Software Construction Project: DSL Compiler Design and Implementation
VerifiedAdded on 2023/06/10
|13
|1794
|407
Project
AI Summary
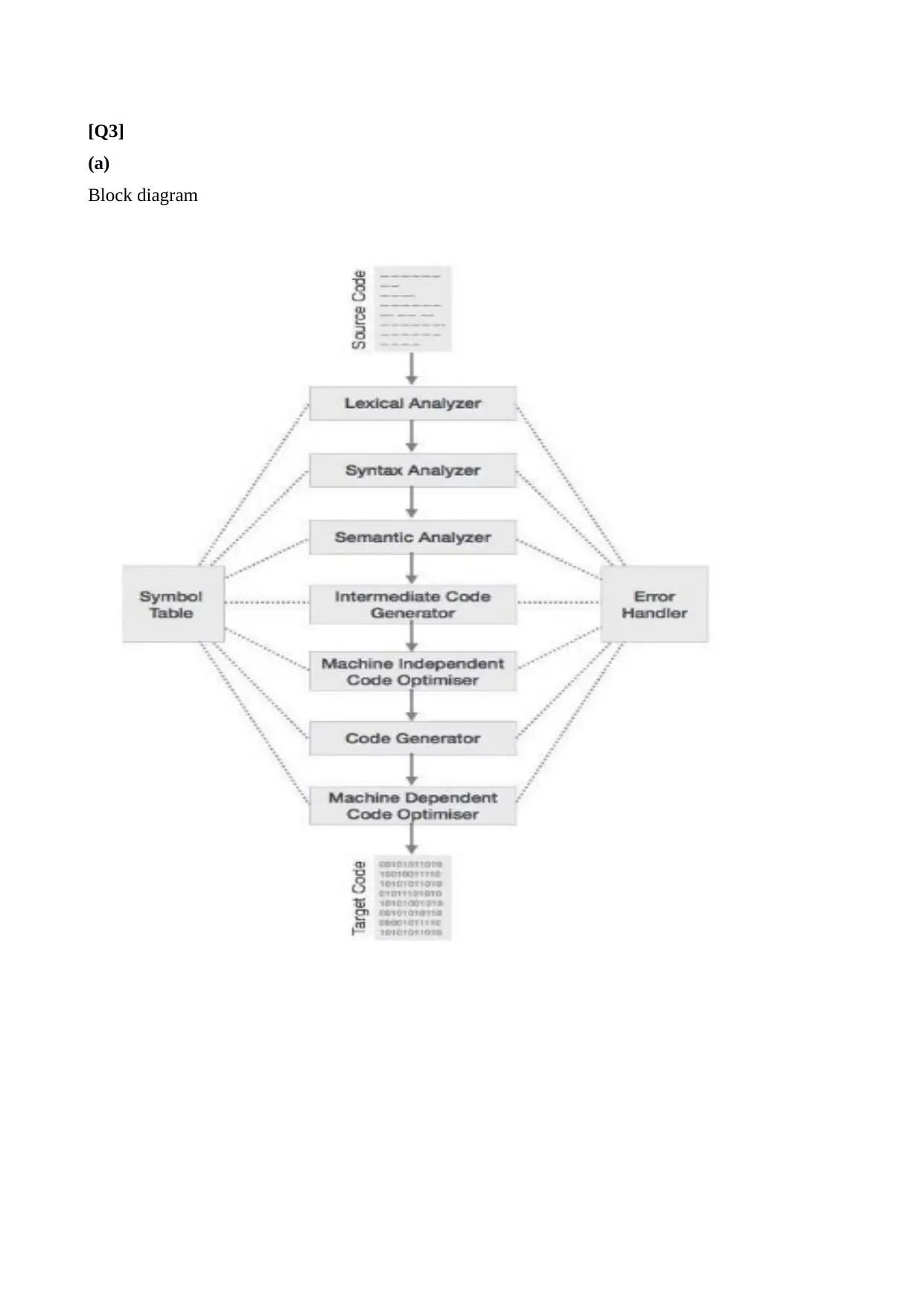
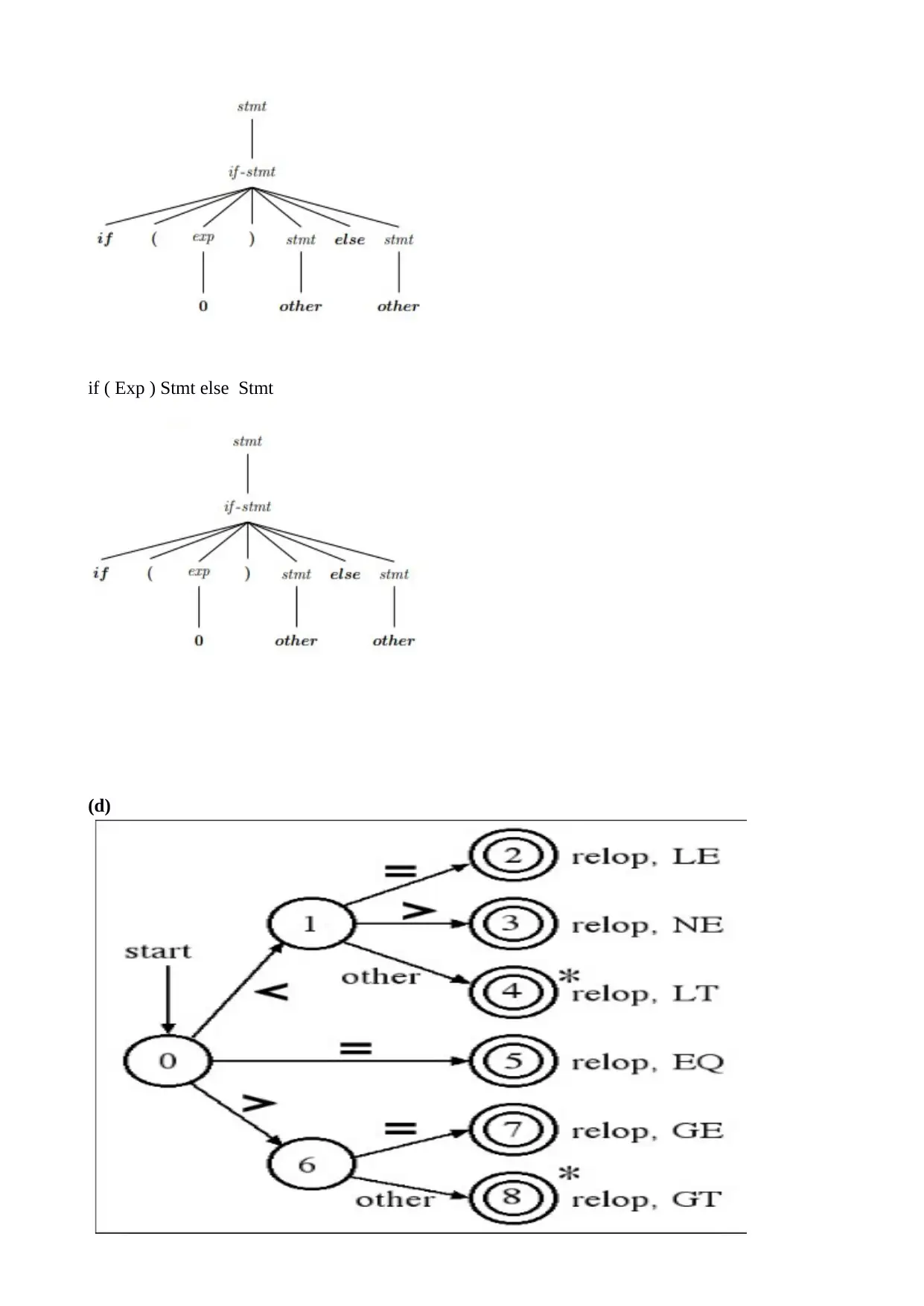
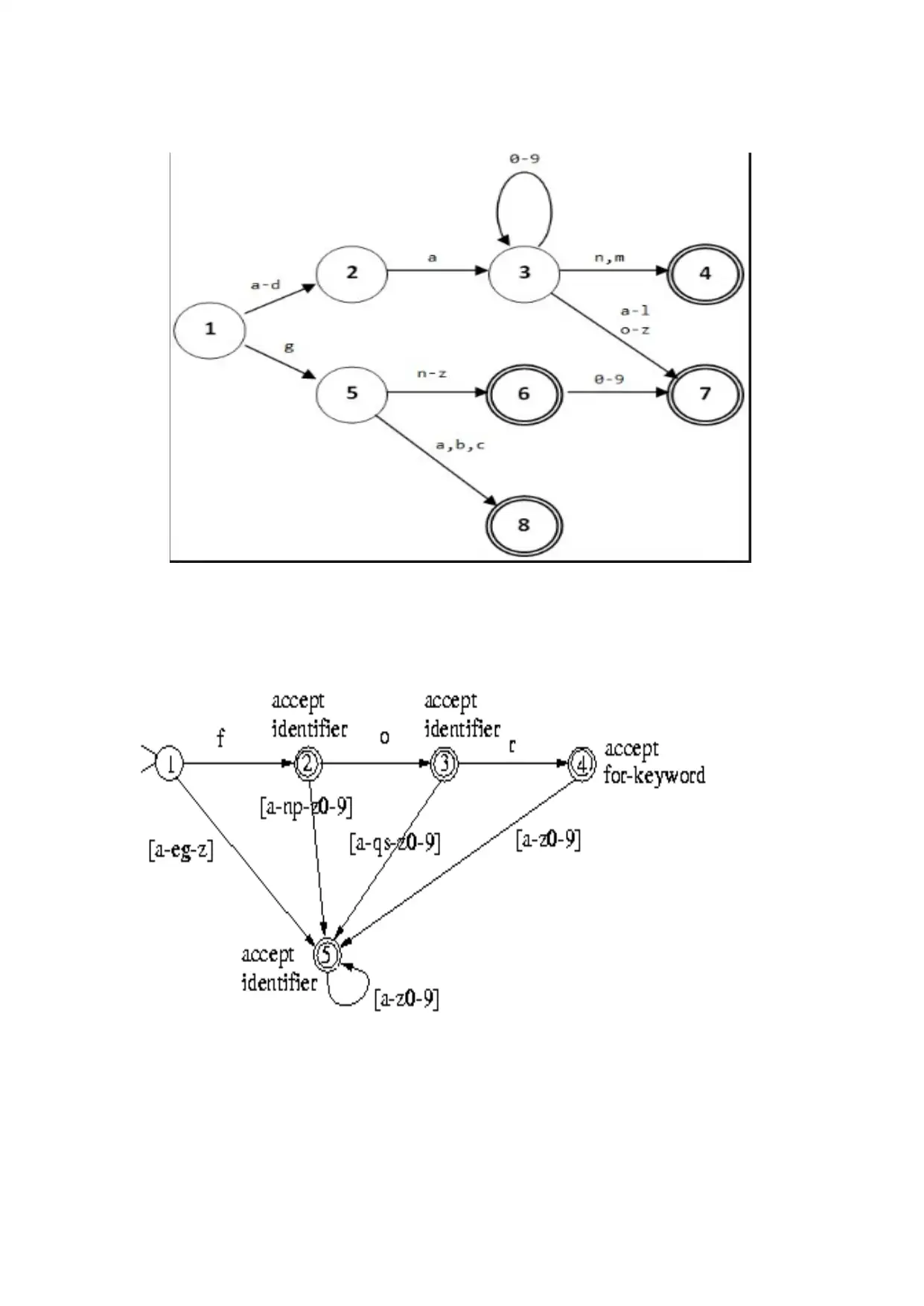
This project focuses on designing and implementing a compiler for a domain-specific language (DSL). The solution covers various phases of compiler design, including lexical analysis, syntax analysis, semantic analysis, intermediate code generation, code optimization, and target code generation. It defines the grammar for the DSL using context-free grammar, and illustrates the creation of Non-deterministic Finite Automata (NDFA) and Deterministic Finite Automata (DFA) based on the production rules. The project also includes code snippets using Lex and YACC tools for grammar verification, demonstrating the practical aspects of compiler construction. The symbol table manager and error handler modules are also mentioned. Desklib provides access to a wealth of study resources, including past papers and solved assignments, to aid students in mastering compiler design and related topics.









1 out of 13


Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.