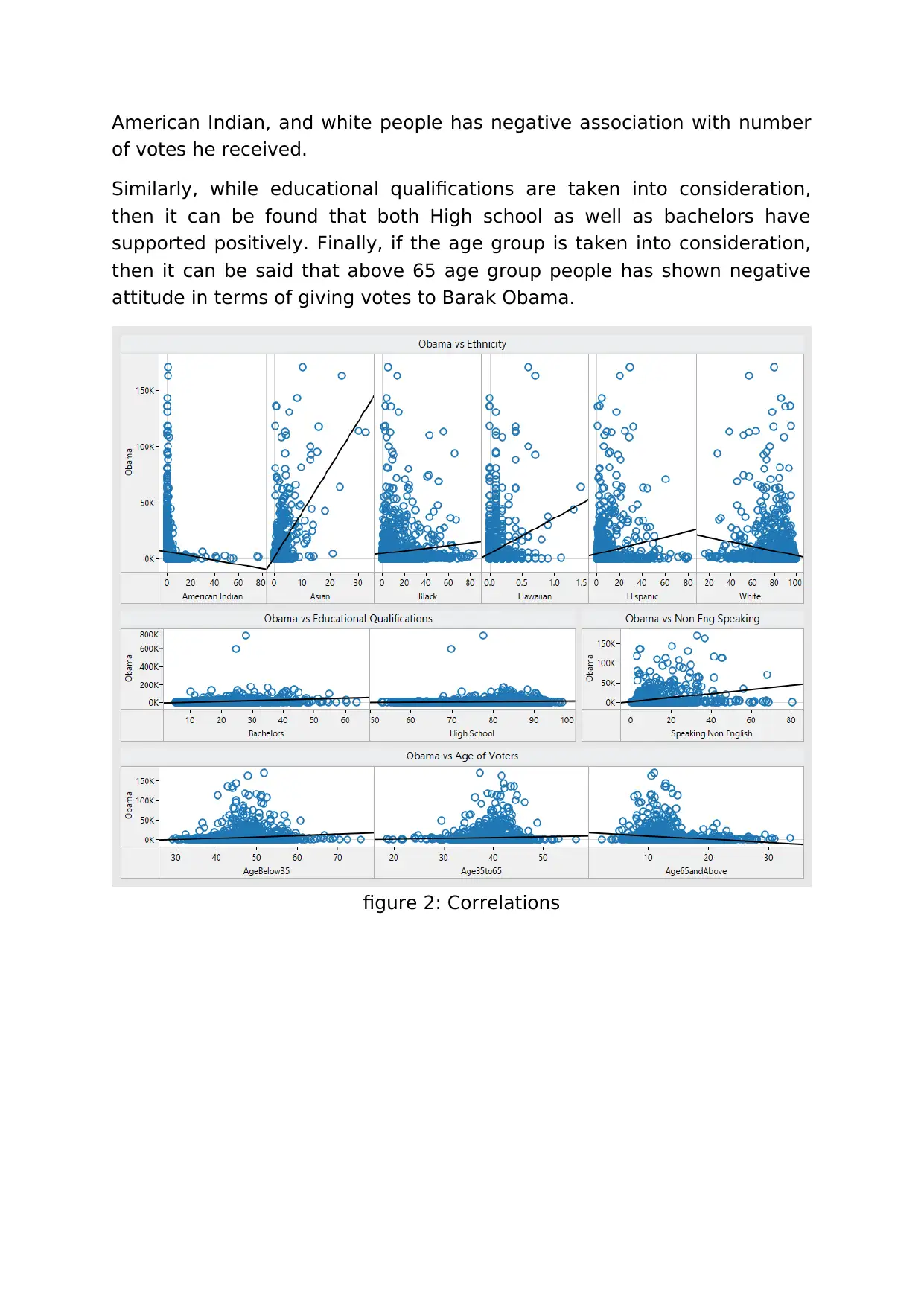
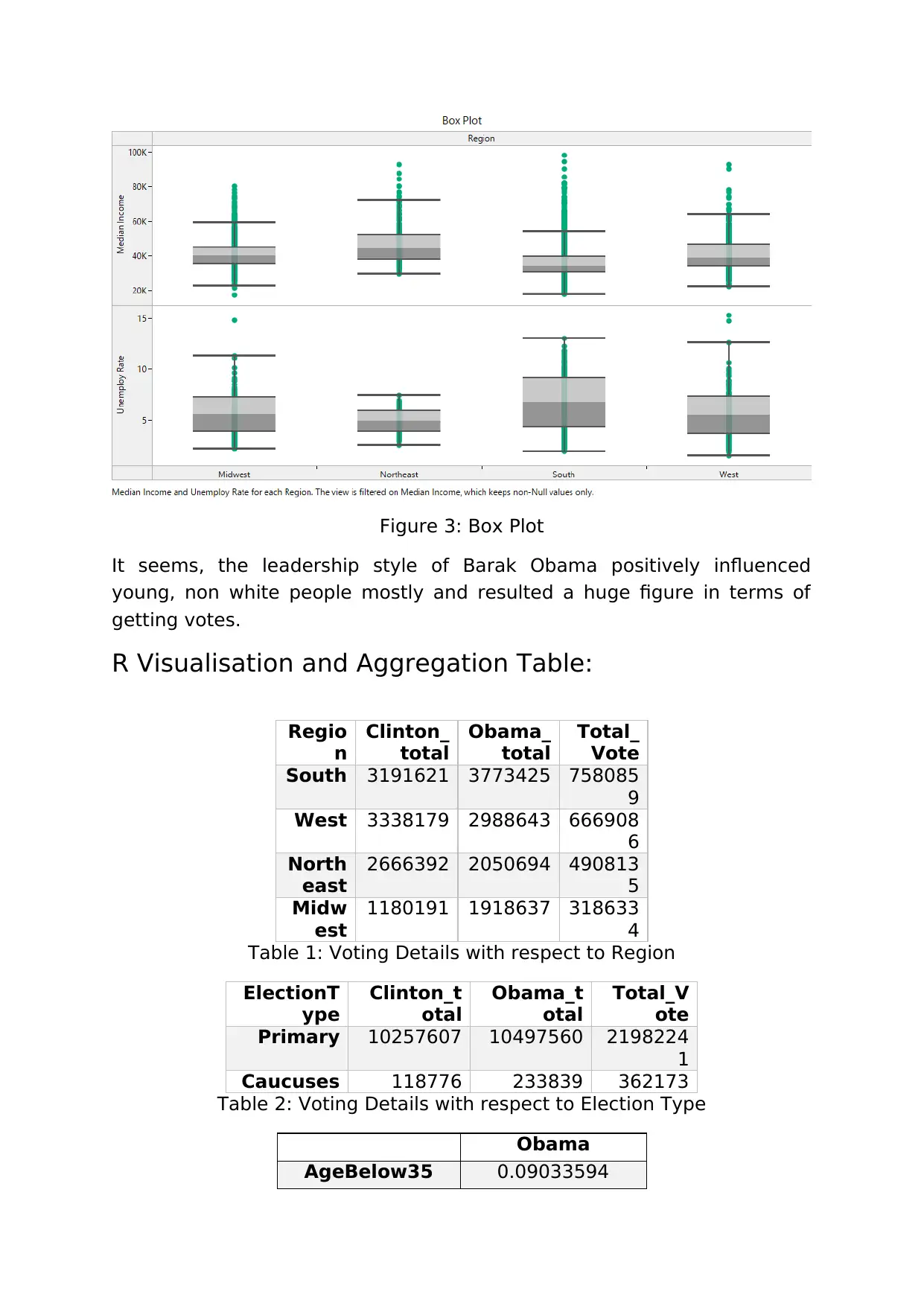
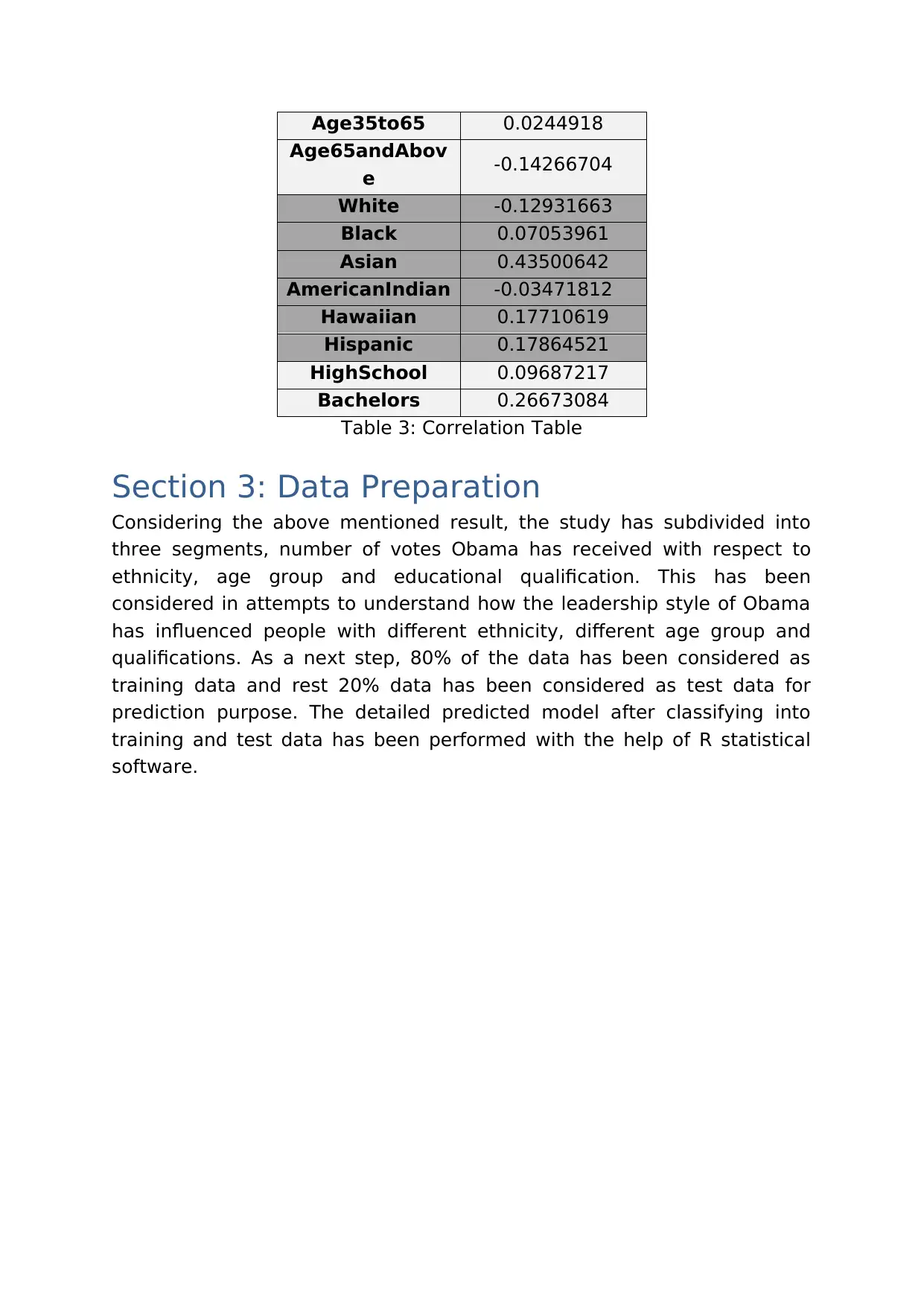
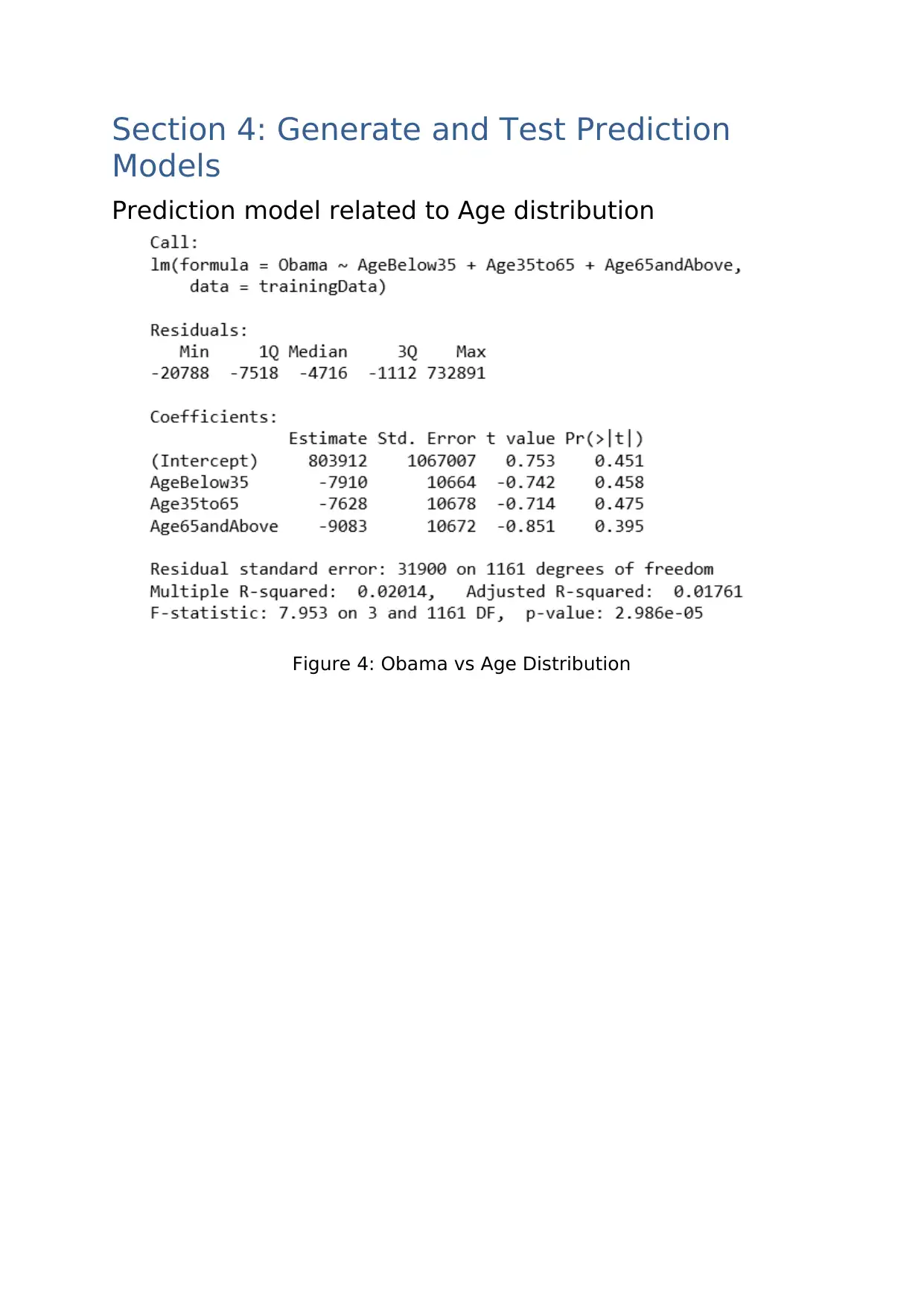
Data Analytics II: Obama-Clinton Election & NICU Data Case Study
VerifiedAdded on 2023/04/20
|25
|2842
|93
Case Study
AI Summary
This assignment presents a comprehensive analysis of two case studies: the 2008 US Presidential primaries between Barack Obama and Hillary Clinton, and trends in US Births data, specifically focusing on the NICU (Neonatal Intensive Care Unit). The Obama-Clinton case study explores the leadership styles of the candidates and their impact on vote results, using data related to ethnicity, age, and education levels. Tableau and R visualizations are employed to understand data characteristics and correlations. Prediction models are generated to assess the influence of Obama's leadership style on different demographic groups. The NICU case study investigates trend and seasonality patterns in US Births data, analyzing variations based on socio-demographic factors. Exponential smoothing techniques in R are used for forecasting birth rates, comparing different models for seasonal and non-seasonal data. The report concludes with recommendations based on the analysis and includes a code appendix detailing the R scripts used.








1 out of 25
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.