Data Mining and Visualization for Business Intelligence Report
VerifiedAdded on 2023/06/08
|14
|1554
|444
Report
AI Summary
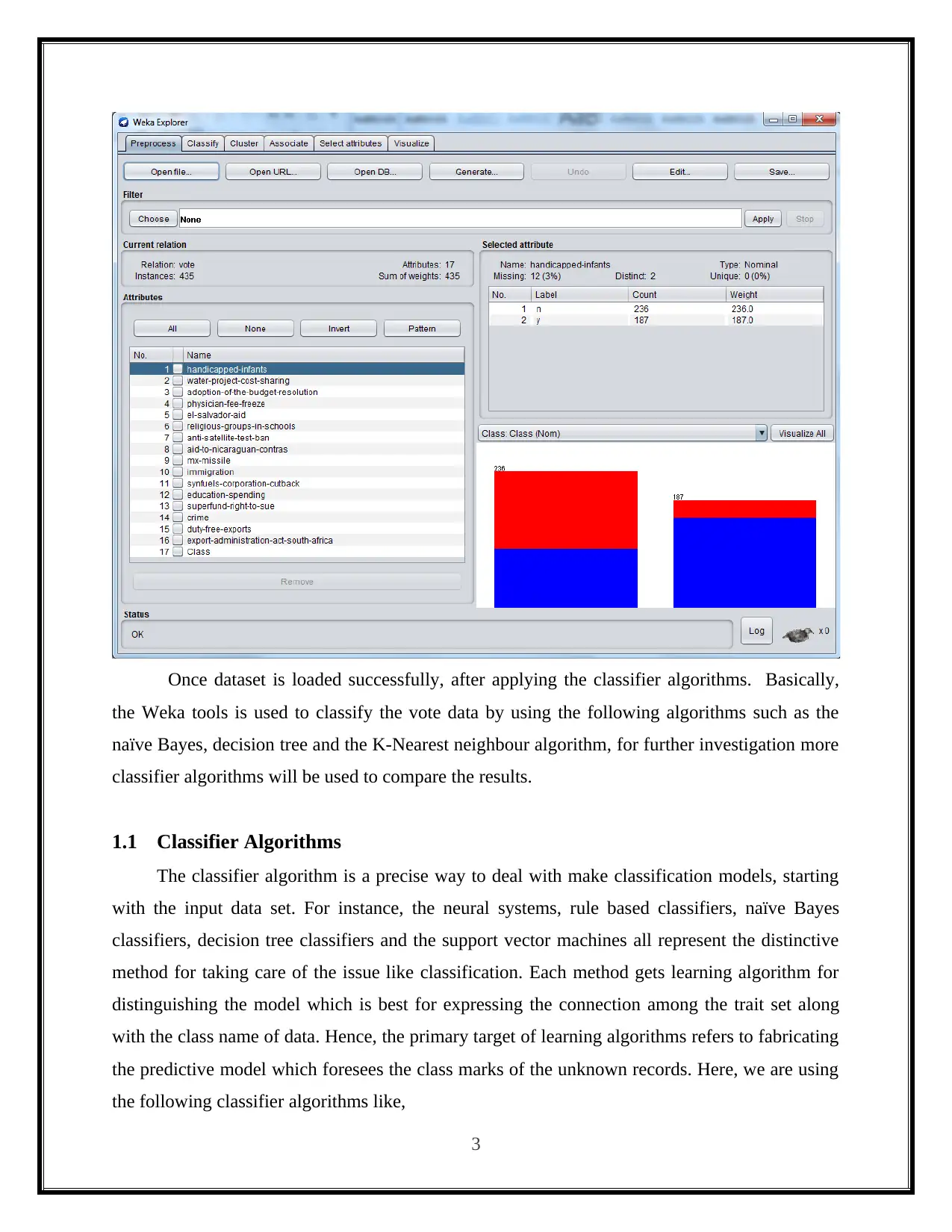
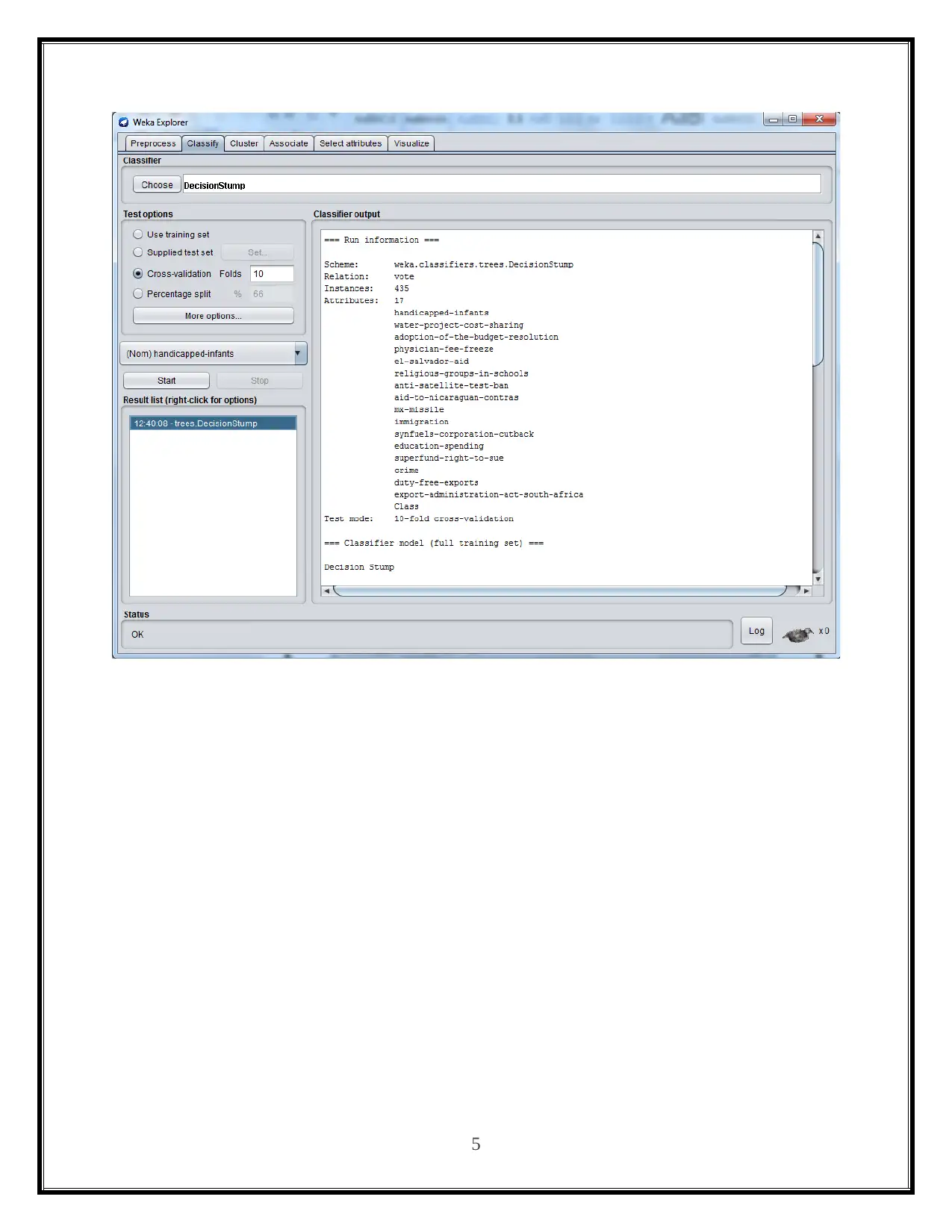
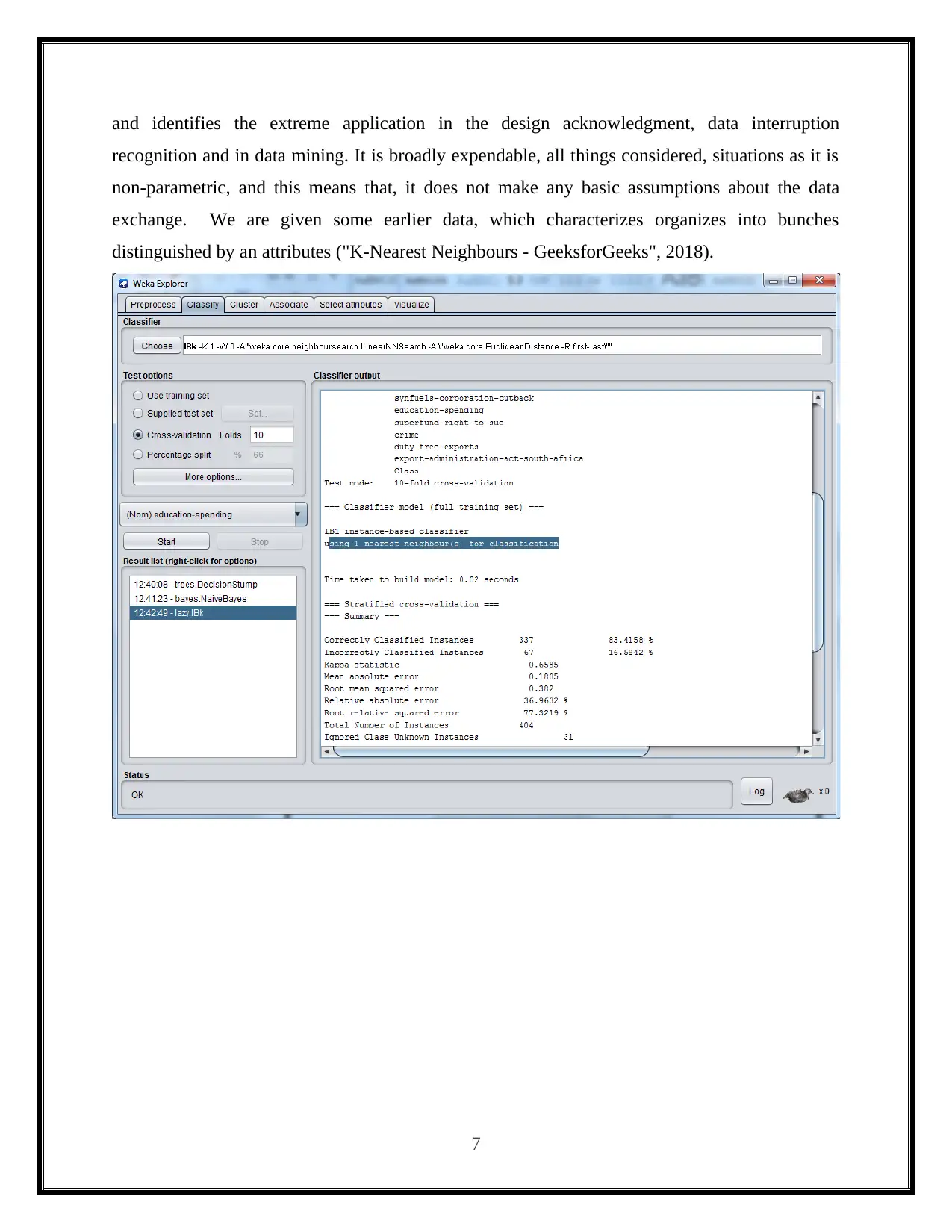
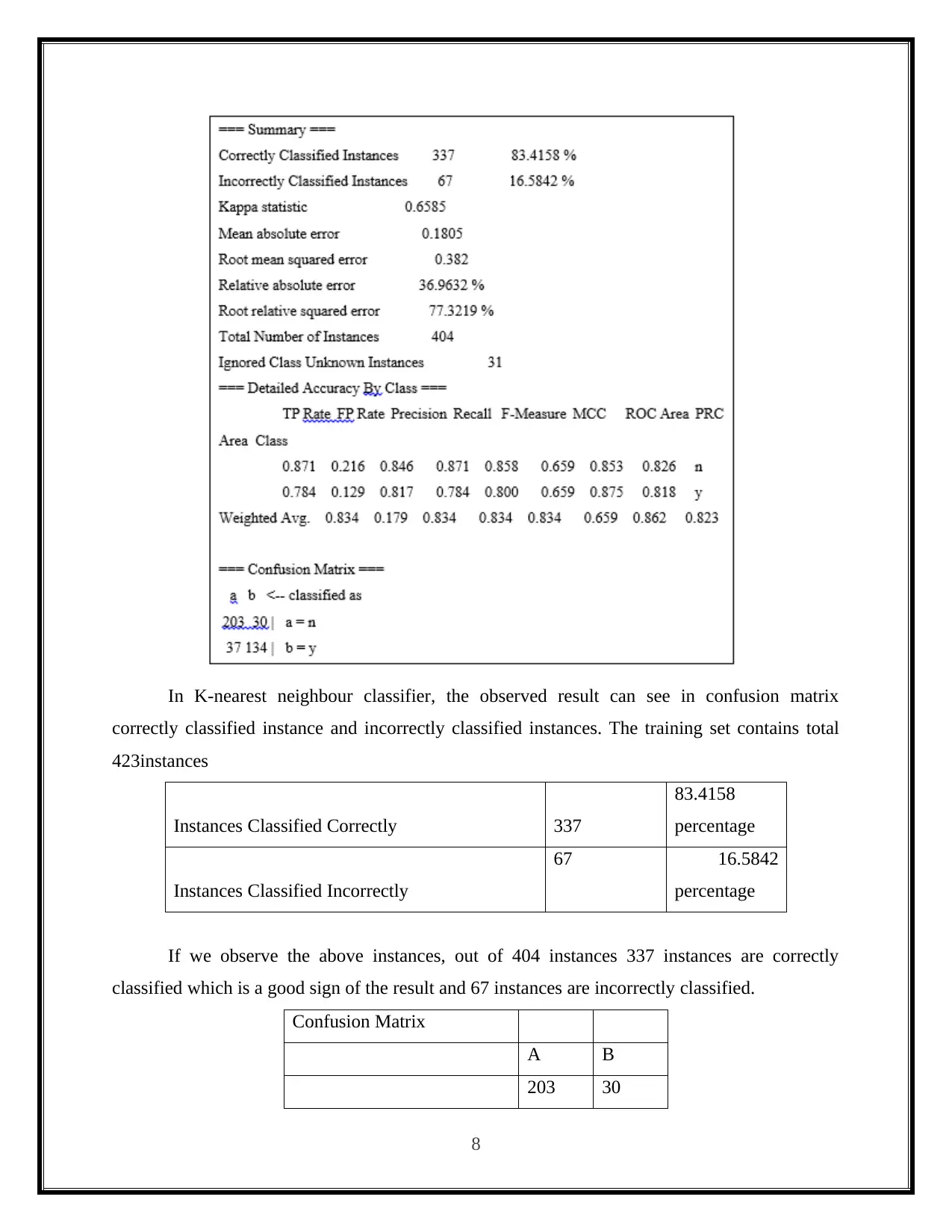
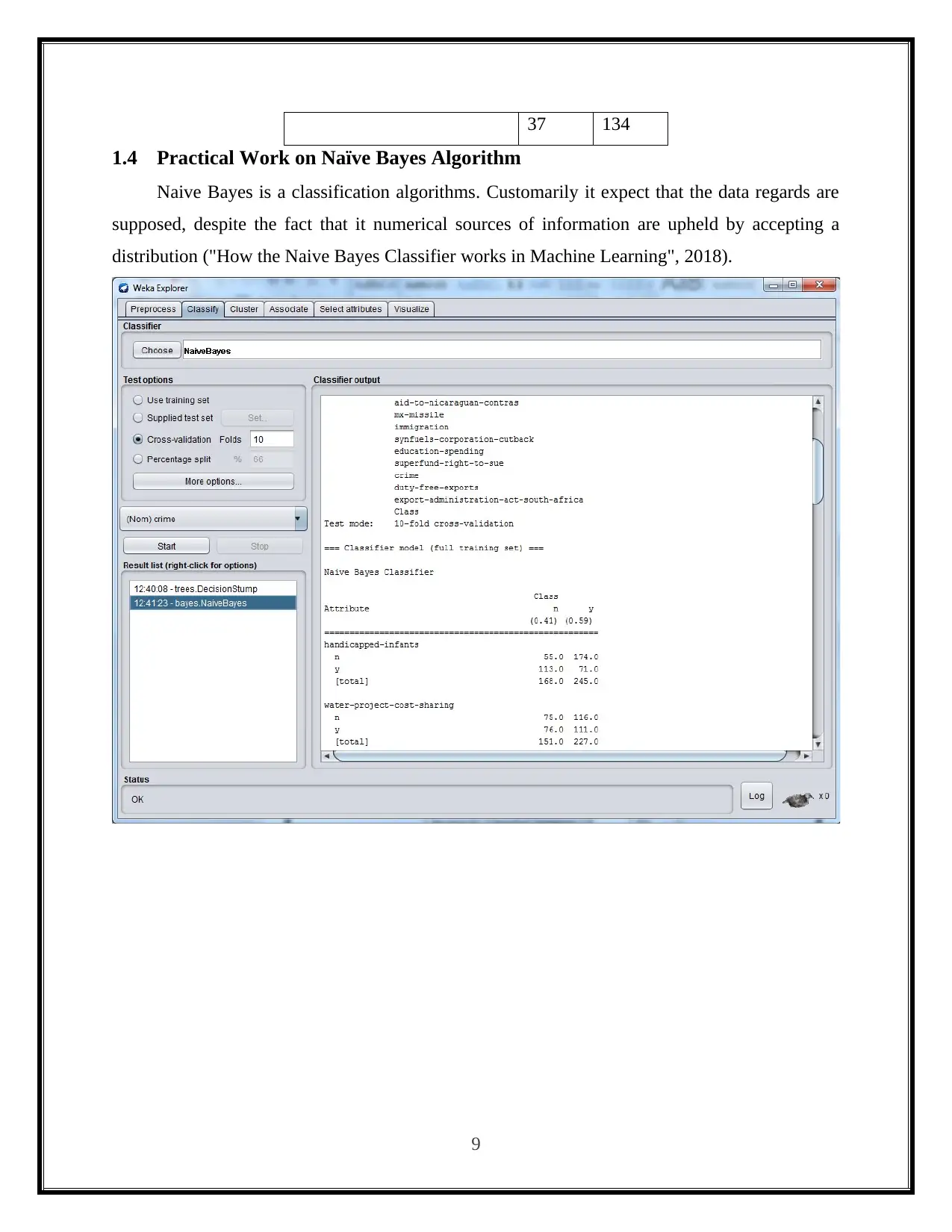
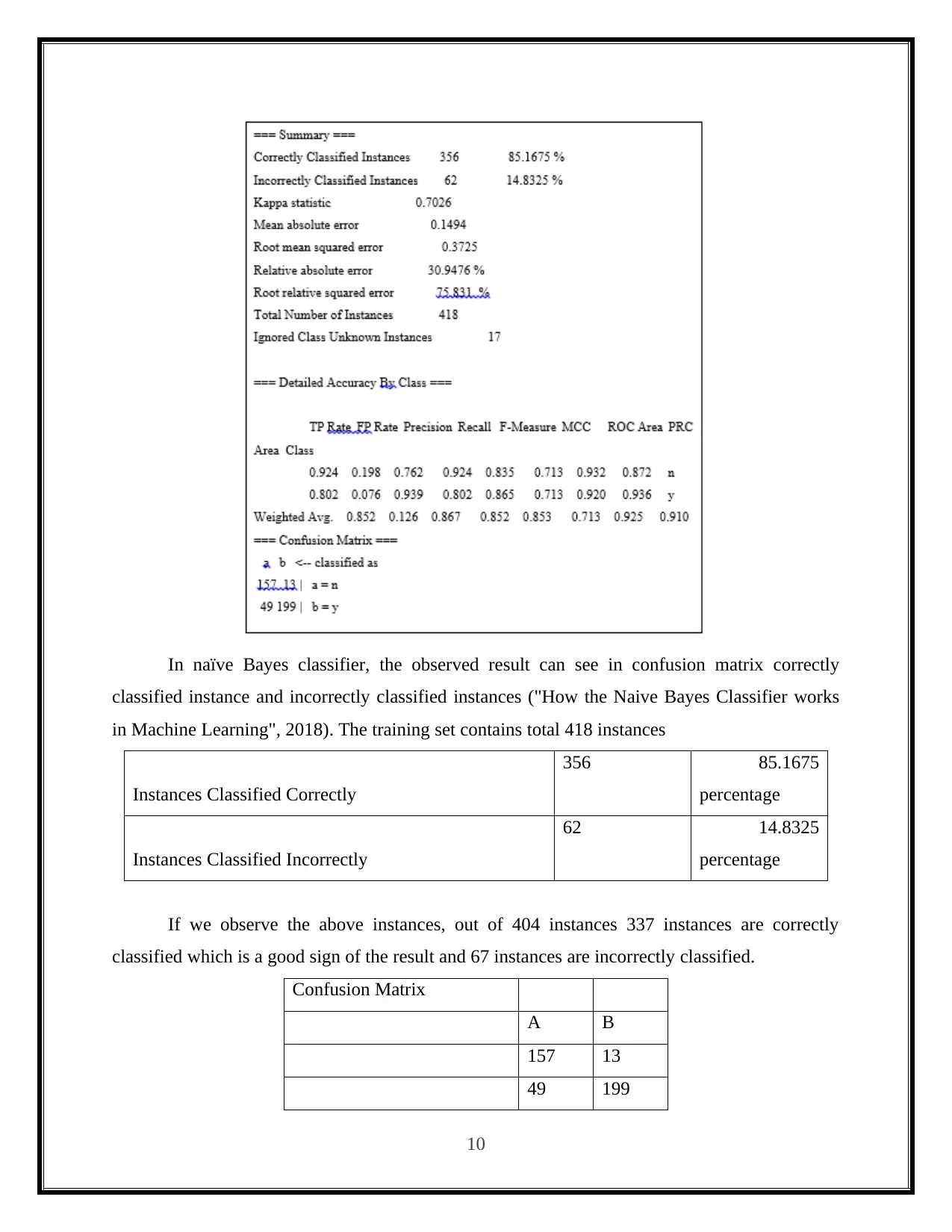
This report presents a practical analysis of data mining and visualization techniques for business intelligence, focusing on the application of classifier algorithms using the Weka software. The study involves loading the 'vote.arff' dataset into Weka and comparing the performance of three classification algorithms: Decision Tree, Naive Bayes, and K-Nearest Neighbor. The report details the practical implementation of each algorithm, including screenshots of the Weka tool and the resulting confusion matrices. It discusses the accuracy and performance of each algorithm based on the number of correctly and incorrectly classified instances. The report concludes with a comparative analysis of the three classifiers, highlighting their strengths, weaknesses, and suitability for different classification problems, with references to relevant sources.





1 out of 14
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.