Comprehensive Analysis of Uber Taxi Usage: A Business Research Report
VerifiedAdded on 2023/01/04
|21
|2807
|37
Report
AI Summary
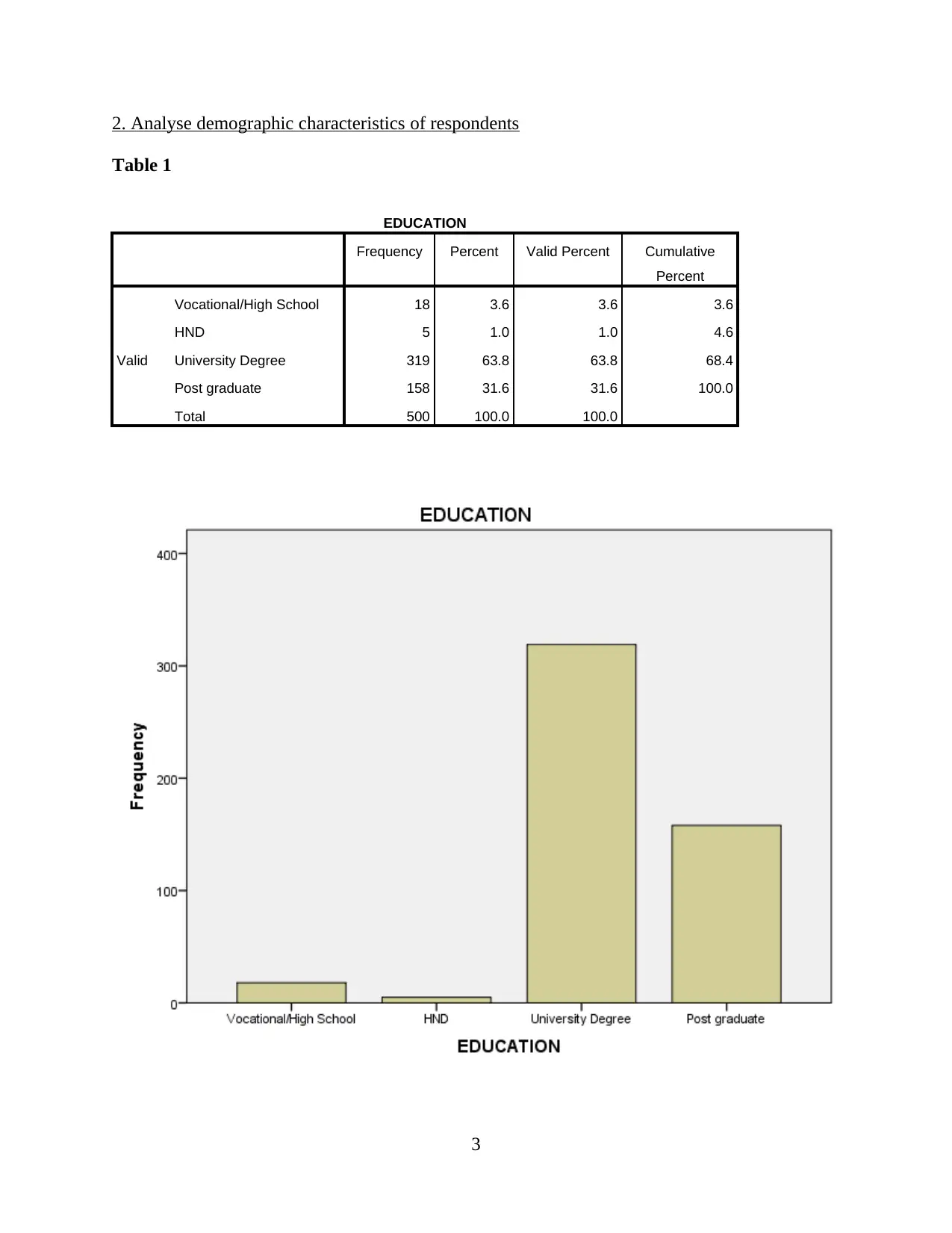
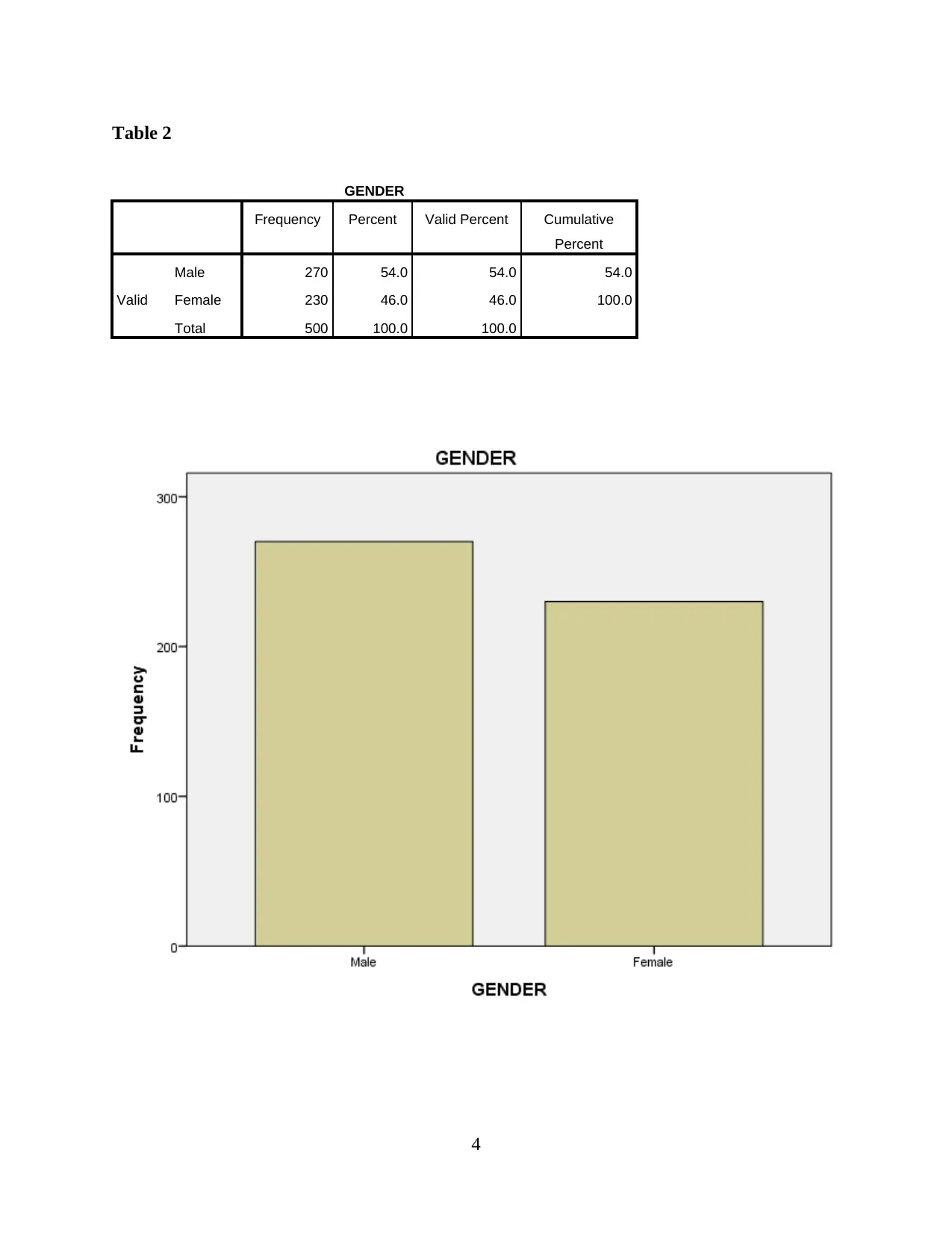
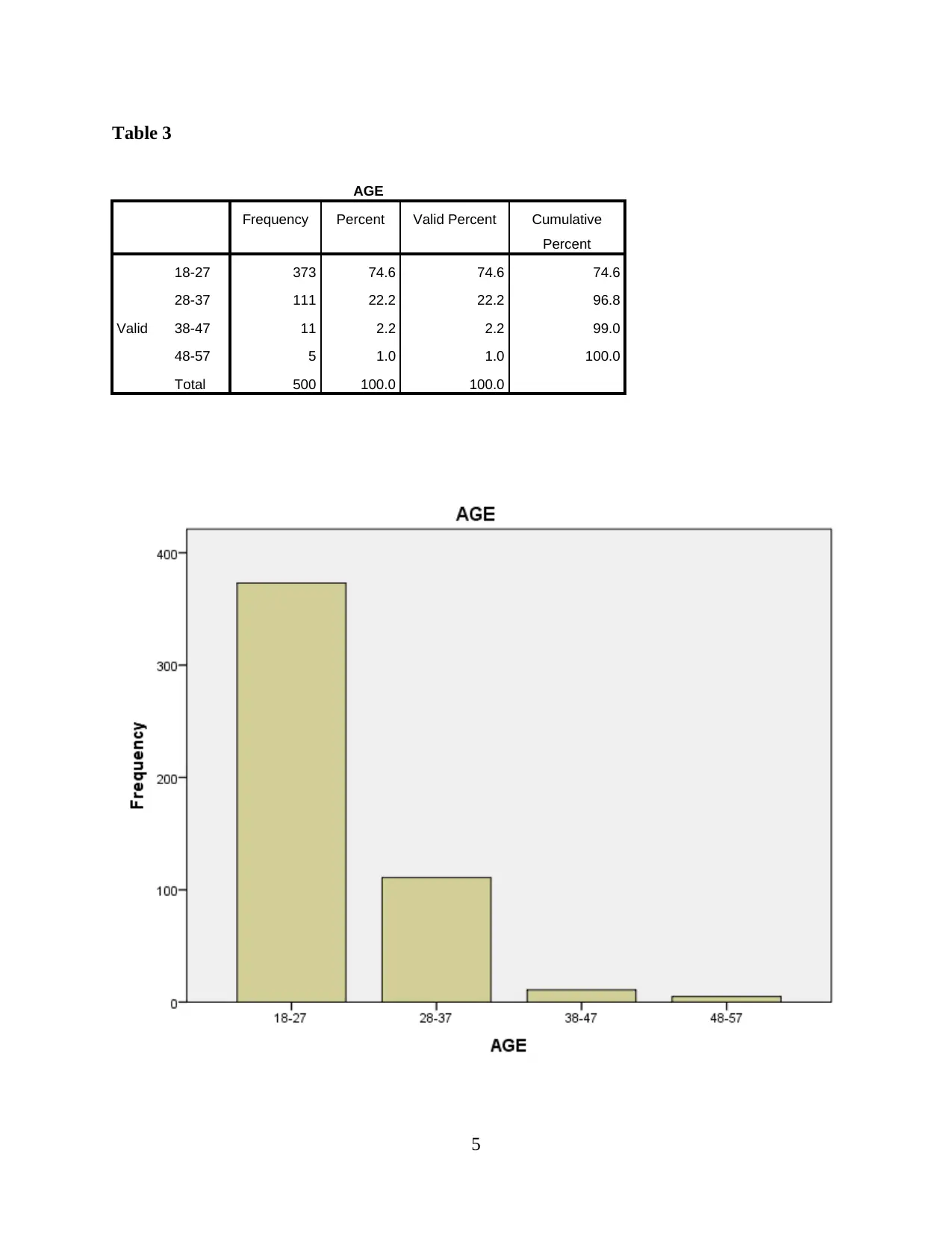
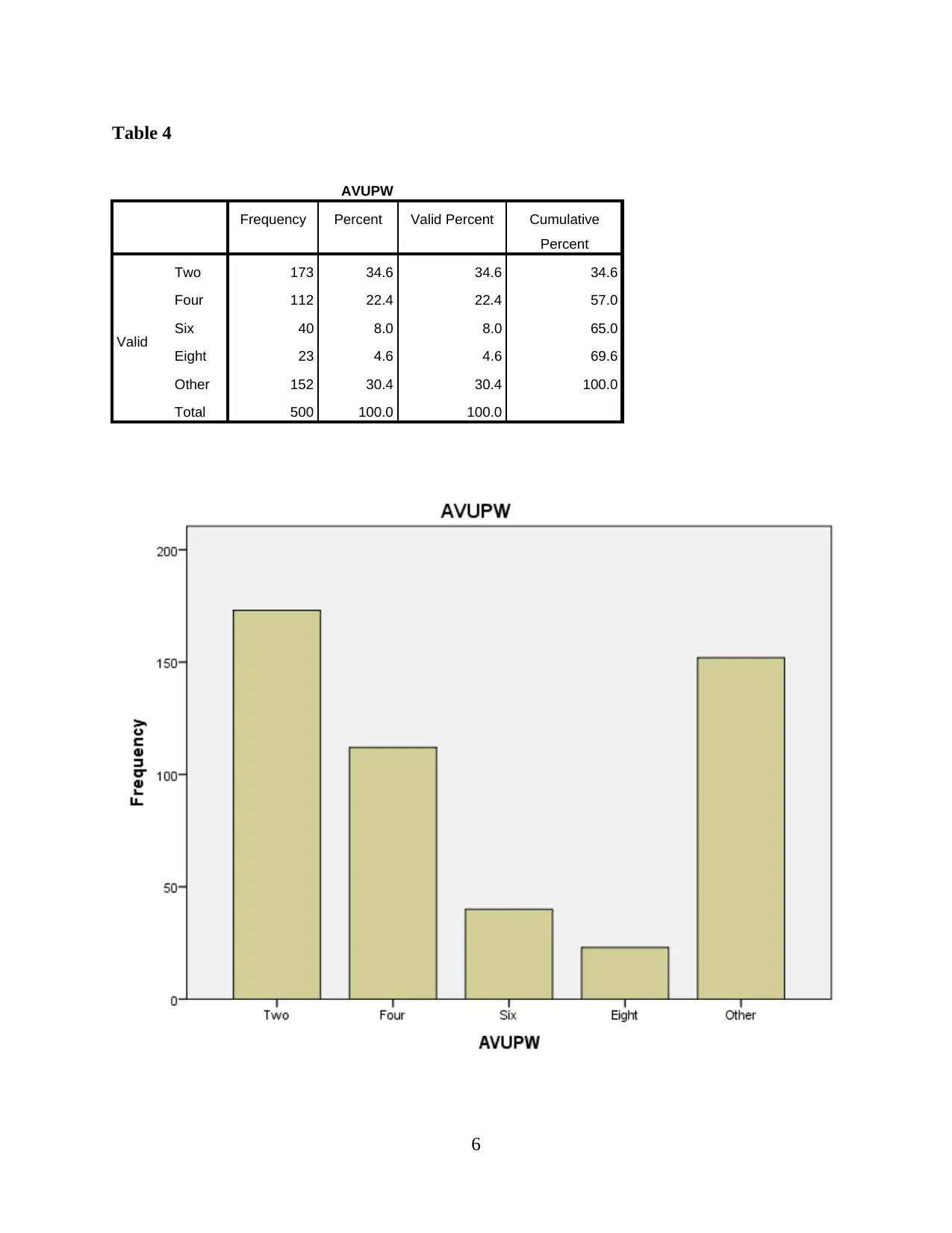
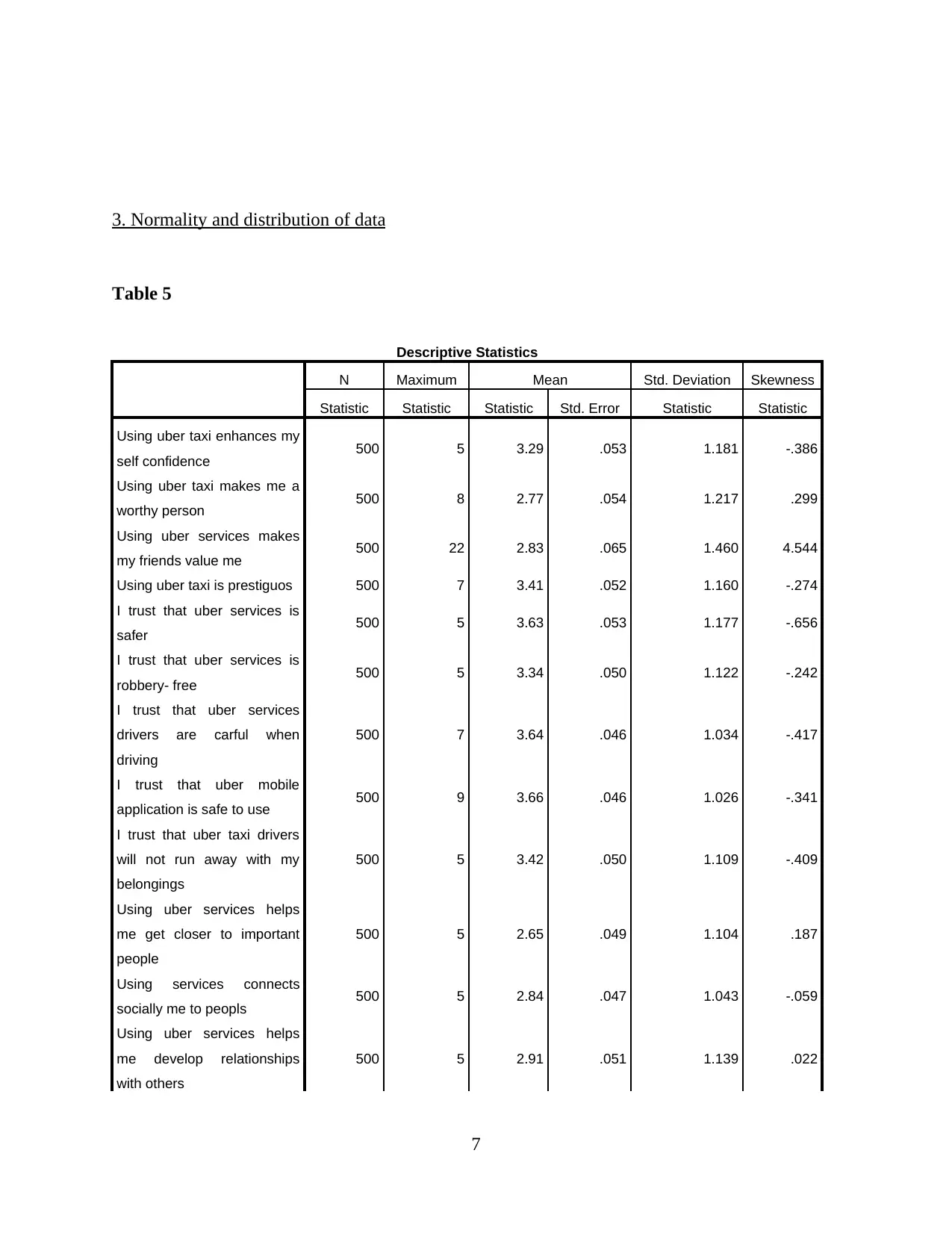
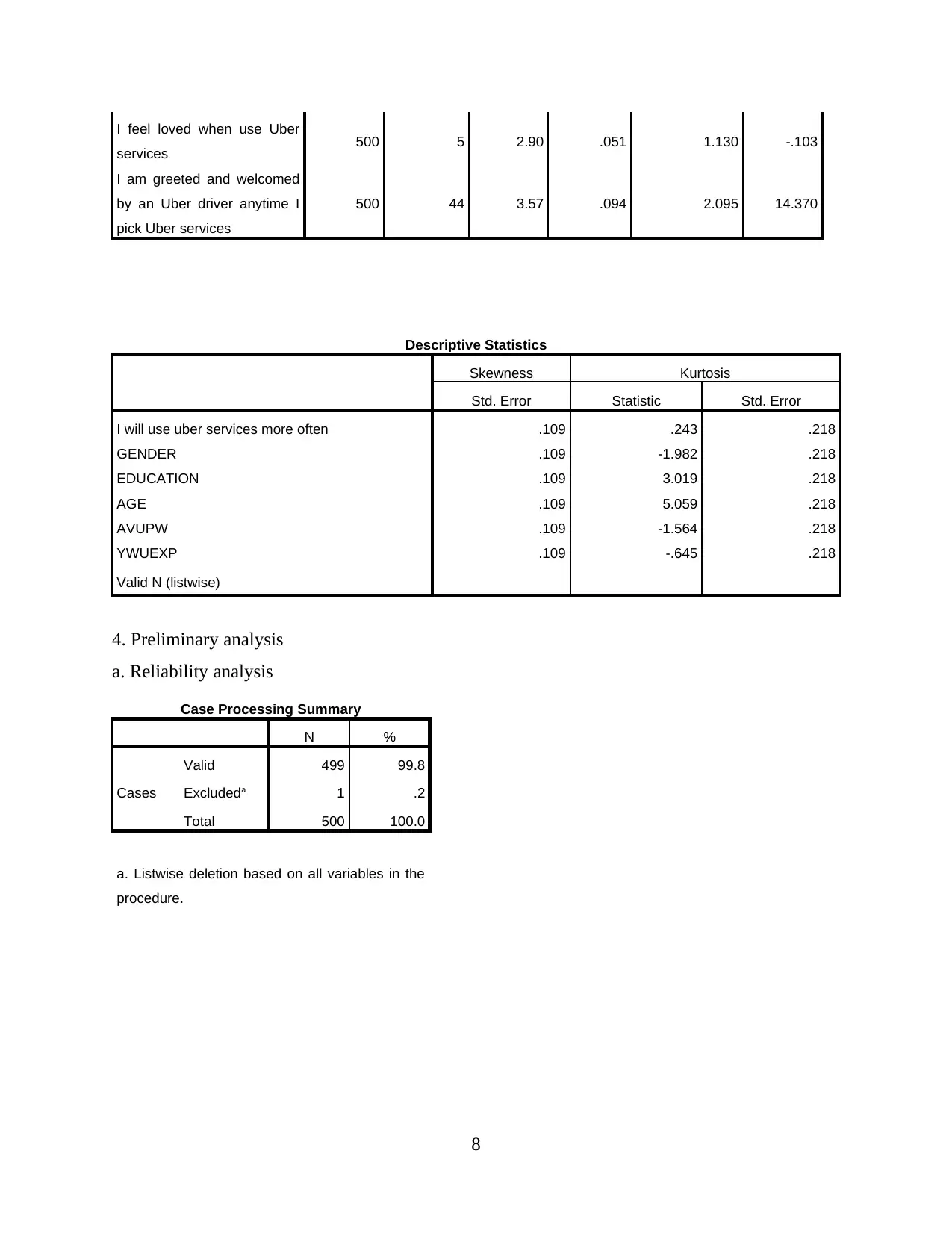
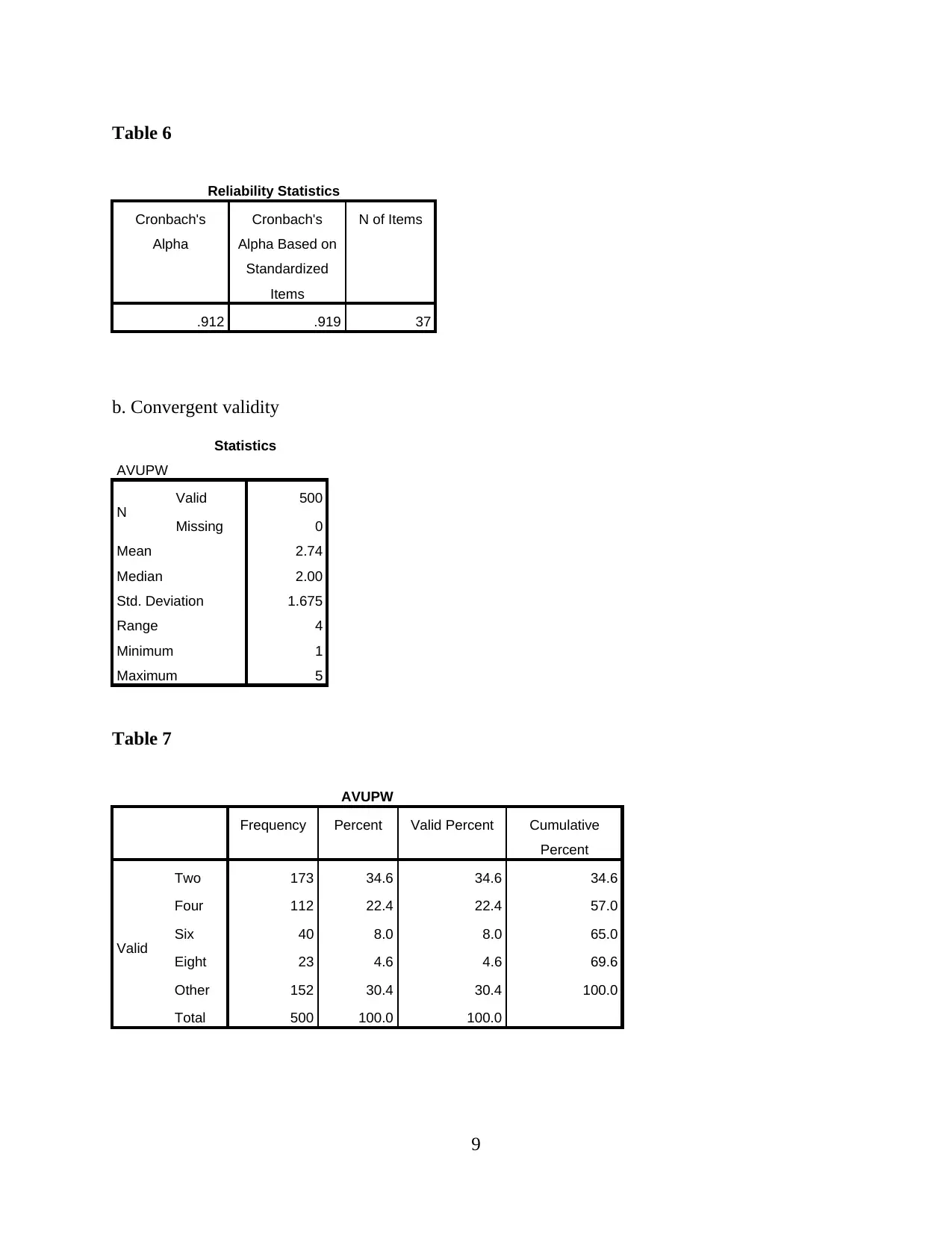
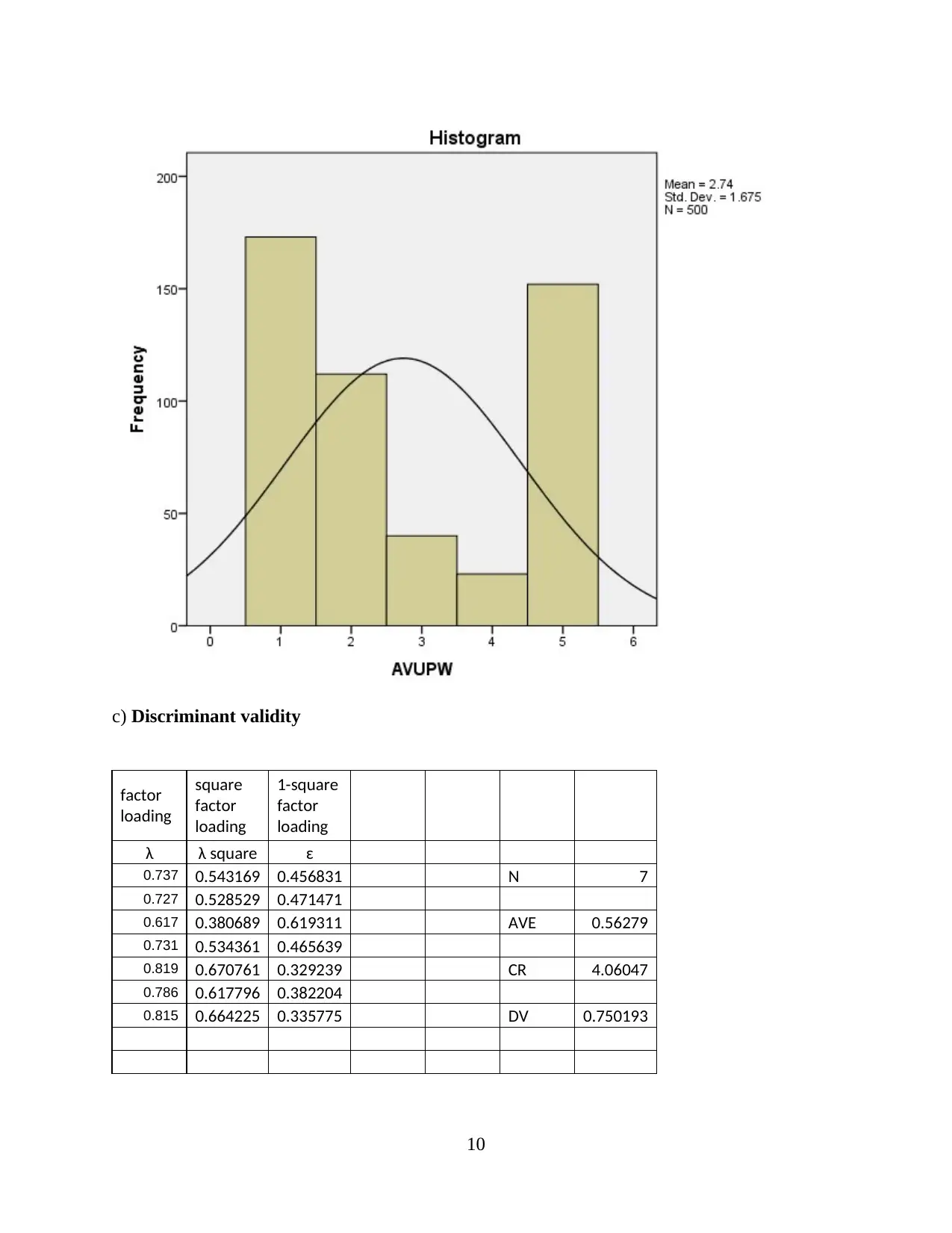
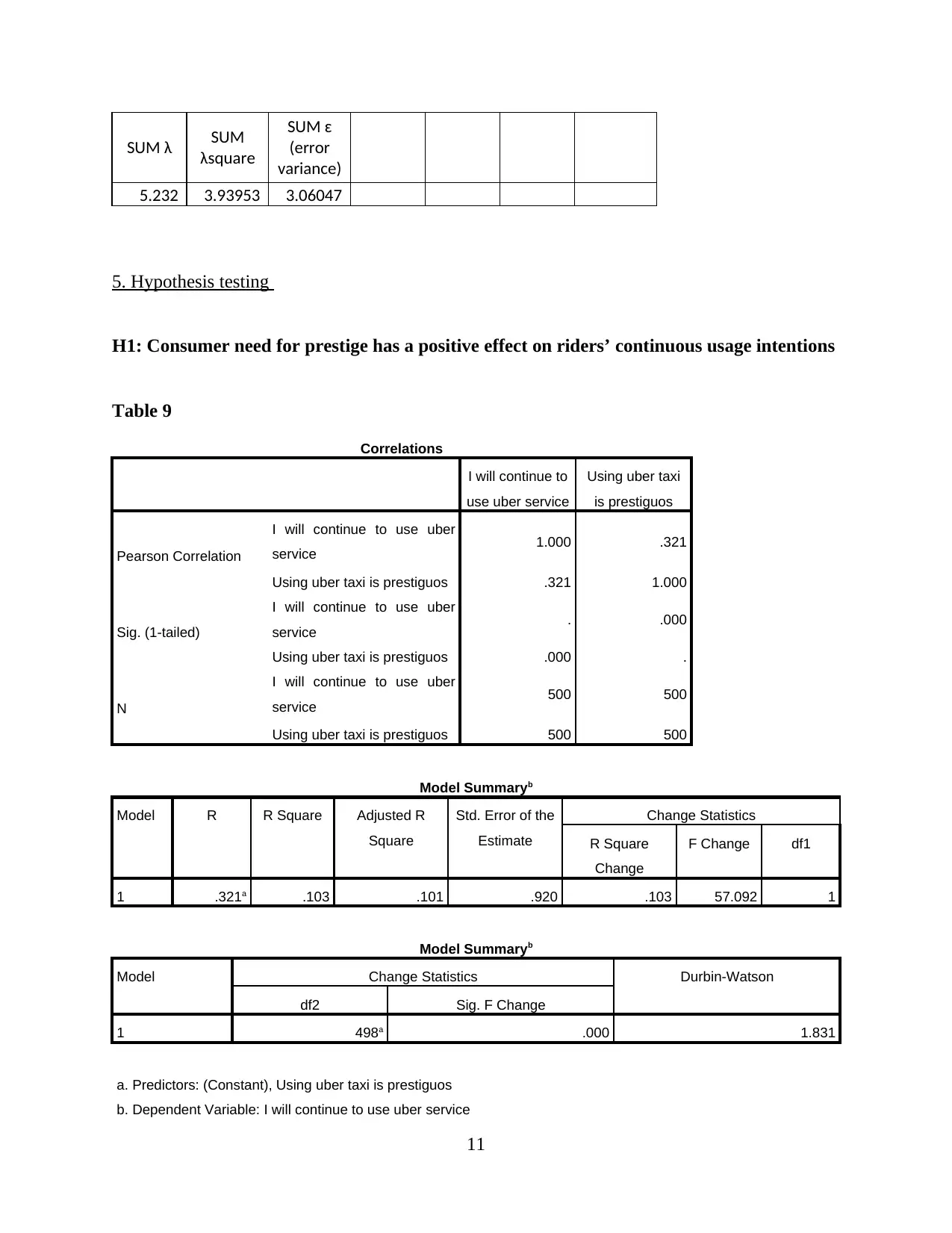
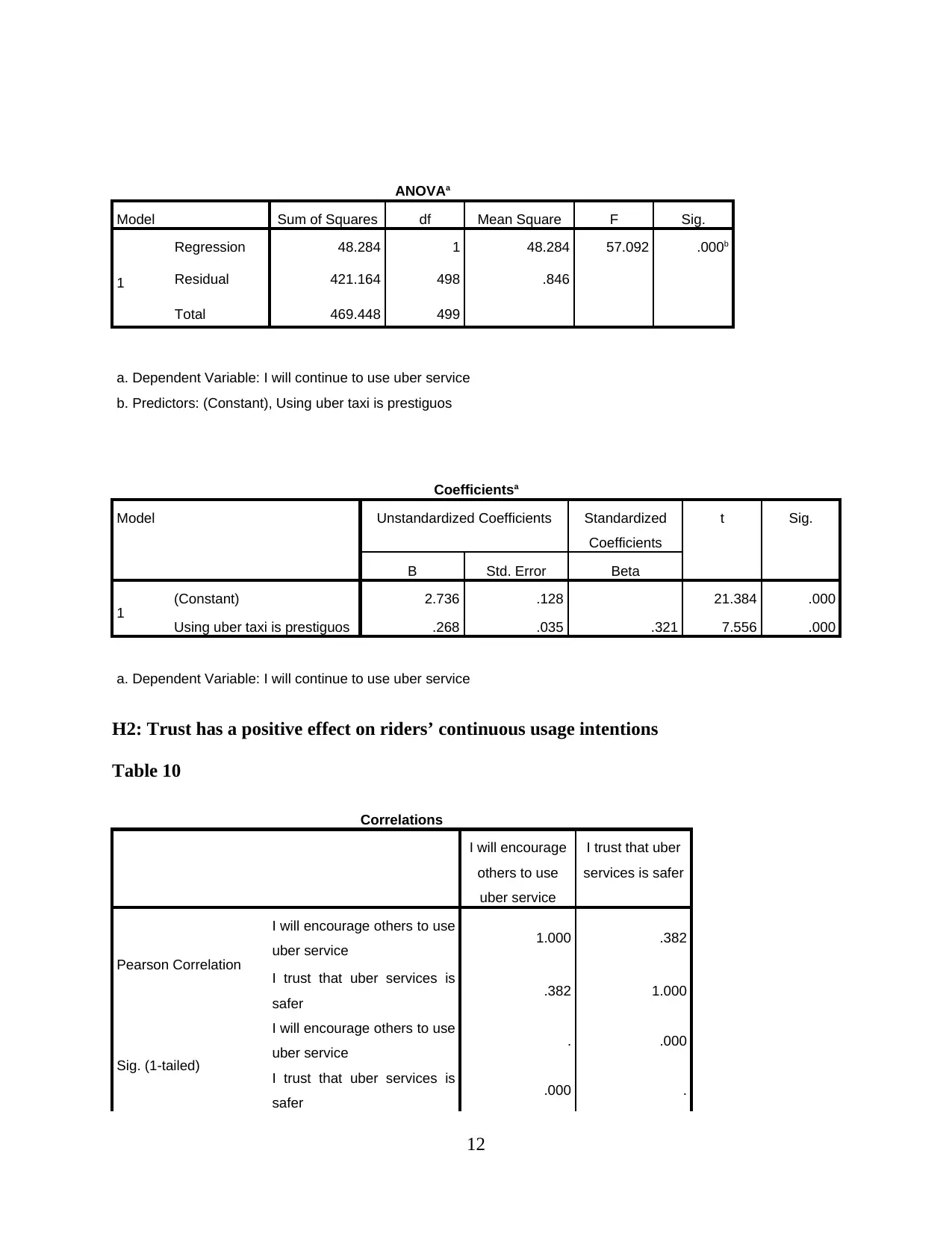
This report presents a comprehensive analysis of Uber taxi usage, based on a survey of 500 respondents. The analysis begins with an examination of demographic characteristics such as education, gender, age, and average weekly usage. Descriptive statistics, including mean, standard deviation, and skewness, are provided to understand data distribution. Reliability and validity analyses are performed to ensure the robustness of the data. The report then delves into hypothesis testing, exploring the relationships between consumer need for prestige, trust, customer return investment, convenience, and search benefits on riders' continuous usage intentions. Correlations, model summaries, ANOVAs, and coefficients are presented to support the findings. The report concludes with an interpretation of the key findings, drawing conclusions about the factors that influence Uber usage. The data reveals that the majority of the respondents are young, with a university degree and a slightly higher proportion of males. Key factors influencing Uber usage include convenience, prestige, and trust. The study suggests that Uber's continued success depends on its ability to maintain these key factors.


1 out of 21
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.