Data Analysis and Forecasting
VerifiedAdded on 2022/12/28
|12
|1090
|26
AI Summary
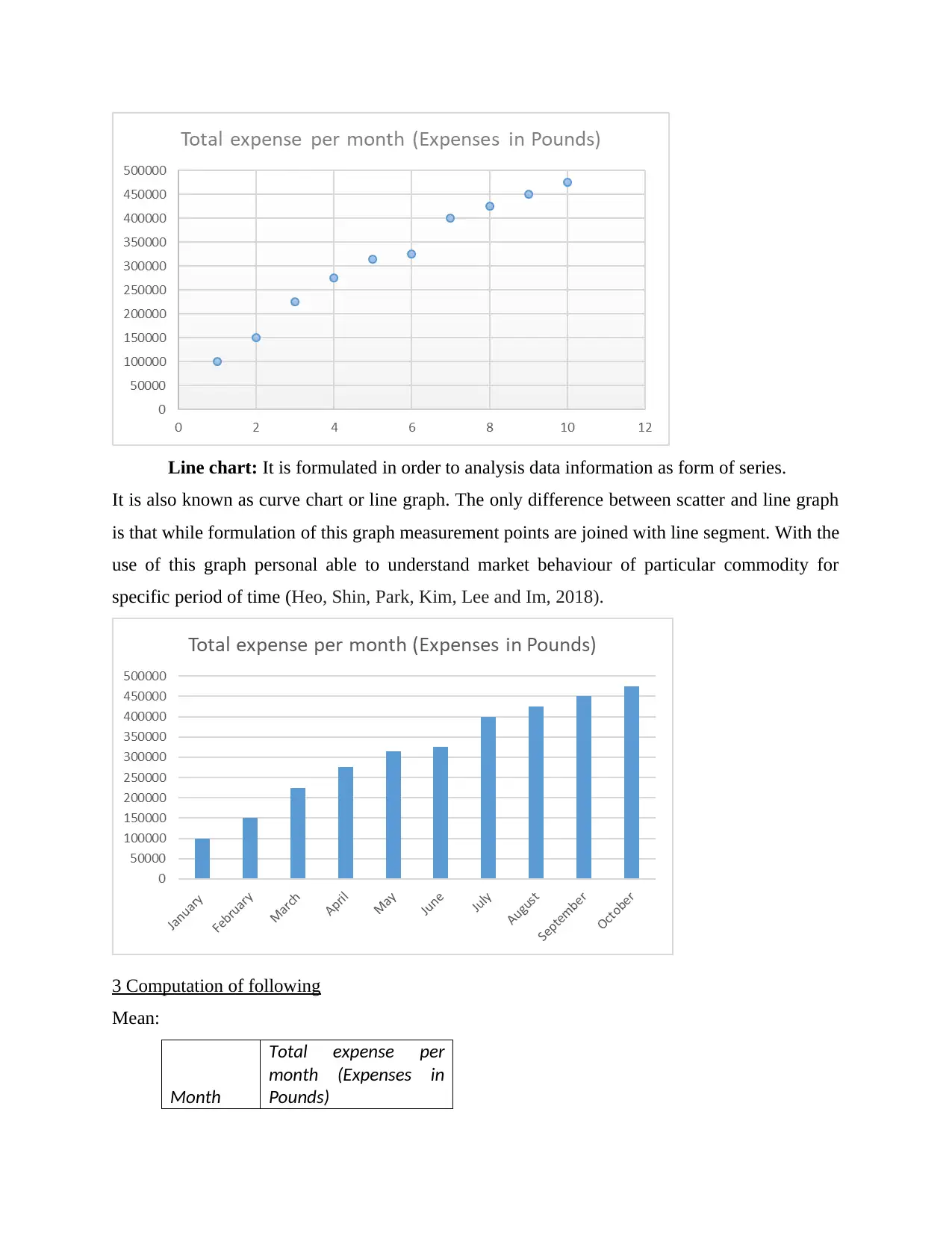
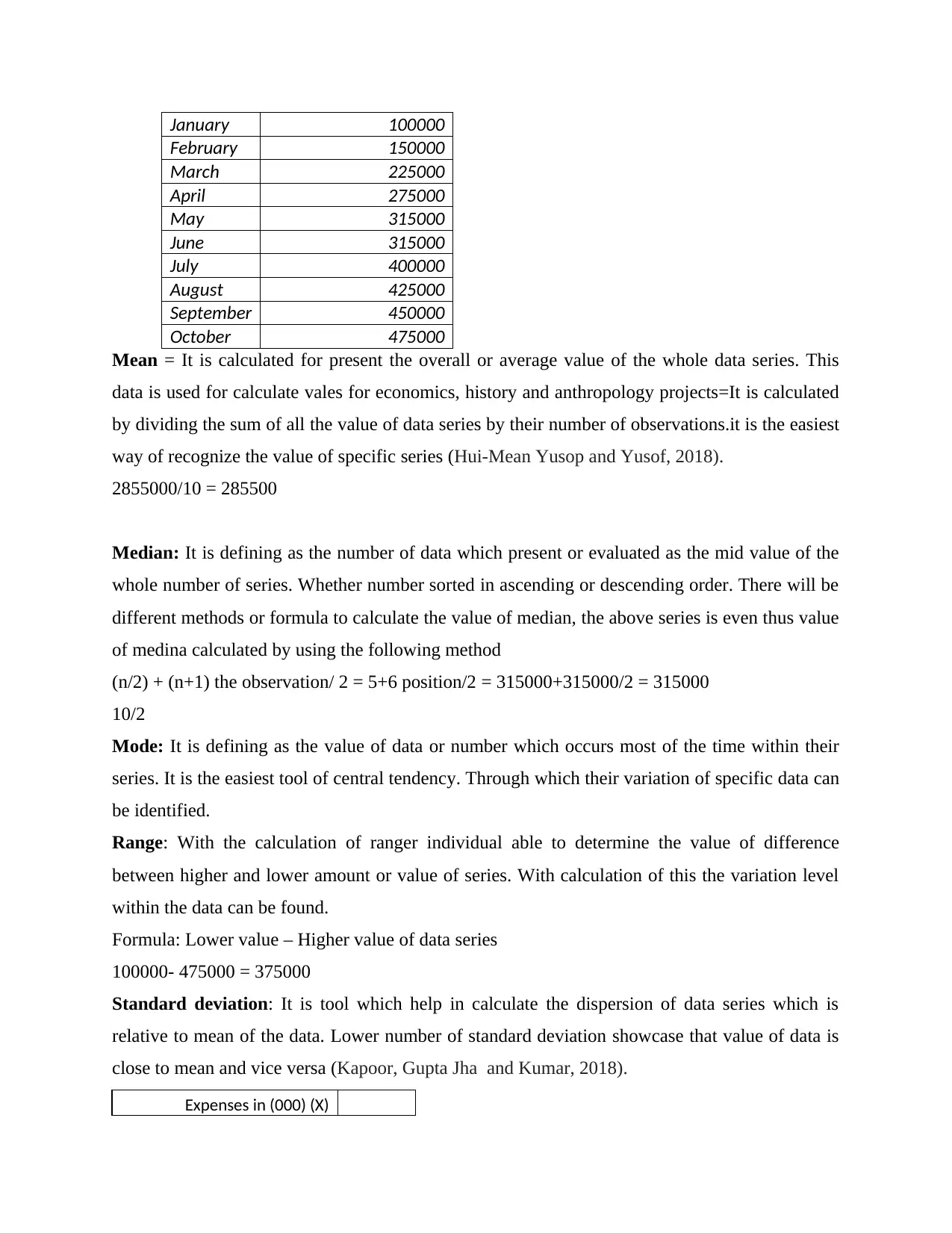
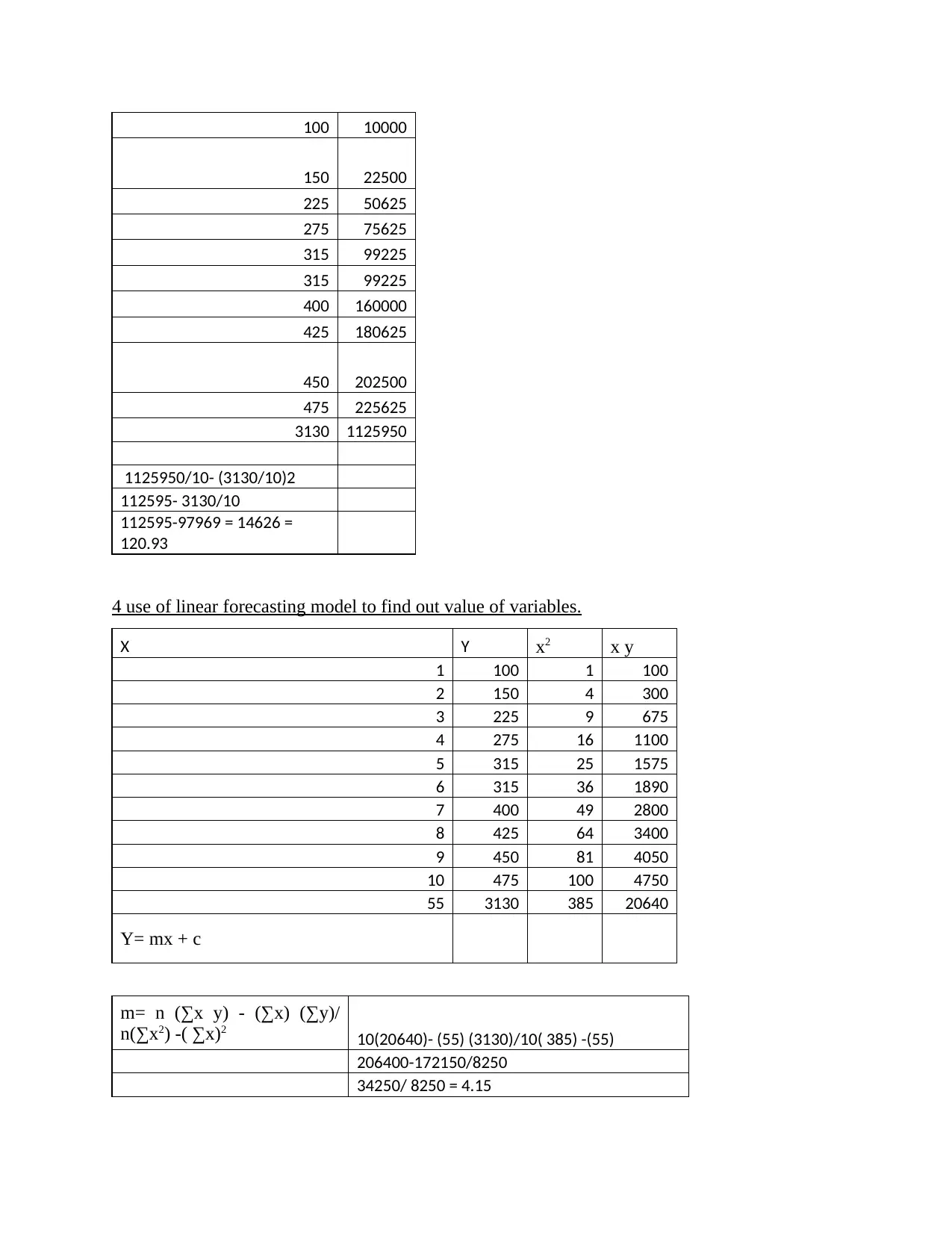
This report discusses the use of tools of central tendency in data analysis and forecasting. It covers the formulation of tables and graphs, computation of mean, median, mode, range, and standard deviation, and the use of linear forecasting models. The relevance of these tools in decision making is also explored. Study material and solved assignments on data analysis and forecasting are available at Desklib.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.









1 out of 12
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
© 2024 | Zucol Services PVT LTD | All rights reserved.