KIT Corporation: Real-Time Analytics Report on Malaria Deaths
VerifiedAdded on 2023/03/17
|20
|3861
|30
Report
AI Summary
This report presents a comprehensive analysis of malaria-related deaths using real-time analytics and data mining techniques. The study leverages data from the World Health Organization (WHO) repository and performs analysis within SAP Predictive Analysis. The report begins with an introduction to real-time analytics, its applications, and challenges, particularly in handling big data. It then delves into data mining techniques, including regression and classification algorithms, used to analyze the dataset of malaria reported deaths. The research section outlines the methodology, research questions, and objectives, focusing on understanding the trends and patterns of malaria deaths across different countries and years. The analysis includes machine learning applications within SAP Predictive Analysis. The report provides recommendations for the CEO of KIT Corporation based on the findings and concludes with a summary of the key insights. It also includes the data analysis process, the use of SAP Predictive Analytics software, and the selection of target variables for analysis. The report aims to create awareness and provide insights for the business. The report also describes the comparison of classification and prediction methods. The report provides a detailed look into the use of the model and its application in real-time analytics.

Cover letter
KIT Corporation,
39 Woolnough Road
BROWN HILL CREEK
South Australia.
MR. Hamish A Murray,
CEO,
KIT Corporation.
Sir,
The Classication of the Data Analytics is specified in this report. We conducted the data
analytics to collect the “Malaria Reported deaths” dataset information form the WHO (World
Health Organization) repository. The analysis is performed in the SAP predictive analysis. All
the findings are showed graphically within the report.
Yours Sincerely,
XYZ.
Date,
17/5/2019.
KIT Corporation,
39 Woolnough Road
BROWN HILL CREEK
South Australia.
MR. Hamish A Murray,
CEO,
KIT Corporation.
Sir,
The Classication of the Data Analytics is specified in this report. We conducted the data
analytics to collect the “Malaria Reported deaths” dataset information form the WHO (World
Health Organization) repository. The analysis is performed in the SAP predictive analysis. All
the findings are showed graphically within the report.
Yours Sincerely,
XYZ.
Date,
17/5/2019.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
1
REALTIME
ANALYTICS
REALTIME
ANALYTICS

Contents
1. Introduction..............................................................................................................................3
2. Data Mining Techniques..........................................................................................................4
3. Research...................................................................................................................................8
4. Recommendations for CEO....................................................................................................17
5. Conclusion..............................................................................................................................18
6. References..............................................................................................................................19
2
1. Introduction..............................................................................................................................3
2. Data Mining Techniques..........................................................................................................4
3. Research...................................................................................................................................8
4. Recommendations for CEO....................................................................................................17
5. Conclusion..............................................................................................................................18
6. References..............................................................................................................................19
2
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

1.Introduction
Real time analytics is used to enterprise all data and resources when they are needed. It
allows the business to process without any delay and prevent problems before they happen. It
uses certain financial institutions to decide about the credit, Fraud detection at points of sale. The
biggest challenge of real-time analytics is to handle big data. Real-time big data analytics are
already used in financial trading. The data is used in the form of financial databases, social
media, and satellite weather stations for the buying and selling decisions. The major process used
in the Real-time analytics is classification which says about the historical background, elements
used in the process and characteristics of the real-time systems. Data set used in the Real-time
analytics know as Reported deaths Data for the analysis of the Malaria (Bialski, 2012). The death
data which says about the risk factor of malaria and shows about the people’s suffering, death
rate and control measures in the locality. These ratings are more accurately given by the WHO
(World Health Organization), and it also explains about the major effects that are caused by the
various insects and parasites, it is mainly caused by the Plasmodium parasites. It also explains
about the transmission to the people. SAP Predictive Analysis is a software intelligence by the
SAP that is designed to make analyses of the dataset of a table and to make a forecast on the
outputs received and the attributes are explained on the further sections. While building a
predictive model traditionally it has been done using the scripts and algorithms are applied
manually. So the predictive analytics is used by the business users and the analyst of data to
create a new predictive model. Machine learning based on the SAP Predictive analysis is
described briefly. Machine learning always focuses on how data is retrieved and the development
of computer programs.
Research Questions
How many numbers of malaria deaths are reported?
What countries have the highest rate of malaria?
How many people died of malaria in 2017 and 2016?
How many cases of malaria were reported for all who reporting regions?
3
Real time analytics is used to enterprise all data and resources when they are needed. It
allows the business to process without any delay and prevent problems before they happen. It
uses certain financial institutions to decide about the credit, Fraud detection at points of sale. The
biggest challenge of real-time analytics is to handle big data. Real-time big data analytics are
already used in financial trading. The data is used in the form of financial databases, social
media, and satellite weather stations for the buying and selling decisions. The major process used
in the Real-time analytics is classification which says about the historical background, elements
used in the process and characteristics of the real-time systems. Data set used in the Real-time
analytics know as Reported deaths Data for the analysis of the Malaria (Bialski, 2012). The death
data which says about the risk factor of malaria and shows about the people’s suffering, death
rate and control measures in the locality. These ratings are more accurately given by the WHO
(World Health Organization), and it also explains about the major effects that are caused by the
various insects and parasites, it is mainly caused by the Plasmodium parasites. It also explains
about the transmission to the people. SAP Predictive Analysis is a software intelligence by the
SAP that is designed to make analyses of the dataset of a table and to make a forecast on the
outputs received and the attributes are explained on the further sections. While building a
predictive model traditionally it has been done using the scripts and algorithms are applied
manually. So the predictive analytics is used by the business users and the analyst of data to
create a new predictive model. Machine learning based on the SAP Predictive analysis is
described briefly. Machine learning always focuses on how data is retrieved and the development
of computer programs.
Research Questions
How many numbers of malaria deaths are reported?
What countries have the highest rate of malaria?
How many people died of malaria in 2017 and 2016?
How many cases of malaria were reported for all who reporting regions?
3
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

2.Data Mining Techniques
The data mining techniques are explained here. It is an execution of depicts between a
group of descriptive attributes and target attribute, that is between the input of a model and
output of a model that we create. These regression algorithms are of the family in predictive
models to be built that belongs to the model. The proprietary algorithm is used by the Automated
Analytics Engine. The predictive models are built using the training dataset that contains the
questions regarding the business. The returned models contain the polynomial expression who
need input number. The attribute contribution, the relative importance of weighting by the input
of the trained models has been analyzed. The characteristics are described in two types,
1. Predictive Power: It is commonly known as KI. It represents the quality of the model created
by Automated Analytics. The Predictive Power responds to the information that has a proportion.
It is also an explanatory variable that is explained using the target variable.
2. Prediction Confidence: It is commonly called as KR. It is a strong indicator of the model that
is created by Automated Analytics (Bruce Hanson, 2018).
The capacity value of the model is described to reach the same level of performance when KR is
given to the new dataset which has the same characteristics of the training dataset.
PREDICTION AND ACTION IN BUSINESS MOMENT USING AUTOMATION
The extreme changes are made across the various features on the business and make all
the enterprises to recreate the customers' value and the operational model. The employees,
customers, and partners are connected digitally. These peoples have an uneven opportunity on
the value for the creation and to capture. But it has risk on the organization chose that does not
respond to that problem.
When an employee, customer, and partners have increased expectations will make
pressure on the leaders of the business which will result in the innovative creation of the new
form value and occupy it. The new values will not be the responsibility for the business but
recreate the operating models. The digital transformations are made by predictive analysis. To
4
The data mining techniques are explained here. It is an execution of depicts between a
group of descriptive attributes and target attribute, that is between the input of a model and
output of a model that we create. These regression algorithms are of the family in predictive
models to be built that belongs to the model. The proprietary algorithm is used by the Automated
Analytics Engine. The predictive models are built using the training dataset that contains the
questions regarding the business. The returned models contain the polynomial expression who
need input number. The attribute contribution, the relative importance of weighting by the input
of the trained models has been analyzed. The characteristics are described in two types,
1. Predictive Power: It is commonly known as KI. It represents the quality of the model created
by Automated Analytics. The Predictive Power responds to the information that has a proportion.
It is also an explanatory variable that is explained using the target variable.
2. Prediction Confidence: It is commonly called as KR. It is a strong indicator of the model that
is created by Automated Analytics (Bruce Hanson, 2018).
The capacity value of the model is described to reach the same level of performance when KR is
given to the new dataset which has the same characteristics of the training dataset.
PREDICTION AND ACTION IN BUSINESS MOMENT USING AUTOMATION
The extreme changes are made across the various features on the business and make all
the enterprises to recreate the customers' value and the operational model. The employees,
customers, and partners are connected digitally. These peoples have an uneven opportunity on
the value for the creation and to capture. But it has risk on the organization chose that does not
respond to that problem.
When an employee, customer, and partners have increased expectations will make
pressure on the leaders of the business which will result in the innovative creation of the new
form value and occupy it. The new values will not be the responsibility for the business but
recreate the operating models. The digital transformations are made by predictive analysis. To
4

make these needs companies must meet the requirements on customer experience, fast and data-
driven decisions. Most of the successful companies use predictive analytics for the applications,
processes, and solutions for the business line.
ACCURATE RESULT
SAP Predictive Analytics are used for the efficient and for the result produced accurately
on the whole predictive modeling processes. The preparation of data permits to create many
derived variables faster without the programming codes. SAP Predictive Analytics has created
models of automation that are self-serving. The predictive models have a high level of accuracy
and it gradually increases the work flow through productivity (Decreusefond, Moyal & Limnios,
2012).
MACHINE LEARNING:
The outlook based on SAP Predictive Analytics that rule, maintain, store and value the
models on probability. We can create thousands of the models segmented without the modeling
environment. The automated model management is done because of its user-friendly, single-
sign-on environment and it is browser based. Using these the models are created as real time, the
models can be managed, scheduling is made and a variety of scenarios are made used.
The performance level is measured and maintained for every single model using SAP
Predictive Analytics. It is done with a simple click and an end-to-end predictive lifecycle is
maintained along with the governance of the enterprise. The feature that makes easier to use is
the flexibility and loose coupling of the predictive factory architecture. It will make easy to
combine with the latest IT landscapes that include the business intelligence, rule of the system,
Big Data ecosystem, data sources, applications, and process on the business. It promotes the
combinations with the SAP Hybrids solutions and SAP software.
5
driven decisions. Most of the successful companies use predictive analytics for the applications,
processes, and solutions for the business line.
ACCURATE RESULT
SAP Predictive Analytics are used for the efficient and for the result produced accurately
on the whole predictive modeling processes. The preparation of data permits to create many
derived variables faster without the programming codes. SAP Predictive Analytics has created
models of automation that are self-serving. The predictive models have a high level of accuracy
and it gradually increases the work flow through productivity (Decreusefond, Moyal & Limnios,
2012).
MACHINE LEARNING:
The outlook based on SAP Predictive Analytics that rule, maintain, store and value the
models on probability. We can create thousands of the models segmented without the modeling
environment. The automated model management is done because of its user-friendly, single-
sign-on environment and it is browser based. Using these the models are created as real time, the
models can be managed, scheduling is made and a variety of scenarios are made used.
The performance level is measured and maintained for every single model using SAP
Predictive Analytics. It is done with a simple click and an end-to-end predictive lifecycle is
maintained along with the governance of the enterprise. The feature that makes easier to use is
the flexibility and loose coupling of the predictive factory architecture. It will make easy to
combine with the latest IT landscapes that include the business intelligence, rule of the system,
Big Data ecosystem, data sources, applications, and process on the business. It promotes the
combinations with the SAP Hybrids solutions and SAP software.
5
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
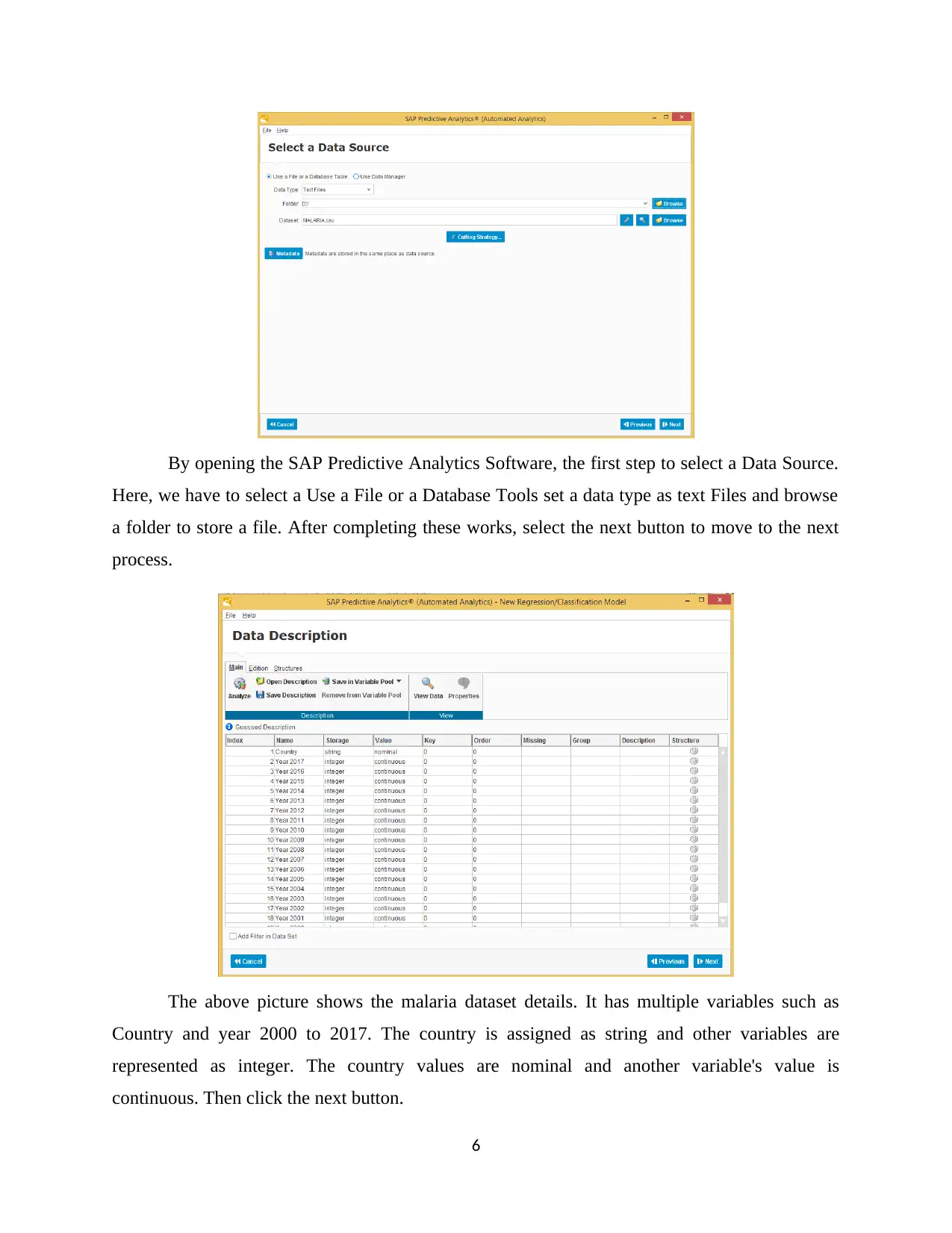
By opening the SAP Predictive Analytics Software, the first step to select a Data Source.
Here, we have to select a Use a File or a Database Tools set a data type as text Files and browse
a folder to store a file. After completing these works, select the next button to move to the next
process.
The above picture shows the malaria dataset details. It has multiple variables such as
Country and year 2000 to 2017. The country is assigned as string and other variables are
represented as integer. The country values are nominal and another variable's value is
continuous. Then click the next button.
6
Here, we have to select a Use a File or a Database Tools set a data type as text Files and browse
a folder to store a file. After completing these works, select the next button to move to the next
process.
The above picture shows the malaria dataset details. It has multiple variables such as
Country and year 2000 to 2017. The country is assigned as string and other variables are
represented as integer. The country values are nominal and another variable's value is
continuous. Then click the next button.
6
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
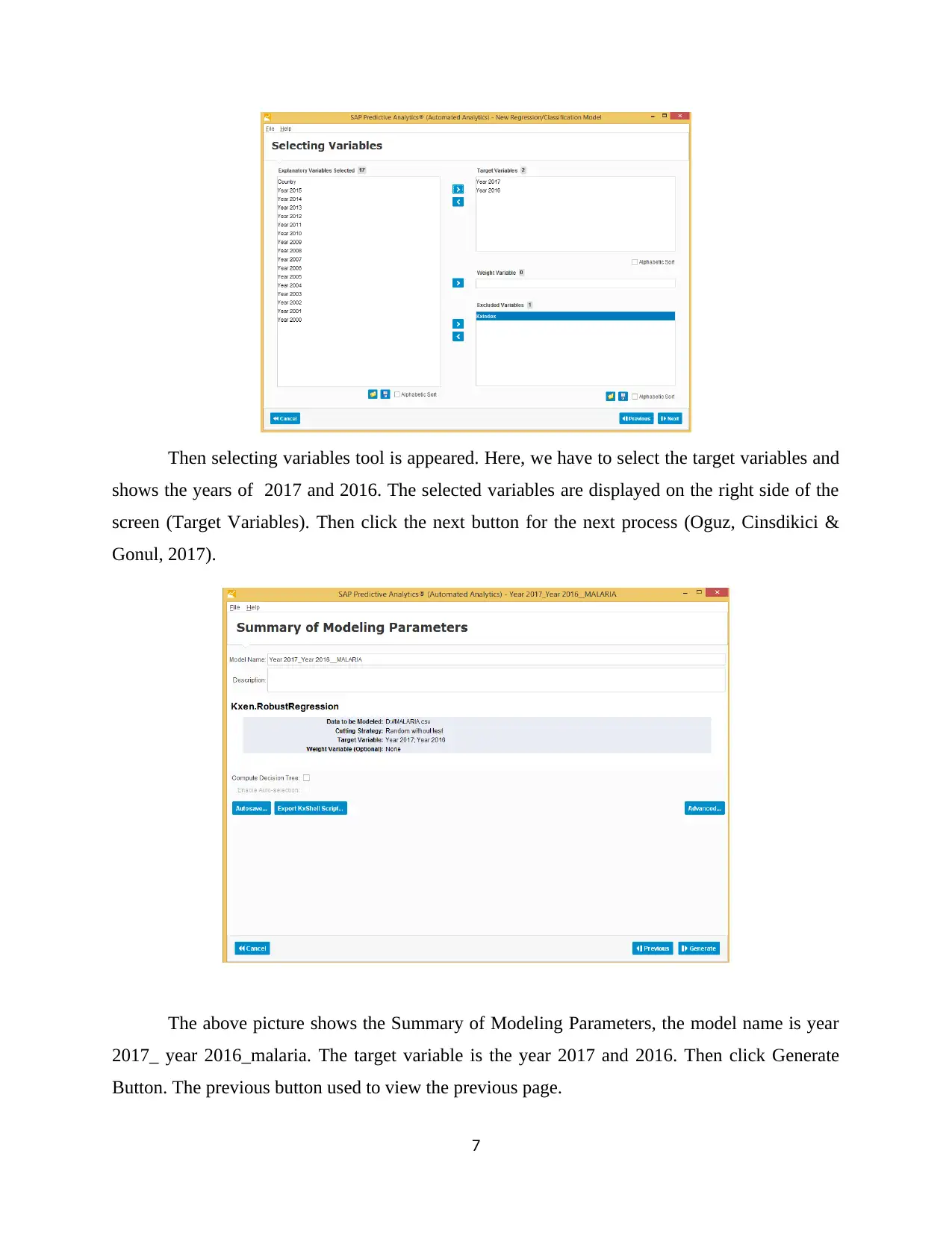
Then selecting variables tool is appeared. Here, we have to select the target variables and
shows the years of 2017 and 2016. The selected variables are displayed on the right side of the
screen (Target Variables). Then click the next button for the next process (Oguz, Cinsdikici &
Gonul, 2017).
The above picture shows the Summary of Modeling Parameters, the model name is year
2017_ year 2016_malaria. The target variable is the year 2017 and 2016. Then click Generate
Button. The previous button used to view the previous page.
7
shows the years of 2017 and 2016. The selected variables are displayed on the right side of the
screen (Target Variables). Then click the next button for the next process (Oguz, Cinsdikici &
Gonul, 2017).
The above picture shows the Summary of Modeling Parameters, the model name is year
2017_ year 2016_malaria. The target variable is the year 2017 and 2016. Then click Generate
Button. The previous button used to view the previous page.
7

3.Research
The Conducted research is explained in this process. This is used to make an evaluation
to the people or to make use of the Modeler for building Regression/Classification. This does not
need statistics or database for creating a new model.
FILES AND DOCUMENTATION
The application has a sample data and these files are stored in the folder D. The name of
the dataset table is Reported deaths Data by country. The manually used Application model is
used in this data file. The dataset name is MALARIA.csv and it can be accessed using this name.
APPLICATIONS ON REGRESSION/CLASSIFICATION
The outline used is about the report of the deaths in most of the countries due to malaria.
It needs increased skills on statistics of data using modeling. The World Health Organization
make statistics of the people who died because of the attack of malaria. This project is to indicate
the peoples die year by year increased or decreased. It is a large database that must be analyzed
deeply with significant time. It is open-data information with 10,000 rows of dataset table (Peng
& Zeng, 2017). Here we explained the examples of Classification in data analysis task:
It analyzes the death of malaria reported in order to know how risky and safe.
A data analyzer has analyzed a people with an issued details.
These both examples are categorized the attacks by the malaria. These are the details are
reported in the data analysis.
OBJECTIVE
The objective is about the statistics created by the WHO. It gives the report about the
people who caused by the malaria. And its major objective is create the awareness between the
people and the Government.
MEANS
It is a statistical analysis that is developed based on records. It also takes various
measures to control the death which is caused by the malaria in the year 2000-2017. Depending
8
The Conducted research is explained in this process. This is used to make an evaluation
to the people or to make use of the Modeler for building Regression/Classification. This does not
need statistics or database for creating a new model.
FILES AND DOCUMENTATION
The application has a sample data and these files are stored in the folder D. The name of
the dataset table is Reported deaths Data by country. The manually used Application model is
used in this data file. The dataset name is MALARIA.csv and it can be accessed using this name.
APPLICATIONS ON REGRESSION/CLASSIFICATION
The outline used is about the report of the deaths in most of the countries due to malaria.
It needs increased skills on statistics of data using modeling. The World Health Organization
make statistics of the people who died because of the attack of malaria. This project is to indicate
the peoples die year by year increased or decreased. It is a large database that must be analyzed
deeply with significant time. It is open-data information with 10,000 rows of dataset table (Peng
& Zeng, 2017). Here we explained the examples of Classification in data analysis task:
It analyzes the death of malaria reported in order to know how risky and safe.
A data analyzer has analyzed a people with an issued details.
These both examples are categorized the attacks by the malaria. These are the details are
reported in the data analysis.
OBJECTIVE
The objective is about the statistics created by the WHO. It gives the report about the
people who caused by the malaria. And its major objective is create the awareness between the
people and the Government.
MEANS
It is a statistical analysis that is developed based on records. It also takes various
measures to control the death which is caused by the malaria in the year 2000-2017. Depending
8
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

upon the performance validation and estimation increases in the year 2016-2017.According to
the statistics the maximum death is happened in the year 2012 and minimum is in 2006. From
2001 to 2006 there is only a minor difference in the death level. But from 2007 there was a huge
difference with increased death.
The working on the classification is understood with the help of the death rate on malaria
over the countries. The process of data classification is of two steps,
Developing a model or a classifier
Using the classification of classifier
DEVELOPING A MODEL OR A CLASSIFIER
Building a classifier is a learning phase or a learning step.
The classifiers are built using the classification algorithms.
The training set is built using the database tuples and the combination of class
labels that are used to develop the classifiers.
Every single tuple has a training set that describes the category or class. It is
referred to using the sample models, data or objects.
USING THE CLASSIFICATION OF CLASSIFIER
This step explains about the classifier made for the classification. The test data is used to
make the probability of accuracy on the classification of rules. The rules are applied to the newer
data tuples if the accuracy is present.
COMPARISON ON CLASSIFICATION AND PREDICTION METHODS
Accuracy -The accuracy is defined as the ability of the classifier. The class labels are
projected correctly and the guess made on the value of the attribute of the predicate is the
accuracy of the predicate.
Speed - It is the calculation of the cost while creating and using the classifiers or models.
Robustness - The ability to make the predictions correctly with the given data.
Scalability - When a large amount of data is given the ability to build the model is
scalability.
9
the statistics the maximum death is happened in the year 2012 and minimum is in 2006. From
2001 to 2006 there is only a minor difference in the death level. But from 2007 there was a huge
difference with increased death.
The working on the classification is understood with the help of the death rate on malaria
over the countries. The process of data classification is of two steps,
Developing a model or a classifier
Using the classification of classifier
DEVELOPING A MODEL OR A CLASSIFIER
Building a classifier is a learning phase or a learning step.
The classifiers are built using the classification algorithms.
The training set is built using the database tuples and the combination of class
labels that are used to develop the classifiers.
Every single tuple has a training set that describes the category or class. It is
referred to using the sample models, data or objects.
USING THE CLASSIFICATION OF CLASSIFIER
This step explains about the classifier made for the classification. The test data is used to
make the probability of accuracy on the classification of rules. The rules are applied to the newer
data tuples if the accuracy is present.
COMPARISON ON CLASSIFICATION AND PREDICTION METHODS
Accuracy -The accuracy is defined as the ability of the classifier. The class labels are
projected correctly and the guess made on the value of the attribute of the predicate is the
accuracy of the predicate.
Speed - It is the calculation of the cost while creating and using the classifiers or models.
Robustness - The ability to make the predictions correctly with the given data.
Scalability - When a large amount of data is given the ability to build the model is
scalability.
9
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

SAP Predictive Analytics are used to deliver results in decision point in applications and
systems. We initiate predictive probability for an open variety of specified system and it is most
useful in the database (business processes and line-of-business solutions) are performed. From
the SAP platform, it allows to perform a memory-scoring in the SAP predictive analysis
platform, relational database management system and data sources. Without moving data, we can
store each model and directly embed into SAP HANA and SAP S/4HANA software. By
generating a CCL (Continuous Computation Model) code are used for the model and install the
software for using cases.
The SAP model is placed in the predictive insights of Organization. With the SAP
Analytics Cloud Solution, the customers can hold the platform and to identify key variables with
the mouse click.
From the SAP Predictive Analytics software, it depends on the * Data manager
Guided model authoring
Predictive factory
Predictive factory
Scorer
Link analysis and recommendation
Software development kit and API
SAP Predictive Analytics provides
It delivers predictive insights faster by reducing the errors through automated techniques
with the help of quality measures (KI and KR)
The thousands of predictive models have scaled with the machine learning that are valued
and enterprise.
It contributes to the predictive value chain using guided workflows and automated
techniques. It is integrated with SAP software by including the SAP HANA, SAP
S/4HANA, SAP Business Objects and the SAP business Warehouse Application.
It improves the operating margins across the enterprise by utilizing thousands of models.
It increases productivity, to create predictive data sets it does not have multiple points.
10
systems. We initiate predictive probability for an open variety of specified system and it is most
useful in the database (business processes and line-of-business solutions) are performed. From
the SAP platform, it allows to perform a memory-scoring in the SAP predictive analysis
platform, relational database management system and data sources. Without moving data, we can
store each model and directly embed into SAP HANA and SAP S/4HANA software. By
generating a CCL (Continuous Computation Model) code are used for the model and install the
software for using cases.
The SAP model is placed in the predictive insights of Organization. With the SAP
Analytics Cloud Solution, the customers can hold the platform and to identify key variables with
the mouse click.
From the SAP Predictive Analytics software, it depends on the * Data manager
Guided model authoring
Predictive factory
Predictive factory
Scorer
Link analysis and recommendation
Software development kit and API
SAP Predictive Analytics provides
It delivers predictive insights faster by reducing the errors through automated techniques
with the help of quality measures (KI and KR)
The thousands of predictive models have scaled with the machine learning that are valued
and enterprise.
It contributes to the predictive value chain using guided workflows and automated
techniques. It is integrated with SAP software by including the SAP HANA, SAP
S/4HANA, SAP Business Objects and the SAP business Warehouse Application.
It improves the operating margins across the enterprise by utilizing thousands of models.
It increases productivity, to create predictive data sets it does not have multiple points.
10
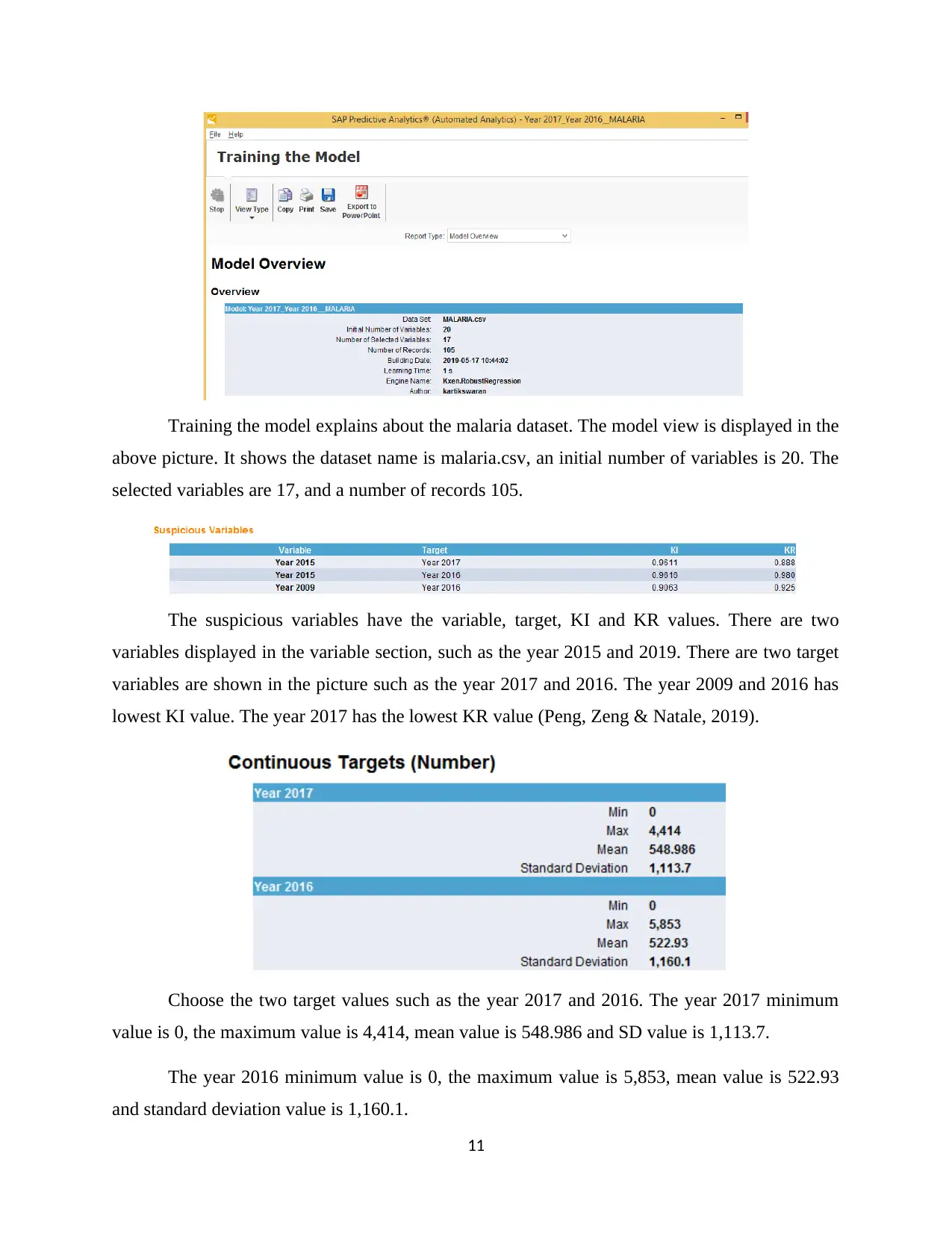
Training the model explains about the malaria dataset. The model view is displayed in the
above picture. It shows the dataset name is malaria.csv, an initial number of variables is 20. The
selected variables are 17, and a number of records 105.
The suspicious variables have the variable, target, KI and KR values. There are two
variables displayed in the variable section, such as the year 2015 and 2019. There are two target
variables are shown in the picture such as the year 2017 and 2016. The year 2009 and 2016 has
lowest KI value. The year 2017 has the lowest KR value (Peng, Zeng & Natale, 2019).
Choose the two target values such as the year 2017 and 2016. The year 2017 minimum
value is 0, the maximum value is 4,414, mean value is 548.986 and SD value is 1,113.7.
The year 2016 minimum value is 0, the maximum value is 5,853, mean value is 522.93
and standard deviation value is 1,160.1.
11
above picture. It shows the dataset name is malaria.csv, an initial number of variables is 20. The
selected variables are 17, and a number of records 105.
The suspicious variables have the variable, target, KI and KR values. There are two
variables displayed in the variable section, such as the year 2015 and 2019. There are two target
variables are shown in the picture such as the year 2017 and 2016. The year 2009 and 2016 has
lowest KI value. The year 2017 has the lowest KR value (Peng, Zeng & Natale, 2019).
Choose the two target values such as the year 2017 and 2016. The year 2017 minimum
value is 0, the maximum value is 4,414, mean value is 548.986 and SD value is 1,113.7.
The year 2016 minimum value is 0, the maximum value is 5,853, mean value is 522.93
and standard deviation value is 1,160.1.
11
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 20
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.