Report on Data Mining and Visualization for Business Intelligence
VerifiedAdded on 2020/03/23
|7
|1204
|86
Report
AI Summary
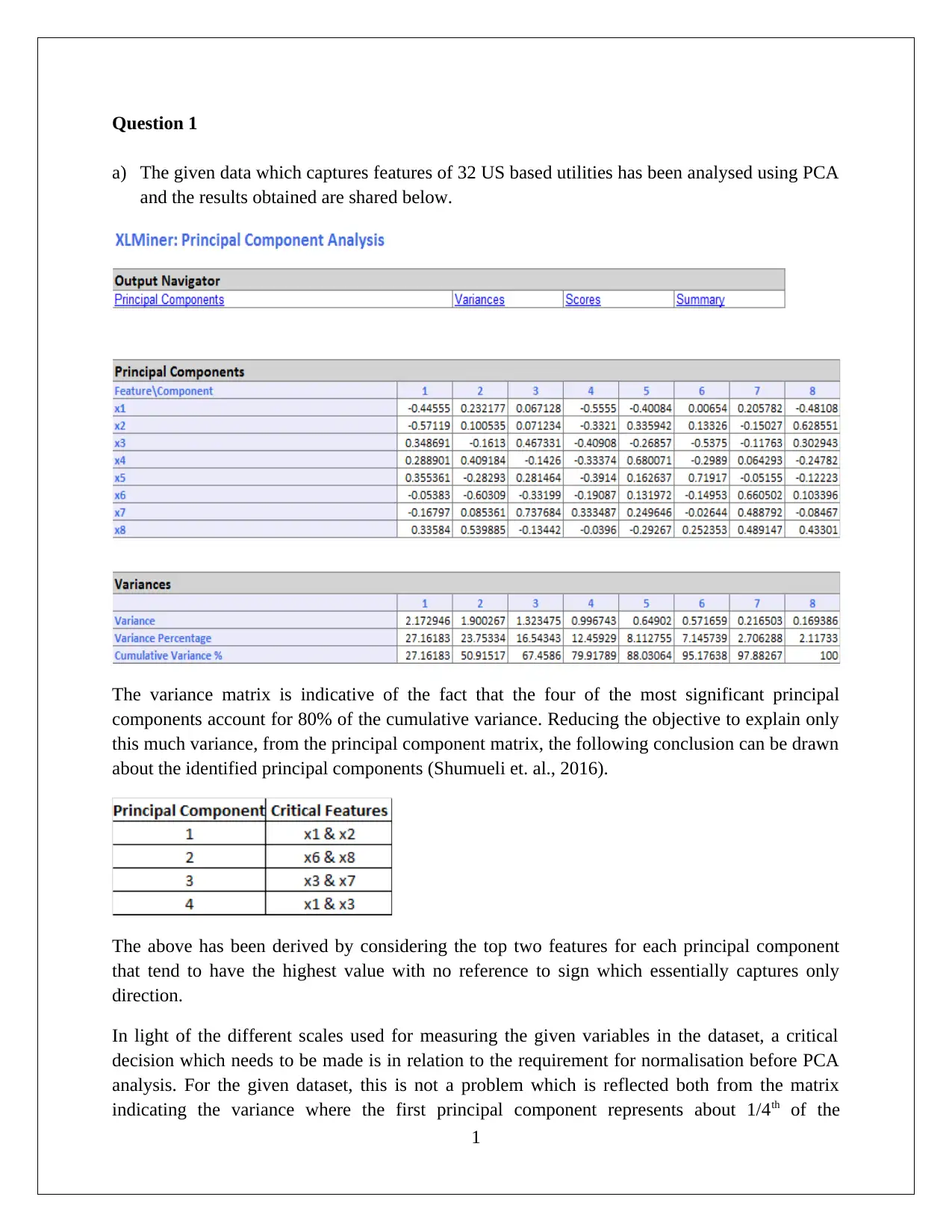
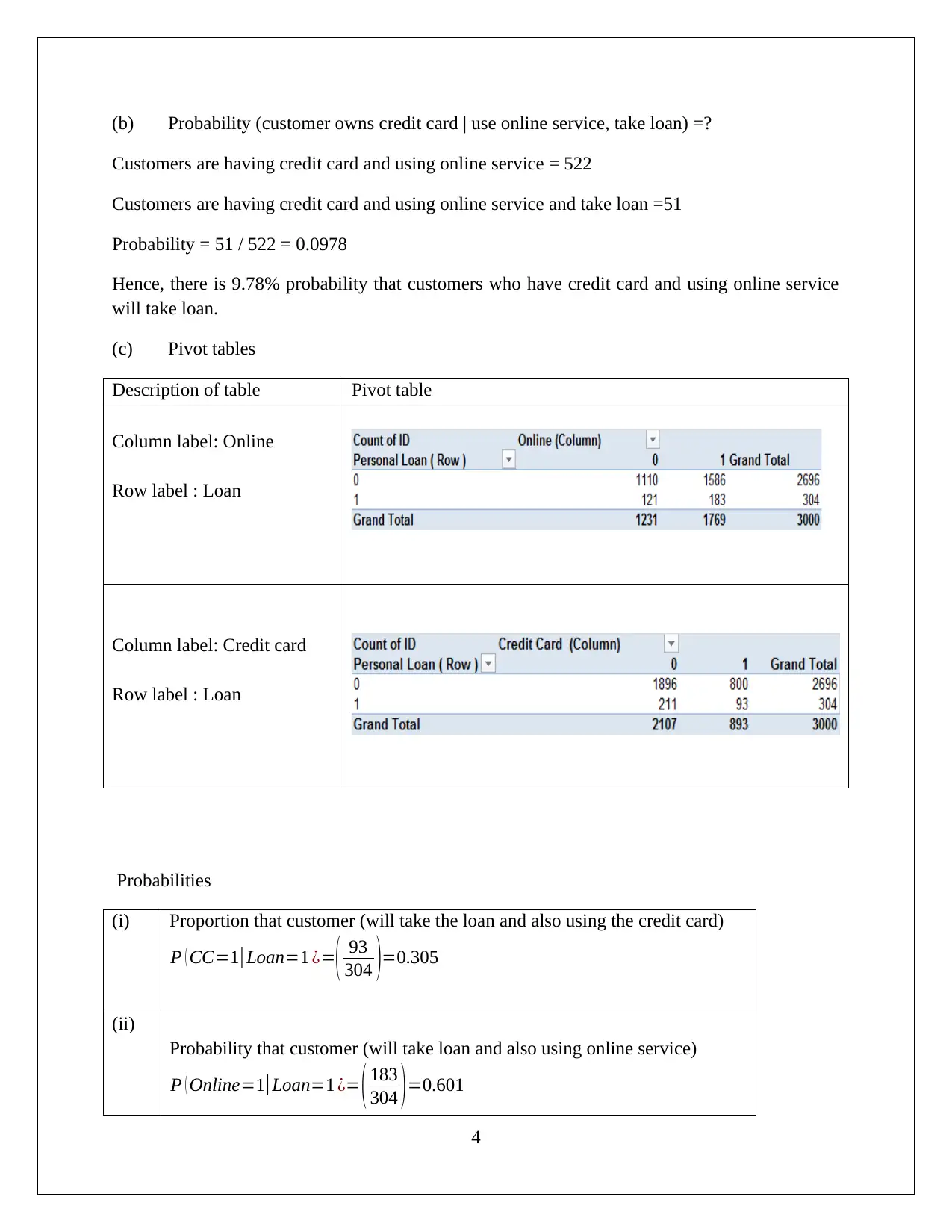
This report analyzes data mining and visualization techniques in the context of business intelligence. It examines a dataset of 32 US utilities using Principal Component Analysis (PCA), concluding that data normalization is not required. The report discusses the advantages and disadvantages of PCA, highlighting its utility in simplifying complex data while noting limitations in capturing non-linear relationships. Furthermore, the report uses pivot tables and probability calculations to analyze customer data from Universal Bank, focusing on the relationship between online service usage, credit card ownership, and personal loan acceptance. Naive Bayes probability is applied to identify the best strategy for loan offers, concluding that customers with credit cards and active online service usage have a higher likelihood of loan acceptance. The analysis provides insights into leveraging data mining for strategic decision-making in the banking sector. Desklib offers a wide array of similar solved assignments and resources for students.





1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.