Business Statistics Homework: Hypothesis Testing and Probability
VerifiedAdded on 2023/01/17
|8
|824
|52
Homework Assignment
AI Summary
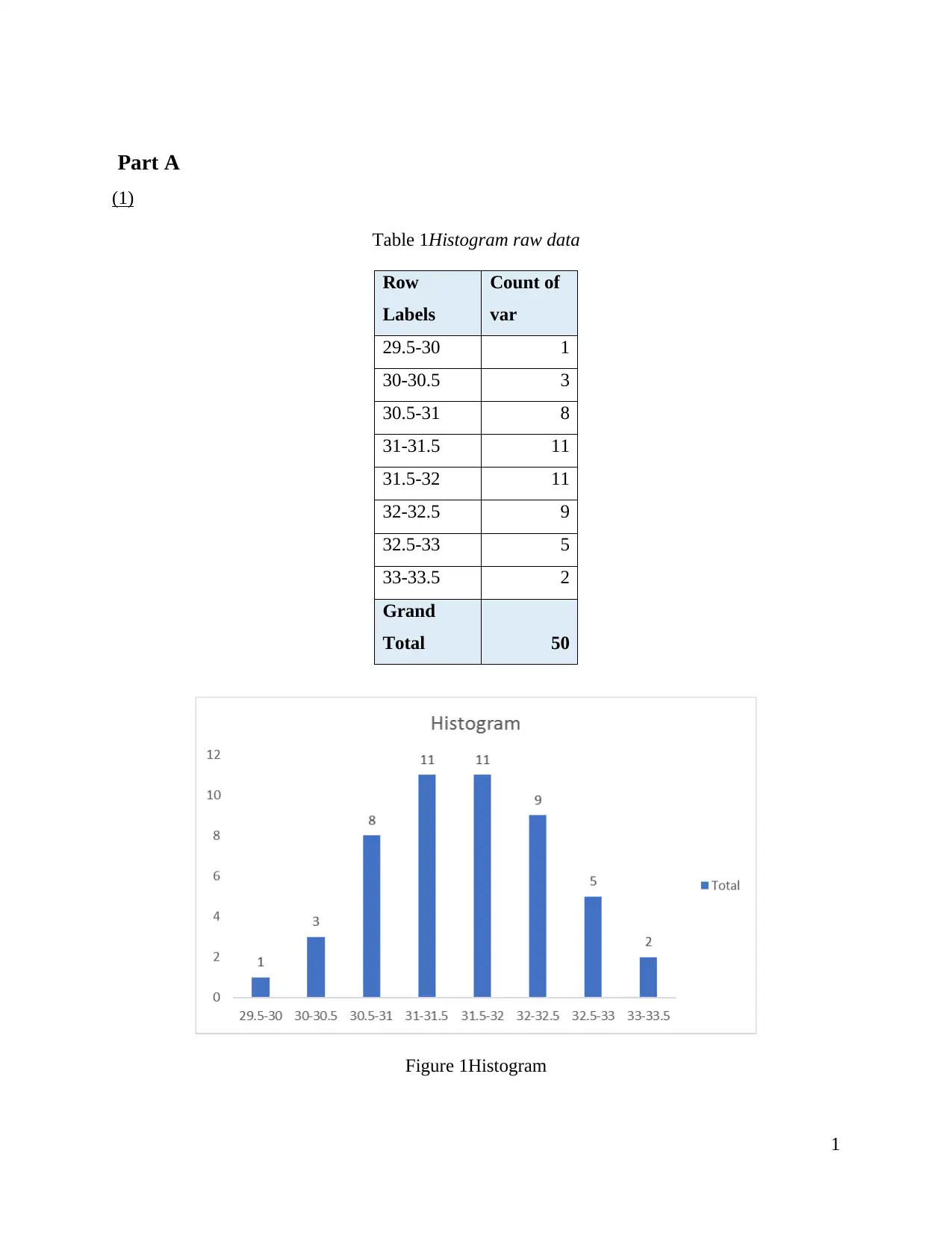
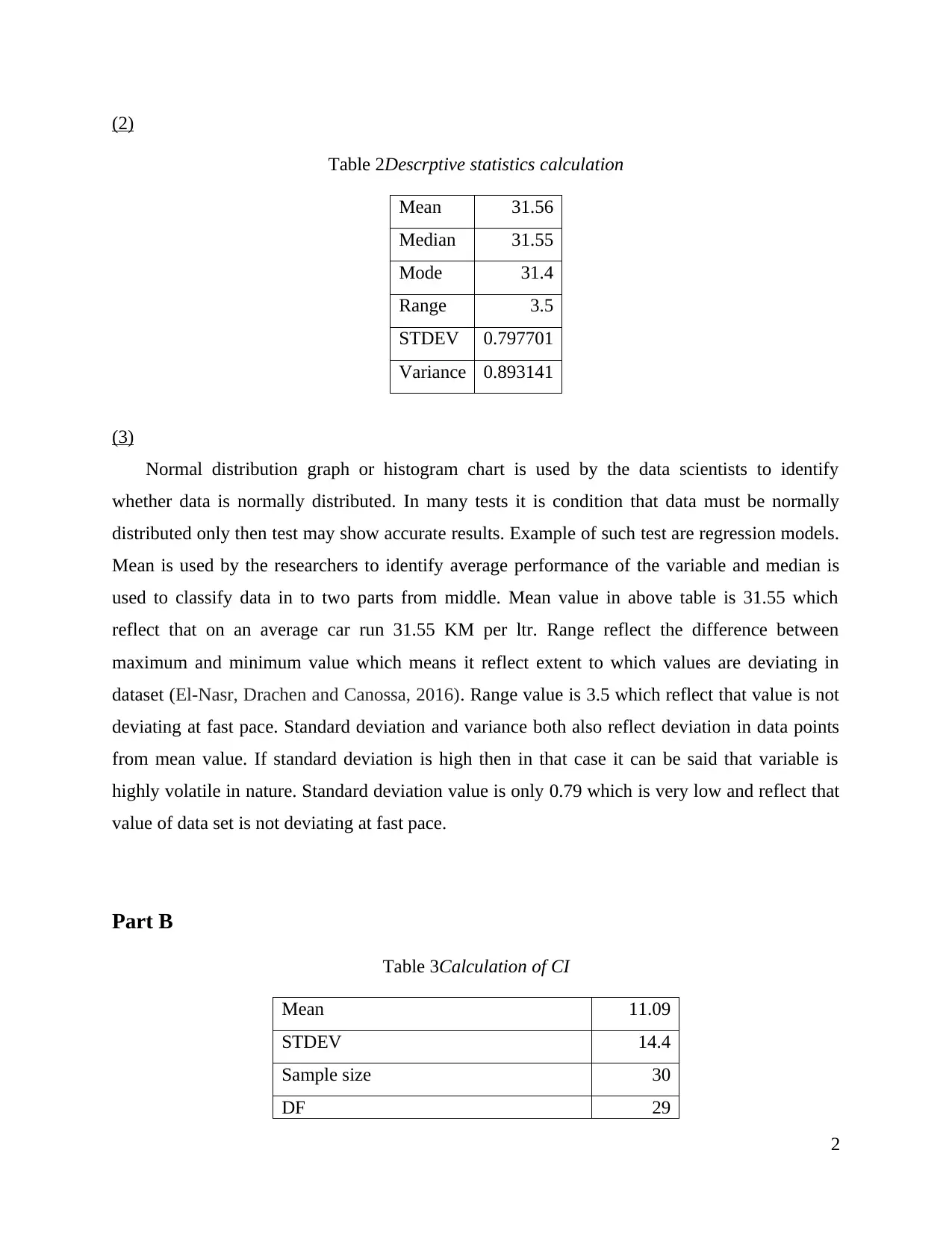
This Business Statistics homework assignment covers several key statistical concepts. Part A focuses on descriptive statistics, including calculating mean, median, range, standard deviation, and variance from raw data presented in a table and histogram. Part B calculates a confidence interval. Part C discusses the significance of statistics for managers in business decision-making. Part D involves hypothesis testing, explaining the process and providing a calculation of probability. Finally, Part E presents a probability calculation related to salary. The assignment uses tables, histograms and statistical calculations to analyze data and draw conclusions, with references to relevant literature.






1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.