Real-Time Analytic Data Analytics Report: SAP HANA and Data Mining
VerifiedAdded on 2022/11/13
|22
|3791
|170
Report
AI Summary
This report provides a comprehensive analysis of data analytics, focusing on the application of SAP HANA for real-time data processing and analysis. It begins with an introduction to data analysis and the background of the project, followed by a detailed explanation of data modeling and provisioning within SAP HANA. The report explores different types of attributes, measures, and modeling objects. Furthermore, it delves into data mining techniques, specifically association rule data mining, outlining algorithms, and applications. The report also includes a discussion of the dataset used, research findings, and recommendations for a CEO based on the analysis. The report concludes with a summary of the key findings and references the sources used.

DATA ANALYTICS
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Contents
1. Introduction.......................................................................................................................................2
2. Background of the Project................................................................................................................2
3. Create Data View/Cube-Data Modelling and Provision.................................................................2
4. SAP HANA Data Modeling...............................................................................................................4
Types of Attributes...............................................................................................................................5
Types of measures................................................................................................................................5
Types of Modeling Objects........................................................................................................................6
5. Perform Data Mining Techniques....................................................................................................7
6. ASSOCIATION RULE DATA MINING:.......................................................................................8
Association rule algorithms...............................................................................................................8
Uses of association rules in data mining...........................................................................................9
7. Dataset................................................................................................................................................9
8. Research...........................................................................................................................................10
9. Important results of the above analysis and Recommendations to CEO....................................19
10. Conclusion....................................................................................................................................19
References............................................................................................................................................20
1. Introduction.......................................................................................................................................2
2. Background of the Project................................................................................................................2
3. Create Data View/Cube-Data Modelling and Provision.................................................................2
4. SAP HANA Data Modeling...............................................................................................................4
Types of Attributes...............................................................................................................................5
Types of measures................................................................................................................................5
Types of Modeling Objects........................................................................................................................6
5. Perform Data Mining Techniques....................................................................................................7
6. ASSOCIATION RULE DATA MINING:.......................................................................................8
Association rule algorithms...............................................................................................................8
Uses of association rules in data mining...........................................................................................9
7. Dataset................................................................................................................................................9
8. Research...........................................................................................................................................10
9. Important results of the above analysis and Recommendations to CEO....................................19
10. Conclusion....................................................................................................................................19
References............................................................................................................................................20

⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

1. Introduction
The study of investigating patterns in large dataset is called Data analysis. In this paper we use the SAP
HANA state of the art tool for the purpose of analyzing data and reporting results. This tool is a Web
Application that is very commonly used for the analyses of huge datasets. Many researches have used
this tool and that is why it is also our choice of tool for our research.
2. Background of the Project
In comma divided value format, the information representing social procurement for the European Area,
Switzerland, and the previously Yugoslav Republic of Macedonia from (2006- 01- 01) to (2018- 12- 31)
is represented by a subgroup of Tenders Electronic Daily (TED). It involves the most significant areas
from the conventional forms of contract and reward notification, for example, who purchased what from
whom, in what amount, and which standards were used for the operation and reward (Ramsay &
Silverman, 2013). The information typically comprises of contracts above the thresholds of acquisition.
Nevertheless, publication of under-threshold contracts in TED is regarded as excellent practice and
therefore there are significant amount of under-threshold contracts.
3. Create Data View/Cube-Data Modelling and Provision
SAP HANA
SAP HANA is a framework for in-memory database and application production for real-time handling of
huge amounts of information. Being the best product of SAP, it allows data analysts in real time
questioning of that information. HANA's in-memory computation database software liberates analysts
from needing to import or record information. It also contains a programming element that allows the IT
office of a company to generate and operate custom software programs in addition to HANA, in addition
to a set of indicative, visual and text analysis databases across various information sources. Since it can
work with a source SAP ERP application, analysts can access real-time data for real-time processing and
The study of investigating patterns in large dataset is called Data analysis. In this paper we use the SAP
HANA state of the art tool for the purpose of analyzing data and reporting results. This tool is a Web
Application that is very commonly used for the analyses of huge datasets. Many researches have used
this tool and that is why it is also our choice of tool for our research.
2. Background of the Project
In comma divided value format, the information representing social procurement for the European Area,
Switzerland, and the previously Yugoslav Republic of Macedonia from (2006- 01- 01) to (2018- 12- 31)
is represented by a subgroup of Tenders Electronic Daily (TED). It involves the most significant areas
from the conventional forms of contract and reward notification, for example, who purchased what from
whom, in what amount, and which standards were used for the operation and reward (Ramsay &
Silverman, 2013). The information typically comprises of contracts above the thresholds of acquisition.
Nevertheless, publication of under-threshold contracts in TED is regarded as excellent practice and
therefore there are significant amount of under-threshold contracts.
3. Create Data View/Cube-Data Modelling and Provision
SAP HANA
SAP HANA is a framework for in-memory database and application production for real-time handling of
huge amounts of information. Being the best product of SAP, it allows data analysts in real time
questioning of that information. HANA's in-memory computation database software liberates analysts
from needing to import or record information. It also contains a programming element that allows the IT
office of a company to generate and operate custom software programs in addition to HANA, in addition
to a set of indicative, visual and text analysis databases across various information sources. Since it can
work with a source SAP ERP application, analysts can access real-time data for real-time processing and
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

they don't have to queue for a regular or weekly report ("SAP HANA server infrastructure with Power
Systems", 2019).
SAP HANA FUNDAMENTALS
Function of Hana (SILVIA, 2016) ("What is SAP HANA | In Memory Computing and Real Time
Analytics", 2019) in:
o Financial affairs (Does not require merging of FI & CO with a single row object table as
an only source of data)
o Development plan (Lesser time for MRP and no time consuming jobs)
o Stockpile management (Real time warnings, decreased security inventory)
o Acquisition (Real time statistics of procurement KPI)
o Product assessment (multi capital uptake etc)
o Financial period closure (quicker reporting of outcomes for interim analysis etc)
o Informing business activities (Real time with indicative and simulation analysis)
Fiori (Instinctive knowledge for users)
o Salesperson order handling (Sales order completion dashboard for problem detection and
resolution)
o Acquisition for procurement clerk (Dashboard for all information of purchased closings)
o Structural planner’s planning (Predict supply options)
Unification of applications to core ECC
o Capabilities of current apps (such as SCM, CRM, etc.) and recently purchased cloud
alternatives (such as Ariba, Success factor, etc.) are accessible in ECC (such as ‘Digital
core’)
Systems", 2019).
SAP HANA FUNDAMENTALS
Function of Hana (SILVIA, 2016) ("What is SAP HANA | In Memory Computing and Real Time
Analytics", 2019) in:
o Financial affairs (Does not require merging of FI & CO with a single row object table as
an only source of data)
o Development plan (Lesser time for MRP and no time consuming jobs)
o Stockpile management (Real time warnings, decreased security inventory)
o Acquisition (Real time statistics of procurement KPI)
o Product assessment (multi capital uptake etc)
o Financial period closure (quicker reporting of outcomes for interim analysis etc)
o Informing business activities (Real time with indicative and simulation analysis)
Fiori (Instinctive knowledge for users)
o Salesperson order handling (Sales order completion dashboard for problem detection and
resolution)
o Acquisition for procurement clerk (Dashboard for all information of purchased closings)
o Structural planner’s planning (Predict supply options)
Unification of applications to core ECC
o Capabilities of current apps (such as SCM, CRM, etc.) and recently purchased cloud
alternatives (such as Ariba, Success factor, etc.) are accessible in ECC (such as ‘Digital
core’)

4. SAP HANA Data Modeling
DATA Provisioning
Data provisioning is another area of interest that we have explored in our research work. In Data
provisioning we create and preparing a network and then configure it to provide required information to
the users. Once all of the data has been processed it will be ready for loading into the HANA software
where the user can access it easily and use it as he wishes
There is a name given to these processes. They are known with the titles of Extract Transform Load, also
abbreviated as ETL. In extraction we take out the data using various sources of raw data. In the
transformation phase the data is made readily usable to the user. This is done in accordance with a set
of rules laid down that are standard processes of transformation of data. The toughest part is extraction
because the data sources are not always reliable.
Duplicating data in SAP HANA:
The duplication of data in this software is commonly done in 2 methods.
- Using the already existing libraries of HANA to have a collection of flat files or data streams.
This supports multiple formats such as .cs, .xls and .xlsx, among others
- Making use of the services that are included in the SAP package which help in extraction in ETL
and weaver platform when it is run. The other service that can be used is SLT which is especially
useful for some platforms like weaver
It displays data from the databases as a business design. With this, we can make an information model,
which could be used in reporting and analytical application, for example SAP Lumira, Webi etc. These
type of models can be made by processing and modification of information from data sources.
It’s modeling is done by the SAP HANA Studio Modeler and is enforced on the database layer so that it
can later be used by the application layer without having to go through many stages. This saves a large
DATA Provisioning
Data provisioning is another area of interest that we have explored in our research work. In Data
provisioning we create and preparing a network and then configure it to provide required information to
the users. Once all of the data has been processed it will be ready for loading into the HANA software
where the user can access it easily and use it as he wishes
There is a name given to these processes. They are known with the titles of Extract Transform Load, also
abbreviated as ETL. In extraction we take out the data using various sources of raw data. In the
transformation phase the data is made readily usable to the user. This is done in accordance with a set
of rules laid down that are standard processes of transformation of data. The toughest part is extraction
because the data sources are not always reliable.
Duplicating data in SAP HANA:
The duplication of data in this software is commonly done in 2 methods.
- Using the already existing libraries of HANA to have a collection of flat files or data streams.
This supports multiple formats such as .cs, .xls and .xlsx, among others
- Making use of the services that are included in the SAP package which help in extraction in ETL
and weaver platform when it is run. The other service that can be used is SLT which is especially
useful for some platforms like weaver
It displays data from the databases as a business design. With this, we can make an information model,
which could be used in reporting and analytical application, for example SAP Lumira, Webi etc. These
type of models can be made by processing and modification of information from data sources.
It’s modeling is done by the SAP HANA Studio Modeler and is enforced on the database layer so that it
can later be used by the application layer without having to go through many stages. This saves a large
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

amount of time and supplies. Modeling equipment can be made in the modeler where data will be
processed form the database according to the framework of the model. Models created on this level make
use of the processing innovations and characteristics of multi-core CPU’s, which can later be executed.
A SAP HANA data model can be crated in the SAP HANA Studio. The database and tables can be
accessed in the Catalog tab. After the model with information views has been created, all those views can
be accessed in the Content tab. These views are present in a package named categories, depending on the
view types. The data tables have been designed differently in a view, particularly as dimension and fact
tables.
Attributes are the explanatory data containing information about the data used in the tables. The attributes
are therefore data features like Country, Store, Sales ID etc. Attributes are the kinds of data that are
immeasurable and can not be used in calculations.
But measures are data entries which are both measurable and calculable.
The measures that are used by the views can be helpful for analytical requirements.
Types of Attributes
Basic Attributes – Can be derived from the date source.
Calculated Attributes – Created from residing source attributes. For example, full name,
created from two attributes, first name and last name.
Private Attributes – Used in modeling data in views. Once these attributes are taken as private
in a view, they can be used in the specific view only.
Types of measures
Basic Measure - Taken from the source table in their original state.
Calculated Measure – Created from a combination of two measures from OLAP, cubes,
constants etc. For example, Profit = Sales price – Cost price.
processed form the database according to the framework of the model. Models created on this level make
use of the processing innovations and characteristics of multi-core CPU’s, which can later be executed.
A SAP HANA data model can be crated in the SAP HANA Studio. The database and tables can be
accessed in the Catalog tab. After the model with information views has been created, all those views can
be accessed in the Content tab. These views are present in a package named categories, depending on the
view types. The data tables have been designed differently in a view, particularly as dimension and fact
tables.
Attributes are the explanatory data containing information about the data used in the tables. The attributes
are therefore data features like Country, Store, Sales ID etc. Attributes are the kinds of data that are
immeasurable and can not be used in calculations.
But measures are data entries which are both measurable and calculable.
The measures that are used by the views can be helpful for analytical requirements.
Types of Attributes
Basic Attributes – Can be derived from the date source.
Calculated Attributes – Created from residing source attributes. For example, full name,
created from two attributes, first name and last name.
Private Attributes – Used in modeling data in views. Once these attributes are taken as private
in a view, they can be used in the specific view only.
Types of measures
Basic Measure - Taken from the source table in their original state.
Calculated Measure – Created from a combination of two measures from OLAP, cubes,
constants etc. For example, Profit = Sales price – Cost price.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Restricted Measure – Selected measure values due to an applied condition placed on an
attribute. For example, displaying the measure values for a gross revenue on a pecific car in USA.
Counter – Kind of column in a calculation or analytical view. It displays the number of attribute
columns.
Types of Modeling Objects
Attribute View
Analytic View
Calculation View
Decision Table
SAP HANA Data Provision:
DATA Provisioning is a method that creates, prepares and enables a network to provide its customer
with information. Before information hits the customer through a front-end instrument, information must
be added to SAP HANA.
It works with information reproduction in the HANA database to be used in modeling of HANA and to
be gobbled up by reporting instruments. Different techniques of information provisioning are endorsed
in information reproduction of SAP HANA scheme.
Its replication enables information to be migrated to the SAP HANA database from source devices. An
easy way to transfer information from the current SAP scheme to HANA is through the use of different
methods for information reproduction.
You can set up system replication via command line on the computer or by using HANA studio. During
this phase, the main ECC or transaction schemes can remain online. The HANA scheme contains three
kinds of information replication techniques –
attribute. For example, displaying the measure values for a gross revenue on a pecific car in USA.
Counter – Kind of column in a calculation or analytical view. It displays the number of attribute
columns.
Types of Modeling Objects
Attribute View
Analytic View
Calculation View
Decision Table
SAP HANA Data Provision:
DATA Provisioning is a method that creates, prepares and enables a network to provide its customer
with information. Before information hits the customer through a front-end instrument, information must
be added to SAP HANA.
It works with information reproduction in the HANA database to be used in modeling of HANA and to
be gobbled up by reporting instruments. Different techniques of information provisioning are endorsed
in information reproduction of SAP HANA scheme.
Its replication enables information to be migrated to the SAP HANA database from source devices. An
easy way to transfer information from the current SAP scheme to HANA is through the use of different
methods for information reproduction.
You can set up system replication via command line on the computer or by using HANA studio. During
this phase, the main ECC or transaction schemes can remain online. The HANA scheme contains three
kinds of information replication techniques –

• SAP Landscape Transformation (SLT) Replication
• ETL tool SAP Business Object Data Service (BODS)
• Direct Extractor Connection (DXC)
Extract - This is the first and often the hardest portion of ETL that extracts information from the distinct
source scheme.
Transform - Sequence of laws or features are described for the information obtained from the original
scheme, to feed this information into the destination scheme in the Transformation Part.
Load – It loads the data in the target system.
5. Perform Data Mining Techniques
The process of taking data and performing analysis on it in order to be able to categorize it into
different categories is called data mining. In this process we try to extract useful information
from all of the data so that this data can then be used to understand and make inferences. Some
other terms have also surfaced in the past few years such as knowledge discovery and the
discovery of data. This data mining helps business in becoming more efficient and making
informed decision ahead of time that can help them increase their revenues
Key features of data mining:
There are many key features of data mining, some of which are written below:
Analyzing the trends, leading to prediction of patterns that are automatic
Checking the possible outcomes of data and then being able to state the probablitlty of which one
will occurs (Hair, Black, Babin & Anderson, n.d.) Help in decision making by making decisions
according to the data trends Huge datasets are analyzed that are to be used in databases
Making clusters or groups of data to infer information that was not previously known (Peck &
Devore, 2012).
• ETL tool SAP Business Object Data Service (BODS)
• Direct Extractor Connection (DXC)
Extract - This is the first and often the hardest portion of ETL that extracts information from the distinct
source scheme.
Transform - Sequence of laws or features are described for the information obtained from the original
scheme, to feed this information into the destination scheme in the Transformation Part.
Load – It loads the data in the target system.
5. Perform Data Mining Techniques
The process of taking data and performing analysis on it in order to be able to categorize it into
different categories is called data mining. In this process we try to extract useful information
from all of the data so that this data can then be used to understand and make inferences. Some
other terms have also surfaced in the past few years such as knowledge discovery and the
discovery of data. This data mining helps business in becoming more efficient and making
informed decision ahead of time that can help them increase their revenues
Key features of data mining:
There are many key features of data mining, some of which are written below:
Analyzing the trends, leading to prediction of patterns that are automatic
Checking the possible outcomes of data and then being able to state the probablitlty of which one
will occurs (Hair, Black, Babin & Anderson, n.d.) Help in decision making by making decisions
according to the data trends Huge datasets are analyzed that are to be used in databases
Making clusters or groups of data to infer information that was not previously known (Peck &
Devore, 2012).
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Data mining processes are a collection of many steps. We underline some of them below
- The extraction and transformation of the data by loading it into databanks of huge
capacity
- Data is converted into many different dimension based on attributes and then stored
easily
- The analyzers are provided access to all the data so they can analyze and visualize it for
business development
- Once the data is analyzed it is presented in easily visualizable form so that the reader can
understand it really quickly
6. ASSOCIATION RULE DATA MINING:
Quickly one of the branches of data mining is the association rule data mining which is the study
of machine learning techniques and models in order to find recurring occurrences and trends in
the data. And how the data is associated to different patterns and trends. Antecedent and
consequent are the two major parts of the associative properties of datasets. The items found
within the data are termed as antecedent and the output of different combinations of the data are
called consequents. Consequents comes from the word consequences, and its meaning is the
same as the root word as well. It is a consequence of the merging of different types of data
(Berthold & Hand, 2011) ("Challenges with Big Data Analytics", 2015).If looked at closely, you
will find if and else associations in almost all datasets. This means that every dataset contains
associations and a response to some certain variables. This often gives rise to another variable
which is given the term lift.
Association rule algorithms
Many association rules algorithms have been developed in order to help people in the working
and understanding of associative algorithms. The AIS algorithm is one such examples in the
large datasets contain transactions and new item sets that result from the transactions that are
occurring. Another algorithms is the SETM which is an efficient way of using associative data. It
- The extraction and transformation of the data by loading it into databanks of huge
capacity
- Data is converted into many different dimension based on attributes and then stored
easily
- The analyzers are provided access to all the data so they can analyze and visualize it for
business development
- Once the data is analyzed it is presented in easily visualizable form so that the reader can
understand it really quickly
6. ASSOCIATION RULE DATA MINING:
Quickly one of the branches of data mining is the association rule data mining which is the study
of machine learning techniques and models in order to find recurring occurrences and trends in
the data. And how the data is associated to different patterns and trends. Antecedent and
consequent are the two major parts of the associative properties of datasets. The items found
within the data are termed as antecedent and the output of different combinations of the data are
called consequents. Consequents comes from the word consequences, and its meaning is the
same as the root word as well. It is a consequence of the merging of different types of data
(Berthold & Hand, 2011) ("Challenges with Big Data Analytics", 2015).If looked at closely, you
will find if and else associations in almost all datasets. This means that every dataset contains
associations and a response to some certain variables. This often gives rise to another variable
which is given the term lift.
Association rule algorithms
Many association rules algorithms have been developed in order to help people in the working
and understanding of associative algorithms. The AIS algorithm is one such examples in the
large datasets contain transactions and new item sets that result from the transactions that are
occurring. Another algorithms is the SETM which is an efficient way of using associative data. It
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

involves transactions as well and for that reason shares some of the disadvantages of AIS. Both
algorithms create many small subsets that are related to each other and then there is a summation
done at the end again. All this makes the process tedious and not very efficient. All this has been
mentioned in great detail by Dr. SaedSayad in the book he has authored.
Uses of association rules in data mining
It is not unheard of to make usage of the association rules in data mining (Gjerstad, 2008). A very
important role is played by them in data mining and programmers use the rules when they face
difficultly in building machine learning algorithms. For those who are new to machine learning,
it is important to understand that machine learning is a branch of artificial intelligence in which
computers are taught to understand and analyze data and then make inferences from it.
Association rules play a major part in data mining and are used very frequently. The developers
use these rules in development of machine learning algorithms to provide more efficient and
transparent results of data mining
7. Dataset
In machine learning the greatest challenge is the availability of datasets. Without large datasets
our results will always be inaccurate. The data is used in its raw form. Then it is cleaned up for
anomalies and portions that are not of use (Graham, 2011). This data is the stored separately to
avoid overlapping data. It is common for data entry operators to make mistakes while entering
the data so over the year’s people have looked toward technology to provide more efficient data
entry mechanisms. The data is also filtered to keep the relevant data and discard the other. The
number of fields has now been put a limit on in order to stop the overly splitting of data in which
there is the possibility of losing meaningful data. The man to many relationship of the data
amongst each other greatly affects the way matters are influenced. To explain this:
- One notice has lots of information about more than one slots
algorithms create many small subsets that are related to each other and then there is a summation
done at the end again. All this makes the process tedious and not very efficient. All this has been
mentioned in great detail by Dr. SaedSayad in the book he has authored.
Uses of association rules in data mining
It is not unheard of to make usage of the association rules in data mining (Gjerstad, 2008). A very
important role is played by them in data mining and programmers use the rules when they face
difficultly in building machine learning algorithms. For those who are new to machine learning,
it is important to understand that machine learning is a branch of artificial intelligence in which
computers are taught to understand and analyze data and then make inferences from it.
Association rules play a major part in data mining and are used very frequently. The developers
use these rules in development of machine learning algorithms to provide more efficient and
transparent results of data mining
7. Dataset
In machine learning the greatest challenge is the availability of datasets. Without large datasets
our results will always be inaccurate. The data is used in its raw form. Then it is cleaned up for
anomalies and portions that are not of use (Graham, 2011). This data is the stored separately to
avoid overlapping data. It is common for data entry operators to make mistakes while entering
the data so over the year’s people have looked toward technology to provide more efficient data
entry mechanisms. The data is also filtered to keep the relevant data and discard the other. The
number of fields has now been put a limit on in order to stop the overly splitting of data in which
there is the possibility of losing meaningful data. The man to many relationship of the data
amongst each other greatly affects the way matters are influenced. To explain this:
- One notice has lots of information about more than one slots
- The information about various rewards is contained in one single CAN
- Several slots are linked and associated to one award
- It is common to award multiple cases to one single slot
8. Research
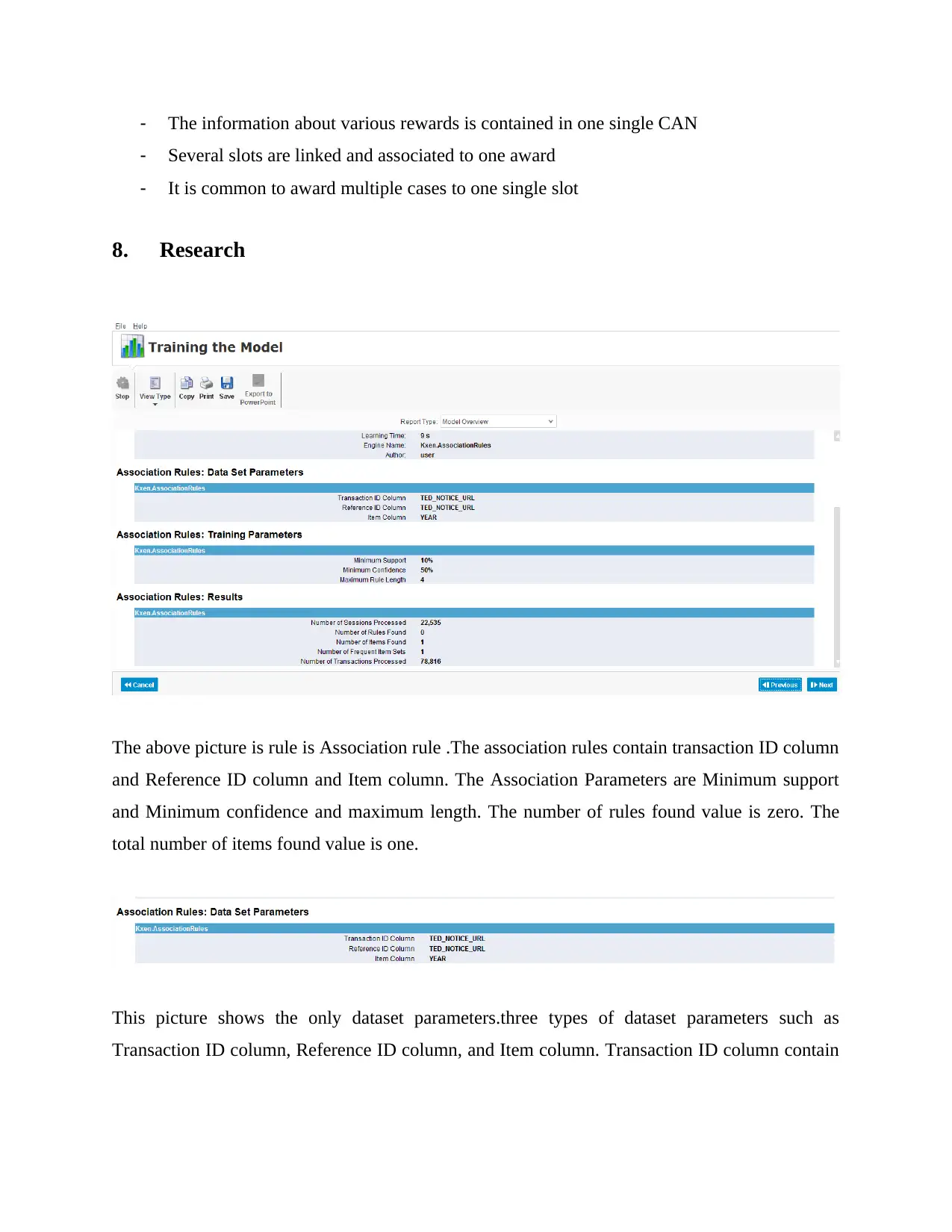
The above picture is rule is Association rule .The association rules contain transaction ID column
and Reference ID column and Item column. The Association Parameters are Minimum support
and Minimum confidence and maximum length. The number of rules found value is zero. The
total number of items found value is one.
This picture shows the only dataset parameters.three types of dataset parameters such as
Transaction ID column, Reference ID column, and Item column. Transaction ID column contain
- Several slots are linked and associated to one award
- It is common to award multiple cases to one single slot
8. Research
The above picture is rule is Association rule .The association rules contain transaction ID column
and Reference ID column and Item column. The Association Parameters are Minimum support
and Minimum confidence and maximum length. The number of rules found value is zero. The
total number of items found value is one.
This picture shows the only dataset parameters.three types of dataset parameters such as
Transaction ID column, Reference ID column, and Item column. Transaction ID column contain
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 22
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.