Business Data Analysis Assignment Solution: Griffith University
VerifiedAdded on 2022/08/28
|11
|1197
|12
Homework Assignment
AI Summary
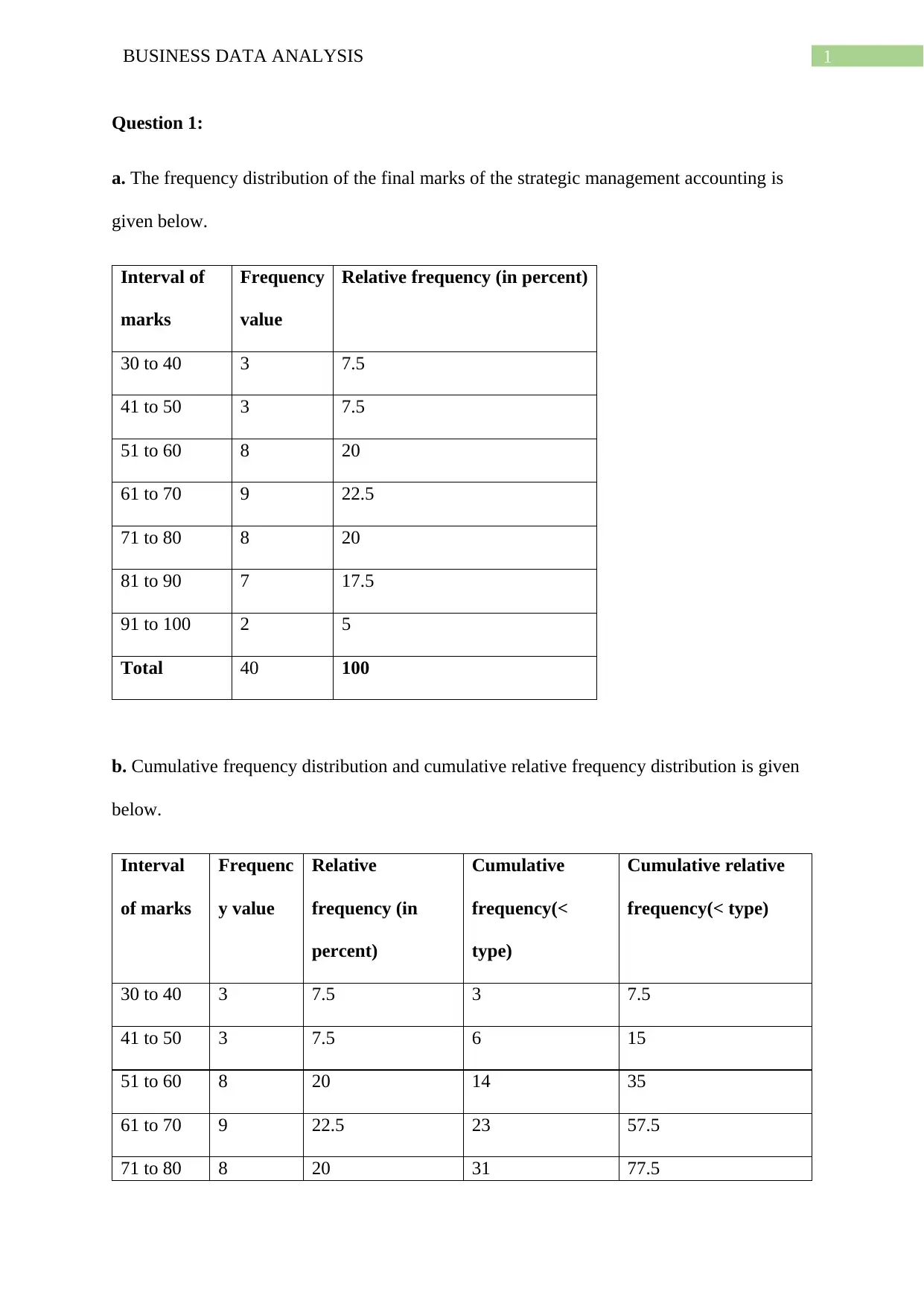
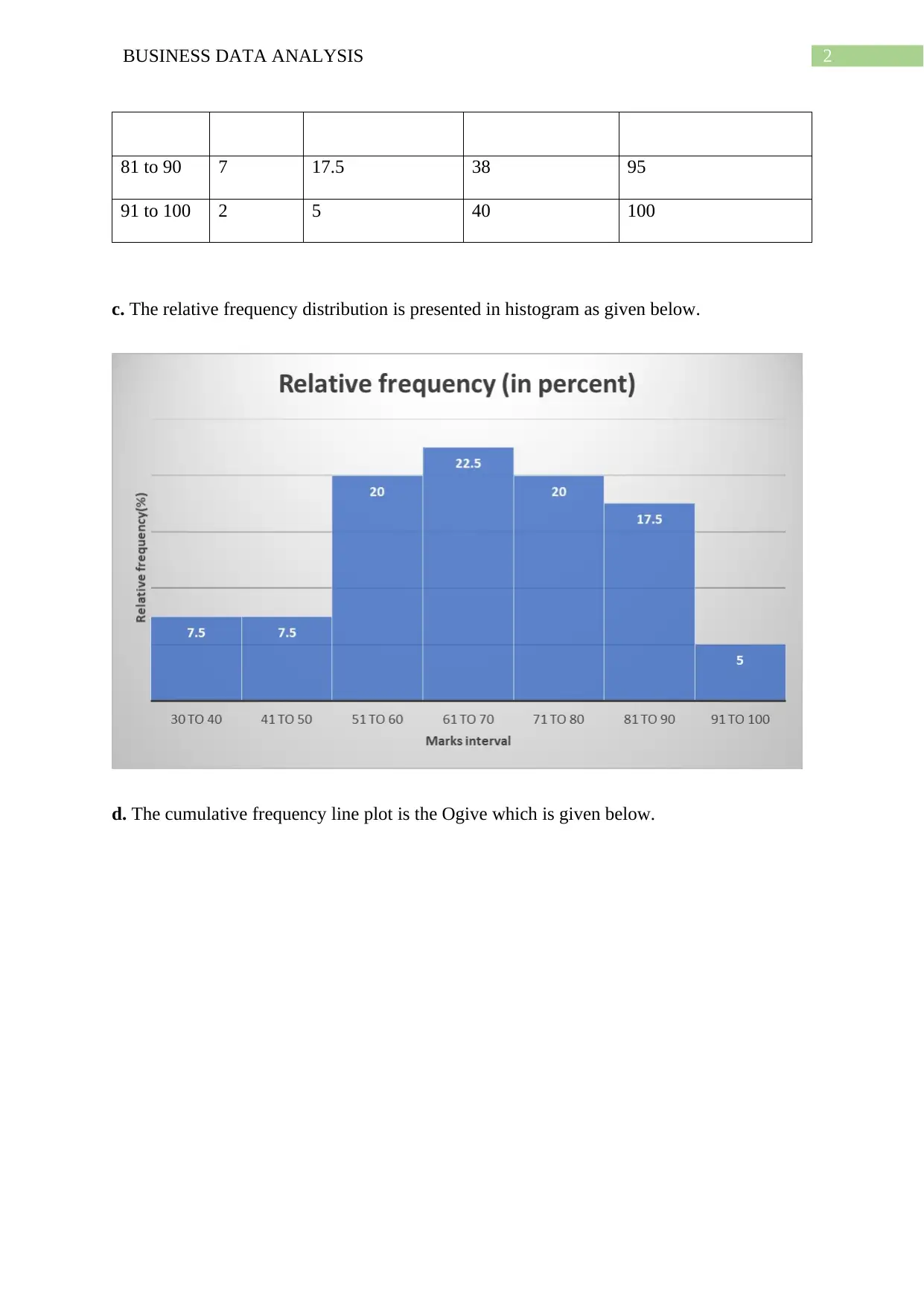
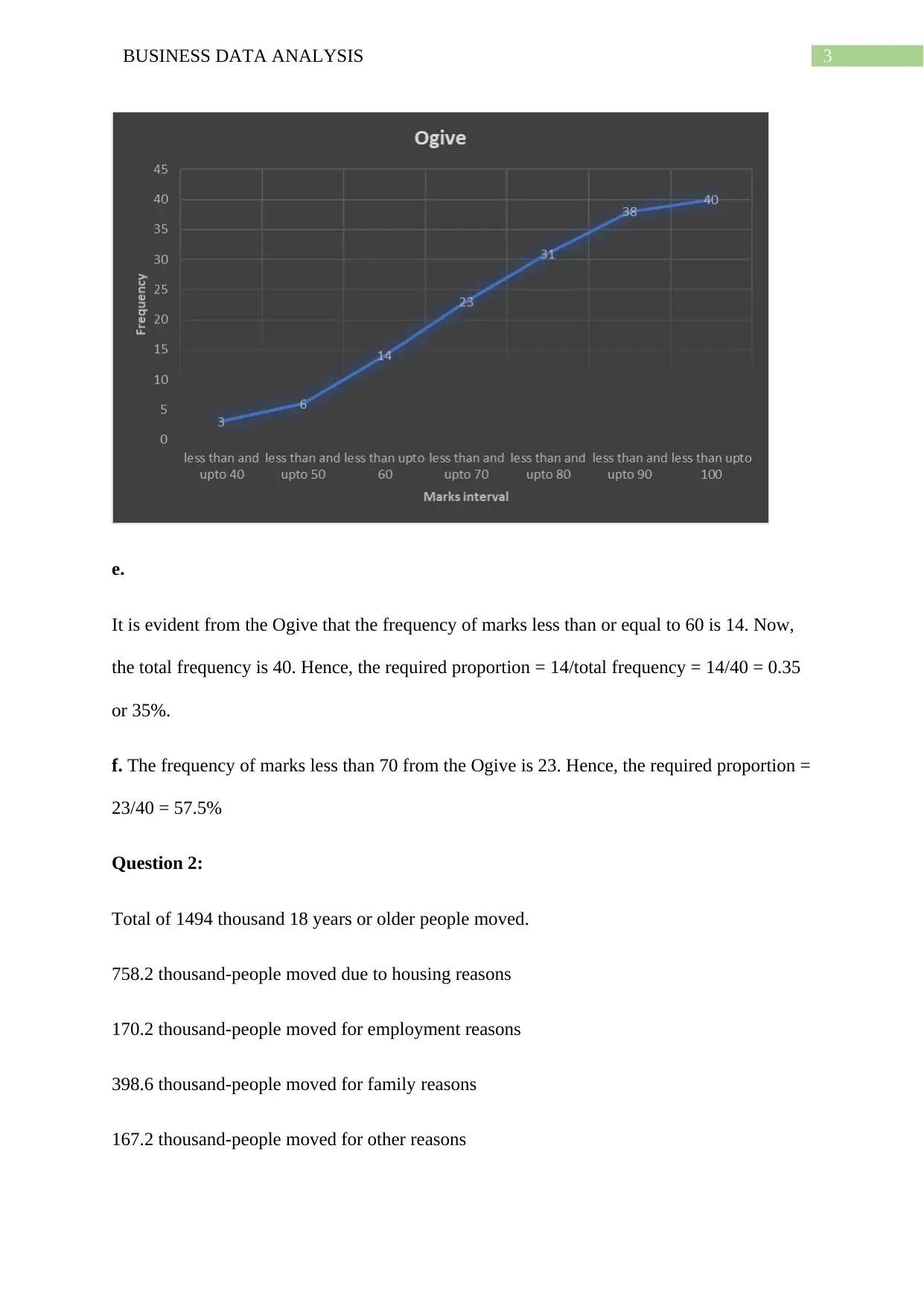
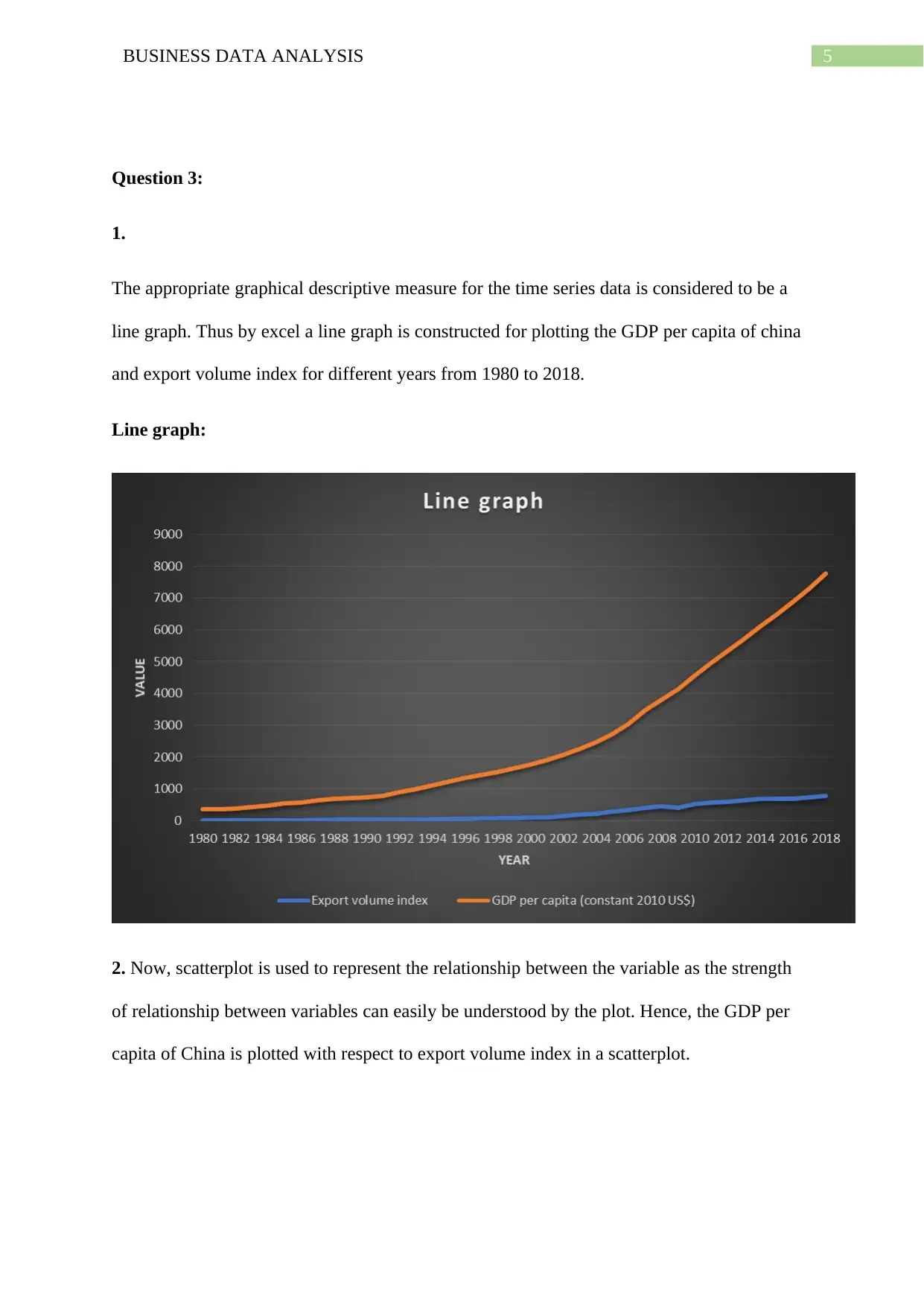
This assignment solution covers various aspects of business data analysis, including frequency distribution, cumulative frequency, and graphical representations like histograms and Ogives. It analyzes a dataset on housing, employment, and family-related moves using pie charts. Furthermore, the solution delves into time series analysis, employing line graphs and scatterplots to explore the relationship between China's GDP per capita and export volume index. It provides a numerical summary, correlation coefficient calculation, and a detailed regression analysis, including interpretation of coefficients, coefficient of determination, and standard error. The assignment also includes hypothesis testing and concepts related to simple linear regression models and sampling distributions.






1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.