SIT772: Database and Information Retrieval Search Algorithm Report
VerifiedAdded on 2023/06/04
|12
|1428
|444
Report
AI Summary
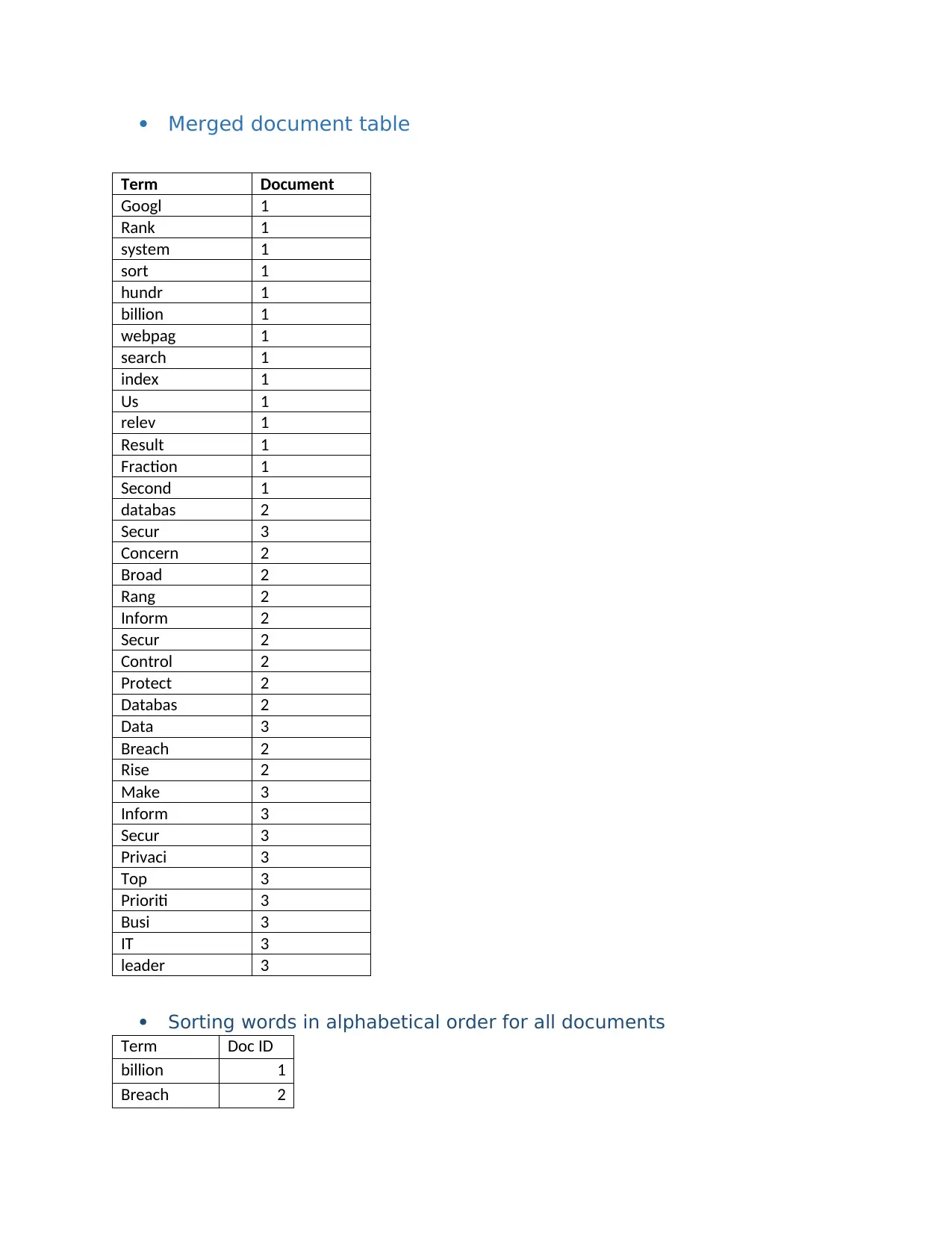
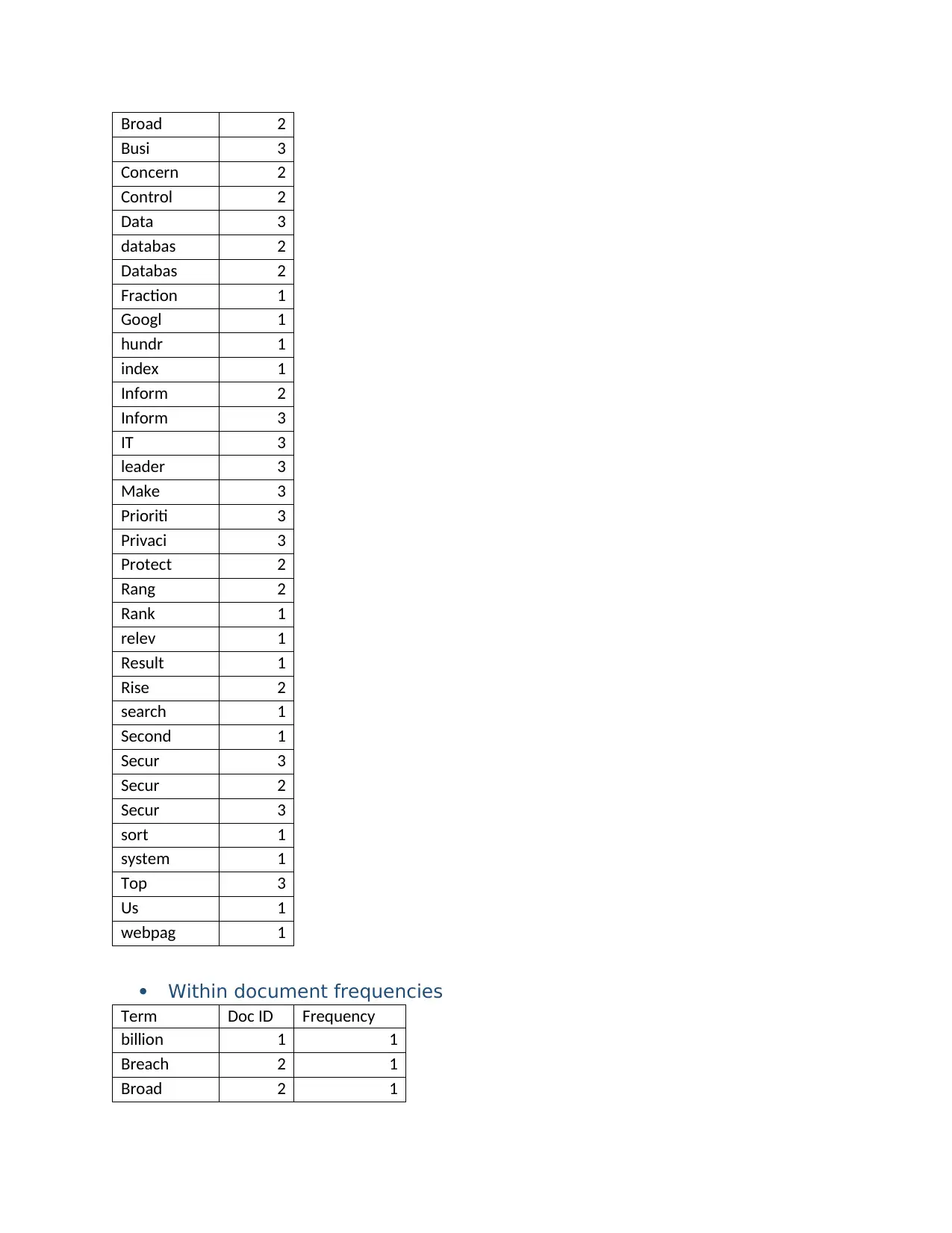
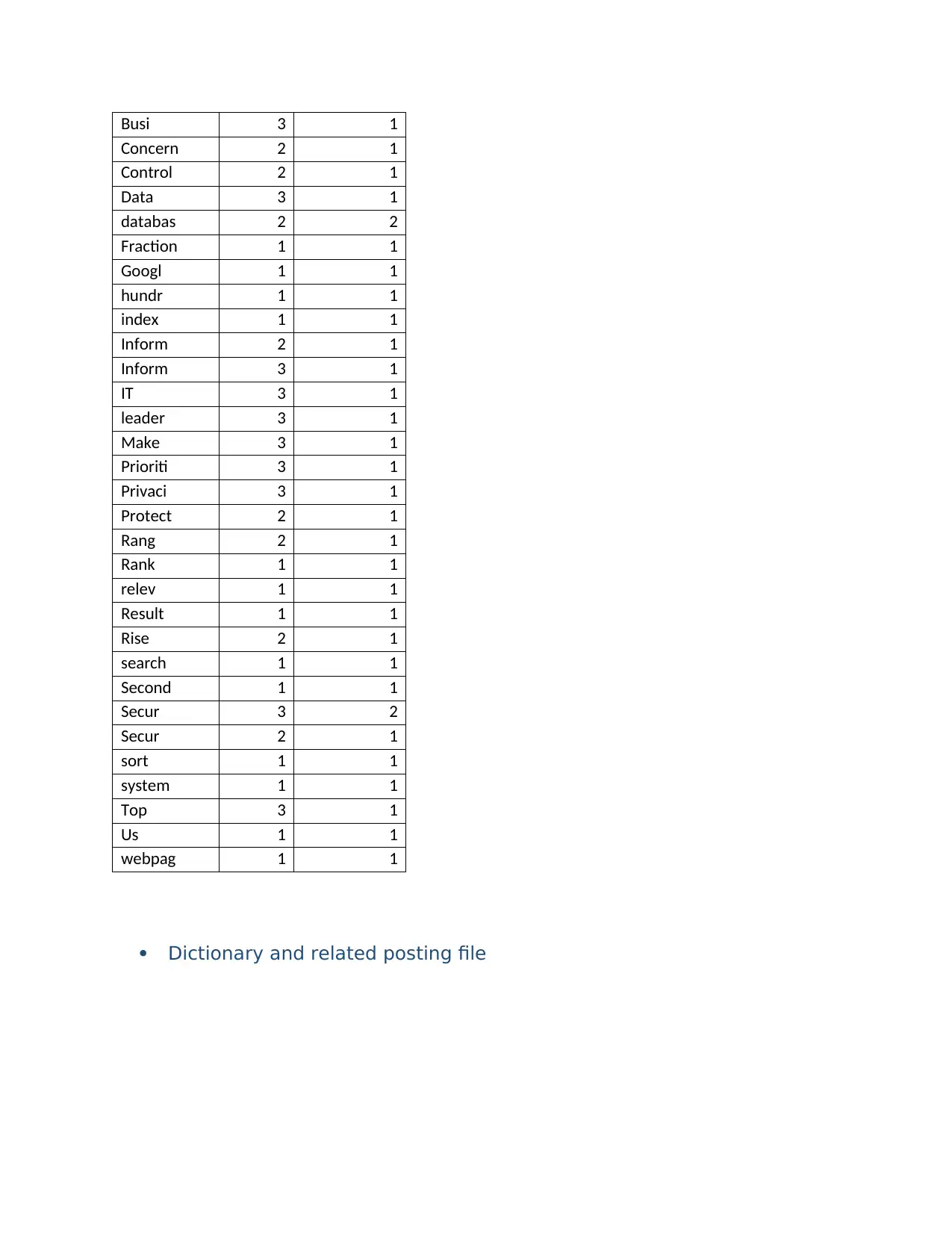
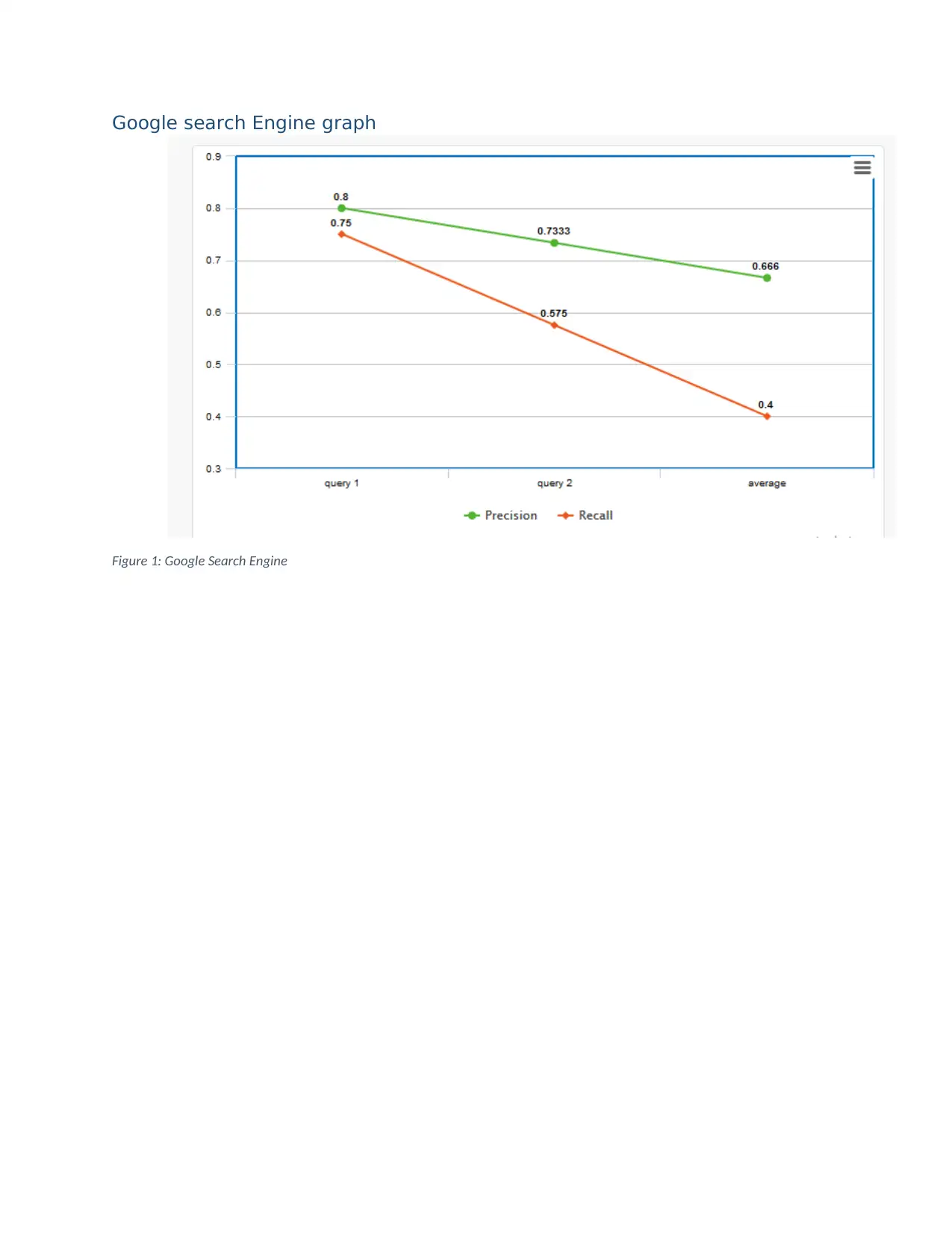
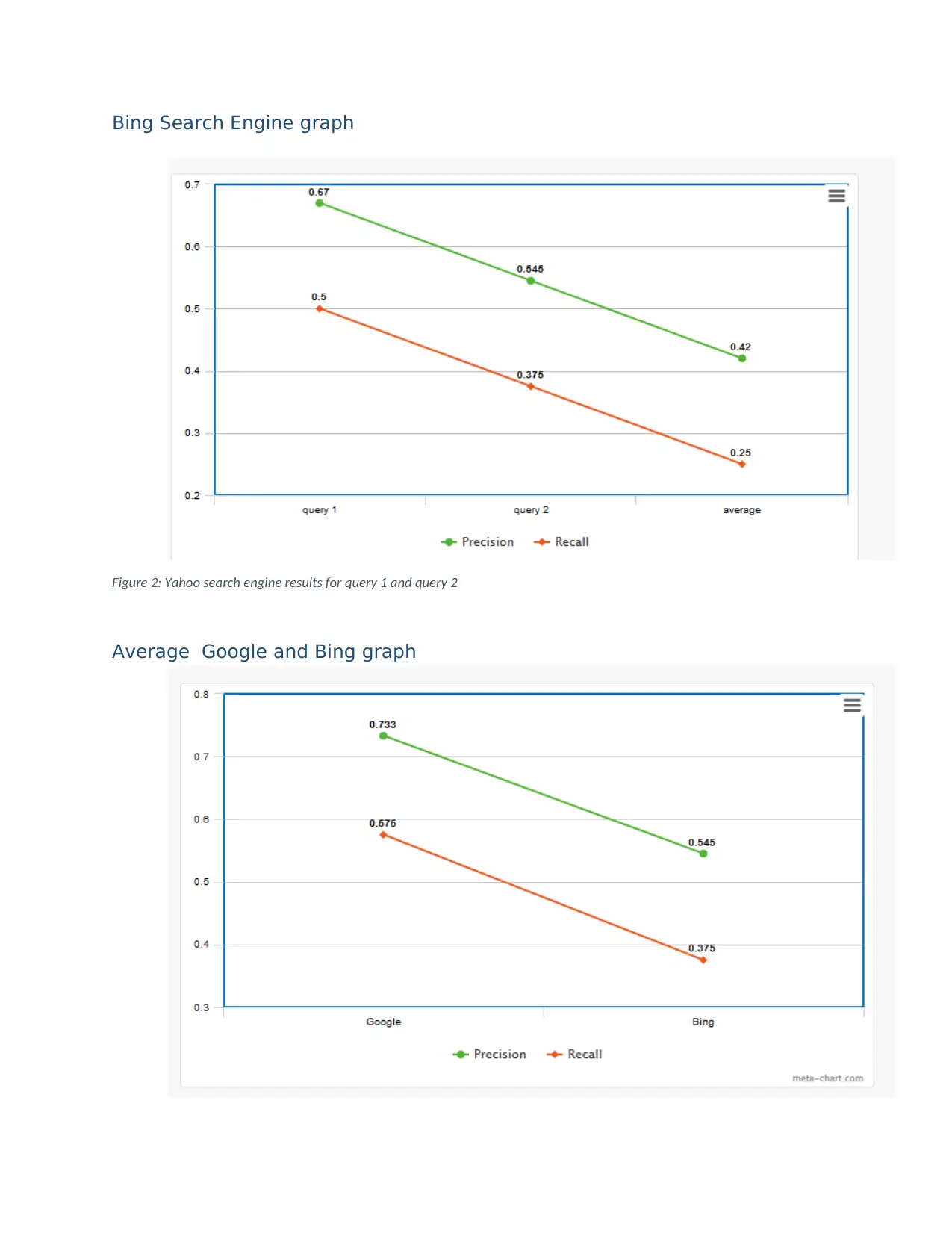
This report presents a comprehensive solution to a SIT772 assignment on database and information retrieval, focusing on the design and evaluation of search algorithms. The assignment begins with the creation of an inverted index, detailing the steps of removing stop words, applying the Porter stemming algorithm, and merging document tables. It includes sorting words alphabetically, calculating within-document frequencies, constructing a dictionary and posting file, and testing the index. The report then explores Boolean and vector queries, providing examples and calculations for cosine similarity. Furthermore, the assignment evaluates information retrieval (IR) using Google and Bing search engines. The evaluation includes target identification, query design, and graphical comparisons of recall and precision to determine the superior search engine. The report concludes with references to support the analysis.







1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.