HI6007 Statistics Assignment: Data Analysis, Regression, Holmes
VerifiedAdded on 2023/05/28
|11
|1525
|220
Homework Assignment
AI Summary
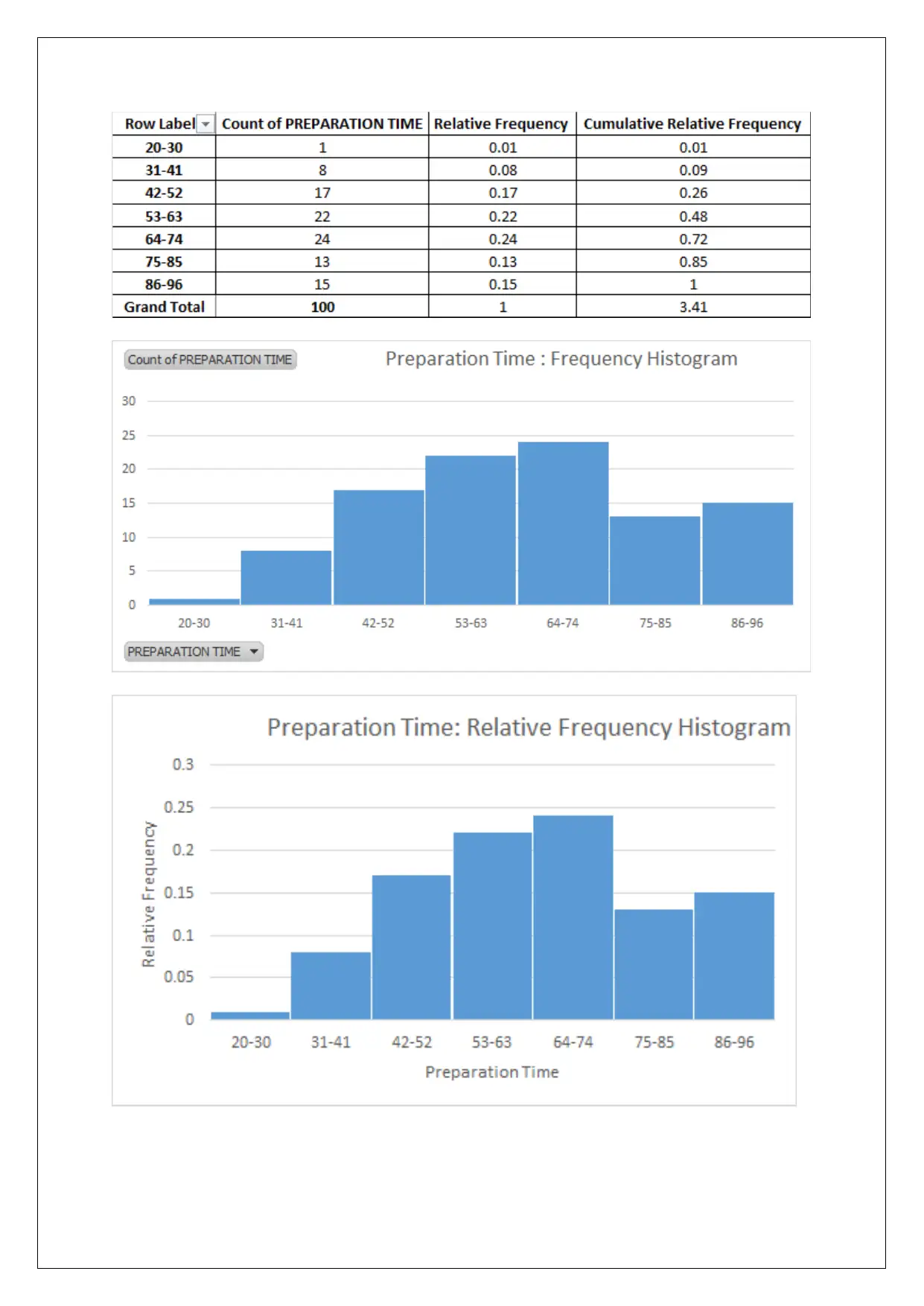
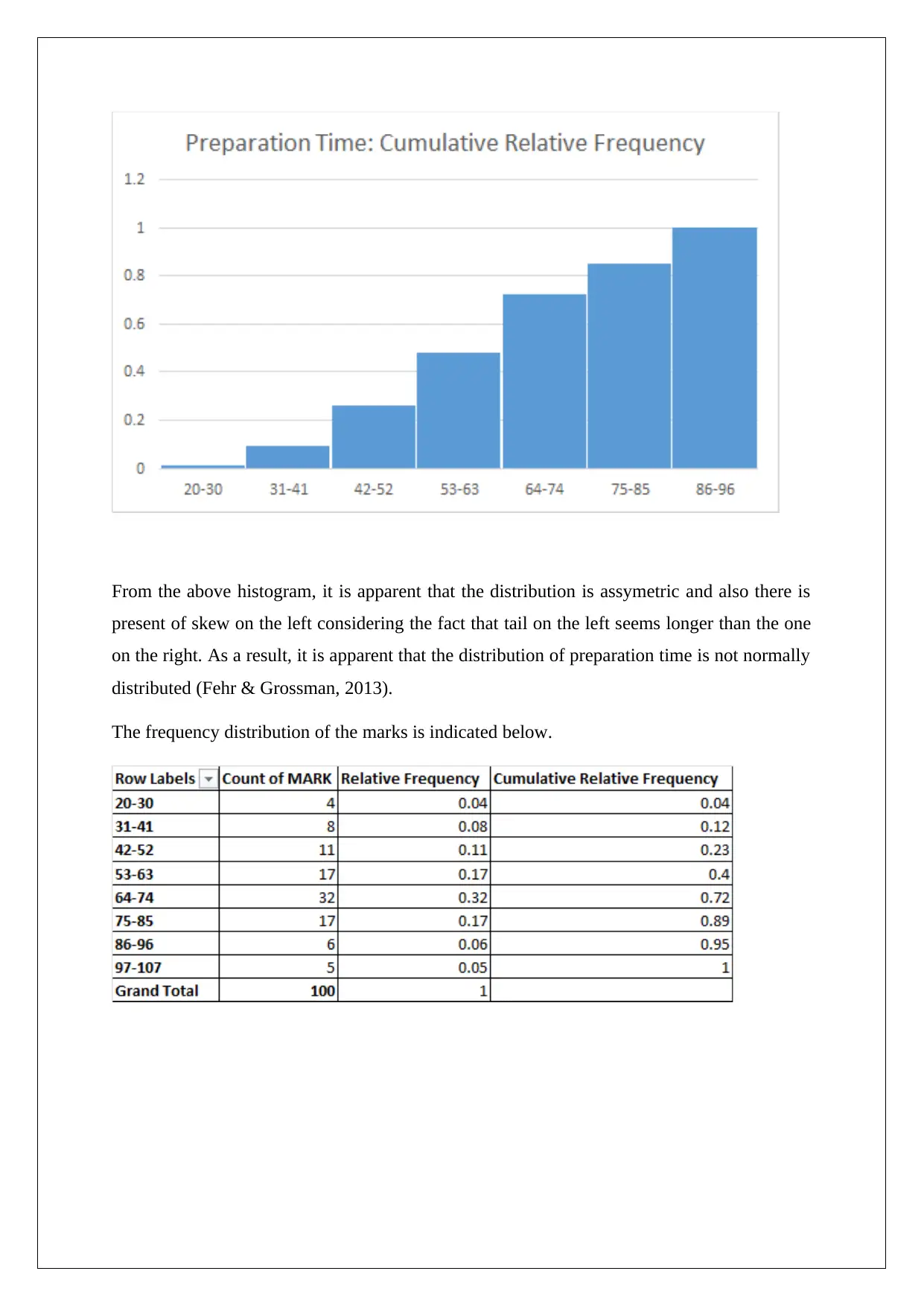
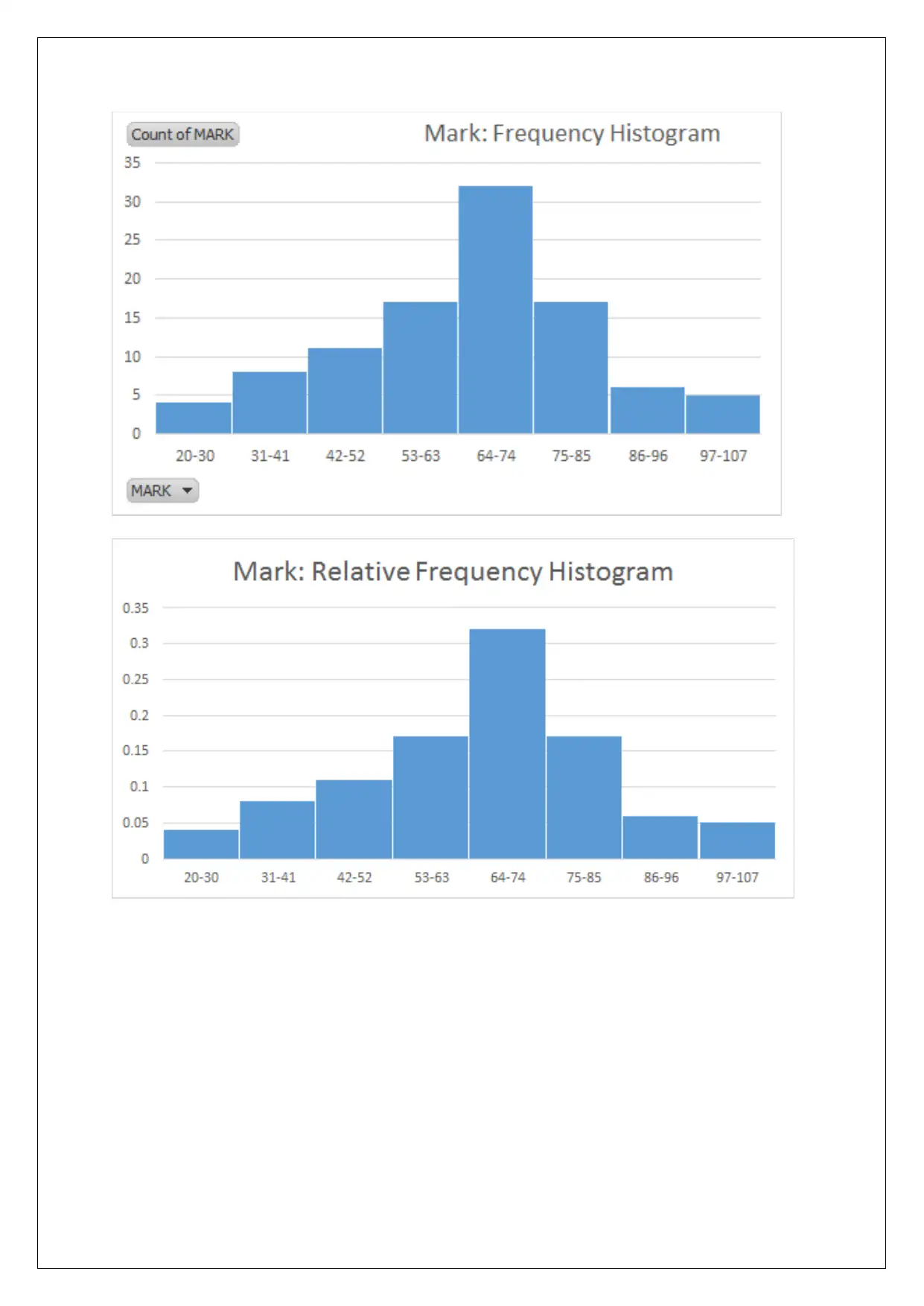
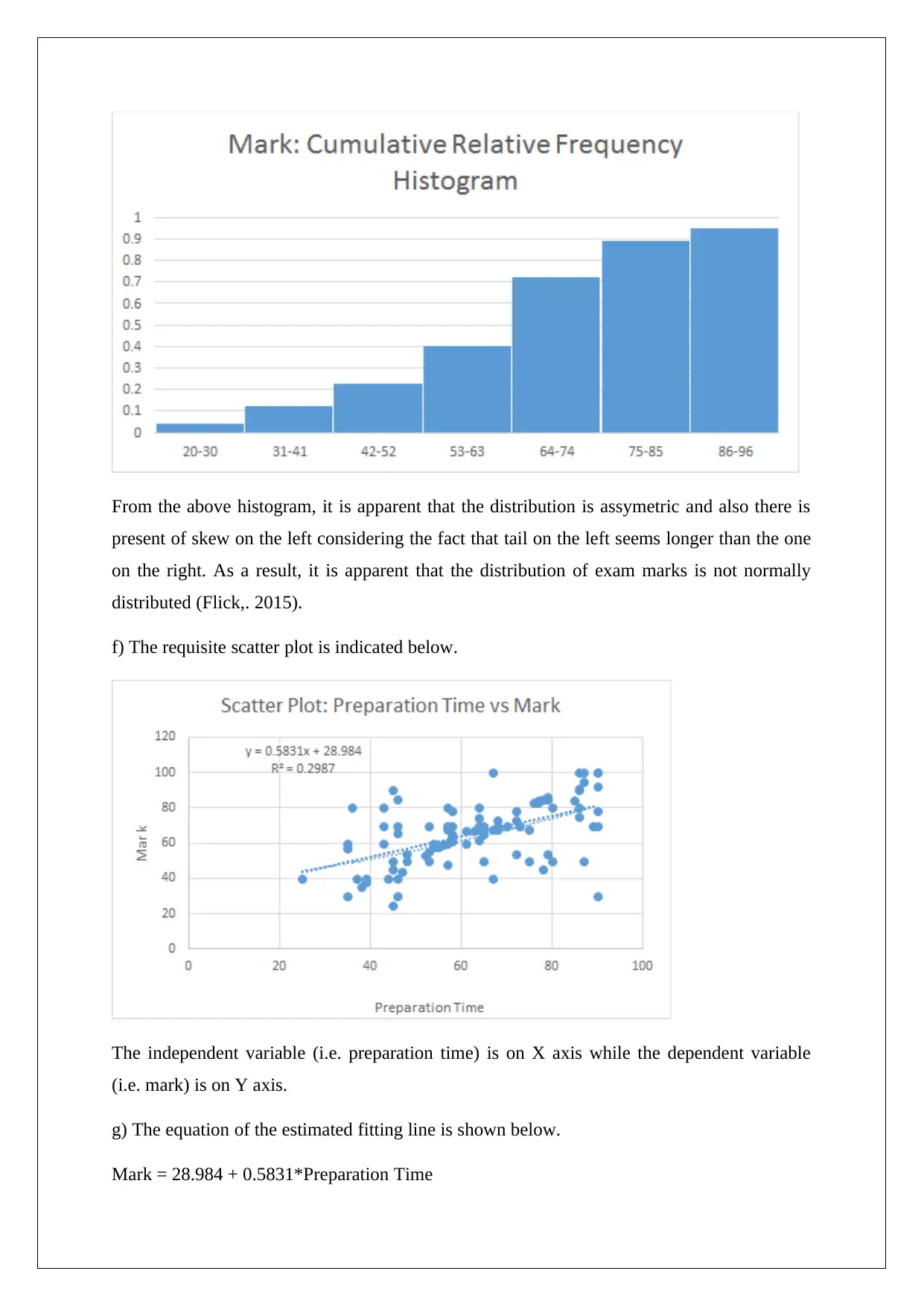
This assignment solution provides a comprehensive analysis of statistical data, focusing on regression modeling. It covers various aspects, including data collection methods, sampling techniques like stratified random sampling, and the identification of independent and dependent variables. The solution addresses potential issues in data collection, examines frequency distributions, and interprets scatter plots. It further delves into regression analysis, providing the equation of the estimated fitting line, numerical summaries, and correlation coefficients. The assignment also includes a detailed analysis of a multiple regression model, interpreting standard error, R-squared values, and hypothesis testing, ultimately determining the significance of various factors in the model. This resource is helpful for students seeking to understand and apply statistical techniques, with Desklib providing additional support through access to past papers and solved assignments.





1 out of 11
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.