Data Mining Business Case Analysis: PCA, Naive Bayes, and Strategy
VerifiedAdded on 2020/04/01
|8
|1115
|66
Project
AI Summary
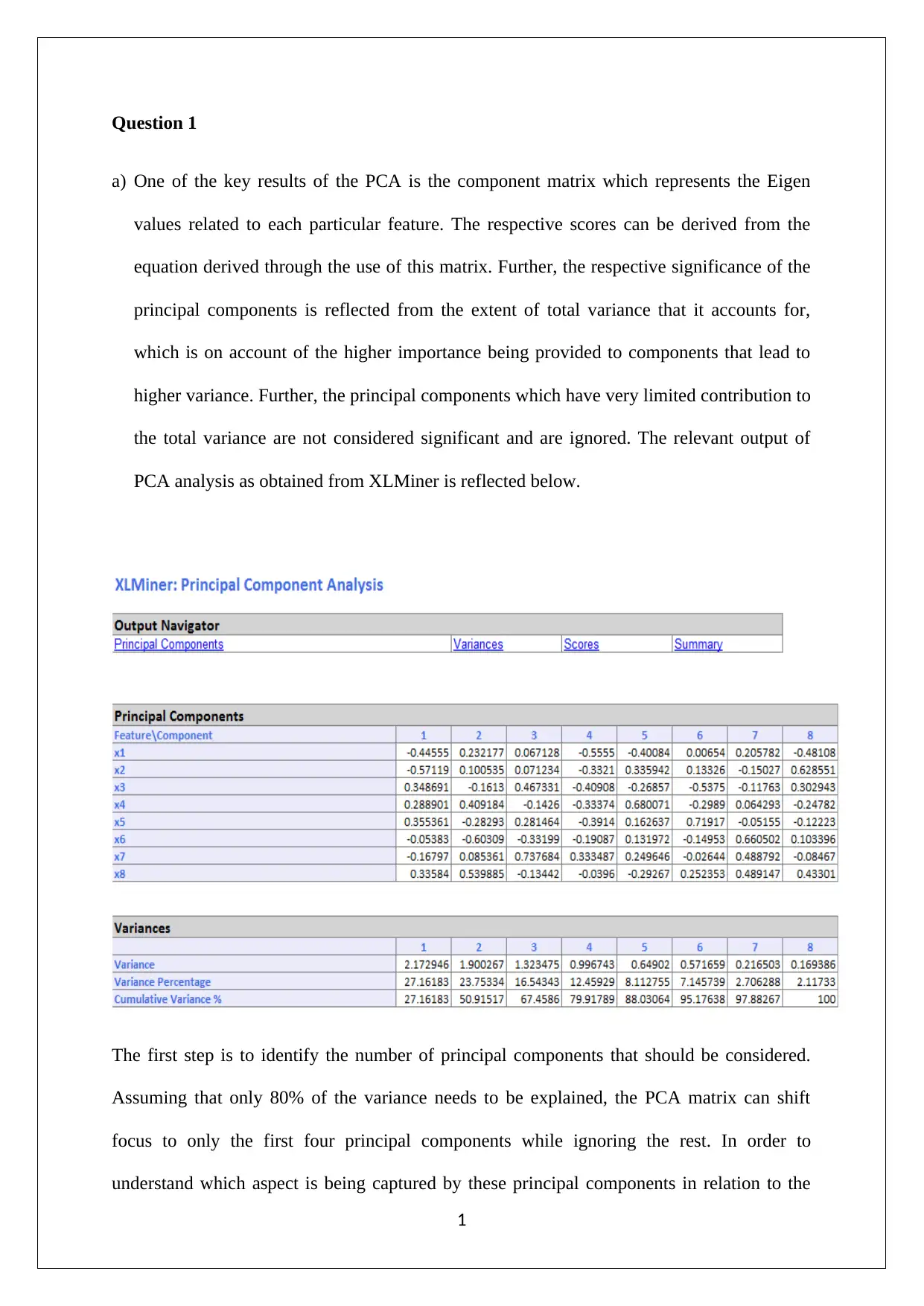
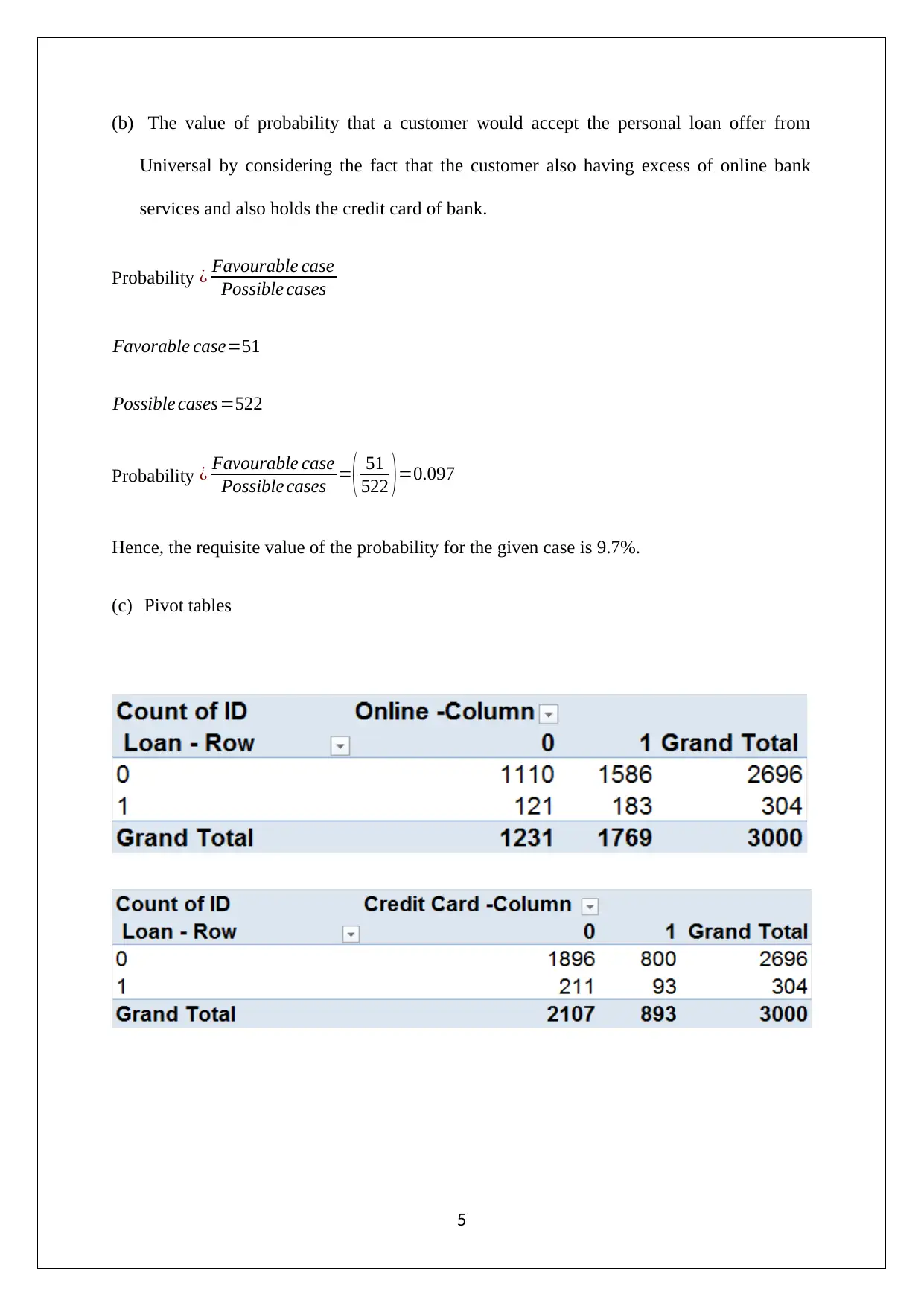
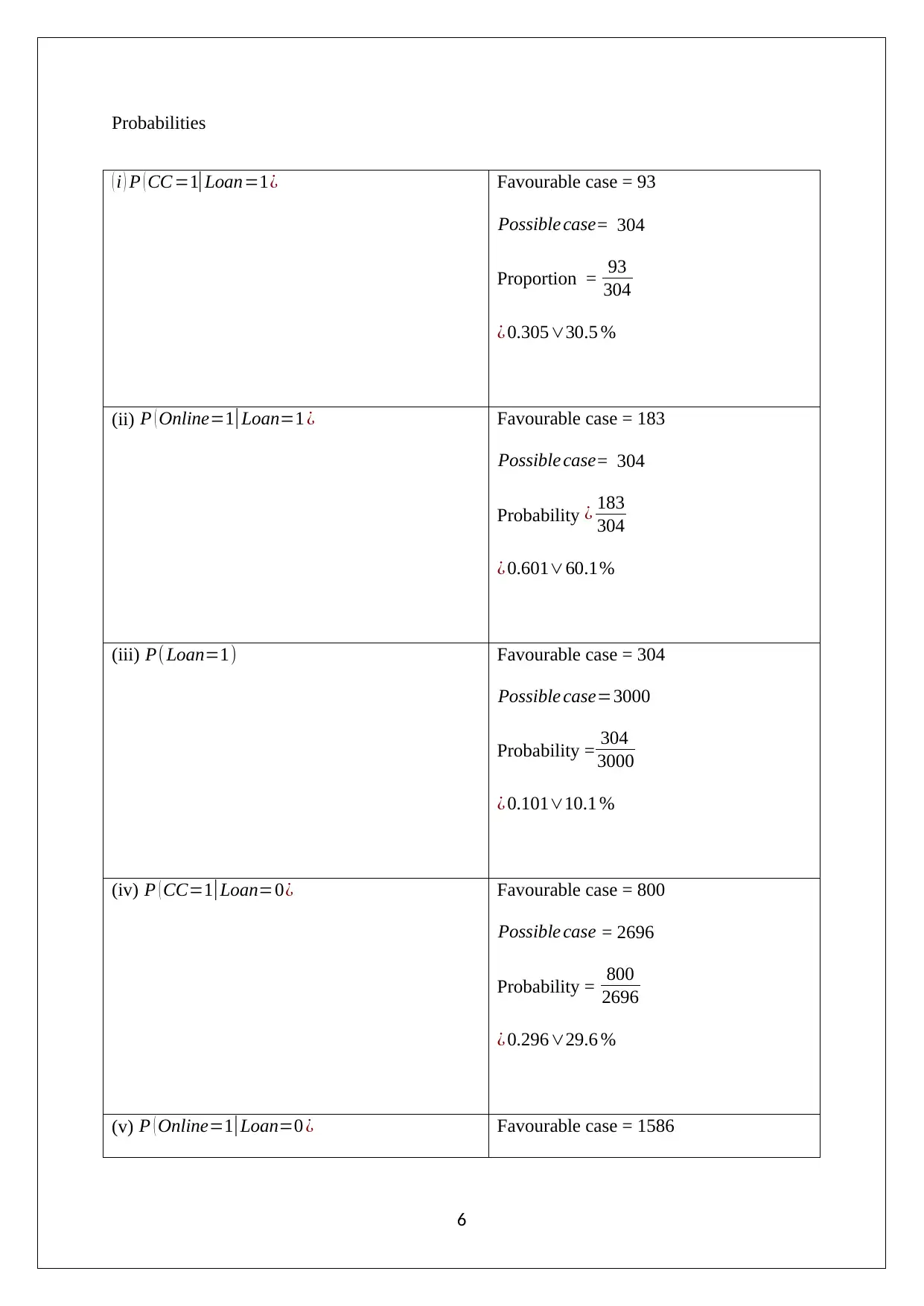
This assignment presents a data mining business case analysis, focusing on Principal Component Analysis (PCA) and Naive Bayes techniques. The analysis begins with an examination of PCA, including the identification of significant principal components and their relation to firm performance, financial returns, operational efficiency, and variable electricity costs. It addresses normalization issues and outlines the advantages and limitations of PCA. The second part of the assignment utilizes the XLMiner tool to generate training data and explores customer behavior in relation to loan acceptance, online banking services, and credit card usage. Pivot tables and Naive Bayes probability calculations are used to determine the best customer strategy to increase the probability of loan acceptance. The analysis concludes with the identification of the optimal customer strategy based on the computed probabilities.





1 out of 8
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.