Business Statistics Assignment: Data Analysis, Charts, and Statistics
VerifiedAdded on 2020/05/28
|23
|3433
|387
Homework Assignment
AI Summary
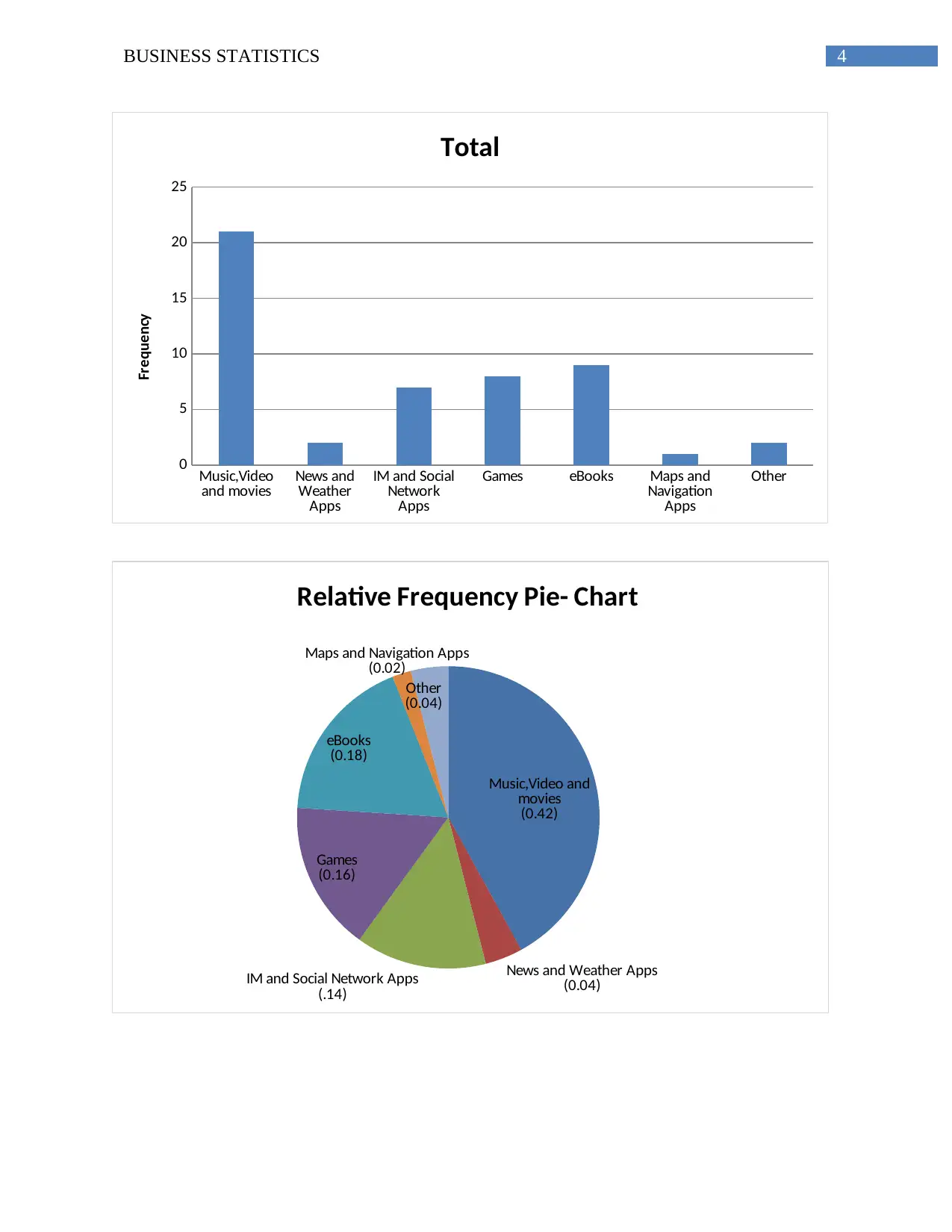
This assignment solution addresses a business statistics problem, beginning with random number selection based on a student ID to choose data samples. It then constructs frequency column charts and relative frequency pie charts to represent the distribution of entertainment types. Part of the assignment involves calculating income percentiles, including the 70th percentile and the interquartile range, using provided income data. Descriptive statistics such as mean, median, mode, standard deviation, and variance are calculated and analyzed to understand the dataset's central tendency and dispersion. The solution also explores whether the data follows a normal distribution, assessing skewness and identifying the number of observations within a specified range using Z-scores. The assignment provides detailed calculations and interpretations, demonstrating a comprehensive understanding of statistical concepts and their application.









1 out of 23
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.