Data Handling and Business Intelligence: Excel and Weka Analysis
VerifiedAdded on 2023/01/11
|15
|2608
|27
Report
AI Summary
This report delves into data handling and business intelligence, focusing on the evaluation of Microsoft Excel and Weka for data analysis and visualization. It explores current trends in data mining and business intelligence, including mobile BI and collaborative BI, while also providing a comprehensive understanding of predictive analytic software. The report uses Excel to analyze Superstore data for pre-processing, analysis, and visualization, highlighting key findings on sales and profit patterns. It then compares the advantages and disadvantages of Weka over Excel, followed by explanations of various data mining methods like clustering and regression, with real-world examples. The report applies Weka's k-means clustering to an Audi dealership dataset, uncovering insights on customer preferences. Finally, it suggests additional data columns to enrich the analysis, such as customer satisfaction levels, to gain a competitive advantage.

DATA HANDLING AND
BUSINESS INTELLIGENCE
BUSINESS INTELLIGENCE
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Contents
INTRODUCTION...........................................................................................................................1
PART 1............................................................................................................................................1
Evaluating the use of Excel for pre-processing the data, analysing the data and visualising the
data...............................................................................................................................................1
PART 2............................................................................................................................................6
2.1 Discussing the advantages/disadvantages of Weka over Excel.............................................6
2.2 Explaining the data mining methods that can be used in business with real world examples
.....................................................................................................................................................7
2.2.2 Weka clustering..................................................................................................................7
2.3 Additional columns in the audidealership1.csv...................................................................10
CONCLUSION..............................................................................................................................11
REFERENCES..............................................................................................................................12
INTRODUCTION...........................................................................................................................1
PART 1............................................................................................................................................1
Evaluating the use of Excel for pre-processing the data, analysing the data and visualising the
data...............................................................................................................................................1
PART 2............................................................................................................................................6
2.1 Discussing the advantages/disadvantages of Weka over Excel.............................................6
2.2 Explaining the data mining methods that can be used in business with real world examples
.....................................................................................................................................................7
2.2.2 Weka clustering..................................................................................................................7
2.3 Additional columns in the audidealership1.csv...................................................................10
CONCLUSION..............................................................................................................................11
REFERENCES..............................................................................................................................12

⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

INTRODUCTION
The concepts of data handling and business intelligence are related to data analytics which
helps an organisation to use their raw data and transform in intro much meaningful information
which can be used for strategy formation and future planning (Ashrafi, Kelleher and Kuilboer,
2014). The main aim of this report includes evaluation of current trends in data mining, business
intelligence and data mining along with building a comprehensive knowledge of essential
concepts and principles of predictive analytic software.
In this report, software applications of Microsoft Excel and Weka are used. Using Excel, the
data set of Superstore is evaluated and using Weka, data of audidealership is analysed. In this
report, uses of Excel are also evaluated for pre processing, analysing and visualising the data.
Along with explanation of data mining methods, the pros and cons of Weka over Excel are also
discussed in this report.
PART 1
Evaluating the use of Excel for pre-processing the data, analysing the data and visualising the
data
Data warehousing, business intelligence and data mining are the procedures which allow
an organisation to record, classify, transform and analyse the data. There are various current
trends in this field of data analytics which are the result to issues which are faced while analysing
the data. These current trends include mobile BI, collaborative BI, sigma computing, Web 2.0
based Visualisation. The current trend of mobile BI will allow its user to access their big data
information from any place in the world which develops ease of accessibility. Collaborative BI is
a current trend which is also known as social BI; this technology allows all permitted
stakeholders to access the data which eliminates the issue of ineffective communication. Sigma
computing is a current trend which allows its users to adopt holistic approach while analysing the
data so that each and every variable in the data can be considered. Lastly, Web 2.0 based
visualisation is a current trend which allows its users to visualise their mined data using
dashboards and graphs so that it can presented to executives (Hänel and Felden, 2013).
There are various tools and applications of business intelligence and one of them is
Microsoft Excel. Excel is a software application which is commonly used for data recording and
1
The concepts of data handling and business intelligence are related to data analytics which
helps an organisation to use their raw data and transform in intro much meaningful information
which can be used for strategy formation and future planning (Ashrafi, Kelleher and Kuilboer,
2014). The main aim of this report includes evaluation of current trends in data mining, business
intelligence and data mining along with building a comprehensive knowledge of essential
concepts and principles of predictive analytic software.
In this report, software applications of Microsoft Excel and Weka are used. Using Excel, the
data set of Superstore is evaluated and using Weka, data of audidealership is analysed. In this
report, uses of Excel are also evaluated for pre processing, analysing and visualising the data.
Along with explanation of data mining methods, the pros and cons of Weka over Excel are also
discussed in this report.
PART 1
Evaluating the use of Excel for pre-processing the data, analysing the data and visualising the
data
Data warehousing, business intelligence and data mining are the procedures which allow
an organisation to record, classify, transform and analyse the data. There are various current
trends in this field of data analytics which are the result to issues which are faced while analysing
the data. These current trends include mobile BI, collaborative BI, sigma computing, Web 2.0
based Visualisation. The current trend of mobile BI will allow its user to access their big data
information from any place in the world which develops ease of accessibility. Collaborative BI is
a current trend which is also known as social BI; this technology allows all permitted
stakeholders to access the data which eliminates the issue of ineffective communication. Sigma
computing is a current trend which allows its users to adopt holistic approach while analysing the
data so that each and every variable in the data can be considered. Lastly, Web 2.0 based
visualisation is a current trend which allows its users to visualise their mined data using
dashboards and graphs so that it can presented to executives (Hänel and Felden, 2013).
There are various tools and applications of business intelligence and one of them is
Microsoft Excel. Excel is a software application which is commonly used for data recording and
1
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
analysis. The uses of this application for pre processing, analysis and visualisation are discussed
below by using the dataset of Superstore:
Data pre processing
Preparing the data for the purpose of analysis is known as pre processing the data. This
procedure involves cleansing, transformation and reduction of data to mould the data in such a
way that it can be used for further analysis purposes (Heang, 2017). Microsoft Excel has a
feature of finding missing data frequencies which is used to clean the data. This function can be
used by the shortcut key of Shift + F4. This function is used to find missing values from
superstore data. The missing values were found in the variable of product base margin which
were filled by their mean value. Once the entire data was cleansed, it was reduced by using the
PIVOT table function of Excel. This function was used by using PIVOT table field list, from
which only those variables were selected which can impact the sales and profit of superstore. All
the numeric variables were recorded in columns which are Sum of Order Quantity, Sum of Sales,
Sum of Discount, Sum of Profit, Sum of Unit Price, Sum of Shipping Cost , Sum of Product Base
Margin and all the numeric variables were recorded in rows which are order date, shipment mode
and customer segment.
Data analysis and visualisation
After pre processing of data, it is important to analyse and visualise the data. Data analysis
is a procedure in which data is mined so that additional information from that data can be gained
(Olszak and Batko, 2012). Consequently, data visualisation is a procedure which presents the
mined data using graphs and tables.
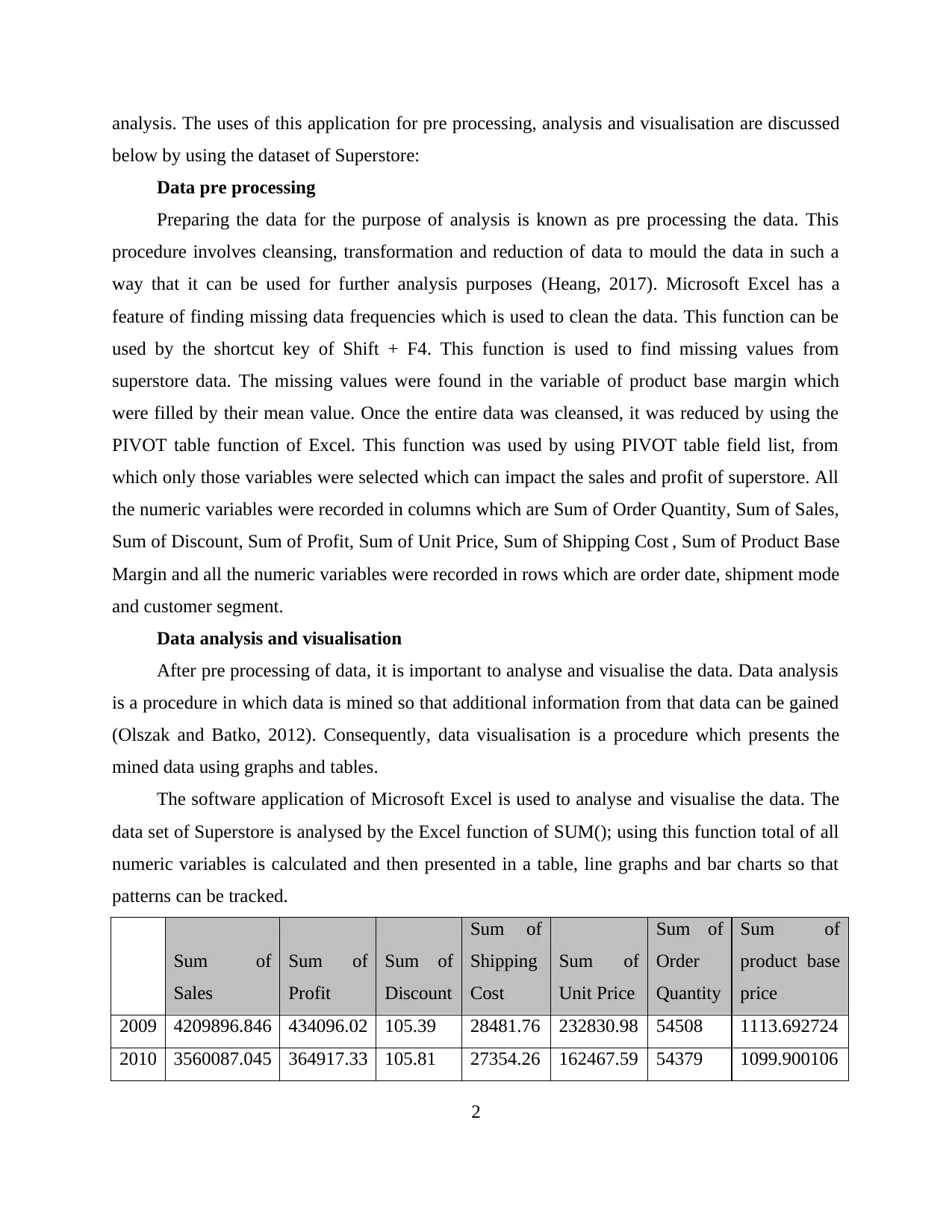
The software application of Microsoft Excel is used to analyse and visualise the data. The
data set of Superstore is analysed by the Excel function of SUM(); using this function total of all
numeric variables is calculated and then presented in a table, line graphs and bar charts so that
patterns can be tracked.
Sum of
Sales
Sum of
Profit
Sum of
Discount
Sum of
Shipping
Cost
Sum of
Unit Price
Sum of
Order
Quantity
Sum of
product base
price
2009 4209896.846 434096.02 105.39 28481.76 232830.98 54508 1113.692724
2010 3560087.045 364917.33 105.81 27354.26 162467.59 54379 1099.900106
2
below by using the dataset of Superstore:
Data pre processing
Preparing the data for the purpose of analysis is known as pre processing the data. This
procedure involves cleansing, transformation and reduction of data to mould the data in such a
way that it can be used for further analysis purposes (Heang, 2017). Microsoft Excel has a
feature of finding missing data frequencies which is used to clean the data. This function can be
used by the shortcut key of Shift + F4. This function is used to find missing values from
superstore data. The missing values were found in the variable of product base margin which
were filled by their mean value. Once the entire data was cleansed, it was reduced by using the
PIVOT table function of Excel. This function was used by using PIVOT table field list, from
which only those variables were selected which can impact the sales and profit of superstore. All
the numeric variables were recorded in columns which are Sum of Order Quantity, Sum of Sales,
Sum of Discount, Sum of Profit, Sum of Unit Price, Sum of Shipping Cost , Sum of Product Base
Margin and all the numeric variables were recorded in rows which are order date, shipment mode
and customer segment.
Data analysis and visualisation
After pre processing of data, it is important to analyse and visualise the data. Data analysis
is a procedure in which data is mined so that additional information from that data can be gained
(Olszak and Batko, 2012). Consequently, data visualisation is a procedure which presents the
mined data using graphs and tables.
The software application of Microsoft Excel is used to analyse and visualise the data. The
data set of Superstore is analysed by the Excel function of SUM(); using this function total of all
numeric variables is calculated and then presented in a table, line graphs and bar charts so that
patterns can be tracked.
Sum of
Sales
Sum of
Profit
Sum of
Discount
Sum of
Shipping
Cost
Sum of
Unit Price
Sum of
Order
Quantity
Sum of
product base
price
2009 4209896.846 434096.02 105.39 28481.76 232830.98 54508 1113.692724
2010 3560087.045 364917.33 105.81 27354.26 162467.59 54379 1099.900106
2
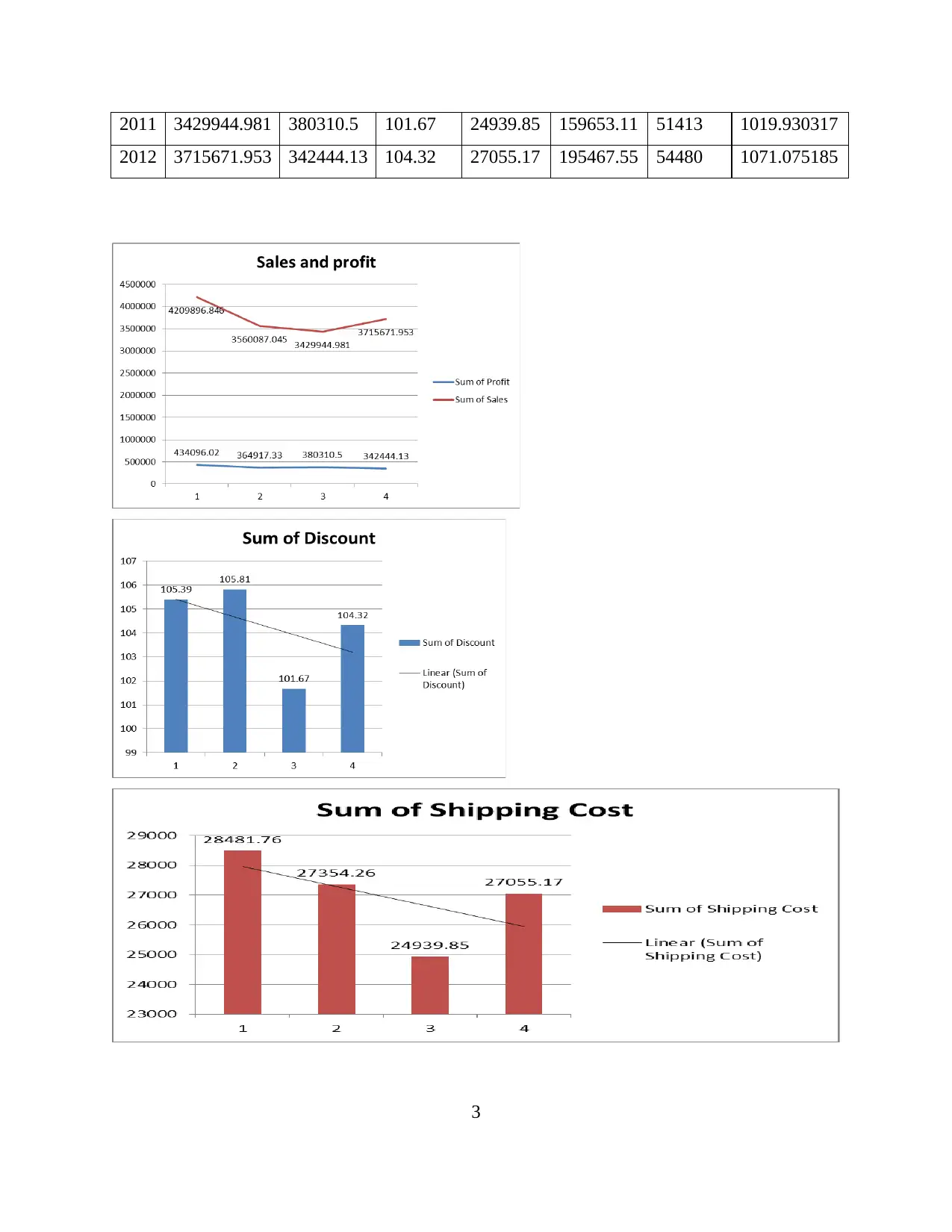
2011 3429944.981 380310.5 101.67 24939.85 159653.11 51413 1019.930317
2012 3715671.953 342444.13 104.32 27055.17 195467.55 54480 1071.075185
3
2012 3715671.953 342444.13 104.32 27055.17 195467.55 54480 1071.075185
3
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
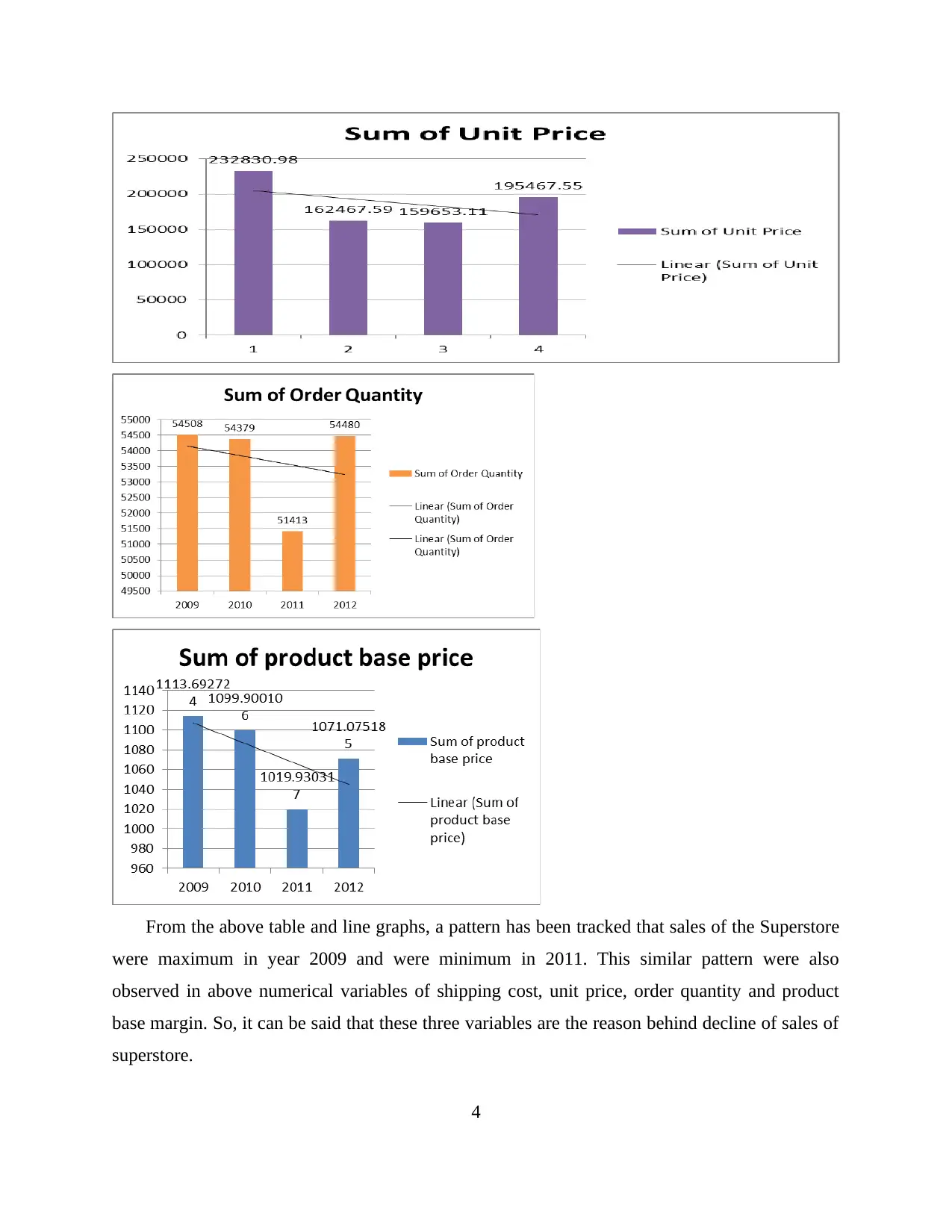
From the above table and line graphs, a pattern has been tracked that sales of the Superstore
were maximum in year 2009 and were minimum in 2011. This similar pattern were also
observed in above numerical variables of shipping cost, unit price, order quantity and product
base margin. So, it can be said that these three variables are the reason behind decline of sales of
superstore.
4
were maximum in year 2009 and were minimum in 2011. This similar pattern were also
observed in above numerical variables of shipping cost, unit price, order quantity and product
base margin. So, it can be said that these three variables are the reason behind decline of sales of
superstore.
4
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
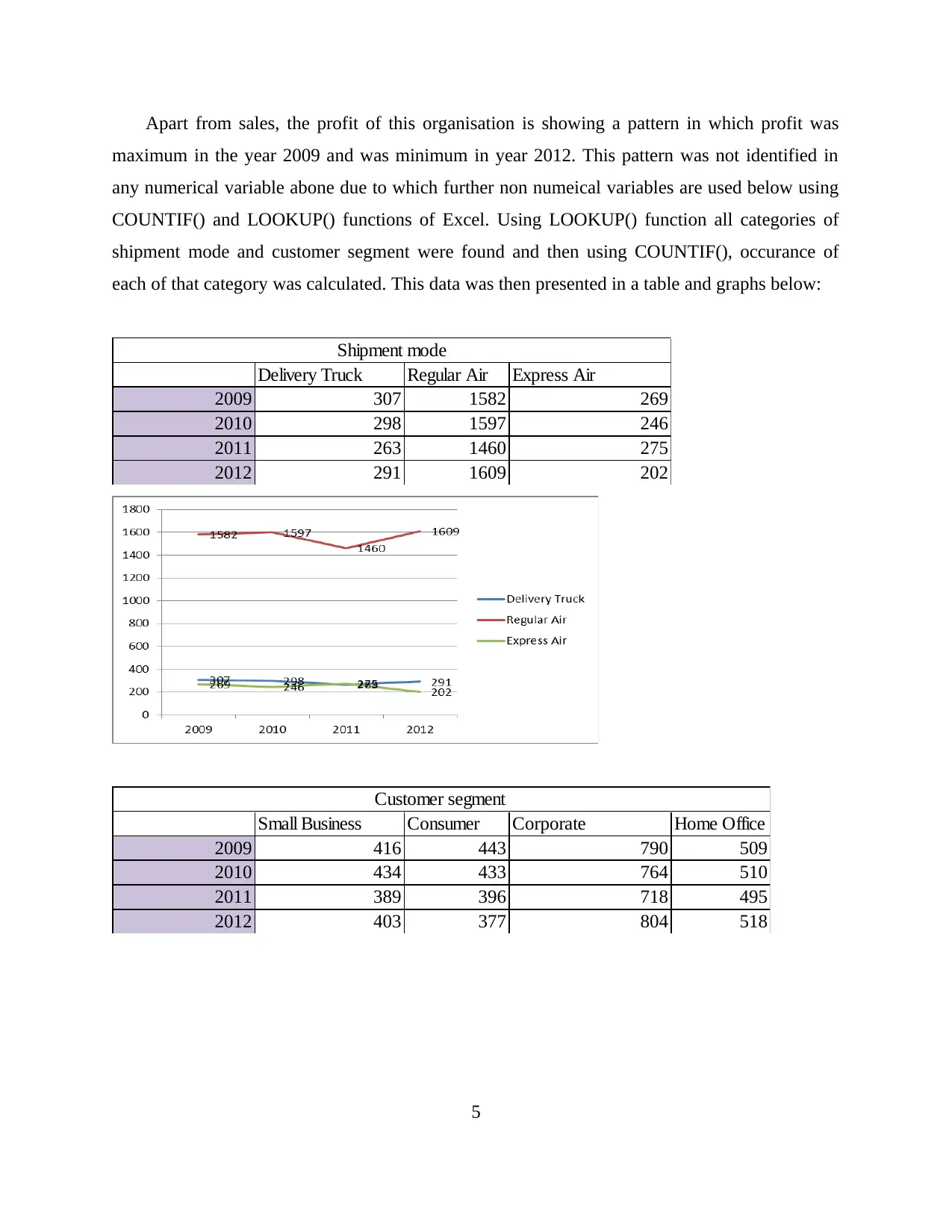
Apart from sales, the profit of this organisation is showing a pattern in which profit was
maximum in the year 2009 and was minimum in year 2012. This pattern was not identified in
any numerical variable abone due to which further non numeical variables are used below using
COUNTIF() and LOOKUP() functions of Excel. Using LOOKUP() function all categories of
shipment mode and customer segment were found and then using COUNTIF(), occurance of
each of that category was calculated. This data was then presented in a table and graphs below:
Delivery Truck Regular Air Express Air
2009 307 1582 269
2010 298 1597 246
2011 263 1460 275
2012 291 1609 202
Shipment mode
Small Business Consumer Corporate Home Office
2009 416 443 790 509
2010 434 433 764 510
2011 389 396 718 495
2012 403 377 804 518
Customer segment
5
maximum in the year 2009 and was minimum in year 2012. This pattern was not identified in
any numerical variable abone due to which further non numeical variables are used below using
COUNTIF() and LOOKUP() functions of Excel. Using LOOKUP() function all categories of
shipment mode and customer segment were found and then using COUNTIF(), occurance of
each of that category was calculated. This data was then presented in a table and graphs below:
Delivery Truck Regular Air Express Air
2009 307 1582 269
2010 298 1597 246
2011 263 1460 275
2012 291 1609 202
Shipment mode
Small Business Consumer Corporate Home Office
2009 416 443 790 509
2010 434 433 764 510
2011 389 396 718 495
2012 403 377 804 518
Customer segment
5
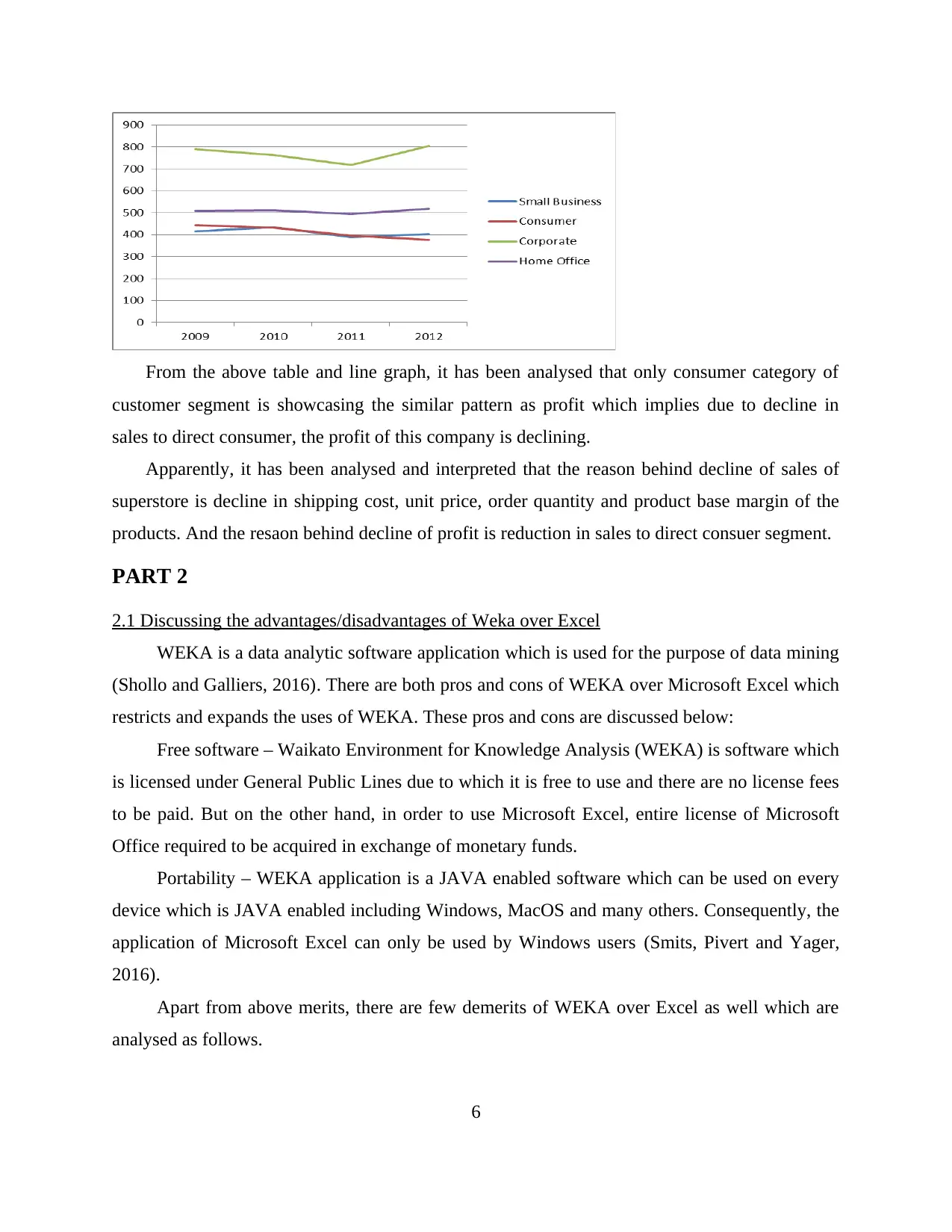
From the above table and line graph, it has been analysed that only consumer category of
customer segment is showcasing the similar pattern as profit which implies due to decline in
sales to direct consumer, the profit of this company is declining.
Apparently, it has been analysed and interpreted that the reason behind decline of sales of
superstore is decline in shipping cost, unit price, order quantity and product base margin of the
products. And the resaon behind decline of profit is reduction in sales to direct consuer segment.
PART 2
2.1 Discussing the advantages/disadvantages of Weka over Excel
WEKA is a data analytic software application which is used for the purpose of data mining
(Shollo and Galliers, 2016). There are both pros and cons of WEKA over Microsoft Excel which
restricts and expands the uses of WEKA. These pros and cons are discussed below:
Free software – Waikato Environment for Knowledge Analysis (WEKA) is software which
is licensed under General Public Lines due to which it is free to use and there are no license fees
to be paid. But on the other hand, in order to use Microsoft Excel, entire license of Microsoft
Office required to be acquired in exchange of monetary funds.
Portability – WEKA application is a JAVA enabled software which can be used on every
device which is JAVA enabled including Windows, MacOS and many others. Consequently, the
application of Microsoft Excel can only be used by Windows users (Smits, Pivert and Yager,
2016).
Apart from above merits, there are few demerits of WEKA over Excel as well which are
analysed as follows.
6
customer segment is showcasing the similar pattern as profit which implies due to decline in
sales to direct consumer, the profit of this company is declining.
Apparently, it has been analysed and interpreted that the reason behind decline of sales of
superstore is decline in shipping cost, unit price, order quantity and product base margin of the
products. And the resaon behind decline of profit is reduction in sales to direct consuer segment.
PART 2
2.1 Discussing the advantages/disadvantages of Weka over Excel
WEKA is a data analytic software application which is used for the purpose of data mining
(Shollo and Galliers, 2016). There are both pros and cons of WEKA over Microsoft Excel which
restricts and expands the uses of WEKA. These pros and cons are discussed below:
Free software – Waikato Environment for Knowledge Analysis (WEKA) is software which
is licensed under General Public Lines due to which it is free to use and there are no license fees
to be paid. But on the other hand, in order to use Microsoft Excel, entire license of Microsoft
Office required to be acquired in exchange of monetary funds.
Portability – WEKA application is a JAVA enabled software which can be used on every
device which is JAVA enabled including Windows, MacOS and many others. Consequently, the
application of Microsoft Excel can only be used by Windows users (Smits, Pivert and Yager,
2016).
Apart from above merits, there are few demerits of WEKA over Excel as well which are
analysed as follows.
6
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

Reliability – The application of WEKA does not have valid documentation and security
enabled system, which increases the chances of hacking. Due to this WEKA is considered as less
reliable than Microsoft Excel.
Restricted Memory – WEKA application is only enabled to store limited data due to which
it is not used for the purpose of data warehousing. On the other hand, Microsoft Excel is even
appropriate for big data analysis and warehousing. Due to this, data of Superstore which has big
data was analysed using Microsoft Excel and audidealership data is analysed using WEKA as it
only has 100 queries (Zulkefli and et.al., 2016).
From the above discussion, it has been analysed that a small business like Audi dealership
can use WEKA software for data analysis as it is appropriate for their small data and will also
provide them benefit of low costs.
2.2 Explaining the data mining methods that can be used in business with real world examples
Data mining methods are used by business organisations to use their data for the purpose
of decision making. Few of these methods are explained below along with real life examples:
Tracking patterns – Users of data mining software can use functions of tables and graphs to
identify the patterns in data set. This method is used by showrooms of cars to identify which car
model is most looked over by their visitors.
Clustering – This method of data mining is much more complex and involves multiple
steps. There are various types of clustering such as k means clustering which are used to identify
clusters between the data. This method is used in this report for Audi dealership organisation.
Regression – This method is considered as most reliable methods of data analysis as it does
not only helps in identifying the relationship between two variables but also allows to identity
the nature and strength of the relationships. In real life, this method is used by investigators to
identify the relationship between independent and dependent variable of their investigation
(Jayaram and Singal, 2017).
2.2.2 Weka clustering
As analysed above, WEKA is analytic software which can be used for the purpose of
clustering. The k means clustering is used in this method by selecting “2” as the number of
clusters.
=== Run information ===
7
enabled system, which increases the chances of hacking. Due to this WEKA is considered as less
reliable than Microsoft Excel.
Restricted Memory – WEKA application is only enabled to store limited data due to which
it is not used for the purpose of data warehousing. On the other hand, Microsoft Excel is even
appropriate for big data analysis and warehousing. Due to this, data of Superstore which has big
data was analysed using Microsoft Excel and audidealership data is analysed using WEKA as it
only has 100 queries (Zulkefli and et.al., 2016).
From the above discussion, it has been analysed that a small business like Audi dealership
can use WEKA software for data analysis as it is appropriate for their small data and will also
provide them benefit of low costs.
2.2 Explaining the data mining methods that can be used in business with real world examples
Data mining methods are used by business organisations to use their data for the purpose
of decision making. Few of these methods are explained below along with real life examples:
Tracking patterns – Users of data mining software can use functions of tables and graphs to
identify the patterns in data set. This method is used by showrooms of cars to identify which car
model is most looked over by their visitors.
Clustering – This method of data mining is much more complex and involves multiple
steps. There are various types of clustering such as k means clustering which are used to identify
clusters between the data. This method is used in this report for Audi dealership organisation.
Regression – This method is considered as most reliable methods of data analysis as it does
not only helps in identifying the relationship between two variables but also allows to identity
the nature and strength of the relationships. In real life, this method is used by investigators to
identify the relationship between independent and dependent variable of their investigation
(Jayaram and Singal, 2017).
2.2.2 Weka clustering
As analysed above, WEKA is analytic software which can be used for the purpose of
clustering. The k means clustering is used in this method by selecting “2” as the number of
clusters.
=== Run information ===
7
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Scheme:weka.clusterers.SimpleKMeans -N 2 -A "weka.core.EuclideanDistance -R first-last" -I
500 -S 10
Relation: audidealership2
Instances: 100
Attributes: 8
Dealership
Showroom
InternetSearch
RS7
A4
TT
Financing
Purchase
Test mode:evaluate on training data
=== Model and evaluation on training set ===
kMeans
======
Number of iterations: 6
Within cluster sum of squared errors: 160.2980769230769
Missing values globally replaced with mean/mode
Cluster centroids:
Cluster#
Attribute Full Data 0 1
(100) (48) (52)
8
500 -S 10
Relation: audidealership2
Instances: 100
Attributes: 8
Dealership
Showroom
InternetSearch
RS7
A4
TT
Financing
Purchase
Test mode:evaluate on training data
=== Model and evaluation on training set ===
kMeans
======
Number of iterations: 6
Within cluster sum of squared errors: 160.2980769230769
Missing values globally replaced with mean/mode
Cluster centroids:
Cluster#
Attribute Full Data 0 1
(100) (48) (52)
8
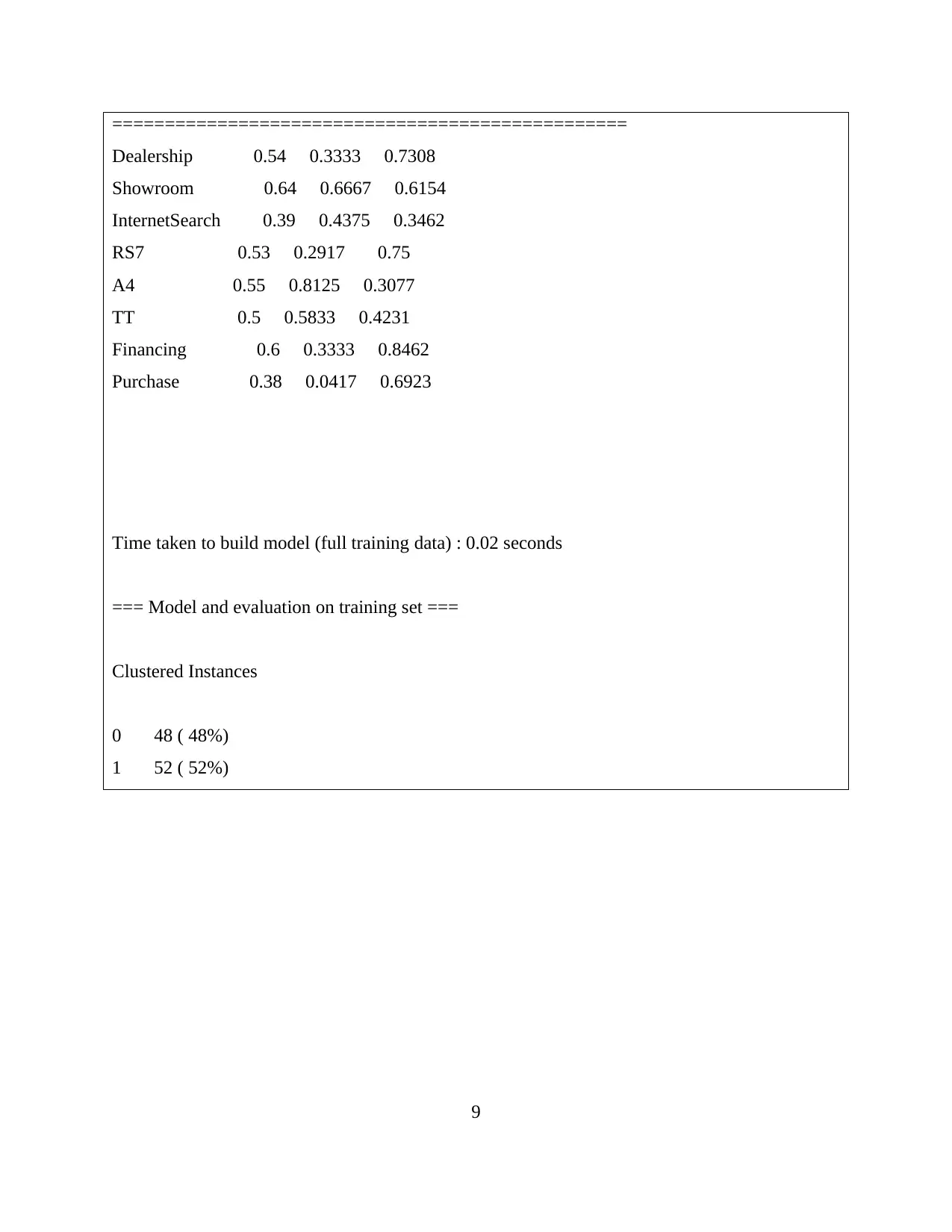
=================================================
Dealership 0.54 0.3333 0.7308
Showroom 0.64 0.6667 0.6154
InternetSearch 0.39 0.4375 0.3462
RS7 0.53 0.2917 0.75
A4 0.55 0.8125 0.3077
TT 0.5 0.5833 0.4231
Financing 0.6 0.3333 0.8462
Purchase 0.38 0.0417 0.6923
Time taken to build model (full training data) : 0.02 seconds
=== Model and evaluation on training set ===
Clustered Instances
0 48 ( 48%)
1 52 ( 52%)
9
Dealership 0.54 0.3333 0.7308
Showroom 0.64 0.6667 0.6154
InternetSearch 0.39 0.4375 0.3462
RS7 0.53 0.2917 0.75
A4 0.55 0.8125 0.3077
TT 0.5 0.5833 0.4231
Financing 0.6 0.3333 0.8462
Purchase 0.38 0.0417 0.6923
Time taken to build model (full training data) : 0.02 seconds
=== Model and evaluation on training set ===
Clustered Instances
0 48 ( 48%)
1 52 ( 52%)
9
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 15
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.