Clinical Research Skills: Analysis of LBP_Final.sav SPSS Data Report
VerifiedAdded on 2023/01/13
|11
|1807
|25
Report
AI Summary
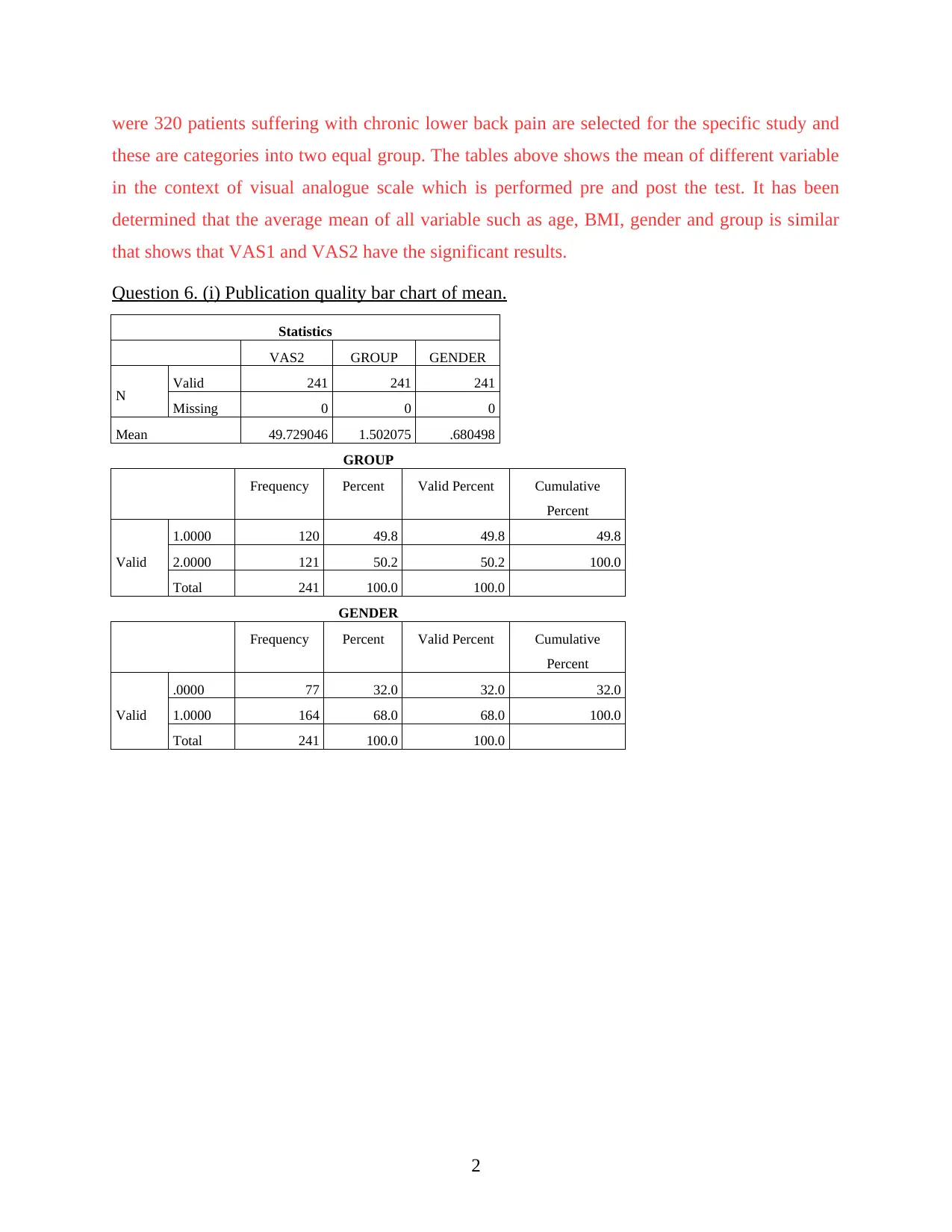
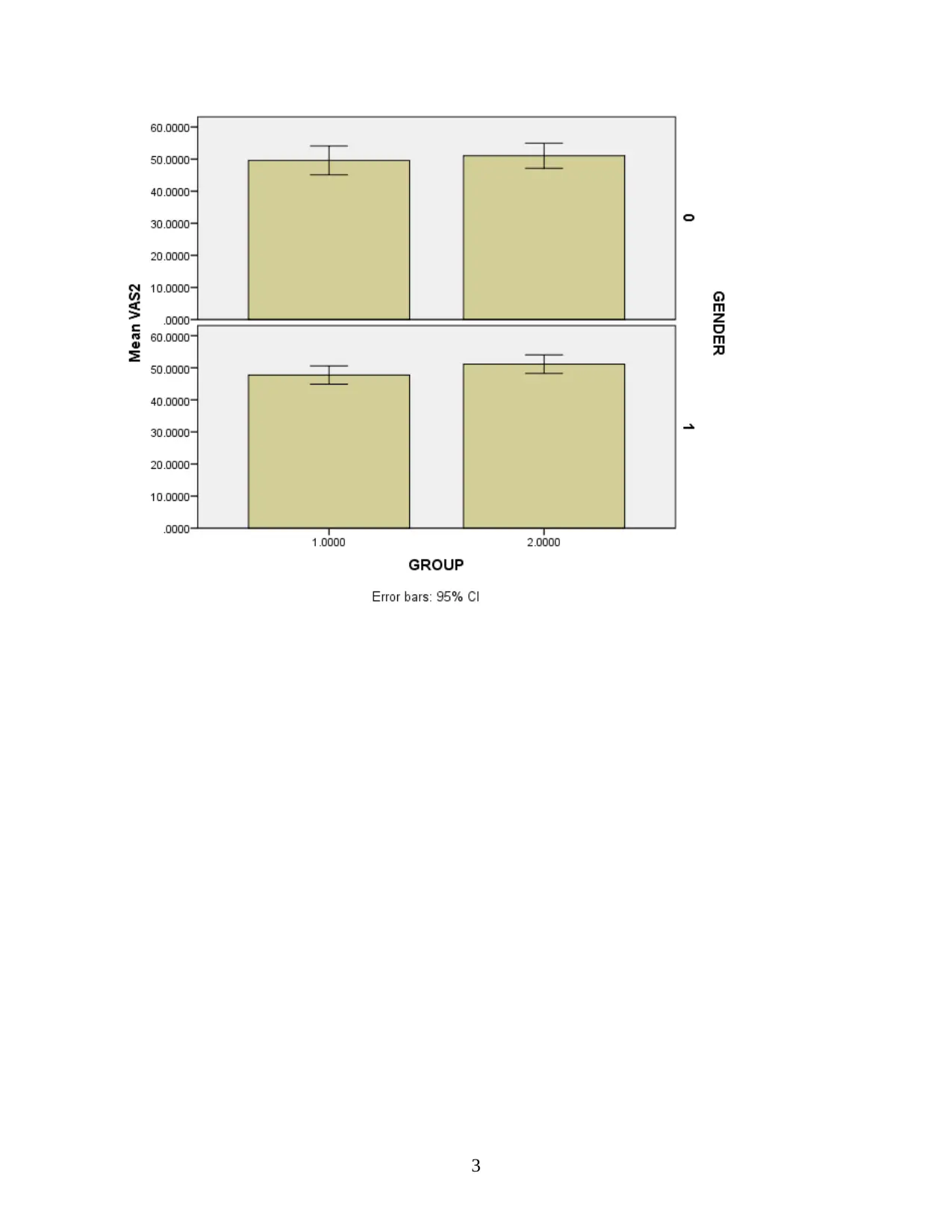
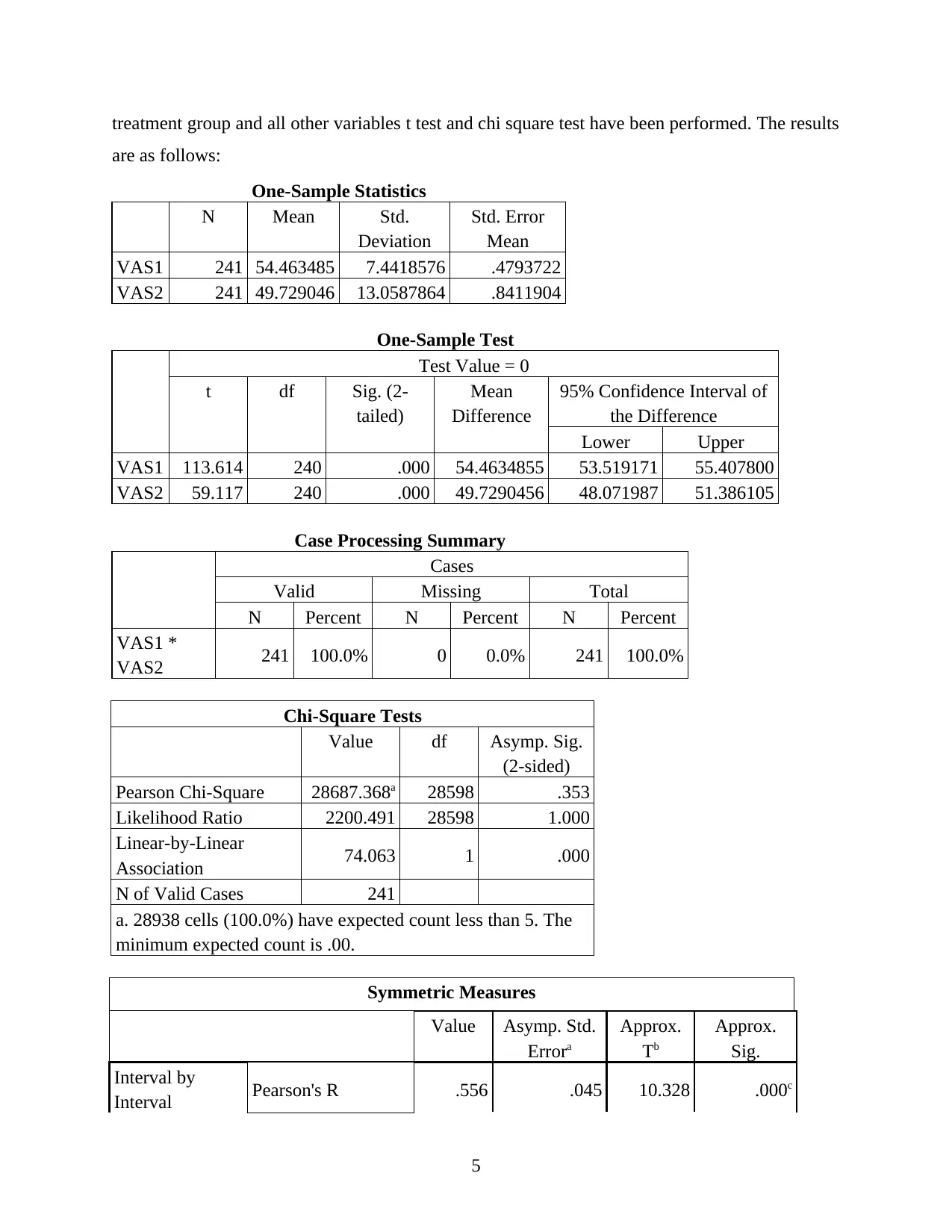
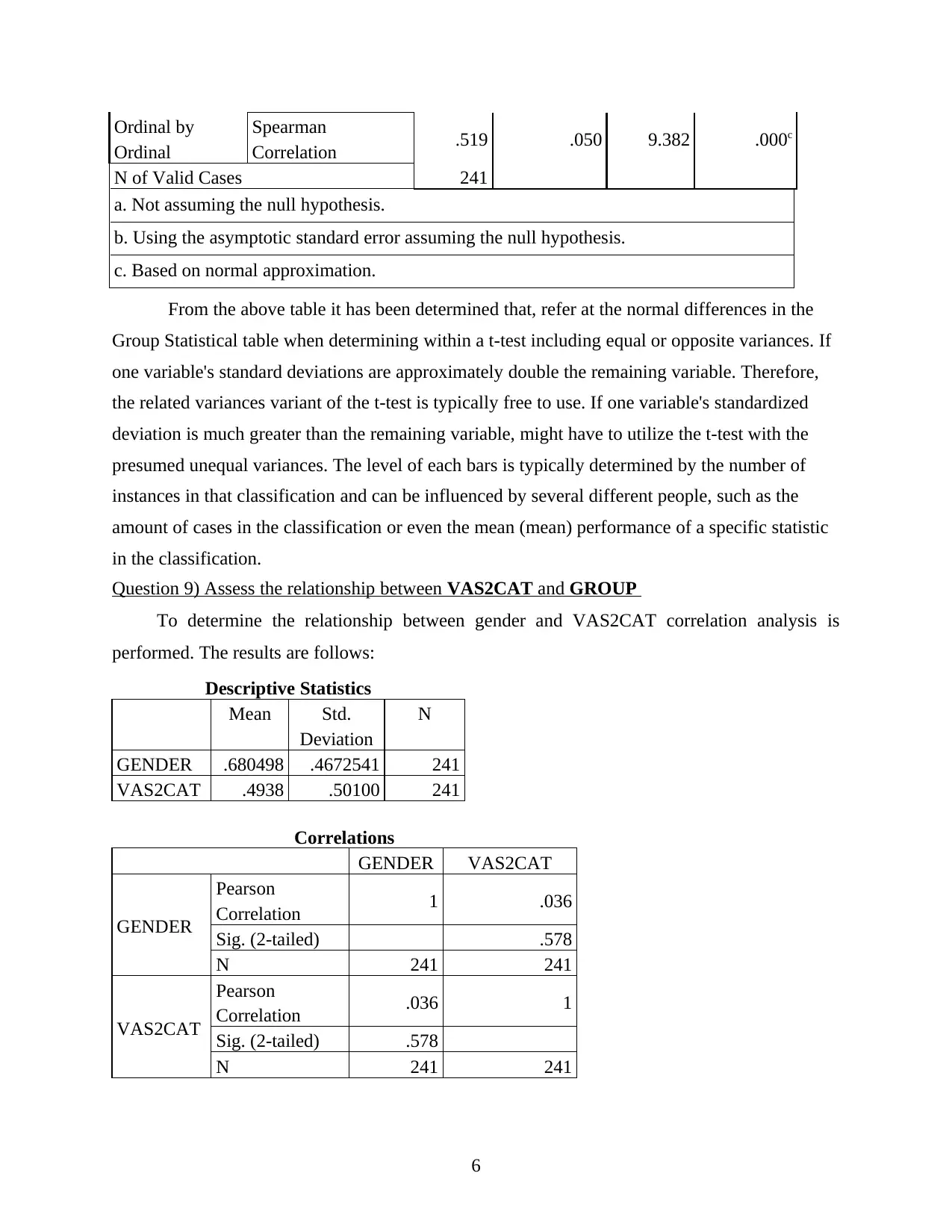
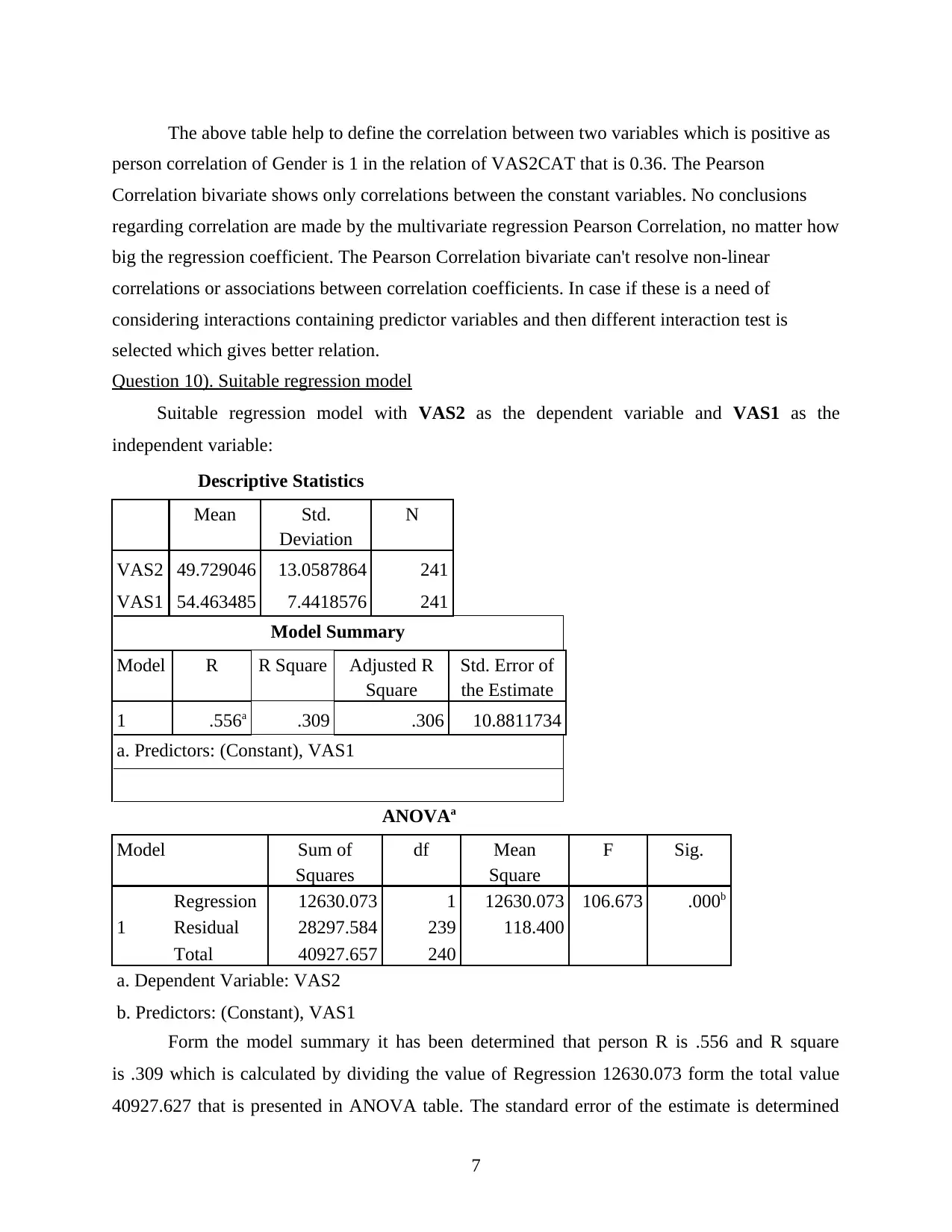
This report presents an analysis of clinical research data from the SPSS file LBP_Final.sav, focusing on subjects who returned for a 3-month assessment. The analysis includes creating new variables, generating quality tables summarizing demographic and clinical variables, and constructing publication-quality bar charts. The report justifies the choice of plots, identifies suitable statistical tests (t-test, chi-square), assesses relationships between variables (VAS2CAT and GROUP), and proposes a suitable regression model. It also details the statistical methods employed (descriptive analysis, regression, correlation) and concludes with key findings regarding the data's distribution and variable comparisons, particularly concerning VAS1 and VAS2 scores and their relationship to other variables like age and gender. The report emphasizes the importance of clinical research skills, including data analysis, GCP compliance, and safety management.





1 out of 11
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.