Creating an Inverted Index
VerifiedAdded on 2023/04/21
|12
|2086
|131
AI Summary
This document explains the process of creating an inverted index for data science, data mining, and information systems. It covers removing stop words and using the Porter Stemming algorithm. The document also discusses merging and sorting the list, testing the posting file, and understanding the Boolean and vector models. Additionally, it provides an evaluation of information retrieval (IR) performance.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

COVER PAGE ()
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Contents
Question 1...................................................................................................................................................3
Creating an inverted index......................................................................................................................3
Remove stop words.............................................................................................................................3
Porter Stemming algorithm.................................................................................................................3
Merged list..............................................................................................................................................4
Posting file...........................................................................................................................................5
Testing.................................................................................................................................................7
Boolean Model and vector Model...........................................................................................................7
Question 2 IR evaluation.............................................................................................................................8
Bibliography...............................................................................................................................................14
Question 1...................................................................................................................................................3
Creating an inverted index......................................................................................................................3
Remove stop words.............................................................................................................................3
Porter Stemming algorithm.................................................................................................................3
Merged list..............................................................................................................................................4
Posting file...........................................................................................................................................5
Testing.................................................................................................................................................7
Boolean Model and vector Model...........................................................................................................7
Question 2 IR evaluation.............................................................................................................................8
Bibliography...............................................................................................................................................14

Question 1
Creating an inverted index
Document 1
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and
systems to extract knowledge and insights from data in various forms, both structured and
unstructured.
Document 2
Data mining is the process of discovering patterns in large data sets involving methods at the
intersection of machine learning, statistics, and database systems
Document 3
Information systems is the study of complementary networks of hardware and software that
people and organizations use to collect, filter, process, create, and distribute data
Remove stop words
Results
Document 1
Data science interdisciplinary field scientific methods, processes, algorithms systems extract
knowledge insights data various forms, structured unstructured.
Document 2
Data mining process discovering patterns large data sets involving methods intersection
machine learning, statistics, database systems
Document 3
Information systems study complementary networks hardware software people organizations
collect, filter, process, create, distribute data
Porter Stemming algorithm
Results
Document 1
Data scienc interdisciplinari field scientif method process algorithm system extract knowledg
insight data variou form structur unstructur
Document 2
Data mine process discov pattern larg data set involv method intersect machin learn statist
databas system
Document 3
Informat system studi complementari network hardwar softwar peopl organ collect filter
process creat distribut data
Creating an inverted index
Document 1
Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and
systems to extract knowledge and insights from data in various forms, both structured and
unstructured.
Document 2
Data mining is the process of discovering patterns in large data sets involving methods at the
intersection of machine learning, statistics, and database systems
Document 3
Information systems is the study of complementary networks of hardware and software that
people and organizations use to collect, filter, process, create, and distribute data
Remove stop words
Results
Document 1
Data science interdisciplinary field scientific methods, processes, algorithms systems extract
knowledge insights data various forms, structured unstructured.
Document 2
Data mining process discovering patterns large data sets involving methods intersection
machine learning, statistics, database systems
Document 3
Information systems study complementary networks hardware software people organizations
collect, filter, process, create, distribute data
Porter Stemming algorithm
Results
Document 1
Data scienc interdisciplinari field scientif method process algorithm system extract knowledg
insight data variou form structur unstructur
Document 2
Data mine process discov pattern larg data set involv method intersect machin learn statist
databas system
Document 3
Informat system studi complementari network hardwar softwar peopl organ collect filter
process creat distribut data

Merged list
Meged sorted list Merged Sorted List with within document frequency
Term Document Term DocumentFrequency
algorithm 1 algorithm 1 1
collect 3 collect 3 1
complementari 3 complementari 3 1
creat 3 creat 3 1
Data 1 Data 1 2
data 1 Data 2 2
Data 2 data 3 1
data 2 databas 2 1
data 3 discov 2 1
databas 2 distribut 3 1
discov 2 extract 1 1
distribut 3 field 1 1
extract 1 filter 3 1
field 1 form 1 1
filter 3 hardwar 3 1
form 1 informat 3 1
hardwar 3 insigt 1 1
informat 3 interdisciplinari 1 1
insigt 1 intersect 2 1
interdisciplinari 1 involv 2 1
intersect 2 knowledg 1 1
involv 2 larg 2 1
knowledg 1 learn 2 1
larg 2 machin 2 1
learn 2 method 1 1
machin 2 method 2 1
method 1 mine 2 1
method 2 network 3 1
mine 2 organ 3 1
network 3 pattern 2 1
organ 3 peopl 3 1
pattern 2 process 1 1
peopl 3 process 2 1
process 1 process 3 1
process 2 Scienc 1 1
process 3 scientif 1 1
Scienc 1 set 2 1
scientif 1 softwar 3 1
set 2 statist 2 1
softwar 3 structur 1 1
statist 2 studi 3 1
structur 1 system 1 1
studi 3 system 2 1
system 1 system 3 1
system 2 unstrucur 1 1
system 3 variou 1 1
unstrucur 1
variou 1
Meged sorted list Merged Sorted List with within document frequency
Term Document Term DocumentFrequency
algorithm 1 algorithm 1 1
collect 3 collect 3 1
complementari 3 complementari 3 1
creat 3 creat 3 1
Data 1 Data 1 2
data 1 Data 2 2
Data 2 data 3 1
data 2 databas 2 1
data 3 discov 2 1
databas 2 distribut 3 1
discov 2 extract 1 1
distribut 3 field 1 1
extract 1 filter 3 1
field 1 form 1 1
filter 3 hardwar 3 1
form 1 informat 3 1
hardwar 3 insigt 1 1
informat 3 interdisciplinari 1 1
insigt 1 intersect 2 1
interdisciplinari 1 involv 2 1
intersect 2 knowledg 1 1
involv 2 larg 2 1
knowledg 1 learn 2 1
larg 2 machin 2 1
learn 2 method 1 1
machin 2 method 2 1
method 1 mine 2 1
method 2 network 3 1
mine 2 organ 3 1
network 3 pattern 2 1
organ 3 peopl 3 1
pattern 2 process 1 1
peopl 3 process 2 1
process 1 process 3 1
process 2 Scienc 1 1
process 3 scientif 1 1
Scienc 1 set 2 1
scientif 1 softwar 3 1
set 2 statist 2 1
softwar 3 structur 1 1
statist 2 studi 3 1
structur 1 system 1 1
studi 3 system 2 1
system 1 system 3 1
system 2 unstrucur 1 1
system 3 variou 1 1
unstrucur 1
variou 1
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

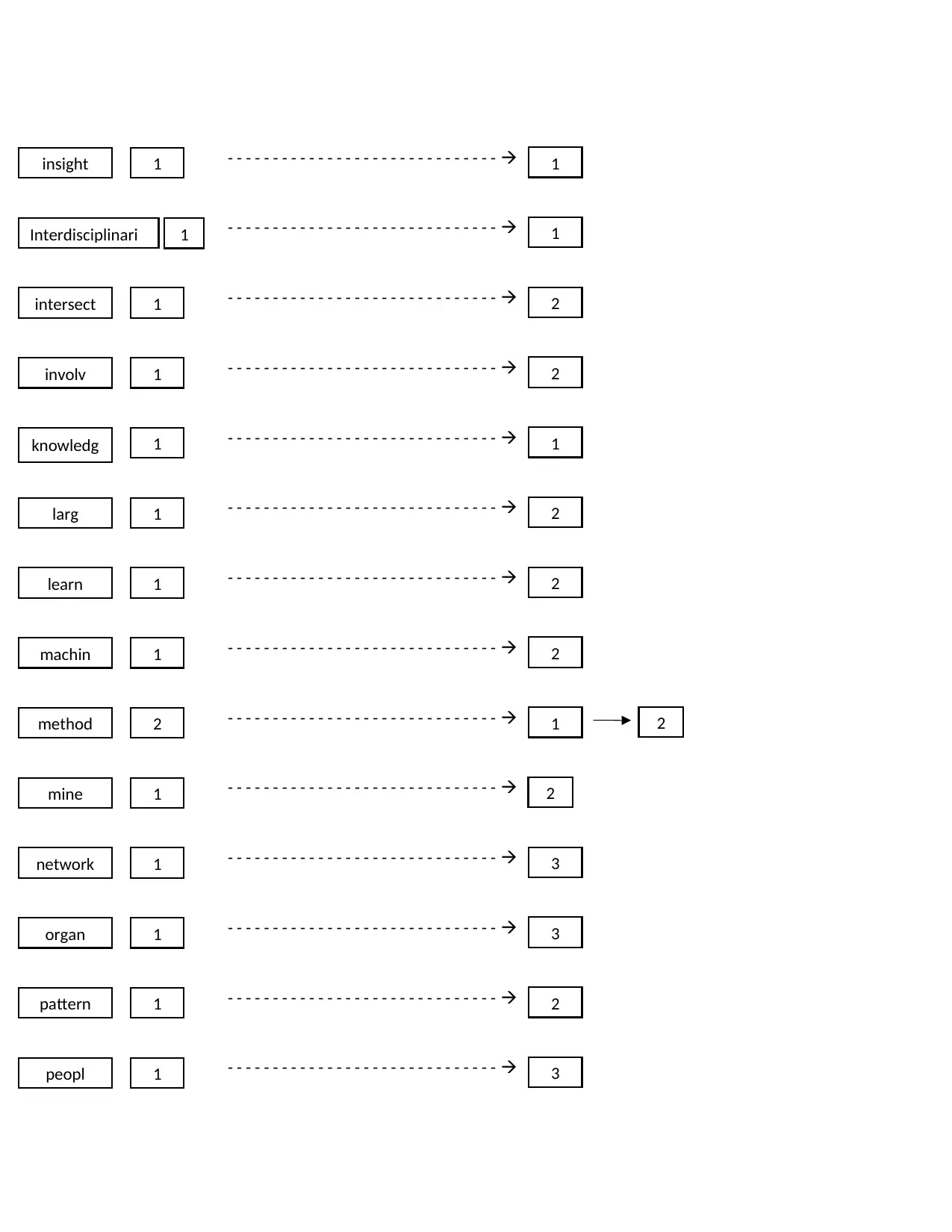
Posting file
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Algorithm 1
Colect 1 3
Complementari 1 3
creat 1 3
Data 5 1
Databas 1 2
Discov 1 2
distribut 1 3
extract 1 1
field 1 1
filter 1 3
form 1 1
hardwar 1 3
informat 1 3
Word Frequency
1
Posting
2 3
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Algorithm 1
Colect 1 3
Complementari 1 3
creat 1 3
Data 5 1
Databas 1 2
Discov 1 2
distribut 1 3
extract 1 1
field 1 1
filter 1 3
form 1 1
hardwar 1 3
informat 1 3
Word Frequency
1
Posting
2 3
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
insight 1 1
Interdisciplinari 1 1
intersect 1 2
involv 1 2
knowledg 1 1
larg 1 2
learn 1 2
machin 1 2
method 2 1
mine 1 2
network 1 3
organ 1 3
pattern 1 2
2
peopl 1 3
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
insight 1 1
Interdisciplinari 1 1
intersect 1 2
involv 1 2
knowledg 1 1
larg 1 2
learn 1 2
machin 1 2
method 2 1
mine 1 2
network 1 3
organ 1 3
pattern 1 2
2
peopl 1 3

- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Testing
Testing of the posting file can be done using a search engine like Google where by the key words should
be used to test whether the documents retrieved by the search engine relate to the documents from
which the posting file is derived from.
Boolean Model and vector Model
a. Boolean Model queries
1) method Ʌ process Ʌ System
This query returns all documents
2) Data Ʌ Method
process 3 1
scienc 1 1
scientif 1 1
set 1 2
2 3
Softwar 1 3
statist 1 2
structur 1 1
studi 1 3
system 3 1 2 3
unstructur 1 1
variou 1 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Testing
Testing of the posting file can be done using a search engine like Google where by the key words should
be used to test whether the documents retrieved by the search engine relate to the documents from
which the posting file is derived from.
Boolean Model and vector Model
a. Boolean Model queries
1) method Ʌ process Ʌ System
This query returns all documents
2) Data Ʌ Method
process 3 1
scienc 1 1
scientif 1 1
set 1 2
2 3
Softwar 1 3
statist 1 2
structur 1 1
studi 1 3
system 3 1 2 3
unstructur 1 1
variou 1 1
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

This query returns all documents
3) method V process V System
This query returns all documents
b. Vector Model queries
Query Q= (Data,method,system)
Document 1
D1= <3, 1, 0>
Q= <1, 1, 1>
σ ( D1 , Q) 3 x 1+1 x 1+ 0 x 1
√ 32+12 +02 √ 12+12 +12 = 4
√ 7 √ 3 = 1.15
Document 2
D2= <2, 0, 0>
Q = <1, 1, 1>
σ ( D2 , Q) 2 x 1+0 x 1+0 x 1
√22 +02+ 02 √12 +12+ 12 = 2
√4 √3 = 0.76
Document 3
D= <1, 1, 0>
Q= <1, 1, 1>
σ ( D3 , Q)= 1 x 1+ 1 x 1+ 0 x 1
√12 +12 +02 √12+12 +12 = 2
√2 √3 = 1.07
The documents are retrieved in the following order Doc1 , Doc 2 then Doc 3
3) method V process V System
This query returns all documents
b. Vector Model queries
Query Q= (Data,method,system)
Document 1
D1= <3, 1, 0>
Q= <1, 1, 1>
σ ( D1 , Q) 3 x 1+1 x 1+ 0 x 1
√ 32+12 +02 √ 12+12 +12 = 4
√ 7 √ 3 = 1.15
Document 2
D2= <2, 0, 0>
Q = <1, 1, 1>
σ ( D2 , Q) 2 x 1+0 x 1+0 x 1
√22 +02+ 02 √12 +12+ 12 = 2
√4 √3 = 0.76
Document 3
D= <1, 1, 0>
Q= <1, 1, 1>
σ ( D3 , Q)= 1 x 1+ 1 x 1+ 0 x 1
√12 +12 +02 √12+12 +12 = 2
√2 √3 = 1.07
The documents are retrieved in the following order Doc1 , Doc 2 then Doc 3

Question 2 IR evaluation
a. Target
Target 2: obtain the price of the new iPad.
Search queries
Query 1= new iPad price
Query 2= new iPad (price,cost)
Search Engines
o Google
o Yahoo
Google
a. Target
Target 2: obtain the price of the new iPad.
Search queries
Query 1= new iPad price
Query 2= new iPad (price,cost)
Search Engines
o Google
o Yahoo

Query 1 Query 2
Precision Recall Precison Recall
R 1 0.0714 R 1 0.071
R 1 0.143 R 1 0.143
1 0.214 0.667 0.143
R 1 0.286 0.5 0.143
R 1 0.357 R 0.6 0.214
R 0.833 0.429 0.5 0.214
0.714 0.429 0.429 0.214
0.625 0.429 0.375 0.214
R 0.667 0.5 0.444 0.286
0.6 0.5 0.4 0.286
0.636 0.571 R 0.455 0.358
R 0.667 0.643 0.417 0.358
0.692 0.714 R 0.462 0.429
0.643 0.714 0.4 0.429
0.6 0.714 R 0.4375 0.5
0.5625 0.714 R 0.412 0.5
0.529 0.714 0.389 0.5
0.556 0.786 0.368 0.5
R 0.526 0.786 0.4 0.571
R 0.55 0.857
Interpolation Interpolation
Precision precision Average Precision
0 1 0 1 0 1
0.1 1 0.1 1 0.1 1
0.2 1 0.2 0.6 0.2 0.8
0.3 1 0.3 0.455 0.3 0.7275
0.4 0.833 0.4 0.462 0.4 0.6475
0.5 0.667 0.5 0.4375 0.5 0.55225
0.6 0.667 0.6 0.412 0.6 0.5395
0.7 0.526 0.7 0 0.7 0.263
0.8 0.55 0.8 0 0.8 0.275
0.9 0 0.9 0 0.9 0
1 0 1 0 1 0
Precision Recall Precison Recall
R 1 0.0714 R 1 0.071
R 1 0.143 R 1 0.143
1 0.214 0.667 0.143
R 1 0.286 0.5 0.143
R 1 0.357 R 0.6 0.214
R 0.833 0.429 0.5 0.214
0.714 0.429 0.429 0.214
0.625 0.429 0.375 0.214
R 0.667 0.5 0.444 0.286
0.6 0.5 0.4 0.286
0.636 0.571 R 0.455 0.358
R 0.667 0.643 0.417 0.358
0.692 0.714 R 0.462 0.429
0.643 0.714 0.4 0.429
0.6 0.714 R 0.4375 0.5
0.5625 0.714 R 0.412 0.5
0.529 0.714 0.389 0.5
0.556 0.786 0.368 0.5
R 0.526 0.786 0.4 0.571
R 0.55 0.857
Interpolation Interpolation
Precision precision Average Precision
0 1 0 1 0 1
0.1 1 0.1 1 0.1 1
0.2 1 0.2 0.6 0.2 0.8
0.3 1 0.3 0.455 0.3 0.7275
0.4 0.833 0.4 0.462 0.4 0.6475
0.5 0.667 0.5 0.4375 0.5 0.55225
0.6 0.667 0.6 0.412 0.6 0.5395
0.7 0.526 0.7 0 0.7 0.263
0.8 0.55 0.8 0 0.8 0.275
0.9 0 0.9 0 0.9 0
1 0 1 0 1 0
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Figure 1: Google Search Engine
b. Yahoo
Query 1 Query 2
Precision Recall Precison Recall
R 1 0.0714 R 1 0.071
R 1 0.143 R 1 0.143
1 0.214 0.667 0.143
R 1 0.286 0.75 0.214
R 1 0.357 R 0.8 0.289
R 0.833 0.429 0.667 0.289
0.714 0.429 0.571 0.289
0.625 0.429 R 0.625 0.357
R 0.667 0.5 R 0.667 0.429
0.6 0.5 0.6 0.429
0.636 0.571 0.636 0.5
R 0.667 0.643 R 0.667 0.571
0.692 0.714 R 0.615 0.571
0.643 0.714 0.571 0.571
0.6 0.714 R 0.6 0.643
0.5625 0.714 0.5625 0.643
0.529 0.714 0.529 0.643
0.556 0.786 0.556 0.714
R 0.526 0.786 0.526 0.714
R 0.55 0.857 R 0.55 0.786
Interpolation Interpolation
Precision precision Average Precision
0 1 0 1 0 1
0.1 1 0.1 1 0.1 1
0.2 1 0.2 0.8 0.2 0.9
0.3 1 0.3 0.625 0.3 0.8125
0.4 0.833 0.4 0.667 0.4 0.75
0.5 0.667 0.5 0.667 0.5 0.667
0.6 0.667 0.6 0.615 0.6 0.641
0.7 0.526 0.7 0.6 0.7 0.563
0.8 0.55 0.8 0.55 0.8 0.55
0.9 0 0.9 0 0.9 0
1 0 1 0 1 0
b. Yahoo
Query 1 Query 2
Precision Recall Precison Recall
R 1 0.0714 R 1 0.071
R 1 0.143 R 1 0.143
1 0.214 0.667 0.143
R 1 0.286 0.75 0.214
R 1 0.357 R 0.8 0.289
R 0.833 0.429 0.667 0.289
0.714 0.429 0.571 0.289
0.625 0.429 R 0.625 0.357
R 0.667 0.5 R 0.667 0.429
0.6 0.5 0.6 0.429
0.636 0.571 0.636 0.5
R 0.667 0.643 R 0.667 0.571
0.692 0.714 R 0.615 0.571
0.643 0.714 0.571 0.571
0.6 0.714 R 0.6 0.643
0.5625 0.714 0.5625 0.643
0.529 0.714 0.529 0.643
0.556 0.786 0.556 0.714
R 0.526 0.786 0.526 0.714
R 0.55 0.857 R 0.55 0.786
Interpolation Interpolation
Precision precision Average Precision
0 1 0 1 0 1
0.1 1 0.1 1 0.1 1
0.2 1 0.2 0.8 0.2 0.9
0.3 1 0.3 0.625 0.3 0.8125
0.4 0.833 0.4 0.667 0.4 0.75
0.5 0.667 0.5 0.667 0.5 0.667
0.6 0.667 0.6 0.615 0.6 0.641
0.7 0.526 0.7 0.6 0.7 0.563
0.8 0.55 0.8 0.55 0.8 0.55
0.9 0 0.9 0 0.9 0
1 0 1 0 1 0

Figure 2: Yahoo search engine
c. Google and Yahoo search engines average
Figure 3: Comparison by average
Evaluation
Google is more powerful than Yahoo for the designed search queries because it is more precise meaning
it retrieves more number of correct results over the relevant results than yahoo than it has a higher
precision and it has a higher recall value than Yahoo because the number of relevant documents over
the total documents retrieved is higher for Google compared to Yahoo.
Bibliography
Google Developers. (2018). Classification: Precision and Recall | Machine Learning Crash
Course | Google Developers. [online] Available at: https://developers.google.com/machine-
learning/crash-course/classification/precision-and-recall [Accessed 26 Jan. 2019].
c. Google and Yahoo search engines average
Figure 3: Comparison by average
Evaluation
Google is more powerful than Yahoo for the designed search queries because it is more precise meaning
it retrieves more number of correct results over the relevant results than yahoo than it has a higher
precision and it has a higher recall value than Yahoo because the number of relevant documents over
the total documents retrieved is higher for Google compared to Yahoo.
Bibliography
Google Developers. (2018). Classification: Precision and Recall | Machine Learning Crash
Course | Google Developers. [online] Available at: https://developers.google.com/machine-
learning/crash-course/classification/precision-and-recall [Accessed 26 Jan. 2019].
1 out of 12
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.