Data Analysis Techniques for Humidity Forecasting - CCCU, Jan 2022
VerifiedAdded on 2023/06/15
|9
|1387
|423
Homework Assignment
AI Summary
This assignment solution focuses on data analysis techniques applied to humidity data in London over ten consecutive days. The data is presented in a table and visualized using bar and line charts. The solution includes calculations and discussion of averages such as mean, median, mode, range, and standard deviation. A linear forecasting model (y = mx + c) is then used to forecast humidity on the 11th and 13th days, providing a practical application of the data analysis. The assignment concludes with references to relevant research and methodologies used in the analysis.

DATA ANALYSIS
TECHNIQUES
TECHNIQUES
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

TABLE OF CONTENTS
1. Humidity data of London for ten consecutive days and arranging in a table format..............3
2. Presentation of data using charts.............................................................................................3
3. Calculation and discussion of averages...................................................................................4
4. Using Linear forecasting model y = mx + c to forecast humidity on 11th day and 13th day6
REFERENCES................................................................................................................................8
1. Humidity data of London for ten consecutive days and arranging in a table format..............3
2. Presentation of data using charts.............................................................................................3
3. Calculation and discussion of averages...................................................................................4
4. Using Linear forecasting model y = mx + c to forecast humidity on 11th day and 13th day6
REFERENCES................................................................................................................................8
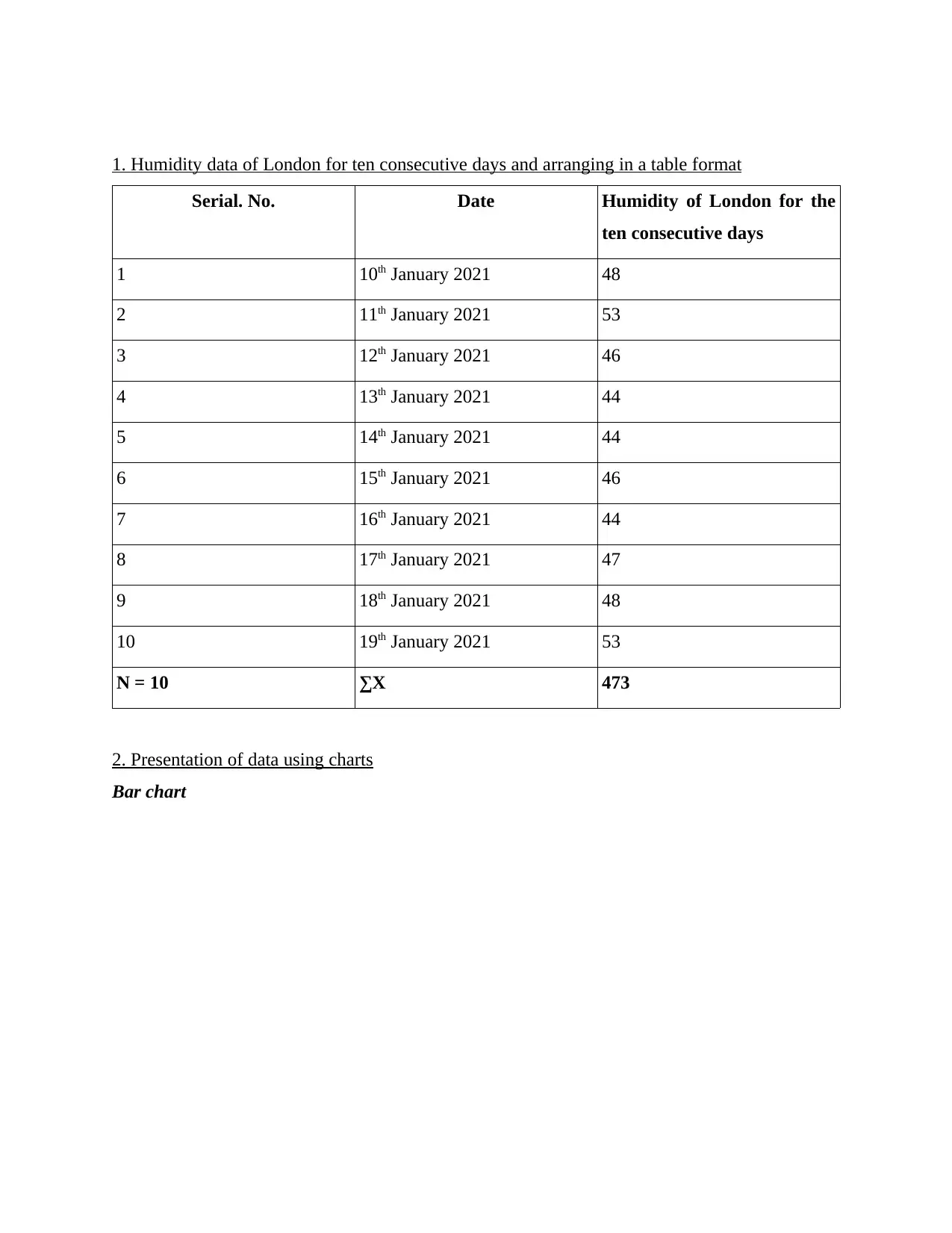
1. Humidity data of London for ten consecutive days and arranging in a table format
Serial. No. Date Humidity of London for the
ten consecutive days
1 10th January 2021 48
2 11th January 2021 53
3 12th January 2021 46
4 13th January 2021 44
5 14th January 2021 44
6 15th January 2021 46
7 16th January 2021 44
8 17th January 2021 47
9 18th January 2021 48
10 19th January 2021 53
N = 10 ∑X 473
2. Presentation of data using charts
Bar chart
Serial. No. Date Humidity of London for the
ten consecutive days
1 10th January 2021 48
2 11th January 2021 53
3 12th January 2021 46
4 13th January 2021 44
5 14th January 2021 44
6 15th January 2021 46
7 16th January 2021 44
8 17th January 2021 47
9 18th January 2021 48
10 19th January 2021 53
N = 10 ∑X 473
2. Presentation of data using charts
Bar chart
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
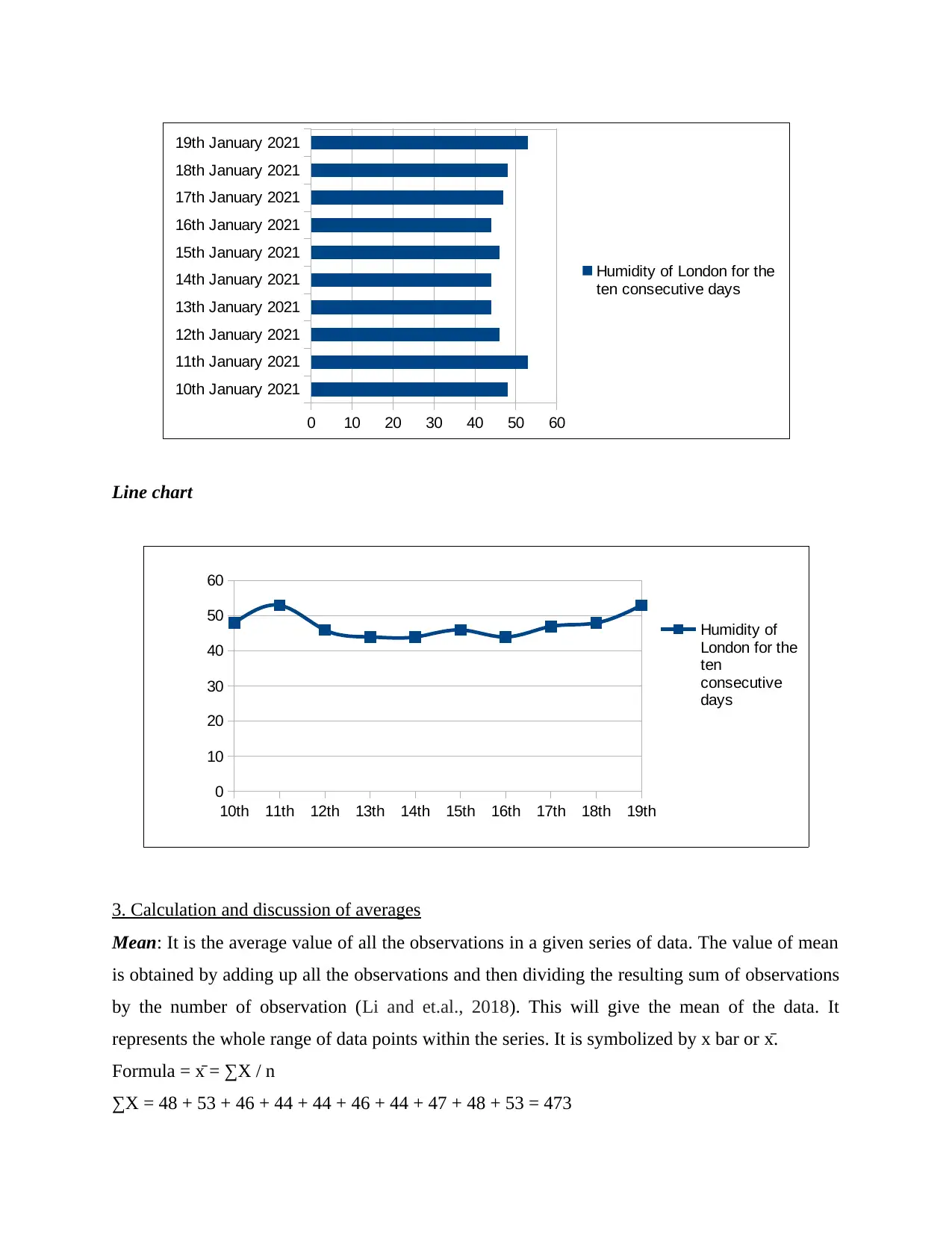
Line chart
3. Calculation and discussion of averages
Mean: It is the average value of all the observations in a given series of data. The value of mean
is obtained by adding up all the observations and then dividing the resulting sum of observations
by the number of observation (Li and et.al., 2018). This will give the mean of the data. It
represents the whole range of data points within the series. It is symbolized by x bar or x̄.
Formula = x̄ = ∑X / n
∑X = 48 + 53 + 46 + 44 + 44 + 46 + 44 + 47 + 48 + 53 = 473
10th January 2021
11th January 2021
12th January 2021
13th January 2021
14th January 2021
15th January 2021
16th January 2021
17th January 2021
18th January 2021
19th January 2021
0 10 20 30 40 50 60
Humidity of London for the
ten consecutive days
10th 11th 12th 13th 14th 15th 16th 17th 18th 19th
0
10
20
30
40
50
60
Humidity of
London for the
ten
consecutive
days
3. Calculation and discussion of averages
Mean: It is the average value of all the observations in a given series of data. The value of mean
is obtained by adding up all the observations and then dividing the resulting sum of observations
by the number of observation (Li and et.al., 2018). This will give the mean of the data. It
represents the whole range of data points within the series. It is symbolized by x bar or x̄.
Formula = x̄ = ∑X / n
∑X = 48 + 53 + 46 + 44 + 44 + 46 + 44 + 47 + 48 + 53 = 473
10th January 2021
11th January 2021
12th January 2021
13th January 2021
14th January 2021
15th January 2021
16th January 2021
17th January 2021
18th January 2021
19th January 2021
0 10 20 30 40 50 60
Humidity of London for the
ten consecutive days
10th 11th 12th 13th 14th 15th 16th 17th 18th 19th
0
10
20
30
40
50
60
Humidity of
London for the
ten
consecutive
days
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

n = 10
x̄ = 473 / 10 = 47.3
Median: It is middle value of the series which is obtained by arranging all the data points in
either ascending or descending order. From the median, 50% of the data points are above and
50% of the data points are below it (Yang and et.al., 2018). When the number of observations in
the series are even, then the value of median is obtained by adding up two numbers in the
middle and dividing the sum of it by 2. The median for the humidity data is calculated as
follows:
Serial No. Humidity data in ascending order
1 44
2 44
3 44
4 46
5 46
6 47
7 48
8 48
9 53
10 53
Two numbers in the middle of the data set consisting of even number of items are 46 and 47.
Adding both these number and dividing it by two will gives us the median of the data, where,
46 + 47 = 93 / 2 = 46.5 is the median of the data set.
Mode: The modal value is one which appears most of the time in data series. In other words, the
value which is repeatedly occurring within the given data set or whose frequency is highest (Kim
and Wang, 2019). In the data series related to the humidity of London city, the mode identified
is 44 as its frequency is highest among other observations.
x̄ = 473 / 10 = 47.3
Median: It is middle value of the series which is obtained by arranging all the data points in
either ascending or descending order. From the median, 50% of the data points are above and
50% of the data points are below it (Yang and et.al., 2018). When the number of observations in
the series are even, then the value of median is obtained by adding up two numbers in the
middle and dividing the sum of it by 2. The median for the humidity data is calculated as
follows:
Serial No. Humidity data in ascending order
1 44
2 44
3 44
4 46
5 46
6 47
7 48
8 48
9 53
10 53
Two numbers in the middle of the data set consisting of even number of items are 46 and 47.
Adding both these number and dividing it by two will gives us the median of the data, where,
46 + 47 = 93 / 2 = 46.5 is the median of the data set.
Mode: The modal value is one which appears most of the time in data series. In other words, the
value which is repeatedly occurring within the given data set or whose frequency is highest (Kim
and Wang, 2019). In the data series related to the humidity of London city, the mode identified
is 44 as its frequency is highest among other observations.
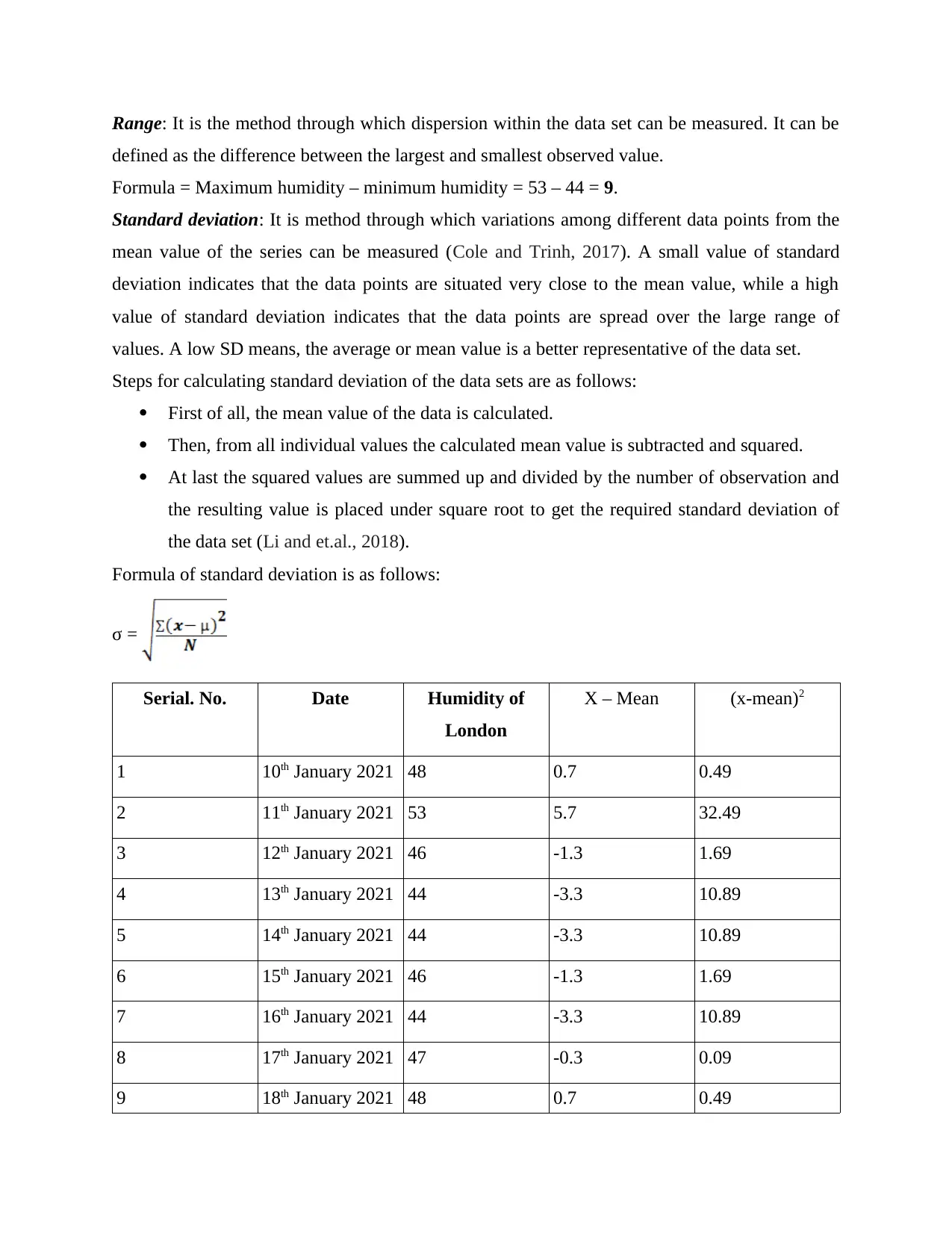
Range: It is the method through which dispersion within the data set can be measured. It can be
defined as the difference between the largest and smallest observed value.
Formula = Maximum humidity – minimum humidity = 53 – 44 = 9.
Standard deviation: It is method through which variations among different data points from the
mean value of the series can be measured (Cole and Trinh, 2017). A small value of standard
deviation indicates that the data points are situated very close to the mean value, while a high
value of standard deviation indicates that the data points are spread over the large range of
values. A low SD means, the average or mean value is a better representative of the data set.
Steps for calculating standard deviation of the data sets are as follows:
First of all, the mean value of the data is calculated.
Then, from all individual values the calculated mean value is subtracted and squared.
At last the squared values are summed up and divided by the number of observation and
the resulting value is placed under square root to get the required standard deviation of
the data set (Li and et.al., 2018).
Formula of standard deviation is as follows:
σ =
Serial. No. Date Humidity of
London
X – Mean (x-mean)2
1 10th January 2021 48 0.7 0.49
2 11th January 2021 53 5.7 32.49
3 12th January 2021 46 -1.3 1.69
4 13th January 2021 44 -3.3 10.89
5 14th January 2021 44 -3.3 10.89
6 15th January 2021 46 -1.3 1.69
7 16th January 2021 44 -3.3 10.89
8 17th January 2021 47 -0.3 0.09
9 18th January 2021 48 0.7 0.49
defined as the difference between the largest and smallest observed value.
Formula = Maximum humidity – minimum humidity = 53 – 44 = 9.
Standard deviation: It is method through which variations among different data points from the
mean value of the series can be measured (Cole and Trinh, 2017). A small value of standard
deviation indicates that the data points are situated very close to the mean value, while a high
value of standard deviation indicates that the data points are spread over the large range of
values. A low SD means, the average or mean value is a better representative of the data set.
Steps for calculating standard deviation of the data sets are as follows:
First of all, the mean value of the data is calculated.
Then, from all individual values the calculated mean value is subtracted and squared.
At last the squared values are summed up and divided by the number of observation and
the resulting value is placed under square root to get the required standard deviation of
the data set (Li and et.al., 2018).
Formula of standard deviation is as follows:
σ =
Serial. No. Date Humidity of
London
X – Mean (x-mean)2
1 10th January 2021 48 0.7 0.49
2 11th January 2021 53 5.7 32.49
3 12th January 2021 46 -1.3 1.69
4 13th January 2021 44 -3.3 10.89
5 14th January 2021 44 -3.3 10.89
6 15th January 2021 46 -1.3 1.69
7 16th January 2021 44 -3.3 10.89
8 17th January 2021 47 -0.3 0.09
9 18th January 2021 48 0.7 0.49
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
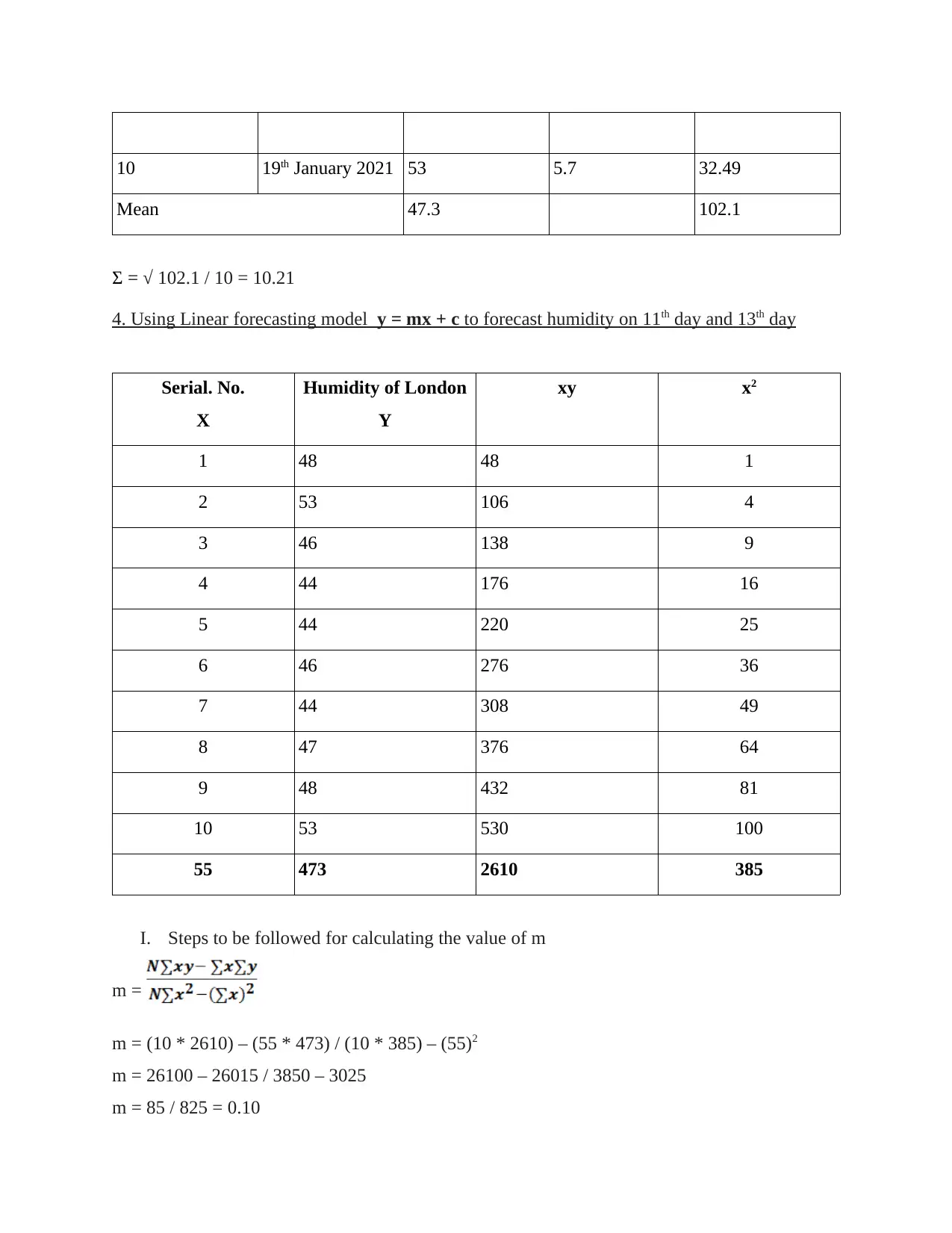
10 19th January 2021 53 5.7 32.49
Mean 47.3 102.1
Σ = √ 102.1 / 10 = 10.21
4. Using Linear forecasting model y = mx + c to forecast humidity on 11th day and 13th day
Serial. No.
X
Humidity of London
Y
xy x2
1 48 48 1
2 53 106 4
3 46 138 9
4 44 176 16
5 44 220 25
6 46 276 36
7 44 308 49
8 47 376 64
9 48 432 81
10 53 530 100
55 473 2610 385
I. Steps to be followed for calculating the value of m
m =
m = (10 * 2610) – (55 * 473) / (10 * 385) – (55)2
m = 26100 – 26015 / 3850 – 3025
m = 85 / 825 = 0.10
Mean 47.3 102.1
Σ = √ 102.1 / 10 = 10.21
4. Using Linear forecasting model y = mx + c to forecast humidity on 11th day and 13th day
Serial. No.
X
Humidity of London
Y
xy x2
1 48 48 1
2 53 106 4
3 46 138 9
4 44 176 16
5 44 220 25
6 46 276 36
7 44 308 49
8 47 376 64
9 48 432 81
10 53 530 100
55 473 2610 385
I. Steps to be followed for calculating the value of m
m =
m = (10 * 2610) – (55 * 473) / (10 * 385) – (55)2
m = 26100 – 26015 / 3850 – 3025
m = 85 / 825 = 0.10
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

m indicates steepness of the linear model and shows the direction of the line (Sari and Ahmad,
2019).
II. Steps to be followed for calculating the value of c
c=
c = 473 – (0.10 * 55) / 10
c = 473 – 5.5 / 10
c = 467.5 / 10 = 46.75
c is the constant or intercept which indicates the distance between the origin and starting point of
y axis.
III. Forecasting humidity for 11th and 13th day
x = 11th day
y = mx +c
y = 0.1 * 11 + 46.75
y = 1.1 + 46.75 = 47.85
x = 13th day
y = 0.1 * 13 + 46.75
y = 1.3 + 46.75 = 48.05
Therefore, humidity in London on 11th and 13th day would be 47.85 and 48.05 respectively.
2019).
II. Steps to be followed for calculating the value of c
c=
c = 473 – (0.10 * 55) / 10
c = 473 – 5.5 / 10
c = 467.5 / 10 = 46.75
c is the constant or intercept which indicates the distance between the origin and starting point of
y axis.
III. Forecasting humidity for 11th and 13th day
x = 11th day
y = mx +c
y = 0.1 * 11 + 46.75
y = 1.1 + 46.75 = 47.85
x = 13th day
y = 0.1 * 13 + 46.75
y = 1.3 + 46.75 = 48.05
Therefore, humidity in London on 11th and 13th day would be 47.85 and 48.05 respectively.

REFERENCES
Li, S., and et.al., 2018, September. Data reduction techniques for simulation, visualization and
data analysis. In Computer Graphics Forum (Vol. 37, No. 6, pp. 422-447).
Cole, A. P. and Trinh, Q. D., 2017. Secondary data analysis: techniques for comparing
interventions and their limitations. Current opinion in urology, 27(4), pp.354-359.
Kim, J. K. and Wang, Z., 2019. Sampling techniques for big data analysis. International
Statistical Review, 87, pp.S177-S191.
Yang, S. J., and et.al., 2018. Predicting students' academic performance using multiple linear
regression and principal component analysis. Journal of Information Processing, 26,
pp.170-176.
Sari, M. and Ahmad, A. A., 2019. Anemia modelling using the multiple regression
analysis. International Journal of Analysis and Applications, 17(5), pp.838-849.
Li, S., and et.al., 2018, September. Data reduction techniques for simulation, visualization and
data analysis. In Computer Graphics Forum (Vol. 37, No. 6, pp. 422-447).
Cole, A. P. and Trinh, Q. D., 2017. Secondary data analysis: techniques for comparing
interventions and their limitations. Current opinion in urology, 27(4), pp.354-359.
Kim, J. K. and Wang, Z., 2019. Sampling techniques for big data analysis. International
Statistical Review, 87, pp.S177-S191.
Yang, S. J., and et.al., 2018. Predicting students' academic performance using multiple linear
regression and principal component analysis. Journal of Information Processing, 26,
pp.170-176.
Sari, M. and Ahmad, A. A., 2019. Anemia modelling using the multiple regression
analysis. International Journal of Analysis and Applications, 17(5), pp.838-849.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 9