Numeracy and Data Analysis: Forecasting and Statistical Analysis
VerifiedAdded on 2023/01/11
|8
|1349
|23
Homework Assignment
AI Summary
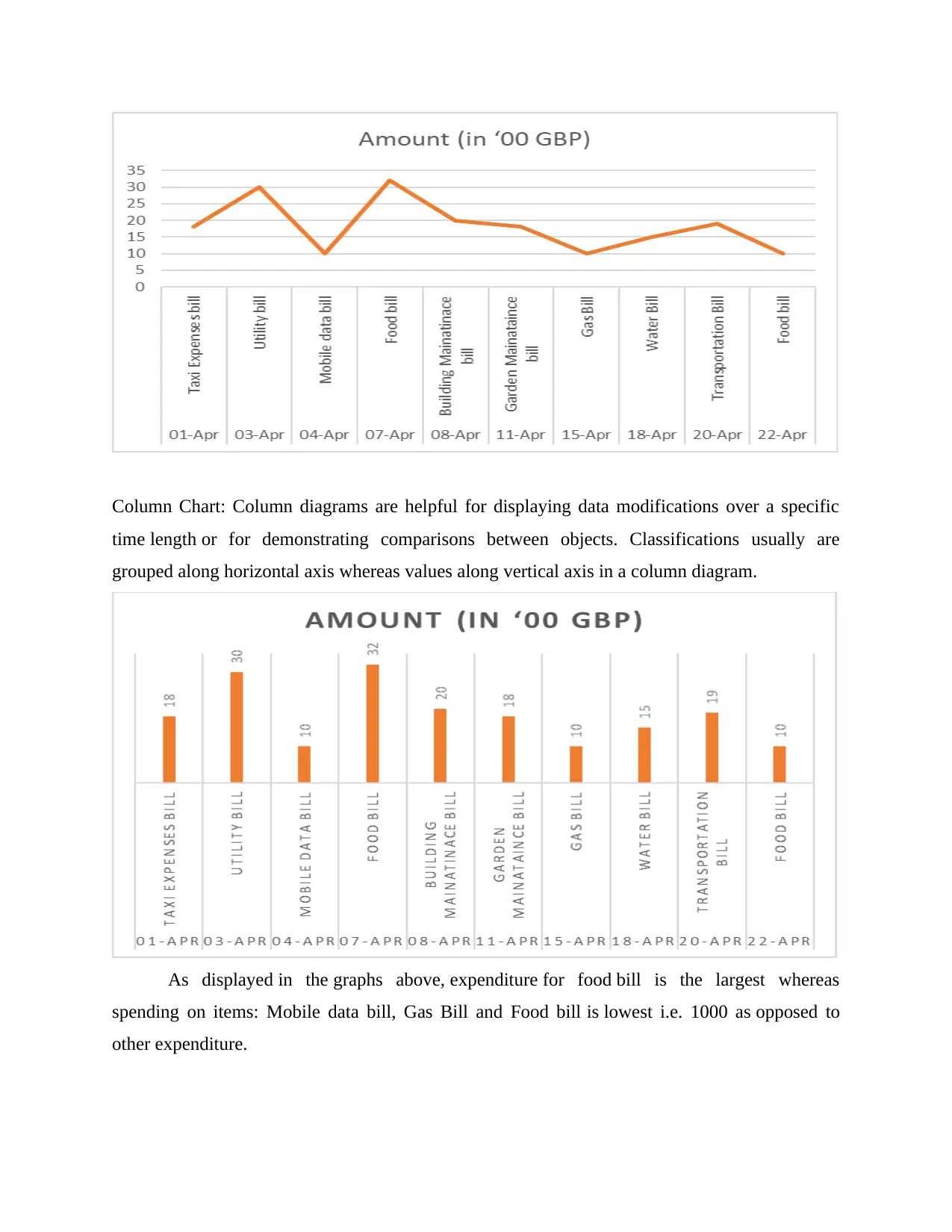
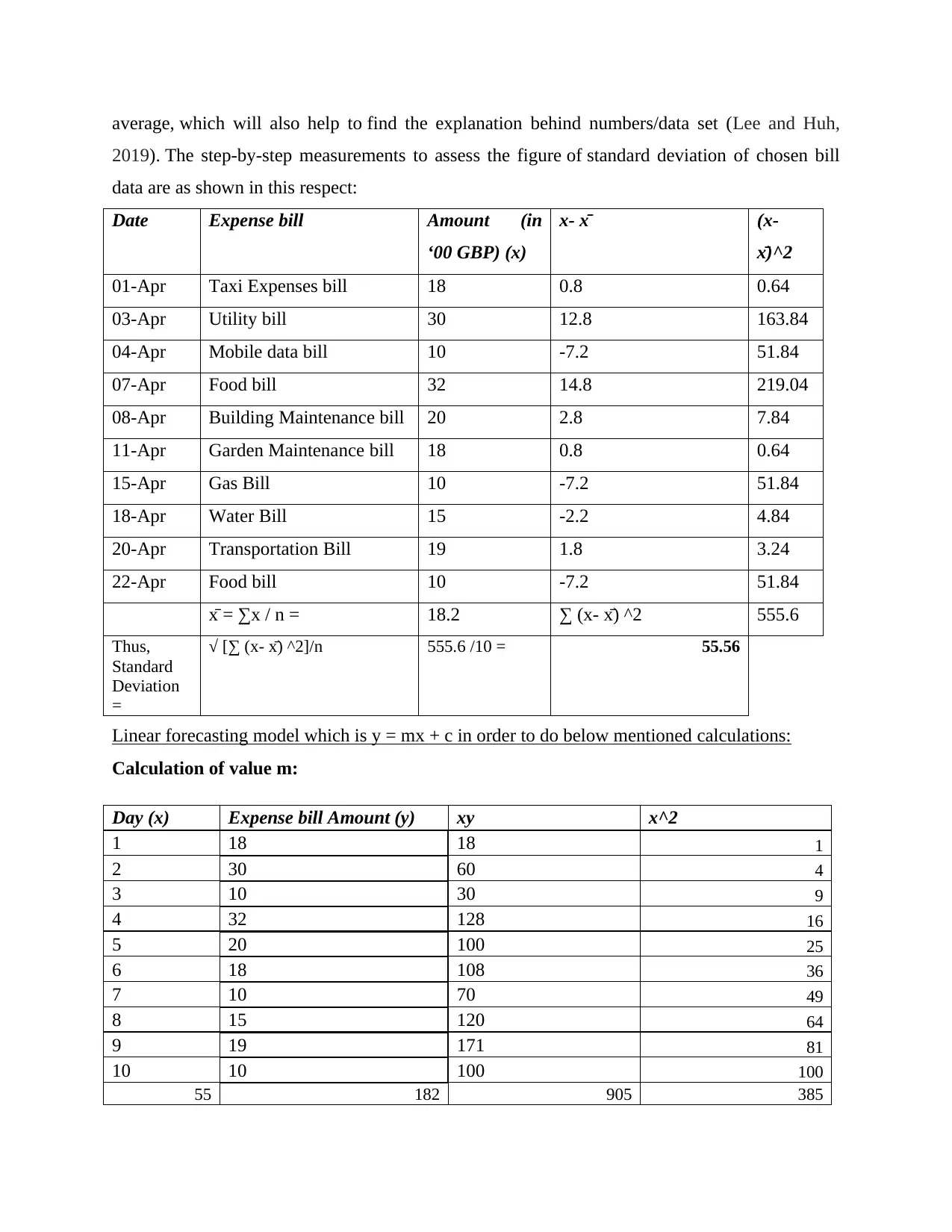
This assignment focuses on data analysis and forecasting techniques using a sample dataset of bill payments. The student begins by arranging the data in a table format and then presents the data using line and column charts. The assignment then calculates and discusses various statistical measures including mean, median, mode, range, and standard deviation. Furthermore, a linear forecasting model (y = mx + c) is employed to predict expenses for future days. The calculations for 'm' and 'c' are shown, and the model is applied to forecast expenses for day 12 and day 14. The conclusion emphasizes the importance of data analysis and prediction in understanding the chosen dataset. The references include books and journals related to statistical and econometric methods for data analysis and forecasting.






1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.