ISCG8049: Data Warehouse Architecture Solution for Adventure Works
VerifiedAdded on 2023/06/04
|19
|4112
|499
Report
AI Summary
This report details a data warehouse architecture solution for Adventure Works, focusing on analyzing product orders, costs, and order locations. The solution employs dimensional modeling with fact and dimensional tables using a star schema to address specific business questions. Data validation is performed using Data Quality Assurance (DQA) rules before loading into the data warehouse, with any incorrect data logged. The implementation utilizes SQL Server and follows the Kimball methodology, emphasizing business value and dimensional data structuring. The report covers requirement analysis, ETL design, and physical database design, including partitioning and indexing. It also evaluates data warehouse performance and outlines lessons learned, concluding with potential future developments. Desklib provides access to this and similar solved assignments to aid students in their studies.

1Data Warehouse Architecture Solution for Adventure Works
DATA WAREHOUSE ARCHITECTURE SOLUTION FOR ADVENTURE WORKS
[Student Names]
[University Name]
[Lecture Name]
[Date]
DATA WAREHOUSE ARCHITECTURE SOLUTION FOR ADVENTURE WORKS
[Student Names]
[University Name]
[Lecture Name]
[Date]
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

2Data Warehouse Architecture Solution for Adventure Works
Abstract
The data warehouse is a process that helps in the storage of data in a centralized location where
the data is extracted from multiple locations the data warehouse is used by the business owners
in the implementation of the business intelligence in order to improve on the handling of their
organizations performance through the analysis of the data warehouse data.
This report involves the implementation of the data warehouse for the adventure works database
this data warehouse will as a result assist in the analysis of the products orders in average, their
costs and the location of orders in a specified month and year. Therefore to get the answer for the
above question the dimensional modelling was done through the creation of fact and dimensional
tables, however the use of star schema was to give the specific solutions to the questions used.
The data is then validated before loading to data warehouse in order to check its quality by use of
the Data Quality Assurance rules where any wrong data is inserted in the data logs table , to
implement the data warehouse the SQL server was used.
Table of Contents
Abstract
The data warehouse is a process that helps in the storage of data in a centralized location where
the data is extracted from multiple locations the data warehouse is used by the business owners
in the implementation of the business intelligence in order to improve on the handling of their
organizations performance through the analysis of the data warehouse data.
This report involves the implementation of the data warehouse for the adventure works database
this data warehouse will as a result assist in the analysis of the products orders in average, their
costs and the location of orders in a specified month and year. Therefore to get the answer for the
above question the dimensional modelling was done through the creation of fact and dimensional
tables, however the use of star schema was to give the specific solutions to the questions used.
The data is then validated before loading to data warehouse in order to check its quality by use of
the Data Quality Assurance rules where any wrong data is inserted in the data logs table , to
implement the data warehouse the SQL server was used.
Table of Contents

3Data Warehouse Architecture Solution for Adventure Works
Abstract............................................................................................................................................2
1 Introduction and requirements analysis...................................................................................5
1.1 Business requirements and proposed data warehouse solution........................................5
2 Solution design and development............................................................................................7
2.1 Development methodology (Kimball approach)...............................................................7
2.2 Detailed requirement analysis...........................................................................................8
2.3 Dimensional modelling...................................................................................................10
2.4 Physical database design.................................................................................................13
2.4.1 Partitioning..............................................................................................................13
2.4.2 Indexing...................................................................................................................13
2.5 ETL design......................................................................................................................14
2.6 Data quality assurance....................................................................................................15
2.7 Key DW technique/technology: Star schema.................................................................15
3 Evaluation and Lesson Learned.............................................................................................16
3.1 Evaluation of data warehouse performance....................................................................19
3.2 Lessons learned from the solution design and development...........................................19
4 Conclusion and future development......................................................................................19
4.1 Conclusion......................................................................................................................19
4.2 Future developments.......................................................................................................20
5 Reference...............................................................................................................................20
Abstract............................................................................................................................................2
1 Introduction and requirements analysis...................................................................................5
1.1 Business requirements and proposed data warehouse solution........................................5
2 Solution design and development............................................................................................7
2.1 Development methodology (Kimball approach)...............................................................7
2.2 Detailed requirement analysis...........................................................................................8
2.3 Dimensional modelling...................................................................................................10
2.4 Physical database design.................................................................................................13
2.4.1 Partitioning..............................................................................................................13
2.4.2 Indexing...................................................................................................................13
2.5 ETL design......................................................................................................................14
2.6 Data quality assurance....................................................................................................15
2.7 Key DW technique/technology: Star schema.................................................................15
3 Evaluation and Lesson Learned.............................................................................................16
3.1 Evaluation of data warehouse performance....................................................................19
3.2 Lessons learned from the solution design and development...........................................19
4 Conclusion and future development......................................................................................19
4.1 Conclusion......................................................................................................................19
4.2 Future developments.......................................................................................................20
5 Reference...............................................................................................................................20
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

4Data Warehouse Architecture Solution for Adventure Works
1 Introduction and requirements analysis
The Data warehouse is a database that is centralised in nature and is used to store data that is
obtained from multiple sources and the stored data is used for analysis and generation of the
reports using some deliverables.
All the historical data is analysed through the use of the queries where the main data warehouse
data sources is from online transaction processing system and all the businesses transactions logs
are stored in this database where the data is consolidated from various sources of data.
The Extract transform and load (ETL) is used in the consolidation purpose of the data to be used
in the creation of the data warehouse where the consolidated data is obtained from various OLTP
data sources.
The Business intelligence is a vital aspect that is used in the business database approaches which
are used in the computing industries and it is used to define the data warehousing and reporting
theories.
To develop the proposed data warehouse the BI tool is used which is part of the Microsoft SQL
Server Reporting Services since the Microsoft SQL server has a flexible and multi-purpose
report solutions where the reports are designed, installed and run on.
1.1 Business requirements and proposed data warehouse solution
This report involves the building of the data warehouse of the database adventure framework
where the adventure works is a company’s database that has various tables including the
products, sales, and production, territory and time details.
Below are the various business requirements:
i. For each product, display & sort working order based on the average/total days it has
been late from starting (ActualStartDate-ScheduledStartDate) & from ending
(ActualEndDate-ScheduledEndDate), average actual resource hours, average cost
deviation (PlannedCost-ActualCost), scrapped quantity, actual quantity (StockedQty-
OrderQty) and average/total location cost (Location.costRate *
actualResourceHours) at a specific month/year.
ii. For each working order, display & sort based on the total number of (unique)
products it produced at a specific month/year.
1 Introduction and requirements analysis
The Data warehouse is a database that is centralised in nature and is used to store data that is
obtained from multiple sources and the stored data is used for analysis and generation of the
reports using some deliverables.
All the historical data is analysed through the use of the queries where the main data warehouse
data sources is from online transaction processing system and all the businesses transactions logs
are stored in this database where the data is consolidated from various sources of data.
The Extract transform and load (ETL) is used in the consolidation purpose of the data to be used
in the creation of the data warehouse where the consolidated data is obtained from various OLTP
data sources.
The Business intelligence is a vital aspect that is used in the business database approaches which
are used in the computing industries and it is used to define the data warehousing and reporting
theories.
To develop the proposed data warehouse the BI tool is used which is part of the Microsoft SQL
Server Reporting Services since the Microsoft SQL server has a flexible and multi-purpose
report solutions where the reports are designed, installed and run on.
1.1 Business requirements and proposed data warehouse solution
This report involves the building of the data warehouse of the database adventure framework
where the adventure works is a company’s database that has various tables including the
products, sales, and production, territory and time details.
Below are the various business requirements:
i. For each product, display & sort working order based on the average/total days it has
been late from starting (ActualStartDate-ScheduledStartDate) & from ending
(ActualEndDate-ScheduledEndDate), average actual resource hours, average cost
deviation (PlannedCost-ActualCost), scrapped quantity, actual quantity (StockedQty-
OrderQty) and average/total location cost (Location.costRate *
actualResourceHours) at a specific month/year.
ii. For each working order, display & sort based on the total number of (unique)
products it produced at a specific month/year.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
5Data Warehouse Architecture Solution for Adventure Works
iii. For each product, display & sort based on the average/total profit
(SalesOrder.LineTotal - ProductCostHistory.StandardCost*SalesOrder.OrderQty)
when it was sold in a specific/all territory at a specific month/year.
Below are the expected results obtained from the questions above.
a. Question 1 solution.
Product name Sum delay Total
actual
resource
hours
Total cost deviation scrap Total location
cost
Road-450
Red.48
20 4.000000 0.00 0 196.00
The above solution gives a list of products which depends on their respective sum delays and the
total actual resources hours and total allocations. In this case the ID of the products names are
used which is the primary key of the productname in order to extract the sum delay, total actual
resource hours, total cost deviation, scrap and total location costs. However to obtain the results
the SQL queries using the “select”, “sum” and “avg”.
Question 2 solution.
Scrapped
quantity
Work
orderid
1 7185
In the second question the scrapped quantity is counted and the respective work id is also
extracted and this helps in the analysis of the scrapped quantities against the order id where the
“count” for the scrap id and “group by” for the “WorkOrderId” are used for analysis.
Question 3 solution.
Product Name Profit
LL Mountain
Frame-Silver.48
6695925
iii. For each product, display & sort based on the average/total profit
(SalesOrder.LineTotal - ProductCostHistory.StandardCost*SalesOrder.OrderQty)
when it was sold in a specific/all territory at a specific month/year.
Below are the expected results obtained from the questions above.
a. Question 1 solution.
Product name Sum delay Total
actual
resource
hours
Total cost deviation scrap Total location
cost
Road-450
Red.48
20 4.000000 0.00 0 196.00
The above solution gives a list of products which depends on their respective sum delays and the
total actual resources hours and total allocations. In this case the ID of the products names are
used which is the primary key of the productname in order to extract the sum delay, total actual
resource hours, total cost deviation, scrap and total location costs. However to obtain the results
the SQL queries using the “select”, “sum” and “avg”.
Question 2 solution.
Scrapped
quantity
Work
orderid
1 7185
In the second question the scrapped quantity is counted and the respective work id is also
extracted and this helps in the analysis of the scrapped quantities against the order id where the
“count” for the scrap id and “group by” for the “WorkOrderId” are used for analysis.
Question 3 solution.
Product Name Profit
LL Mountain
Frame-Silver.48
6695925
6Data Warehouse Architecture Solution for Adventure Works
In the third question the products are selected alongside the respective profits in each products
where the names of products are used and the sum of their respective profits are displayed using
the “sum” and “select” key words.
The adventure databases is the data warehouse source, however due to vagueness in the database
structures it becomes quite hard to get the results directly from the database also during the data
analysis the tables used were not complete and the data contained was very wrong and therefore
Data Quality Assurance (DQA) rules were used in order to apply DQA before the extraction of
data into the data warehouse.
2 Solution design and development
2.1 Development methodology (Kimball approach)
The data warehouse implementations has used various methodologies as the implementations
blue prints where the Kimball life cycle methodology is selected as the methodology to be used.
The Kimball life cycle methodology was invented by Kimbal and others in 1980 and is used used
to do the implementation of the data warehouse and the business intelligence too.
Below are the main aspects used by the Kimball life cycle.
i. Addition of the businesses value in the entire organizations.
ii. It is used in structuring of the data in a dimensional form that is obtained from various
sources through the report and query.
iii. It is used in handling of the dimensions that change slowly.
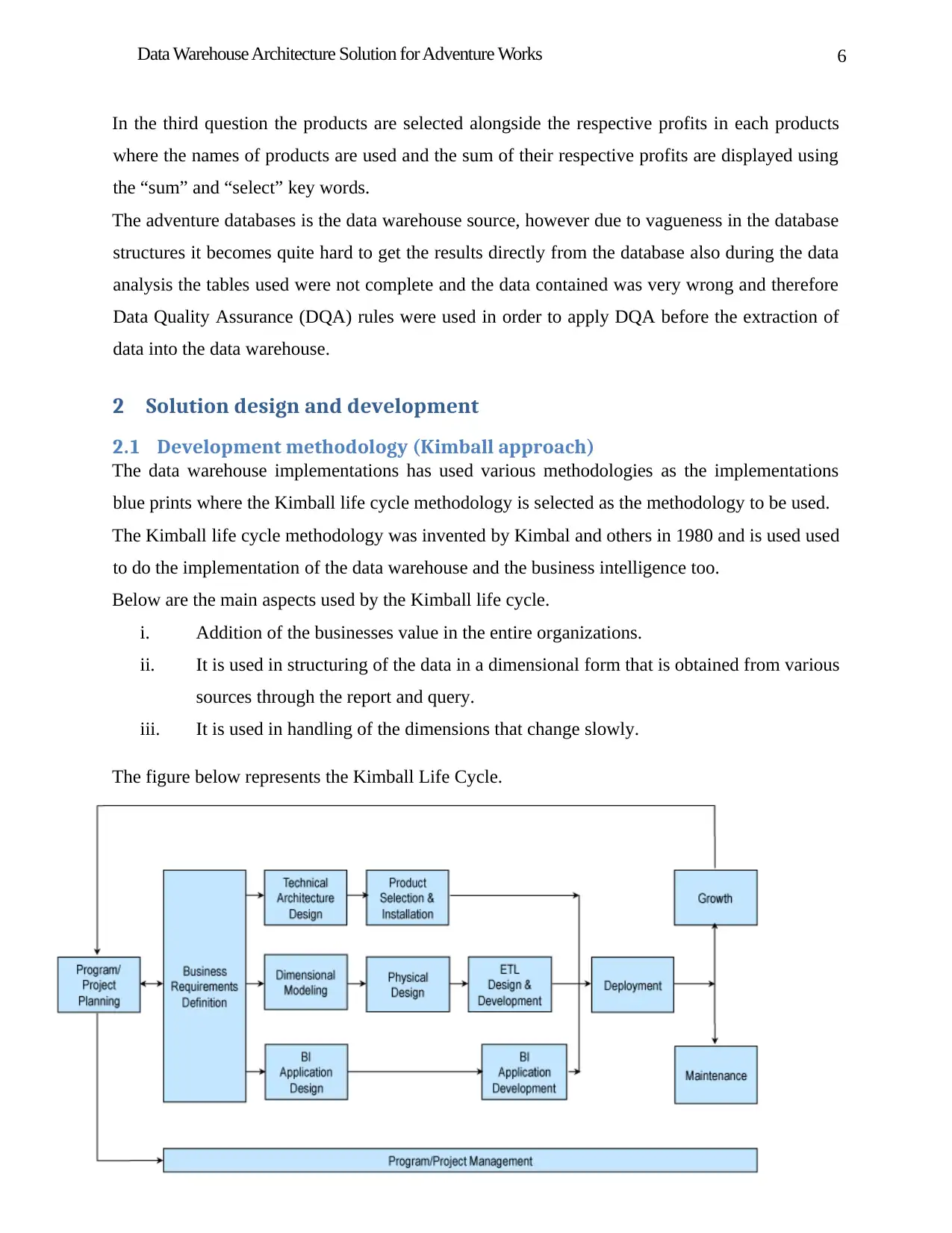
The figure below represents the Kimball Life Cycle.
In the third question the products are selected alongside the respective profits in each products
where the names of products are used and the sum of their respective profits are displayed using
the “sum” and “select” key words.
The adventure databases is the data warehouse source, however due to vagueness in the database
structures it becomes quite hard to get the results directly from the database also during the data
analysis the tables used were not complete and the data contained was very wrong and therefore
Data Quality Assurance (DQA) rules were used in order to apply DQA before the extraction of
data into the data warehouse.
2 Solution design and development
2.1 Development methodology (Kimball approach)
The data warehouse implementations has used various methodologies as the implementations
blue prints where the Kimball life cycle methodology is selected as the methodology to be used.
The Kimball life cycle methodology was invented by Kimbal and others in 1980 and is used used
to do the implementation of the data warehouse and the business intelligence too.
Below are the main aspects used by the Kimball life cycle.
i. Addition of the businesses value in the entire organizations.
ii. It is used in structuring of the data in a dimensional form that is obtained from various
sources through the report and query.
iii. It is used in handling of the dimensions that change slowly.
The figure below represents the Kimball Life Cycle.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

7Data Warehouse Architecture Solution for Adventure Works
According to the above figure the initials stage of data warehouse design is project planning
where a new project is established through staffing, scoping and justifications.
The second step is the requirements analysis where the process starts which uses technology
track for metadata management, and the business track for managing the business intelligence.
Therefore using the Kimball life cycle the data track is used which deals with the data
dimensional modelling and the structuring of the data is done here as the dimensional model is a
relational model just the same as the star schema or the multi dimensional just like in the OLAP.
However in our case the star schema is used as the dimensional models which use two main
aspects as follows:
i. Ease of use of the data from the users perspectives.
ii. Fast in performing the queries.
There are various business models that are used in solving of different businesses processes
where single dimensional model solves single business problem.
To develop the dimension model there are various things that are done which includes handling
of the design issues, configuration of the physical designs including the tuning, Extract
Transform and Load (ETL) where the data required is selected from the databases and then is
cleaned through business rules, and then the last thing is to transform the data to fit in the new
data dimensional model.
2.2 Detailed requirement analysis
This report mainly deals with the development of the adventure works data warehouse solutions
and generation of the reports for particular deliverables.
There are various elements that are put into consideration in the data warehouse development
which depends on the business requirements. However these business requirements comprises of
the reports deliverables which is achievable through various processes which includes the
following:
i. To list answers to the given questions.
This is using the three stated questions that had been answered and thus we start by picturing the
asked questions outputs and as a result the below result tables were obtained.
The initial question was for each of the products ,display and sort working order based on the
average/total days it has late from the starting and from the ending ,average actual resource hours
According to the above figure the initials stage of data warehouse design is project planning
where a new project is established through staffing, scoping and justifications.
The second step is the requirements analysis where the process starts which uses technology
track for metadata management, and the business track for managing the business intelligence.
Therefore using the Kimball life cycle the data track is used which deals with the data
dimensional modelling and the structuring of the data is done here as the dimensional model is a
relational model just the same as the star schema or the multi dimensional just like in the OLAP.
However in our case the star schema is used as the dimensional models which use two main
aspects as follows:
i. Ease of use of the data from the users perspectives.
ii. Fast in performing the queries.
There are various business models that are used in solving of different businesses processes
where single dimensional model solves single business problem.
To develop the dimension model there are various things that are done which includes handling
of the design issues, configuration of the physical designs including the tuning, Extract
Transform and Load (ETL) where the data required is selected from the databases and then is
cleaned through business rules, and then the last thing is to transform the data to fit in the new
data dimensional model.
2.2 Detailed requirement analysis
This report mainly deals with the development of the adventure works data warehouse solutions
and generation of the reports for particular deliverables.
There are various elements that are put into consideration in the data warehouse development
which depends on the business requirements. However these business requirements comprises of
the reports deliverables which is achievable through various processes which includes the
following:
i. To list answers to the given questions.
This is using the three stated questions that had been answered and thus we start by picturing the
asked questions outputs and as a result the below result tables were obtained.
The initial question was for each of the products ,display and sort working order based on the
average/total days it has late from the starting and from the ending ,average actual resource hours
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
8Data Warehouse Architecture Solution for Adventure Works
,average costs deviations , scrapped quantity, actual quantity and average/total location cost at a
specific month/year and below is the table obtained.
Product name Sum delay Total
actual
resource
hours
Total cost deviation scrap Total location
cost
Road-450
Red.48
20 4.000000 0.00 0 196.00
The second question was requesting in each working order, display & sort based on the total
number of (unique) products it produced at a specific month/year and below is the table obtained.
Scrapped
quantity
Work
orderid
1 7185
The third question was requesting each product, display & sort based on the average/total profit
when it was sold in a specific/all territory at a specific month/year and below is the table
obtained.
Product Name Profit
LL Mountain
Frame-Silver.48
6695925
ii. Identification of the sources of data which are needed in the reports generation.
The identified data source is the adventure works which is downloaded and loaded in the
MYSQL database software.
iii. Identification of the target audiences of the generated reports.
The managers, general managers and the employers are the main audience of the
generated reports.
,average costs deviations , scrapped quantity, actual quantity and average/total location cost at a
specific month/year and below is the table obtained.
Product name Sum delay Total
actual
resource
hours
Total cost deviation scrap Total location
cost
Road-450
Red.48
20 4.000000 0.00 0 196.00
The second question was requesting in each working order, display & sort based on the total
number of (unique) products it produced at a specific month/year and below is the table obtained.
Scrapped
quantity
Work
orderid
1 7185
The third question was requesting each product, display & sort based on the average/total profit
when it was sold in a specific/all territory at a specific month/year and below is the table
obtained.
Product Name Profit
LL Mountain
Frame-Silver.48
6695925
ii. Identification of the sources of data which are needed in the reports generation.
The identified data source is the adventure works which is downloaded and loaded in the
MYSQL database software.
iii. Identification of the target audiences of the generated reports.
The managers, general managers and the employers are the main audience of the
generated reports.

9Data Warehouse Architecture Solution for Adventure Works
iv. Selection of the information display formats.
The tables above clearly show the selected format of the stated questions.
2.3 Dimensional modelling
The dimensional modelling consists of the various concepts used in the data warehouse that
mainly supports the database queries.
Below are the steps followed.
Step 1: Identification of the fields needed in answering the questions.
This step deals with the identification of the fields needed in answering of the businesses
problems and below is the OLTP schema for the adventure works.
However in order to solve the questions the following fields are required SalesOrderDetailID,
CustomerID, ProductID, SpecialOfferID, SalesPersonID, OrderQty, Bonus, TerritoryID,
OrderDate. However date field has to be mapped to the date key to enable the standardization of
the values and therefore the an extra DateSK is added in the fact table. The above fields forms
iv. Selection of the information display formats.
The tables above clearly show the selected format of the stated questions.
2.3 Dimensional modelling
The dimensional modelling consists of the various concepts used in the data warehouse that
mainly supports the database queries.
Below are the steps followed.
Step 1: Identification of the fields needed in answering the questions.
This step deals with the identification of the fields needed in answering of the businesses
problems and below is the OLTP schema for the adventure works.
However in order to solve the questions the following fields are required SalesOrderDetailID,
CustomerID, ProductID, SpecialOfferID, SalesPersonID, OrderQty, Bonus, TerritoryID,
OrderDate. However date field has to be mapped to the date key to enable the standardization of
the values and therefore the an extra DateSK is added in the fact table. The above fields forms
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

10Data Warehouse Architecture Solution for Adventure Works
the fact table where OrderDetailID is the primary key and the CustomerID, ProductID,
SpecialOfferID, SalesPersonID, TerritoryID and DateSK are the foreign keys.
Step 2: Designing Facts Table
PK SalesOrderDetailID
FK CustomerID
FK SalesPersonID
FK SpecialOfferID
FK TerritoryID
FK DateSK
OrderQty
FK ProductID
[5].
The above is the fact table has following fetched results:
SalesOrderDetailID forms the primary key of the SalesOrder table which has various fields
which includes ProductID, OrderQty and SpecialOfferID.
However the SalesOrderDetailID references the SalesOrderHeader which is used to fetch the
values of SalesPersonID, CustomerID, TerritoryID, OrderDate fields.
Step 3: Generating Time Key
This is the third step in which the dates fields get converted into unique dates keys which makes
part of dimension and thus it is important to convert date into unique date keys. Below is the
formula to convert dates to dates keys which converts the dates into integers.
Year*1000 + month*100 + date.
Step 4: Identification of the Dimensional Tables
In this step is where the dimensional modelling is completed and the various dimensional tables
are identified that provides the information to the end users of the database.
Below are the identified dimensional tables of the dimensional models.’
i. DimCustomer1 : - This is used in the storage of the information about the customers from
the tables of the adventures works.
ii. DimSalesPerson : - it is used in the storage of the sales people from the entire employees
table.
iii. DimTime : - It is used in the storage of the time keys for respective dates.
the fact table where OrderDetailID is the primary key and the CustomerID, ProductID,
SpecialOfferID, SalesPersonID, TerritoryID and DateSK are the foreign keys.
Step 2: Designing Facts Table
PK SalesOrderDetailID
FK CustomerID
FK SalesPersonID
FK SpecialOfferID
FK TerritoryID
FK DateSK
OrderQty
FK ProductID
[5].
The above is the fact table has following fetched results:
SalesOrderDetailID forms the primary key of the SalesOrder table which has various fields
which includes ProductID, OrderQty and SpecialOfferID.
However the SalesOrderDetailID references the SalesOrderHeader which is used to fetch the
values of SalesPersonID, CustomerID, TerritoryID, OrderDate fields.
Step 3: Generating Time Key
This is the third step in which the dates fields get converted into unique dates keys which makes
part of dimension and thus it is important to convert date into unique date keys. Below is the
formula to convert dates to dates keys which converts the dates into integers.
Year*1000 + month*100 + date.
Step 4: Identification of the Dimensional Tables
In this step is where the dimensional modelling is completed and the various dimensional tables
are identified that provides the information to the end users of the database.
Below are the identified dimensional tables of the dimensional models.’
i. DimCustomer1 : - This is used in the storage of the information about the customers from
the tables of the adventures works.
ii. DimSalesPerson : - it is used in the storage of the sales people from the entire employees
table.
iii. DimTime : - It is used in the storage of the time keys for respective dates.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

11Data Warehouse Architecture Solution for Adventure Works
iv. DimOffer: - This is used in the storage of offers details for various products.
v. DimProduct : - This is used in the storage of the products.
vi. FactSales : - This is used to store the reference details of the various tables.
Step 5: Establishment of the Relationships between fact and Dimensional Tables
The fact table is created in order to define other entities on the fact tables and below is the
resultant dimensional table.
The data warehouse methodology in this case is using the star schema designs and this describes
how the dimension and fact tables to organize the data in the data warehouses.
2.4 Physical database design
2.4.1 Partitioning
In the implementation of the proposed data warehouse the database data is partitioned
horizontally where the various resultant tables has rows from the main table and thus the main
iv. DimOffer: - This is used in the storage of offers details for various products.
v. DimProduct : - This is used in the storage of the products.
vi. FactSales : - This is used to store the reference details of the various tables.
Step 5: Establishment of the Relationships between fact and Dimensional Tables
The fact table is created in order to define other entities on the fact tables and below is the
resultant dimensional table.
The data warehouse methodology in this case is using the star schema designs and this describes
how the dimension and fact tables to organize the data in the data warehouses.
2.4 Physical database design
2.4.1 Partitioning
In the implementation of the proposed data warehouse the database data is partitioned
horizontally where the various resultant tables has rows from the main table and thus the main

12Data Warehouse Architecture Solution for Adventure Works
table is split into many small tables and each small table will consist of equal number of columns
but will have little number of rows as shown below.
2.4.2 Indexing
The indexing is also used in the data warehouse design in order to increase the data retrieval
speed, however as a result it requires more storage space to occupy to be able to sustain the
index data structures.
Therefore the index is used to quickly search records without looking into each and every row
records and therefore the indexes are created from multiple columns from the database tables.
Below is the illustration of the data warehouse indexing.
table is split into many small tables and each small table will consist of equal number of columns
but will have little number of rows as shown below.
2.4.2 Indexing
The indexing is also used in the data warehouse design in order to increase the data retrieval
speed, however as a result it requires more storage space to occupy to be able to sustain the
index data structures.
Therefore the index is used to quickly search records without looking into each and every row
records and therefore the indexes are created from multiple columns from the database tables.
Below is the illustration of the data warehouse indexing.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 19
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.