Analysis of Data Structures and Algorithms in Inventory Management
VerifiedAdded on 2022/10/13
|17
|2852
|12
Report
AI Summary
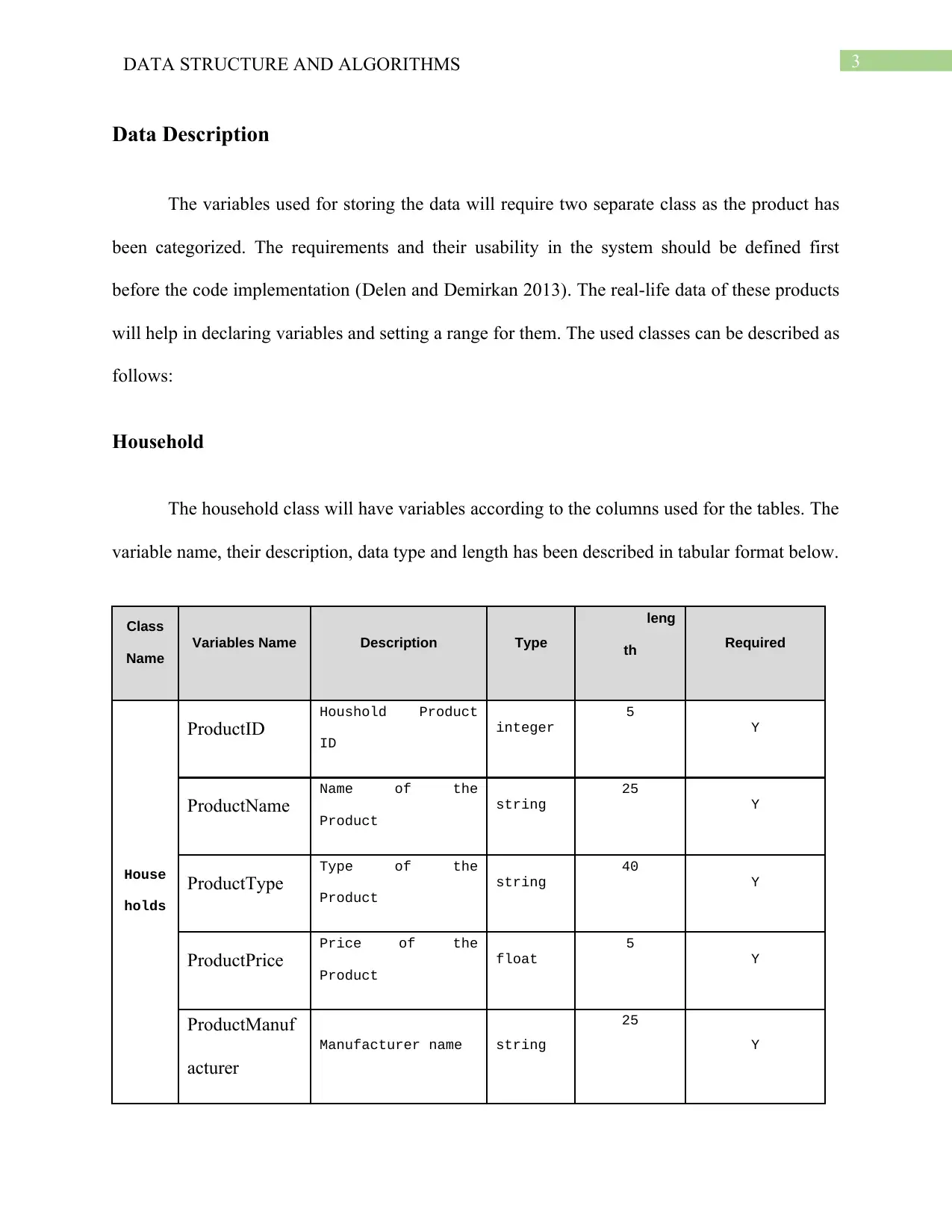
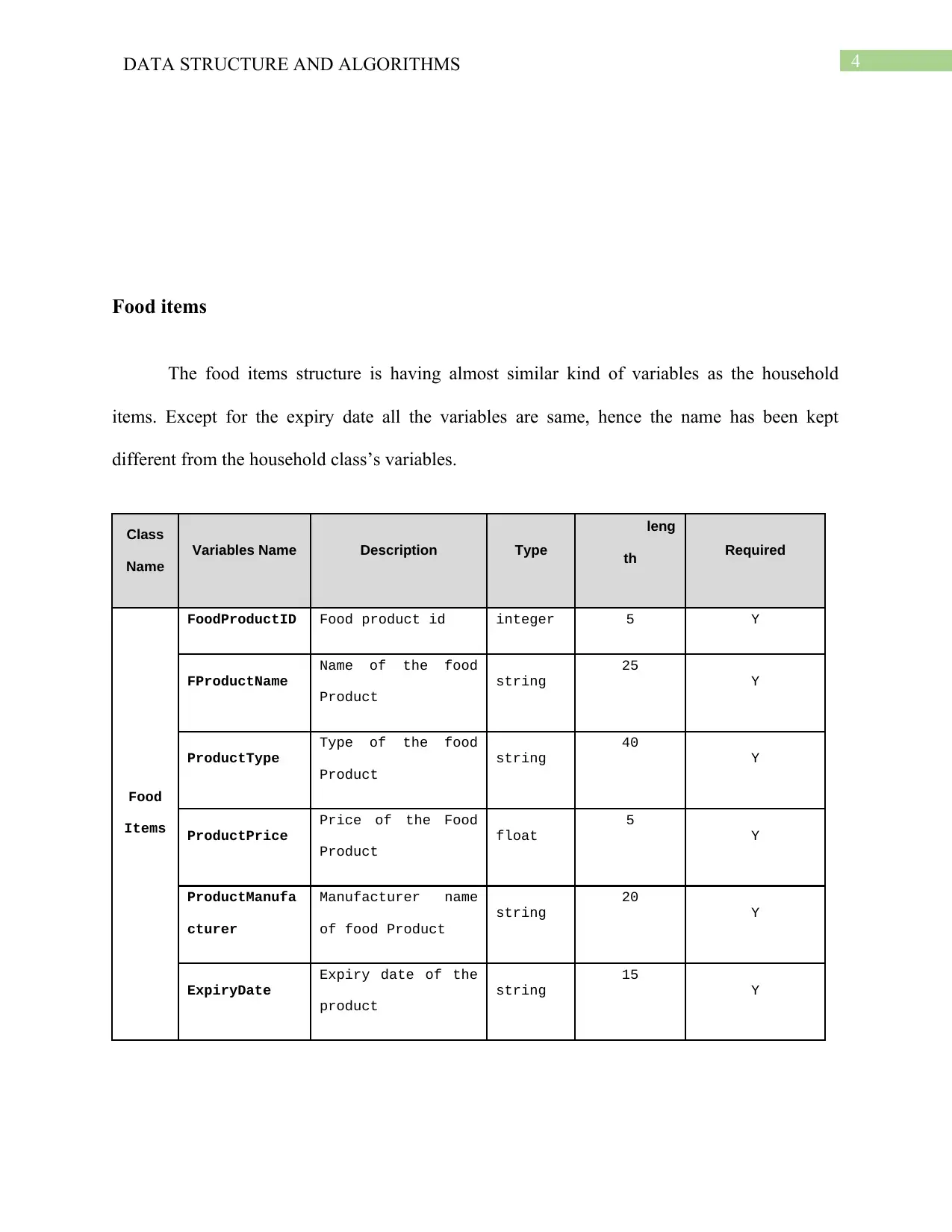
This report provides an in-depth analysis of data structures and algorithms used in an inventory management system for a company dealing with household and food items. It details the data description, including variables for household and food products, and identifies key inventory operations like insert, delete, update, and search. The report then explores appropriate data structures such as arrays and dictionaries with hashing for efficient data storage and retrieval. It discusses the selection of algorithms, including insertion sort, and linear search, along with their implementation. The report emphasizes the use of hash tables and their operations. Finally, it addresses the scalability of the system, suggesting changes like using ArrayLists or resizing hash tables to accommodate larger datasets and increased complexity. The report concludes by highlighting the efficiency and effectiveness of the chosen data structures and algorithms in managing inventory data.










1 out of 17
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.