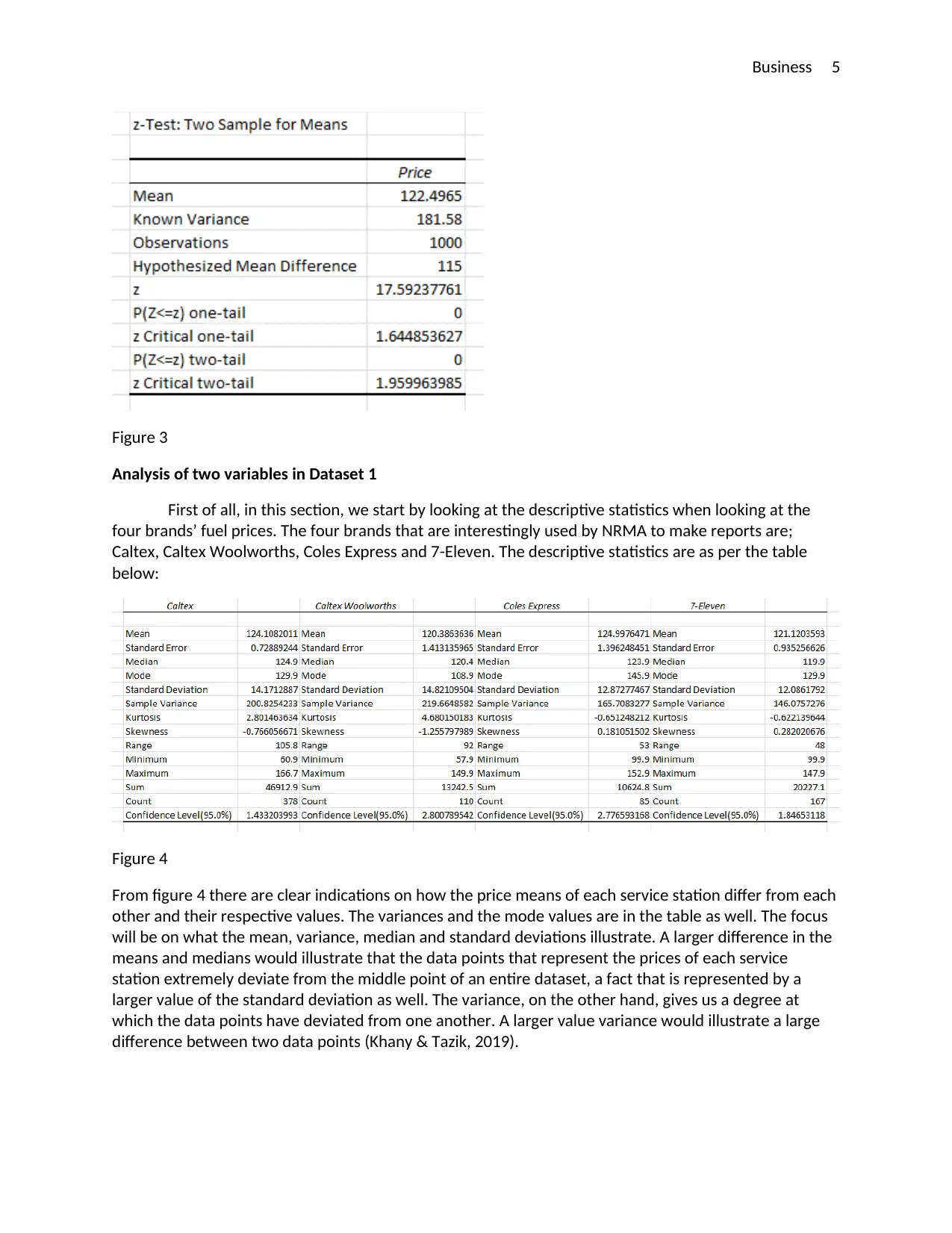
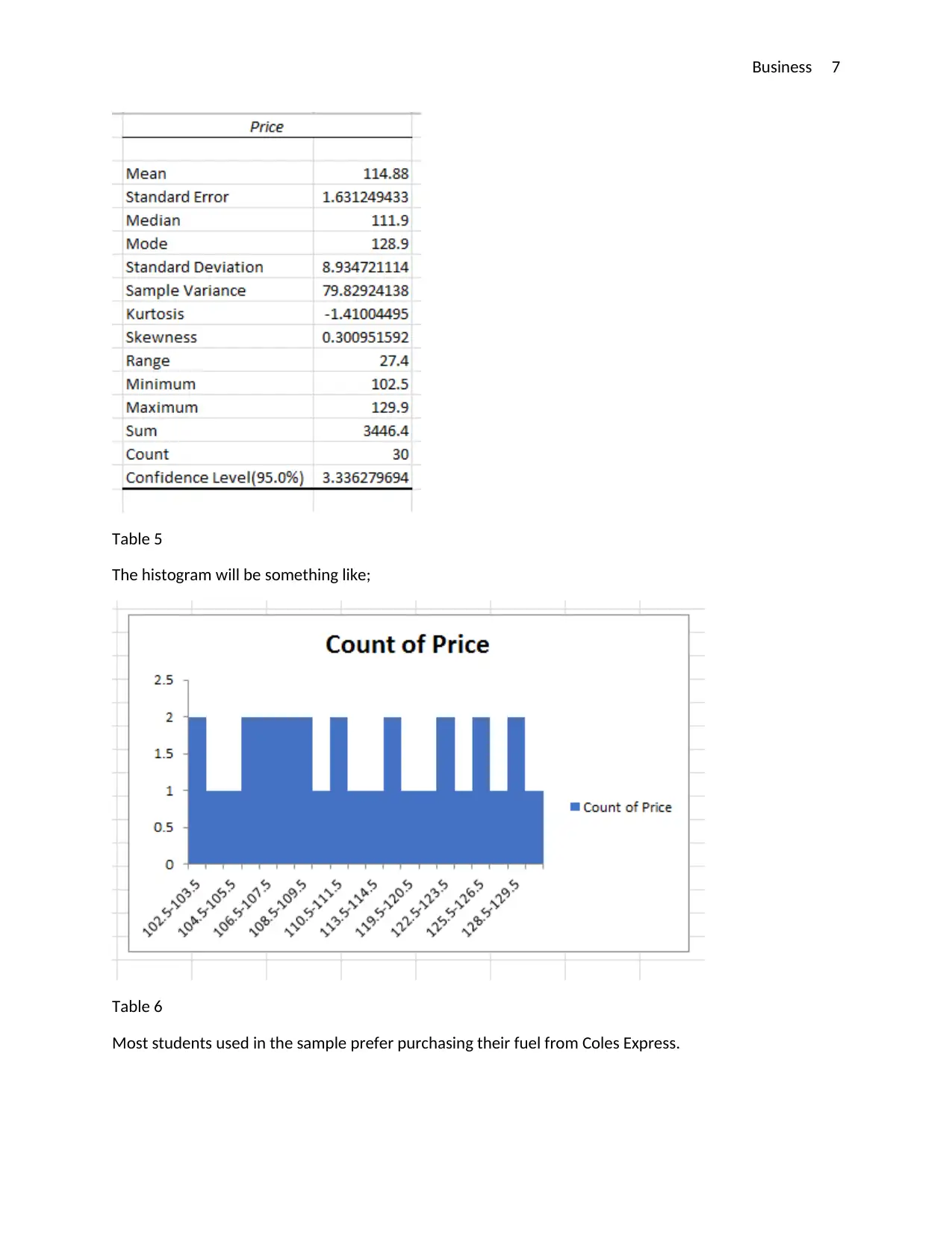
This report presents a comprehensive statistical analysis of fuel prices in Australia, addressing a business problem for NRMA. The assignment utilizes two datasets, one provided and one collected, to explore fuel price trends and variations across different brands and locations. The analysis includes descriptive statistics, graphical representations, and hypothesis testing to draw meaningful conclusions. The report investigates single and two-variable analyses, comparing fuel prices across different service stations and brands. The methodology involves using Excel for data manipulation, statistical calculations, and visualization. Key findings include the identification of price variations among service providers, with Caltex Woolworths being the cheapest. The report concludes with recommendations for NRMA to improve market competition and standardize fuel prices and suggests further research to address price challenges and service improvements. It demonstrates the application of statistical modeling to solve business problems.






1 out of 9
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.