Data Warehouse Analysis: Components, Structures, ETL, and Weka
VerifiedAdded on 2020/07/23
|16
|4219
|143
Project
AI Summary
This project provides a comprehensive overview of data warehouse components, encompassing source systems, data staging, and presentation servers. It details the ETL (Extract, Transform, Load) process, explaining the roles of Oracle Warehouse Builder and MS SQL Server's DTS. The assignment outlines functional data sources, load managers, factory managers, query managers, detailed and summarized data storage, archive data, meta-information, and end-user access tools. It also examines the ETL process, including extraction, transformation, cleaning, and loading, highlighting data mining with Weka. The inclusion of pivot table data further supports the project's exploration of data analysis and practical application within a business context. This assignment serves as an excellent resource for understanding the fundamentals of data warehousing and its practical applications.

DATA WAREHOUSE COMPONENTS & STRUCTURES
Submitted By;
Date:
Submitted By;
Date:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Introduction
The information in an information warehouse originates from useful techniques of business and
external sources. These are known as supply systems together. The information removed from
source techniques will be held in an area known as data staging, in which the data cleaning is
done changed, reduplicated to get ready the details for us within the data stockroom. In staging
area various machines are collected and fundamental actions like sorting and processing is
done. The area in which any query and presentation services are not provided is called info
staging area. As immediately enough as a program provides concern or display solutions and
divided as a display machine really. The demonstration device will be the target device on
which the information is packed from the information region organized plus held regarding
direct querying by end writers, users and others. There are three types of techniques in data
warehouse that is as follows :-
o Source Systems
o Data Workplace set ups Area
o Presentation hosts
The info travels from source strategies to exhibition servers with the info staging area. This
process is known as ETL (extract, transform, in addition load) or perhaps ETT (extract, change,
and transfer). For this Oracle’s ETL tool is used Oracle Warehouse Builder (OWB) in addition MS
SQL Server’s ETL tool is called Information Modify Services (DTS).
The standard structures of the details warehouse is described below :-
1 . FUNCTIONAL INFORMATION
The sources of information for your data warehouse are usually supplied through:
o The information from the processor methods within the conventional program and
stratified info.
o Data can also originate from the RDBMS such as Oracle
o Moreover, inner details, functional data furthermore consists of exterior data extracted
from industrial databases and sources related to supplier and clients.
2 LOAD SUPERVISOR
Force supervisor works all the functions connected with extraction and launching details into
the info stockroom. These types of operations consist of easy changes of the data to get ready
the information for access in to the stockroom. The size and complexness of the component
vary in details warehouses and might be built using the particular combination of supplier
details launching tools plus custom built applications.
3. FACTORY MANAGER
A particular warehouse boss operates all of features linked to the business associated with data
within warehouse. This particular component is made using supplier information administration
tools plus default applications. The features operate by employer are :-
o Analysis of details to check persistence
The information in an information warehouse originates from useful techniques of business and
external sources. These are known as supply systems together. The information removed from
source techniques will be held in an area known as data staging, in which the data cleaning is
done changed, reduplicated to get ready the details for us within the data stockroom. In staging
area various machines are collected and fundamental actions like sorting and processing is
done. The area in which any query and presentation services are not provided is called info
staging area. As immediately enough as a program provides concern or display solutions and
divided as a display machine really. The demonstration device will be the target device on
which the information is packed from the information region organized plus held regarding
direct querying by end writers, users and others. There are three types of techniques in data
warehouse that is as follows :-
o Source Systems
o Data Workplace set ups Area
o Presentation hosts
The info travels from source strategies to exhibition servers with the info staging area. This
process is known as ETL (extract, transform, in addition load) or perhaps ETT (extract, change,
and transfer). For this Oracle’s ETL tool is used Oracle Warehouse Builder (OWB) in addition MS
SQL Server’s ETL tool is called Information Modify Services (DTS).
The standard structures of the details warehouse is described below :-
1 . FUNCTIONAL INFORMATION
The sources of information for your data warehouse are usually supplied through:
o The information from the processor methods within the conventional program and
stratified info.
o Data can also originate from the RDBMS such as Oracle
o Moreover, inner details, functional data furthermore consists of exterior data extracted
from industrial databases and sources related to supplier and clients.
2 LOAD SUPERVISOR
Force supervisor works all the functions connected with extraction and launching details into
the info stockroom. These types of operations consist of easy changes of the data to get ready
the information for access in to the stockroom. The size and complexness of the component
vary in details warehouses and might be built using the particular combination of supplier
details launching tools plus custom built applications.
3. FACTORY MANAGER
A particular warehouse boss operates all of features linked to the business associated with data
within warehouse. This particular component is made using supplier information administration
tools plus default applications. The features operate by employer are :-
o Analysis of details to check persistence

o Transformation plus blending the original source data through transient space for
storage space into information stockroom tables
o Create indices plus views on the bottom desk.
o Renormalization
o Generation associated with aggregation
o Backing up plus archiving of details
o Within specific situations, the stockroom employer also produces question dating
profiles to figure out which indices and aggregations are appropriate.
four. QUERY MANAGER
The problem supervisor execute all procedures connected with administration of customer
questions. This component is usually built usually using end-user access tools, information
storage monitoring data source tools, custom built programs and facilities. The specific
complexness of is identified by services provided by end-user and equipment.
5. DETAILED INFORMATION
This particular region of the stockroom shops all the detailed details within the database
schema. Generally comprehensive data is not held on-line yet aggregated to another amount of
details. However the comprehensive information is extra frequently towards the warehouse to
dietary supplement the particular aggregated info.
6. EXTREMELY and SUMMERIZED DATA
The region from the info warehouse shops all of the predefined and summarized details
produced simply by supervisor. In this area usually transient as this changes on the basis of
query information. The objective of information is in order to accelerate the query
effectiveness. The particular data shall be up to date as new information is definitely loaded
into the factory continually.
7. ARCHIVE PLUS REGRESS TO SOMETHING EASIER information
This part of the storage facility stores detailed data to keep a back up of it. The data is usually
stored in devices like magnetic tapes or optic disks.
8. META INFORMATION
The information warehouse in addition shops all the Mean information explanations utilized by
all processes within the factory. It is used for various purpose which includes:
o The elimination plus loading process: Meta information is used in order to map
information sources to some common watch of information inside the warehouse.
o The warehouse management process -- Meta info is used in order to systemize the
production associated with overview tables.
o As component of Issue Management process Meta information is used to immediate the
query to the most suitable information source.
storage space into information stockroom tables
o Create indices plus views on the bottom desk.
o Renormalization
o Generation associated with aggregation
o Backing up plus archiving of details
o Within specific situations, the stockroom employer also produces question dating
profiles to figure out which indices and aggregations are appropriate.
four. QUERY MANAGER
The problem supervisor execute all procedures connected with administration of customer
questions. This component is usually built usually using end-user access tools, information
storage monitoring data source tools, custom built programs and facilities. The specific
complexness of is identified by services provided by end-user and equipment.
5. DETAILED INFORMATION
This particular region of the stockroom shops all the detailed details within the database
schema. Generally comprehensive data is not held on-line yet aggregated to another amount of
details. However the comprehensive information is extra frequently towards the warehouse to
dietary supplement the particular aggregated info.
6. EXTREMELY and SUMMERIZED DATA
The region from the info warehouse shops all of the predefined and summarized details
produced simply by supervisor. In this area usually transient as this changes on the basis of
query information. The objective of information is in order to accelerate the query
effectiveness. The particular data shall be up to date as new information is definitely loaded
into the factory continually.
7. ARCHIVE PLUS REGRESS TO SOMETHING EASIER information
This part of the storage facility stores detailed data to keep a back up of it. The data is usually
stored in devices like magnetic tapes or optic disks.
8. META INFORMATION
The information warehouse in addition shops all the Mean information explanations utilized by
all processes within the factory. It is used for various purpose which includes:
o The elimination plus loading process: Meta information is used in order to map
information sources to some common watch of information inside the warehouse.
o The warehouse management process -- Meta info is used in order to systemize the
production associated with overview tables.
o As component of Issue Management process Meta information is used to immediate the
query to the most suitable information source.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

The framework associated with Meta data can vary in each procedure, since the purpose is
several. Read more about Meta details will be talked about in the later Spiel Records.
9. END-USER ENTRY EQUIPMENT
The importance of information storage place is to provide info towards the continuing business
administrators intended for taking effective decision. These types of clients interact with the
storage service using end user access equipment. For example :-
u Query and Reporting
o Application Development Tools
o Executive Details Systems Tools
o Online Conditional Processing Tools
o Data Goal Tools
THE E in order to L (EXTRACT TRANSFORMATION LOAD) PROCESS
In this the 4 basic process of the details factory are discussed. They are extract (data through
the practical systems and supply this to database transform (the information into internal
format and building of the details warehouse), cleanse (to make sure it is connected with
sufficient quality to be used concerning choice making) and bodyweight (cleanse info is placed
into the information warehouse).
The 4 procedures from elimination via launching referred along since Information Staging often.
GET
A few information elements within functional database is quite being anticipated to be within
the option making, however other medication is associated with less value for the objective. For
this, it is crucial in order to extract relevant information through operational database just
before storing it. Several commercial tools can be found to assist with the extraction procedure.
For example information Junction. The user of one of the equipment generally has an
straightforward windowed interface :-
o Which files in addition tables are to be accessed inside the source database?
o Which locations are to be taken out from them? This really is done within by SQL Select
declaration often actually.
o What are those to be known as within the ending data bank?
o What could be the target machine plus directories format of the result?
o On what schedule if the removal process be repetitive?
CHANGE
The helpful directories created is based on different groups that can be changed with
specifications. Thus, data stockroom is created on basis of types of databases are usually
confronted with inconsistency amongst their data sources. Modify for better process manages
identifies any inconsistency
The popular modification issues is ‘Attribute Determining Inconsistency’. Worker Name may be
EMP_NAME in single database with ENAME in addition. Thus, one group of Information Names
are selected plus used consistently within database. Once element are given proper names they
can be converted into default format. The particular conversion might include the subsequent:
several. Read more about Meta details will be talked about in the later Spiel Records.
9. END-USER ENTRY EQUIPMENT
The importance of information storage place is to provide info towards the continuing business
administrators intended for taking effective decision. These types of clients interact with the
storage service using end user access equipment. For example :-
u Query and Reporting
o Application Development Tools
o Executive Details Systems Tools
o Online Conditional Processing Tools
o Data Goal Tools
THE E in order to L (EXTRACT TRANSFORMATION LOAD) PROCESS
In this the 4 basic process of the details factory are discussed. They are extract (data through
the practical systems and supply this to database transform (the information into internal
format and building of the details warehouse), cleanse (to make sure it is connected with
sufficient quality to be used concerning choice making) and bodyweight (cleanse info is placed
into the information warehouse).
The 4 procedures from elimination via launching referred along since Information Staging often.
GET
A few information elements within functional database is quite being anticipated to be within
the option making, however other medication is associated with less value for the objective. For
this, it is crucial in order to extract relevant information through operational database just
before storing it. Several commercial tools can be found to assist with the extraction procedure.
For example information Junction. The user of one of the equipment generally has an
straightforward windowed interface :-
o Which files in addition tables are to be accessed inside the source database?
o Which locations are to be taken out from them? This really is done within by SQL Select
declaration often actually.
o What are those to be known as within the ending data bank?
o What could be the target machine plus directories format of the result?
o On what schedule if the removal process be repetitive?
CHANGE
The helpful directories created is based on different groups that can be changed with
specifications. Thus, data stockroom is created on basis of types of databases are usually
confronted with inconsistency amongst their data sources. Modify for better process manages
identifies any inconsistency
The popular modification issues is ‘Attribute Determining Inconsistency’. Worker Name may be
EMP_NAME in single database with ENAME in addition. Thus, one group of Information Names
are selected plus used consistently within database. Once element are given proper names they
can be converted into default format. The particular conversion might include the subsequent:
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

o Characters should be converted ASCII to EBCDIC or vice versa.
o Mixed Text might be converted to all of uppercase for perseverance.
o Numerical info must be converted into a common file format.
o Data Structure has to be standard.
o ( versus ) Dimension might. (Rs/ $)
o Coded info (Male/ Female, M/F) must be changed into the typical format.
All these customization actions are automated and several industrial items can be applied.
DataMAPPER from Used Data source Technologies is one this type or even kind of
comprehensive tool.
CLEANING
To determine value of info, detail quality key can be used. The particular designer of the data
storage location is not usually in the place to change the quality of the underlying historical
data, although the data storage task can put spot light around the data quality problems plus
lead to improvements for future years. It is necessary to enter info in database so that there
error can be reduced. This method is known as Information Cleansing.
Information Cleansing must be done with true number of feasible errors. It consists of lacking
data and incorrect details at one resource; sporadic data and inconsistent details when two and
even more resource is involved. Moreover, many strategies can be implemented to clean info
that are mentioned in this report.
LOADING
Launching frequently implies physical motion from the data to system keeping source
database(s) to that particular that will store the data storage services database, assuming it is
numerous. After extraction this process occurs. The methods for details movement is high-
speed communication hyperlink. Ex: Oracle Warehouse Constructor is the API from Oracle, that
can be used to execute ETL job upon Oracle Information Storage place.
Skills for Professional Practice
Pivot table:
o Mixed Text might be converted to all of uppercase for perseverance.
o Numerical info must be converted into a common file format.
o Data Structure has to be standard.
o ( versus ) Dimension might. (Rs/ $)
o Coded info (Male/ Female, M/F) must be changed into the typical format.
All these customization actions are automated and several industrial items can be applied.
DataMAPPER from Used Data source Technologies is one this type or even kind of
comprehensive tool.
CLEANING
To determine value of info, detail quality key can be used. The particular designer of the data
storage location is not usually in the place to change the quality of the underlying historical
data, although the data storage task can put spot light around the data quality problems plus
lead to improvements for future years. It is necessary to enter info in database so that there
error can be reduced. This method is known as Information Cleansing.
Information Cleansing must be done with true number of feasible errors. It consists of lacking
data and incorrect details at one resource; sporadic data and inconsistent details when two and
even more resource is involved. Moreover, many strategies can be implemented to clean info
that are mentioned in this report.
LOADING
Launching frequently implies physical motion from the data to system keeping source
database(s) to that particular that will store the data storage services database, assuming it is
numerous. After extraction this process occurs. The methods for details movement is high-
speed communication hyperlink. Ex: Oracle Warehouse Constructor is the API from Oracle, that
can be used to execute ETL job upon Oracle Information Storage place.
Skills for Professional Practice
Pivot table:
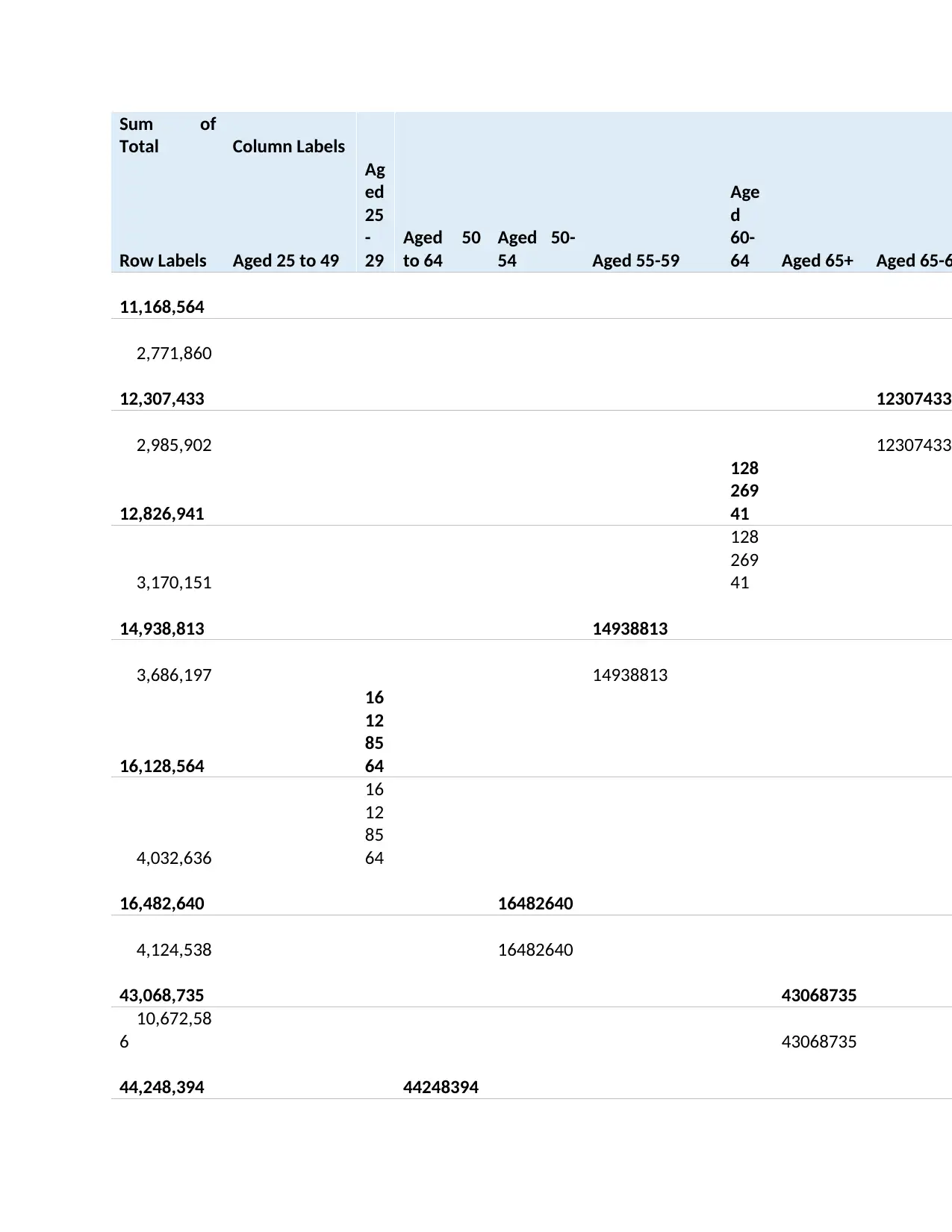
Sum of
Total Column Labels
Row Labels Aged 25 to 49
Ag
ed
25
-
29
Aged 50
to 64
Aged 50-
54 Aged 55-59
Age
d
60-
64 Aged 65+ Aged 65-6
11,168,564
2,771,860
12,307,433 12307433
2,985,902 12307433
12,826,941
128
269
41
3,170,151
128
269
41
14,938,813 14938813
3,686,197 14938813
16,128,564
16
12
85
64
4,032,636
16
12
85
64
16,482,640 16482640
4,124,538 16482640
43,068,735 43068735
10,672,58
6 43068735
44,248,394 44248394
Total Column Labels
Row Labels Aged 25 to 49
Ag
ed
25
-
29
Aged 50
to 64
Aged 50-
54 Aged 55-59
Age
d
60-
64 Aged 65+ Aged 65-6
11,168,564
2,771,860
12,307,433 12307433
2,985,902 12307433
12,826,941
128
269
41
3,170,151
128
269
41
14,938,813 14938813
3,686,197 14938813
16,128,564
16
12
85
64
4,032,636
16
12
85
64
16,482,640 16482640
4,124,538 16482640
43,068,735 43068735
10,672,58
6 43068735
44,248,394 44248394
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

10,985,21
4 44248394
77,930,753 77930753
19,469,63
1 77930753
235,782,007
58,754,76
1
Grand Total 77930753
16
12
85
64 44248394 16482640 14938813
128
269
41 43068735 12307433
Data mining with Weka:
Data mining is a concept that has emerged in today's business. It is a process of analyzing raw
data and transforming it into useful information. These features can be found in software
program like Weka. It is a data mining tool that helps in business to develop strategies in order
to deal with critical situations.
Weka filters the data by processing by visualizing it and applying algorithms to interpret the
outcomes. It also understands the evaluation by applying different methods.
Weka information mining PC is a gadget that will help business in breaking down data and
information more precisely. It is very simple and easy to use as it enable people to separate
specific information from variety of data. Along with this Weka helps in determining the
relationship between the sample of data that is collected from other registries.
Weka helps an endeavor achieve its fullest forthcoming. It is a method that determine how
company is getting impacted by specific qualities helps business to increase their profit and
avoid botches down the line. Basically, it is a process in which an organization dissect specific
data to get a proper view and aggregate it so that it can be analyzed that how company is
performing. Venture entrepreneurs can get a wide perspective and focus on client inclining.
The information may furthermore support in providing techniques that may allow business to
reduce expenses.
Using the data set supplied for working on Weka, various approaches are evaluated.
The explorer
It provides access to all facilities in Weka utilizing menu and shape filling. The information is
opened in Explorer and weight is given. Switch forward and between happens backward,
4 44248394
77,930,753 77930753
19,469,63
1 77930753
235,782,007
58,754,76
1
Grand Total 77930753
16
12
85
64 44248394 16482640 14938813
128
269
41 43068735 12307433
Data mining with Weka:
Data mining is a concept that has emerged in today's business. It is a process of analyzing raw
data and transforming it into useful information. These features can be found in software
program like Weka. It is a data mining tool that helps in business to develop strategies in order
to deal with critical situations.
Weka filters the data by processing by visualizing it and applying algorithms to interpret the
outcomes. It also understands the evaluation by applying different methods.
Weka information mining PC is a gadget that will help business in breaking down data and
information more precisely. It is very simple and easy to use as it enable people to separate
specific information from variety of data. Along with this Weka helps in determining the
relationship between the sample of data that is collected from other registries.
Weka helps an endeavor achieve its fullest forthcoming. It is a method that determine how
company is getting impacted by specific qualities helps business to increase their profit and
avoid botches down the line. Basically, it is a process in which an organization dissect specific
data to get a proper view and aggregate it so that it can be analyzed that how company is
performing. Venture entrepreneurs can get a wide perspective and focus on client inclining.
The information may furthermore support in providing techniques that may allow business to
reduce expenses.
Using the data set supplied for working on Weka, various approaches are evaluated.
The explorer
It provides access to all facilities in Weka utilizing menu and shape filling. The information is
opened in Explorer and weight is given. Switch forward and between happens backward,
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
evaluate models constructed on different datasets furthermore, image graphically both and
versions and datasets, counting characterization errors.
Preparing data:
Information can be in several file types: ARFF, CSV, C4. five...
Weka's local information stockpiling group is ARFF (Attribute-connection File form)
ARFF records have 2 places HEADER and DATA
HEADER:
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class Iris-setosa, Iris-versicolor, Iris-virginica
Launching the data:
For instance, particular Iris information to discover the next screen You'll see that Weka gives a
little information about some factual information about the qualities each one subsequently
The six tabs across the top are the fundamental procedures that the Voyager underpins
versions and datasets, counting characterization errors.
Preparing data:
Information can be in several file types: ARFF, CSV, C4. five...
Weka's local information stockpiling group is ARFF (Attribute-connection File form)
ARFF records have 2 places HEADER and DATA
HEADER:
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class Iris-setosa, Iris-versicolor, Iris-virginica
Launching the data:
For instance, particular Iris information to discover the next screen You'll see that Weka gives a
little information about some factual information about the qualities each one subsequently
The six tabs across the top are the fundamental procedures that the Voyager underpins
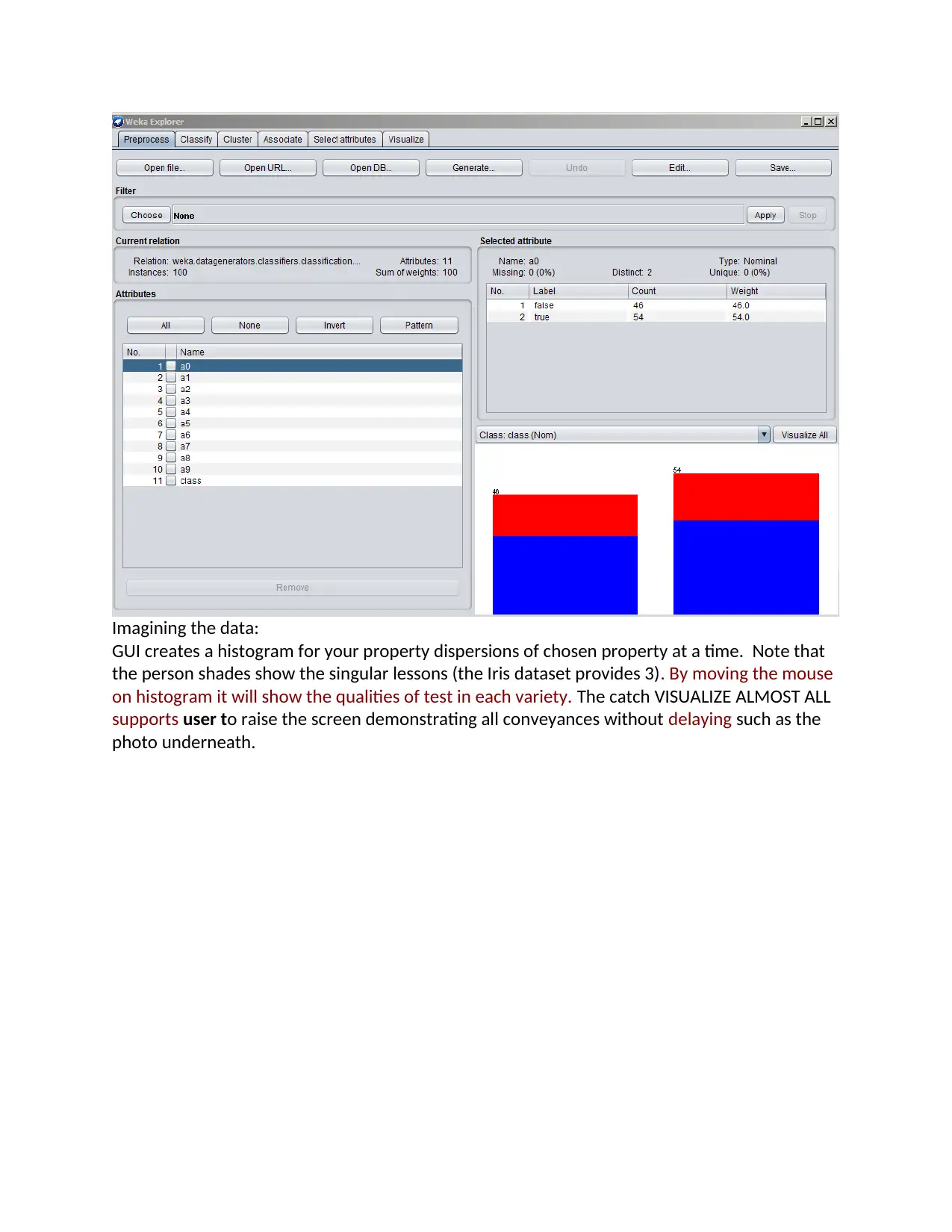
Imagining the data:
GUI creates a histogram for your property dispersions of chosen property at a time. Note that
the person shades show the singular lessons (the Iris dataset provides 3). By moving the mouse
on histogram it will show the qualities of test in each variety. The catch VISUALIZE ALMOST ALL
supports user to raise the screen demonstrating all conveyances without delaying such as the
photo underneath.
GUI creates a histogram for your property dispersions of chosen property at a time. Note that
the person shades show the singular lessons (the Iris dataset provides 3). By moving the mouse
on histogram it will show the qualities of test in each variety. The catch VISUALIZE ALMOST ALL
supports user to raise the screen demonstrating all conveyances without delaying such as the
photo underneath.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

There is another tab called IMAGINE which can be utilized to acquire the scatterplots for all
property sets. It is seen that in some illustrations the bunches as well as the diverse hues relate
to one another such in plots to get class sets as well as the petalwidth/petallength trait match,
while for different sets (sepalwidth/sepallength to get instance) it's much more difficult to
isolate the organizations by shading filters
Pre-preparing apparatuses in WEKA are the filters. This enables you to get rid of framework
without any need to control the report. In order to apply a filter, you need to choose compose
associated with it you'd like by going on the CHOOSE catch suitable underneath Filter
WEKA consists of different filters for: normalization, Resampling, Feature choice, Changing, etc.
Attributes selection:
Weka eliminates superfluous qualities as well as reduce the dimensionality of dataset. After
stacking a dataset, tap select credit tag to open a GUI that will pick both assessment technique,
(for instance, Principal Components Analysis and the pursuit technique. Contingent upon the
selected mix, the time spend on selecting characteristics can be shifted. for example , the
particular Iris information with simply five highlights (counting the particular class property) for
each from the 150 examples It is furthermore vital to take note of the not all assessment/look
strategy combines are substantial, maintain an optical eye to the mistake message in the
Standing bar. Will be certainly additionally an issue using Discretize while in the preprocessing
mode, which usually prompts false outcomes. Within the off chance that you have to employ
this channel, you are able to work around this using the Filtration system Classifier in the group
menus alternatively
property sets. It is seen that in some illustrations the bunches as well as the diverse hues relate
to one another such in plots to get class sets as well as the petalwidth/petallength trait match,
while for different sets (sepalwidth/sepallength to get instance) it's much more difficult to
isolate the organizations by shading filters
Pre-preparing apparatuses in WEKA are the filters. This enables you to get rid of framework
without any need to control the report. In order to apply a filter, you need to choose compose
associated with it you'd like by going on the CHOOSE catch suitable underneath Filter
WEKA consists of different filters for: normalization, Resampling, Feature choice, Changing, etc.
Attributes selection:
Weka eliminates superfluous qualities as well as reduce the dimensionality of dataset. After
stacking a dataset, tap select credit tag to open a GUI that will pick both assessment technique,
(for instance, Principal Components Analysis and the pursuit technique. Contingent upon the
selected mix, the time spend on selecting characteristics can be shifted. for example , the
particular Iris information with simply five highlights (counting the particular class property) for
each from the 150 examples It is furthermore vital to take note of the not all assessment/look
strategy combines are substantial, maintain an optical eye to the mistake message in the
Standing bar. Will be certainly additionally an issue using Discretize while in the preprocessing
mode, which usually prompts false outcomes. Within the off chance that you have to employ
this channel, you are able to work around this using the Filtration system Classifier in the group
menus alternatively
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
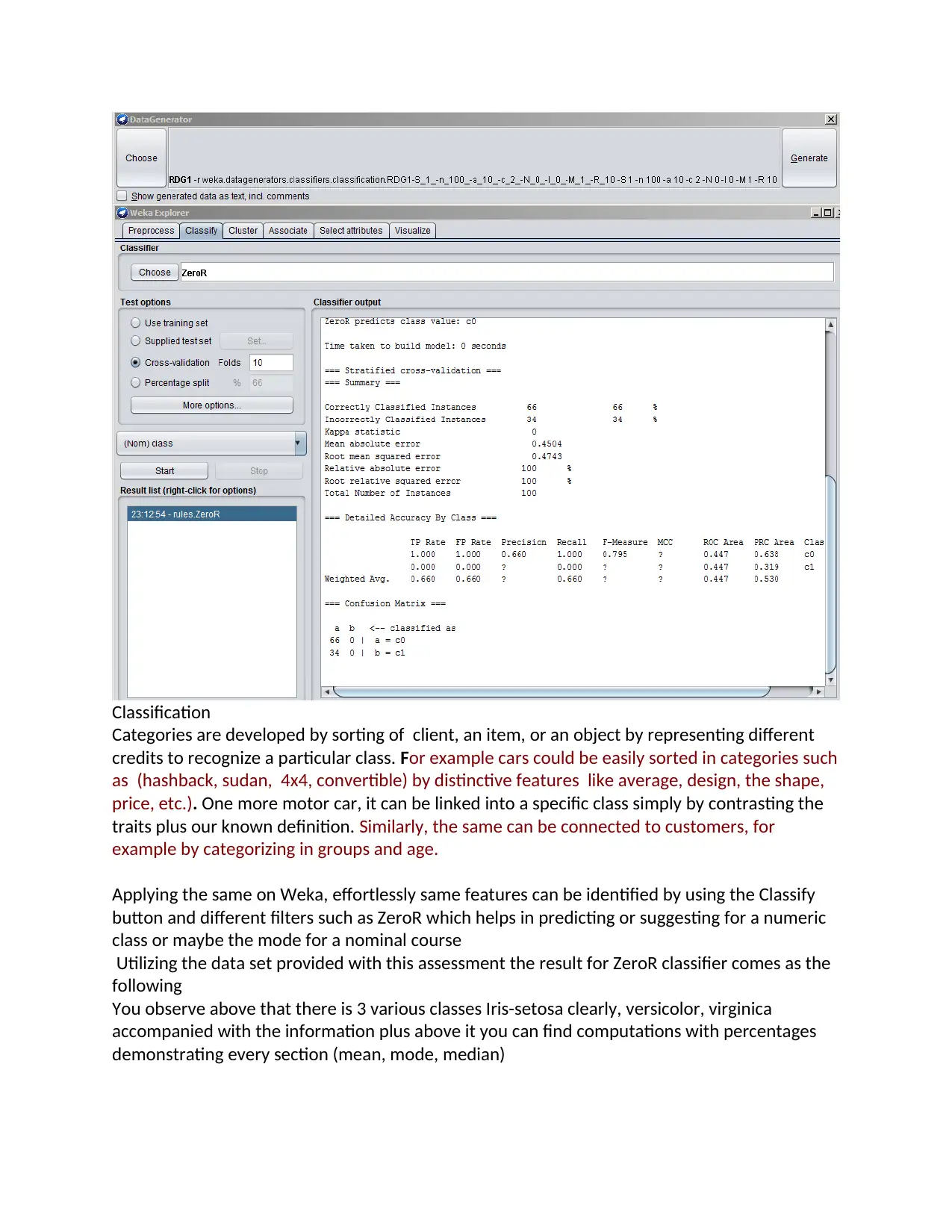
Classification
Categories are developed by sorting of client, an item, or an object by representing different
credits to recognize a particular class. For example cars could be easily sorted in categories such
as (hashback, sudan, 4x4, convertible) by distinctive features like average, design, the shape,
price, etc.). One more motor car, it can be linked into a specific class simply by contrasting the
traits plus our known definition. Similarly, the same can be connected to customers, for
example by categorizing in groups and age.
Applying the same on Weka, effortlessly same features can be identified by using the Classify
button and different filters such as ZeroR which helps in predicting or suggesting for a numeric
class or maybe the mode for a nominal course
Utilizing the data set provided with this assessment the result for ZeroR classifier comes as the
following
You observe above that there is 3 various classes Iris-setosa clearly, versicolor, virginica
accompanied with the information plus above it you can find computations with percentages
demonstrating every section (mean, mode, median)
Categories are developed by sorting of client, an item, or an object by representing different
credits to recognize a particular class. For example cars could be easily sorted in categories such
as (hashback, sudan, 4x4, convertible) by distinctive features like average, design, the shape,
price, etc.). One more motor car, it can be linked into a specific class simply by contrasting the
traits plus our known definition. Similarly, the same can be connected to customers, for
example by categorizing in groups and age.
Applying the same on Weka, effortlessly same features can be identified by using the Classify
button and different filters such as ZeroR which helps in predicting or suggesting for a numeric
class or maybe the mode for a nominal course
Utilizing the data set provided with this assessment the result for ZeroR classifier comes as the
following
You observe above that there is 3 various classes Iris-setosa clearly, versicolor, virginica
accompanied with the information plus above it you can find computations with percentages
demonstrating every section (mean, mode, median)
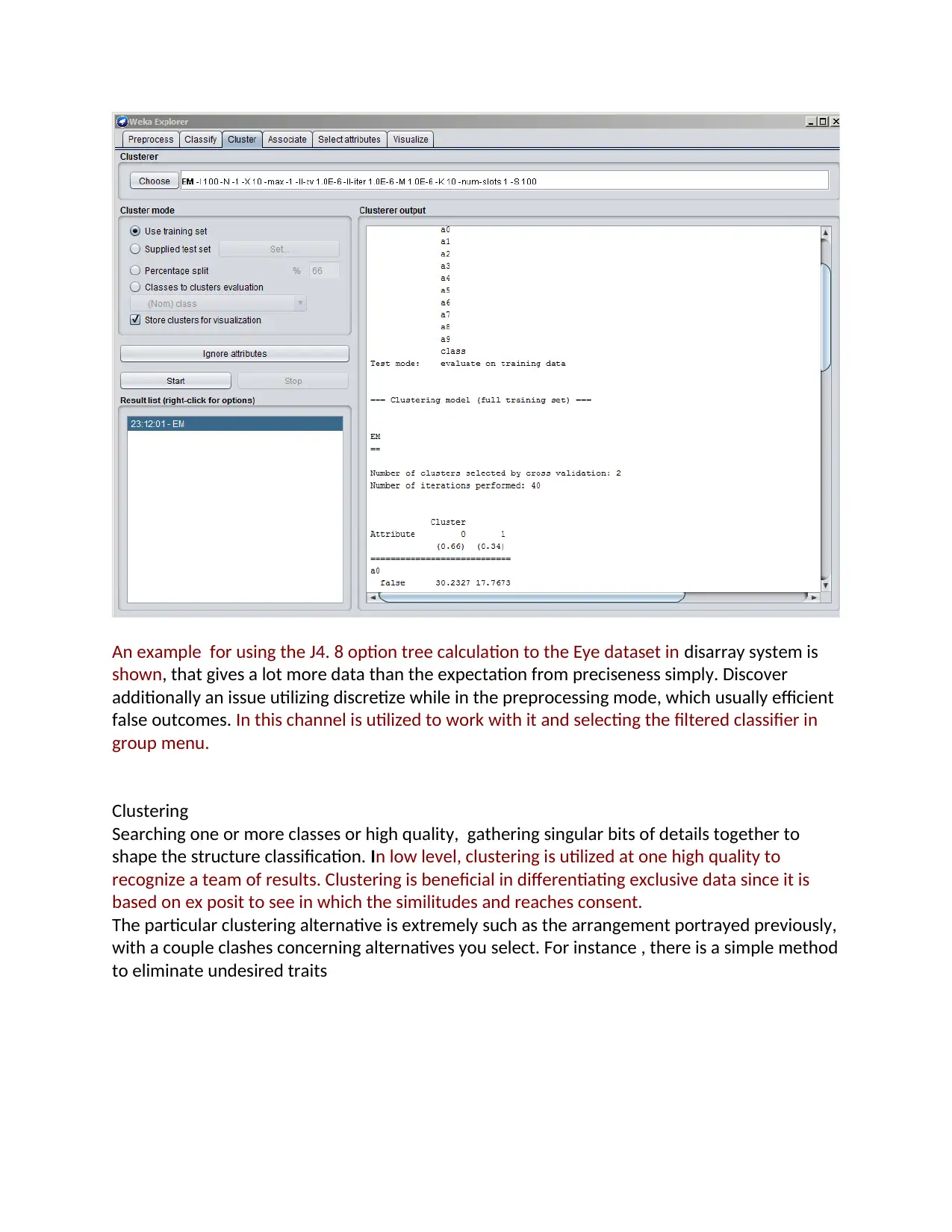
An example for using the J4. 8 option tree calculation to the Eye dataset in disarray system is
shown, that gives a lot more data than the expectation from preciseness simply. Discover
additionally an issue utilizing discretize while in the preprocessing mode, which usually efficient
false outcomes. In this channel is utilized to work with it and selecting the filtered classifier in
group menu.
Clustering
Searching one or more classes or high quality, gathering singular bits of details together to
shape the structure classification. In low level, clustering is utilized at one high quality to
recognize a team of results. Clustering is beneficial in differentiating exclusive data since it is
based on ex posit to see in which the similitudes and reaches consent.
The particular clustering alternative is extremely such as the arrangement portrayed previously,
with a couple clashes concerning alternatives you select. For instance , there is a simple method
to eliminate undesired traits
shown, that gives a lot more data than the expectation from preciseness simply. Discover
additionally an issue utilizing discretize while in the preprocessing mode, which usually efficient
false outcomes. In this channel is utilized to work with it and selecting the filtered classifier in
group menu.
Clustering
Searching one or more classes or high quality, gathering singular bits of details together to
shape the structure classification. In low level, clustering is utilized at one high quality to
recognize a team of results. Clustering is beneficial in differentiating exclusive data since it is
based on ex posit to see in which the similitudes and reaches consent.
The particular clustering alternative is extremely such as the arrangement portrayed previously,
with a couple clashes concerning alternatives you select. For instance , there is a simple method
to eliminate undesired traits
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide
1 out of 16
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.