BABS Foundation Level: Numeracy and Data Analysis Assignment - 2021
VerifiedAdded on 2022/12/28
|12
|1585
|77
Homework Assignment
AI Summary
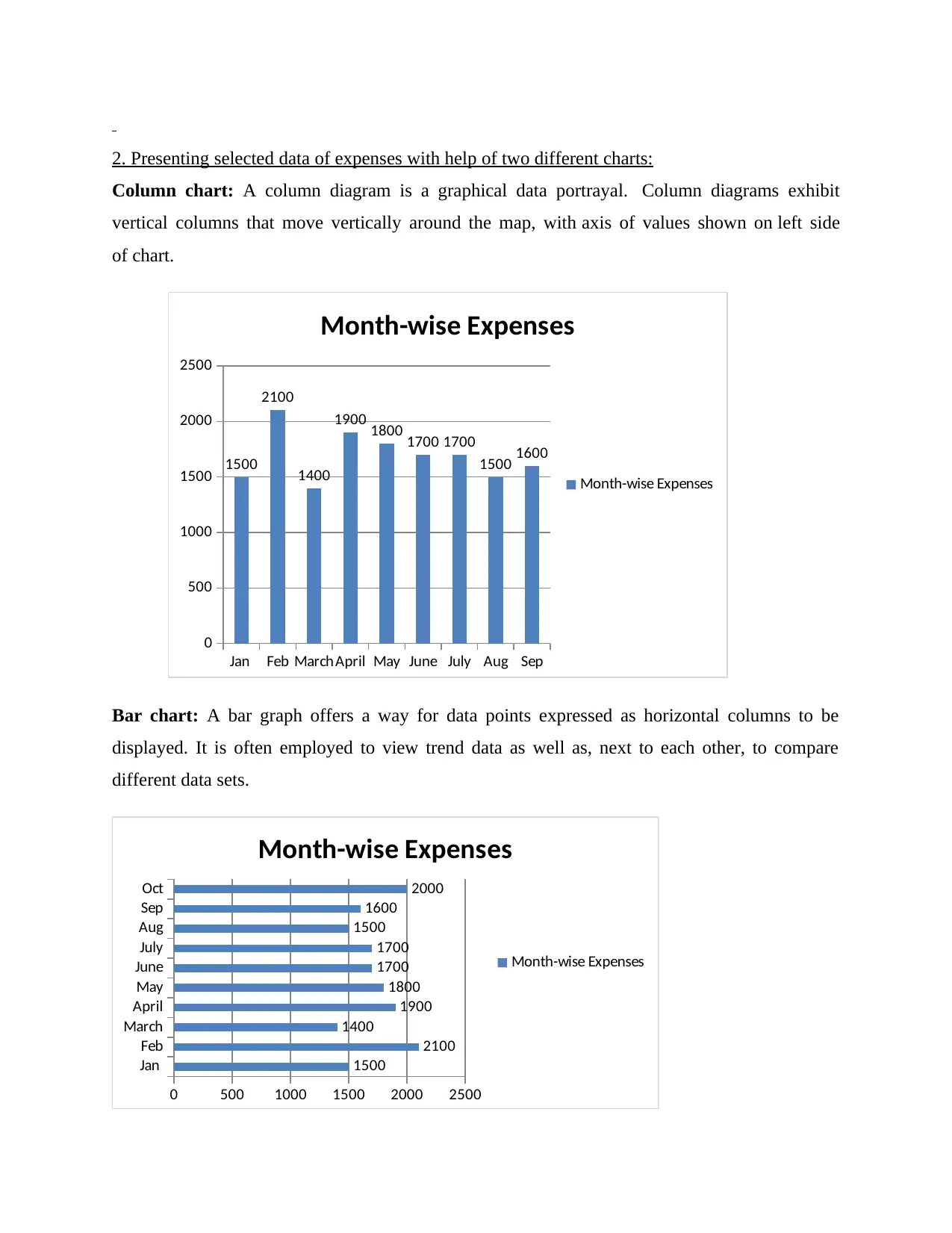
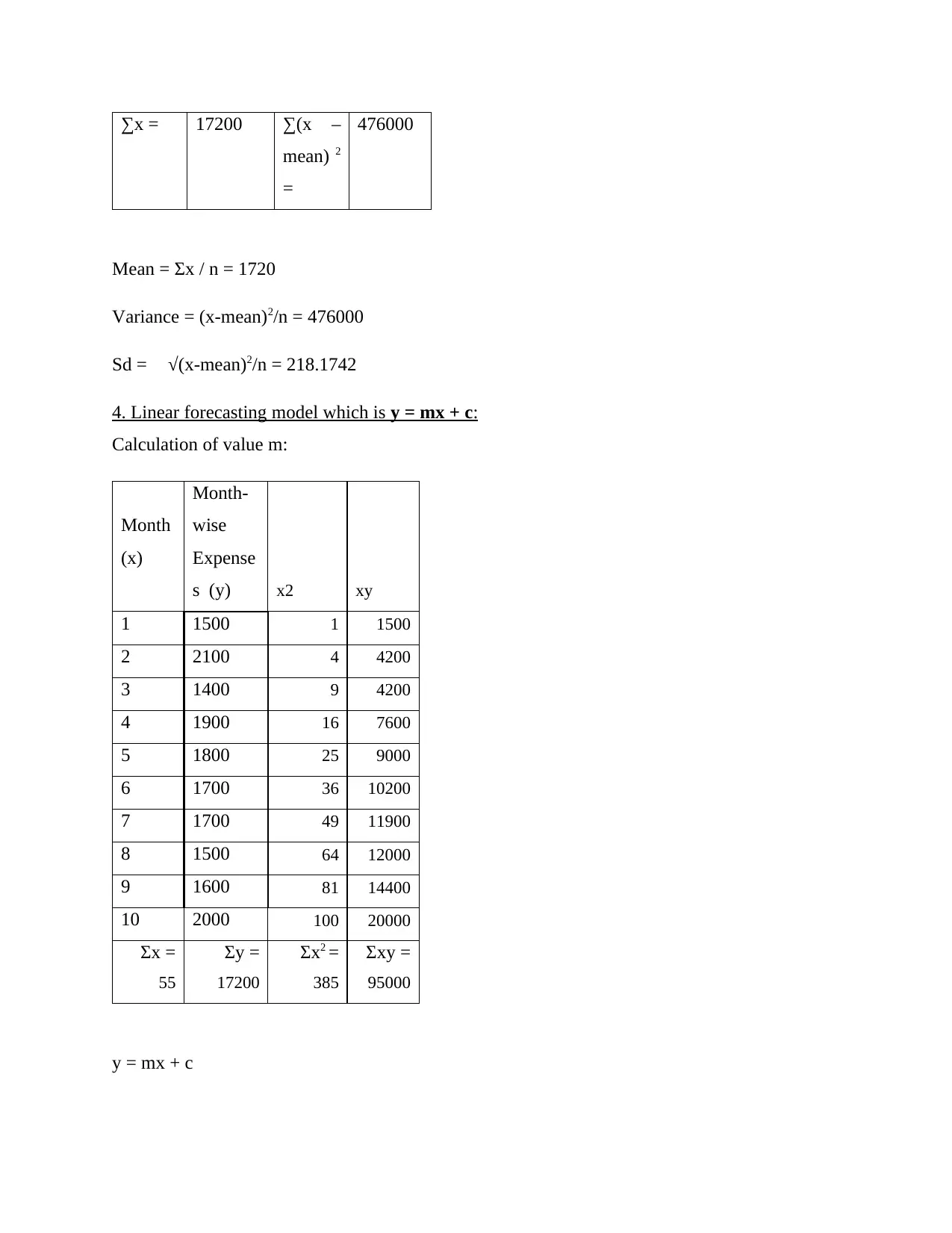
This assignment, completed for the Numeracy and Data Analysis module at the London School of Commerce in association with the University of Suffolk, presents a detailed analysis of expenditure data over ten months. The student begins by organizing the data in a tabular format and visualizing it using column and bar charts. The core of the assignment involves calculating and discussing key statistical measures, including the mean, mode, median, range, and standard deviation, providing insights into the data's central tendencies and variability. Furthermore, the student applies a linear forecasting model to predict expenditures for the eleventh and twelfth months, demonstrating the ability to apply forecasting techniques to real-life scenarios. The assignment concludes with a summary of the findings and references to the sources used. This assignment showcases applications of summarising and analysing data, logical reasoning, and ability to understand and apply forecasting techniques to real life situations.










1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.