Exam Solutions for Data Structures and Algorithms
VerifiedAdded on 2023/06/11
|15
|2418
|221
AI Summary
This article provides solutions for exam questions related to data structures and algorithms. Topics covered include binary search trees, stacks, hash maps, and more. The solutions are perfect for students in computer science courses and include code examples.
Contribute Materials
Your contribution can guide someone’s learning journey. Share your
documents today.

Exam Solutions 1
Exam Solutions
Students Name
Institution
Exam Solutions
Students Name
Institution
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Exam Solutions 2
Question 1
a) We start with the first integer (9) as the root node
9
The second integer (5) is less than 9, it is positioned on left side of the parent
node. The third integer (7) is less than 9 but greater than 5 hence it is placed to the
right 5 being its parent node.
9
5
7
15 is greater than 9 and therefore it is placed on the right of the parent node.
9
15 15
7
2 is less than 9 and less than 5 in the left sub tree and it is therefore placed to the
left of 5 as its parent node.
9
5 15
2 7
Question 1
a) We start with the first integer (9) as the root node
9
The second integer (5) is less than 9, it is positioned on left side of the parent
node. The third integer (7) is less than 9 but greater than 5 hence it is placed to the
right 5 being its parent node.
9
5
7
15 is greater than 9 and therefore it is placed on the right of the parent node.
9
15 15
7
2 is less than 9 and less than 5 in the left sub tree and it is therefore placed to the
left of 5 as its parent node.
9
5 15
2 7
Exam Solutions 3
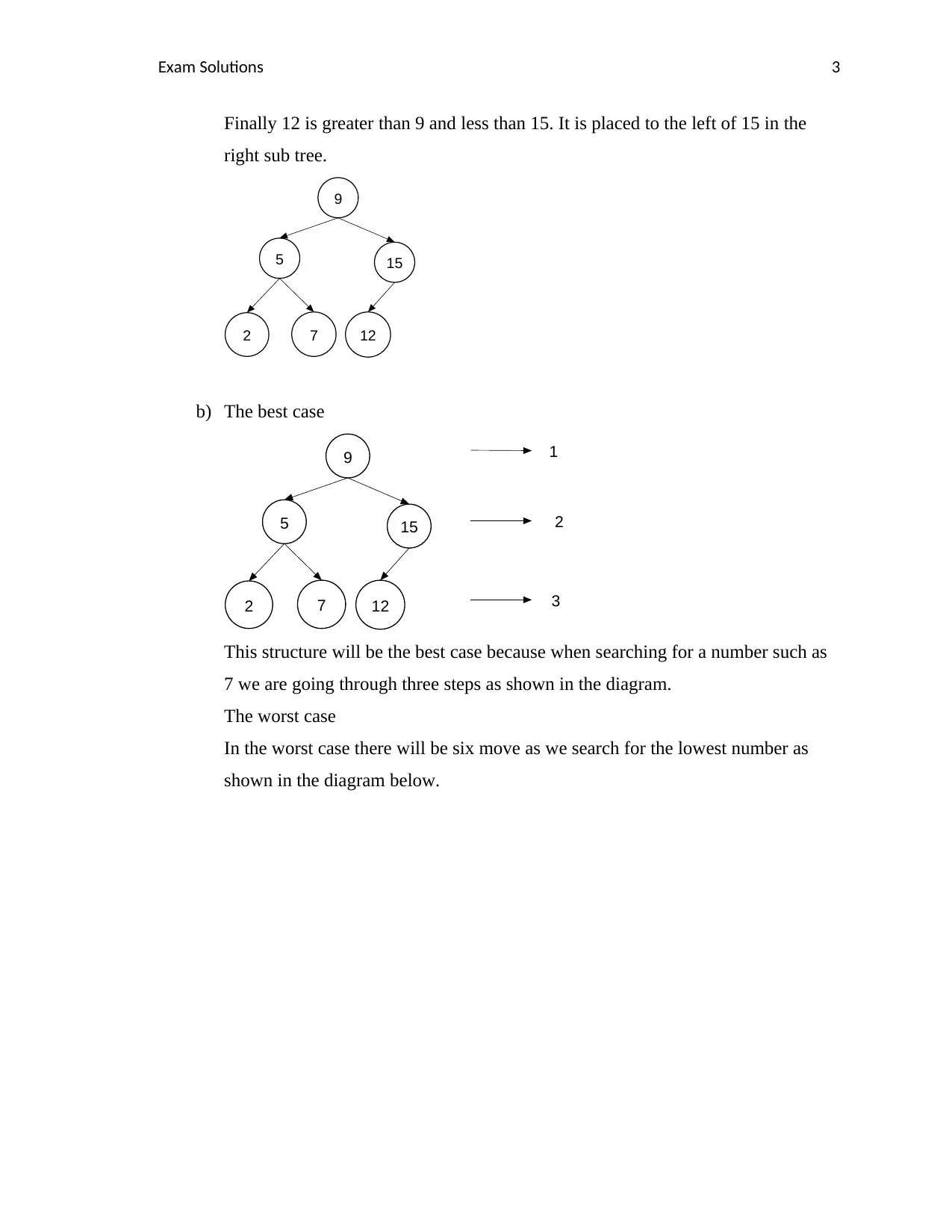
Finally 12 is greater than 9 and less than 15. It is placed to the left of 15 in the
right sub tree.
9
5 15
2 7 12
b) The best case
9
5 15
2 7 12
1
2
3
This structure will be the best case because when searching for a number such as
7 we are going through three steps as shown in the diagram.
The worst case
In the worst case there will be six move as we search for the lowest number as
shown in the diagram below.
Finally 12 is greater than 9 and less than 15. It is placed to the left of 15 in the
right sub tree.
9
5 15
2 7 12
b) The best case
9
5 15
2 7 12
1
2
3
This structure will be the best case because when searching for a number such as
7 we are going through three steps as shown in the diagram.
The worst case
In the worst case there will be six move as we search for the lowest number as
shown in the diagram below.

Exam Solutions 4
9
5
15
2
7
12
1
2
3
4
5
6
c) The linear search algorithm is a less efficient algorithm as compare to the binary
search tree. In this algorithm we sequentially go through the entire list and goes
on until either a match is found or the end of the list is encountered. It has an
average case of 0(N). Binary search tree is faster than the linear search since its
average case is 0(log (N)).
The hash table has an average case of 0(1) in the case whereby one doesn’t know
the size of the input items due to constant retrieve time. But if the items are
continuously added it is better to use binary search tree’s 0(log (N)).
d) For a complete binary search tree to be complete, all the levels must be
completely filled from left to right but not the last level.
The binary search tree created in (a) above is a complete tree since all the nodes
have children except nodes at the lowest level.
9
5
15
2
7
12
1
2
3
4
5
6
c) The linear search algorithm is a less efficient algorithm as compare to the binary
search tree. In this algorithm we sequentially go through the entire list and goes
on until either a match is found or the end of the list is encountered. It has an
average case of 0(N). Binary search tree is faster than the linear search since its
average case is 0(log (N)).
The hash table has an average case of 0(1) in the case whereby one doesn’t know
the size of the input items due to constant retrieve time. But if the items are
continuously added it is better to use binary search tree’s 0(log (N)).
d) For a complete binary search tree to be complete, all the levels must be
completely filled from left to right but not the last level.
The binary search tree created in (a) above is a complete tree since all the nodes
have children except nodes at the lowest level.
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Exam Solutions 5
Question 2
a. Operations of the Stack implementation.
i. Empty() - it checks whether the stack is empty or not. No input parameters are
required in this operation and it returns a Boolean value that is true or false.
ii. Push() - this operation adds a value at the topmost of the stack. Although this
operation do not return anything parameters must be provided.
iii. Pop() – this operation removes an item from the topmost of the stack. It is
different from push() operation in that it don’t require any parameters but it
returns the item.
iv. Constructor() – it creates a new stack if there is none. It has no parameters and
returns an empty stack.
b. A stack is a Last in First out (LIFO) data structure. This is true because items can
only be injected at one side of the stack and removed only at the opposite end.
First in First out data structure occurs when the first element in a queue is the first one
to be removed while in Last in First out principle the last item in the stack is the first
one to be removed.
Question 2
a. Operations of the Stack implementation.
i. Empty() - it checks whether the stack is empty or not. No input parameters are
required in this operation and it returns a Boolean value that is true or false.
ii. Push() - this operation adds a value at the topmost of the stack. Although this
operation do not return anything parameters must be provided.
iii. Pop() – this operation removes an item from the topmost of the stack. It is
different from push() operation in that it don’t require any parameters but it
returns the item.
iv. Constructor() – it creates a new stack if there is none. It has no parameters and
returns an empty stack.
b. A stack is a Last in First out (LIFO) data structure. This is true because items can
only be injected at one side of the stack and removed only at the opposite end.
First in First out data structure occurs when the first element in a queue is the first one
to be removed while in Last in First out principle the last item in the stack is the first
one to be removed.

Exam Solutions 6
c. The program below shows that there are three names to be stored in a stack using a
linked list. We first create a linked list and then add the names to the stack. The
names are then printed and thereby printing the size of the list. The program below is
an example of the implementation as stated above.
Import java.util.Linkedlist;
Public class printNames{
Public static void main(String[] args){
/*Creation of a linked list*/
LinkedList list = new LinkedList();
/*adding values*/
List.add(“Mary”);
List.add(“John”);
List.add(“Kelvin”);
/*Printing the list*/
System.out.println(“LinkedList: ” + list);
/*Printing the size*/
System.out.println(“List size: ” + list.size());
}
]
c. The program below shows that there are three names to be stored in a stack using a
linked list. We first create a linked list and then add the names to the stack. The
names are then printed and thereby printing the size of the list. The program below is
an example of the implementation as stated above.
Import java.util.Linkedlist;
Public class printNames{
Public static void main(String[] args){
/*Creation of a linked list*/
LinkedList list = new LinkedList();
/*adding values*/
List.add(“Mary”);
List.add(“John”);
List.add(“Kelvin”);
/*Printing the list*/
System.out.println(“LinkedList: ” + list);
/*Printing the size*/
System.out.println(“List size: ” + list.size());
}
]

Exam Solutions 7
Question 3
a. The following piece of code shows how to use operations put(k,v) and get(k) in an array-
backed implementation.
put(k,v) operations is used in Maps to insert a pair of element into the map in a form of
<key, value> while get(k) is used to return a value of the key that has been specified.
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Fruits {
public static void main(String[] args) {
Map<String,String> hMap = new HashMap<String, String>();
List<Map<String , String>> Map = new ArrayList<Map<String,String>>();
hMap.put("Yellow", "Banana");
hMap.put("Green", "Apple");
Question 3
a. The following piece of code shows how to use operations put(k,v) and get(k) in an array-
backed implementation.
put(k,v) operations is used in Maps to insert a pair of element into the map in a form of
<key, value> while get(k) is used to return a value of the key that has been specified.
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Fruits {
public static void main(String[] args) {
Map<String,String> hMap = new HashMap<String, String>();
List<Map<String , String>> Map = new ArrayList<Map<String,String>>();
hMap.put("Yellow", "Banana");
hMap.put("Green", "Apple");
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Exam Solutions 8
hMap.put("Orange", "Orange");
Map.add(0,Map1);
Map.add(1,Map1);
for (Map<String, String> map : Map) {
System.out.println(map.get("Yellow"));
System.out.println(map.get("Green"));
System.out.println(map.get("Orange"));
}
}
}
In the code above, the line hMap.put ("Yellow", "Banana"); has been used to input a key
which is a string value, that is, the color of the fruit followed by string banana. The key is
then used by the get () method to retrieve the value of that string and display it using a for
loop.
The use of put(k,v) and get(k) operations has some drawbacks in that when there are
more than one entry that has the same key then the two values will be displayed at the
same time. This results to a collision.
b. Hash Map has an average performance of O (1) which is faster than that of a list-backed
map which has an average performance of O(0) when dealing with large input. Moreover
it depends mostly on the context in which you are using to search. For example, it is
better to use a hash map to find a place with its location address, in this case you will use
a hash map to look for the name of the place in order to get its location address. When
using an array, you will have to use two arrays whereby one array will be for arrays
whereas the other array will be used for the location address. As a result using the get ()
operation in a hash table it will be more fast than when using array list during the search.
c. Hash function maps data of random size to data of a fixed size (Rogaway, P., Shrimpton,
T., 2004).They are used together with the keyword to locate records of data. They are
hMap.put("Orange", "Orange");
Map.add(0,Map1);
Map.add(1,Map1);
for (Map<String, String> map : Map) {
System.out.println(map.get("Yellow"));
System.out.println(map.get("Green"));
System.out.println(map.get("Orange"));
}
}
}
In the code above, the line hMap.put ("Yellow", "Banana"); has been used to input a key
which is a string value, that is, the color of the fruit followed by string banana. The key is
then used by the get () method to retrieve the value of that string and display it using a for
loop.
The use of put(k,v) and get(k) operations has some drawbacks in that when there are
more than one entry that has the same key then the two values will be displayed at the
same time. This results to a collision.
b. Hash Map has an average performance of O (1) which is faster than that of a list-backed
map which has an average performance of O(0) when dealing with large input. Moreover
it depends mostly on the context in which you are using to search. For example, it is
better to use a hash map to find a place with its location address, in this case you will use
a hash map to look for the name of the place in order to get its location address. When
using an array, you will have to use two arrays whereby one array will be for arrays
whereas the other array will be used for the location address. As a result using the get ()
operation in a hash table it will be more fast than when using array list during the search.
c. Hash function maps data of random size to data of a fixed size (Rogaway, P., Shrimpton,
T., 2004).They are used together with the keyword to locate records of data. They are

Exam Solutions 9
also used with hash tables to speed up the search by detecting repeated records in large
files. To use a hash function in a hash table, an element has to be changed to an integer
using this function. The integer can then be used as an index to store the element which
was originally converted in a hash table. The indexes, returned by the hash functions are
called hash codes.
Compression functions are used to combine fixed lengths input to arrive to a single fixed
length output therefore shortening the amount of data to be kept in a hash table. The main
objective of a compression is that it reduces the number of collision that may occur in a
given set of hash codes.
d. A collision is a situation in which a hash function gives the same index for different keys.
It can occur in situations whereby we can have data that has the same index in a hash
table. For example, in a classroom we can have students with the same birthday dates.
When this information is mapped to a hash table, the students with the same birthday
dates will have the same index. While we want to search details of these students the
dates will be returned with the same index leading to collision. To manage the collision,
we use chaining. This method uses a linked list to hold entries that went in a similar
bucket (Maurer, W.D., Lewis, T.G, 1975).
also used with hash tables to speed up the search by detecting repeated records in large
files. To use a hash function in a hash table, an element has to be changed to an integer
using this function. The integer can then be used as an index to store the element which
was originally converted in a hash table. The indexes, returned by the hash functions are
called hash codes.
Compression functions are used to combine fixed lengths input to arrive to a single fixed
length output therefore shortening the amount of data to be kept in a hash table. The main
objective of a compression is that it reduces the number of collision that may occur in a
given set of hash codes.
d. A collision is a situation in which a hash function gives the same index for different keys.
It can occur in situations whereby we can have data that has the same index in a hash
table. For example, in a classroom we can have students with the same birthday dates.
When this information is mapped to a hash table, the students with the same birthday
dates will have the same index. While we want to search details of these students the
dates will be returned with the same index leading to collision. To manage the collision,
we use chaining. This method uses a linked list to hold entries that went in a similar
bucket (Maurer, W.D., Lewis, T.G, 1975).

Exam Solutions 10
Question 4
a) The data structure that would be likely to be used is a Hash map. A Hash map
includes some basic operation such as put () and get (), the former is used to add
entries while the latter is used to retrieving these entries. In our case the addresses are
already store in an electronic database so what we are supposed to do is search the
addresses by username and then displaying them in ascending order. We shall assign
each address with a username by using keys to help in searching and then sort the list
in an ascending order. An example of a code to do this can be:
package testhashes;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class searchsort {
public static void main(String[] args) {
Map<String, String> address = new HashMap<>();
address.put("vinny", "102");
address.put("peter", "123");
address.put("john", "576");
address.put("clark", "475");
Question 4
a) The data structure that would be likely to be used is a Hash map. A Hash map
includes some basic operation such as put () and get (), the former is used to add
entries while the latter is used to retrieving these entries. In our case the addresses are
already store in an electronic database so what we are supposed to do is search the
addresses by username and then displaying them in ascending order. We shall assign
each address with a username by using keys to help in searching and then sort the list
in an ascending order. An example of a code to do this can be:
package testhashes;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class searchsort {
public static void main(String[] args) {
Map<String, String> address = new HashMap<>();
address.put("vinny", "102");
address.put("peter", "123");
address.put("john", "576");
address.put("clark", "475");
Secure Best Marks with AI Grader
Need help grading? Try our AI Grader for instant feedback on your assignments.

Exam Solutions 11
addresssearch(address);
}
private static void addresssearch(Map<String, String> mapaddress) {
System.out.println("Orignal HashMap:" + mapaddress);
System.out.println("\n1. Sort address by ascending keys: " );
TreeMap<String,String>mapSorted = new TreeMap<>(mapaddress);
mapSorted.forEach((key, value) -> {
System.out.println(key + "'s address is: " + value);
})}}
This data structure has a time complexity of O(1) on average case and best case while
its worst case is O(n). This makes it more efficient than other data structures.
b. The DOM (Document Object Model) is a more efficient data structure to be used in
implementing the HTML documents because if any two or more DOM
implementations are used to build a representation of a similar document, then they
will create a similar structure with similar objects and relationships. The tree structure
is another way in which we can represent nested HTML tags. In this structure we start
with the <html></html> tags that begin and end a HTML document respectively.
Other tags such as the <body> tag are inside the <html> tags. A diagram to represent
this tree structure is as shown below:
addresssearch(address);
}
private static void addresssearch(Map<String, String> mapaddress) {
System.out.println("Orignal HashMap:" + mapaddress);
System.out.println("\n1. Sort address by ascending keys: " );
TreeMap<String,String>mapSorted = new TreeMap<>(mapaddress);
mapSorted.forEach((key, value) -> {
System.out.println(key + "'s address is: " + value);
})}}
This data structure has a time complexity of O(1) on average case and best case while
its worst case is O(n). This makes it more efficient than other data structures.
b. The DOM (Document Object Model) is a more efficient data structure to be used in
implementing the HTML documents because if any two or more DOM
implementations are used to build a representation of a similar document, then they
will create a similar structure with similar objects and relationships. The tree structure
is another way in which we can represent nested HTML tags. In this structure we start
with the <html></html> tags that begin and end a HTML document respectively.
Other tags such as the <body> tag are inside the <html> tags. A diagram to represent
this tree structure is as shown below:

Exam Solutions 12
html
head body
link title table h1 img
tr td a
c. A stack is a better method to employ when solving mathematical problems that involves
the use of BODMAS rule. These problems requires priority to some of the sections of the
problem, for example, we must solve what is in the parenthesis fast before the one in the
multiplication. An example of a mathematical problem can be as the one shown below:
5-3+6*(8/2)-2*1
From the problem above we can rewrite it in a post-fix for to become:
5 3 - 6 + 8 2 / 1 2 + - *
html
head body
link title table h1 img
tr td a
c. A stack is a better method to employ when solving mathematical problems that involves
the use of BODMAS rule. These problems requires priority to some of the sections of the
problem, for example, we must solve what is in the parenthesis fast before the one in the
multiplication. An example of a mathematical problem can be as the one shown below:
5-3+6*(8/2)-2*1
From the problem above we can rewrite it in a post-fix for to become:
5 3 - 6 + 8 2 / 1 2 + - *
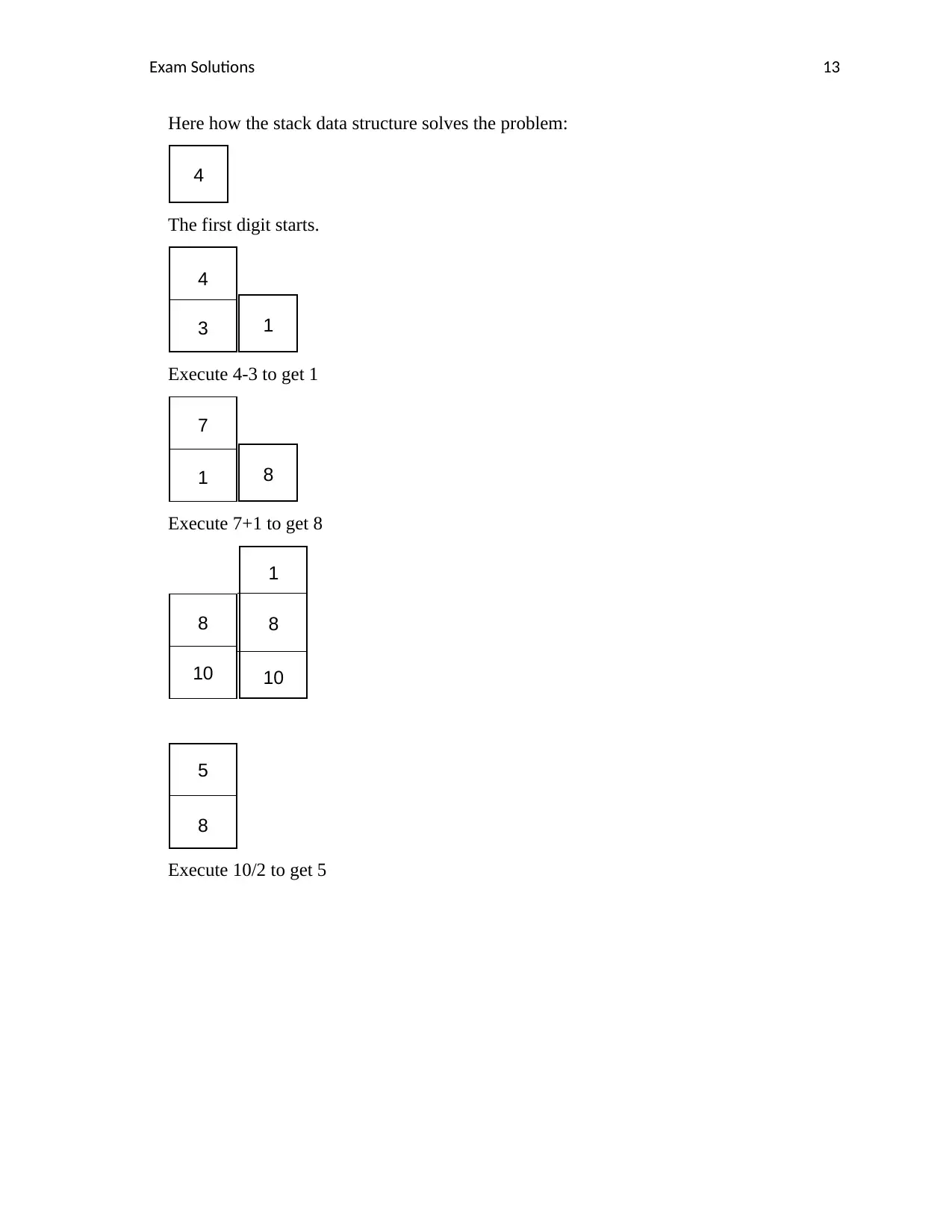
Exam Solutions 13
Here how the stack data structure solves the problem:
4
The first digit starts.
4
3 1
Execute 4-3 to get 1
7
1 8
Execute 7+1 to get 8
8
10
1
8
10
5
8
Execute 10/2 to get 5
Here how the stack data structure solves the problem:
4
The first digit starts.
4
3 1
Execute 4-3 to get 1
7
1 8
Execute 7+1 to get 8
8
10
1
8
10
5
8
Execute 10/2 to get 5
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Exam Solutions 14
2
5
8
3
1
5
8
3
5
8
Execute 5-2 to get 3
2
8
Execute 5-3 to get 2
16
Execute 8*2 to get 1
References
Maurer, W.D. and Lewis, T.G., 1975. Hash table methods. ACM Computing Surveys
(CSUR), 7(1), pp.5-19.
2
5
8
3
1
5
8
3
5
8
Execute 5-2 to get 3
2
8
Execute 5-3 to get 2
16
Execute 8*2 to get 1
References
Maurer, W.D. and Lewis, T.G., 1975. Hash table methods. ACM Computing Surveys
(CSUR), 7(1), pp.5-19.

Exam Solutions 15
Rogaway, P. and Shrimpton, T., 2004, February. Cryptographic hash-function basics:
Definitions, implications, and separations for preimage resistance, second-preimage resistance,
and collision resistance. In International workshop on fast software encryption (pp. 371-388).
Springer, Berlin, Heidelberg
Rogaway, P. and Shrimpton, T., 2004, February. Cryptographic hash-function basics:
Definitions, implications, and separations for preimage resistance, second-preimage resistance,
and collision resistance. In International workshop on fast software encryption (pp. 371-388).
Springer, Berlin, Heidelberg
1 out of 15
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
© 2024 | Zucol Services PVT LTD | All rights reserved.