DMKD Assignment: Critical Analysis of Density-Based Clustering
VerifiedAdded on 2023/06/13
|11
|9222
|377
Report
AI Summary
This paper presents a critical analysis of the article "A Density-Based Algorithm for Discovering Clusters" by Ester et al., focusing on the DBSCAN algorithm's effectiveness in spatial databases. It evaluates the context before the paper's publication, highlighting the importance of clustering algorithms in identifying classes within spatial data. The critique discusses the paper's proposed solution for discovering clusters using density-based approaches, comparing DBSCAN with CLARANS. It further explores subsequent research influenced by the paper, unresolved questions, and interesting points, concluding that while DBSCAN is efficient, it has limitations with large spatial databases. The analysis emphasizes the need for improved clustering algorithms to handle increasing data sizes and complex data arrangements, providing a balanced view of the paper's contributions and areas for further research. Desklib is a great platform to find such solved assignments and study tools.

Critique of an Article – A Density Based Algorithm for Discovering
Clusters
(Name of the Student)
(Name of the University)
(Email of the Student)
Abstract
The following paper will present the critical analysis or
critique of an article based on the journal “A Density
Based Algorithm for Discovering Clusters” by Martin
Ester, Hans-Peter Kriegel, Jiirg Sander, Xiaowei Xu. This
article was published in favour of the University of
Munich, Institute of Computer Science. The article
focuses on clustering algorithm and its related aspects that
are discussed briefly and provides some relevant
information. The clustering algorithm is an essential to
identify classes in spatial databases. The article majorly
discusses clustering algorithm in terms of class
identification. The clustering algorithms as per the article
are of two types, hierarchical and partitioning. The
requirements for clustering algorithm for identifying
classes in spatial databases are required to enhance the
identification for huge spatial databases. The clustering
algorithms are of other types also that are discussed in this
paper and they are CLARANS and DBSCAN. The
CLARANS is Clustering Large Applications based on
RANdomized Search. The DBSCAN is Density Based
Spatial Clustering of Applications with Noise. This article
wants to convey the comparison of CLARANS and
DBSCAN to understand its effect to discover clusters.
The evaluation of DBSCAN and CLARANS in terms of
their performance are presented in this article to
understand their effectiveness and efficiency to discover
and identify clusters. This is being article criticized to
evaluate the justification and relevance of the topic that it
proposes given the recent context. This would be done in
several processes. The situation before the publication is
justified in this regard and this presented the importance
of the paper in relevance to the modern times. The
solution that the paper provides regarding the discovery of
clusters by noise process in large and spatial databases is
briefly stated after in the journal. The paper describes the
subsequent papers and systems that flow from this paper
and also the unresolved open questions that the paper still
needs to answer. Finally, the paper also describes the
other interesting points regarding this paper. The
clustering algorithm is a relevant solution in the
identification of the spiral database. However, the
clustering algorithm does not efficient for those who does
not have good domain knowledge and in certain cases it
does not provide efficient solutions for all the problems.
In order to overcome these disadvantages a new model of
clustering algorithm has been proposed. The name of this
clustering algorithm is DBSCAN. The efficiency of the
proposed DBSCAN is experimented on the real data set
of SEQUOIA 2000 benchmark. The comparison of the
DBSCAN is done with the other clustering algorithm
CLARANS. The result of the experiment indicates that
the DBSCAN is more successful in finding the clusters of
arbitrary shape compared to CLARANS. DBSACN is 100
times efficient than the CLARANS.
Keywords: Critique, Article, Journal, Database,
Clustering technique, Density based Algorithm
1 Introduction
A critique of an article is just not the criticism of the
article but the critical analysis of the article in a specific
style for the given article. This style helps in the
identification, evaluation and response to the author’s
idea depicting both the positive and the negative
approaches of it. The entire idea of the critique is to make
sure that the journal that has been presented, depicts the
proper view of the topic and if the article focuses on all
the relevant information that is proposed in the article,
then it would be declared that the article is justified to its
terms. In this critical analysis for the article, “A Density
Based Algorithm for Discovering Clusters” by Martin
Ester, Hans-Peter Kriegel, Jiirg Sander, Xiaowei Xu this
would be applicable for clarifying the justification for the
journal article. This would be done with the following
processes (Shirkhorshidi et al. 2014). The critique would
begin with justifying the situation that has been in vogue
before the article was presented regarding the topic of the
article (Aghabozorgi, Shirkhorshidi and Wah 2015). Then
it would present the importance of the paper and describe
in brief about the sketch that the article presents about
solving the problem in the journal. It would then focus on
the article and researches that has started inflowing after
the article under critical analysis has been presented. The
paper would then follow the article for the unresolved
questions it has yet to answer, if any, about the subject
(Shirkhorshidi et al. 2014). The algorithm used in the
DBSCAN retrieves all the points reachable from the p
wrt, Eps and Minpts. In case if p is the core point the
procedures results to cluster wrt. In case if p is the
broader point no point can be density reachable from p to
DBSCAN.
Clusters
(Name of the Student)
(Name of the University)
(Email of the Student)
Abstract
The following paper will present the critical analysis or
critique of an article based on the journal “A Density
Based Algorithm for Discovering Clusters” by Martin
Ester, Hans-Peter Kriegel, Jiirg Sander, Xiaowei Xu. This
article was published in favour of the University of
Munich, Institute of Computer Science. The article
focuses on clustering algorithm and its related aspects that
are discussed briefly and provides some relevant
information. The clustering algorithm is an essential to
identify classes in spatial databases. The article majorly
discusses clustering algorithm in terms of class
identification. The clustering algorithms as per the article
are of two types, hierarchical and partitioning. The
requirements for clustering algorithm for identifying
classes in spatial databases are required to enhance the
identification for huge spatial databases. The clustering
algorithms are of other types also that are discussed in this
paper and they are CLARANS and DBSCAN. The
CLARANS is Clustering Large Applications based on
RANdomized Search. The DBSCAN is Density Based
Spatial Clustering of Applications with Noise. This article
wants to convey the comparison of CLARANS and
DBSCAN to understand its effect to discover clusters.
The evaluation of DBSCAN and CLARANS in terms of
their performance are presented in this article to
understand their effectiveness and efficiency to discover
and identify clusters. This is being article criticized to
evaluate the justification and relevance of the topic that it
proposes given the recent context. This would be done in
several processes. The situation before the publication is
justified in this regard and this presented the importance
of the paper in relevance to the modern times. The
solution that the paper provides regarding the discovery of
clusters by noise process in large and spatial databases is
briefly stated after in the journal. The paper describes the
subsequent papers and systems that flow from this paper
and also the unresolved open questions that the paper still
needs to answer. Finally, the paper also describes the
other interesting points regarding this paper. The
clustering algorithm is a relevant solution in the
identification of the spiral database. However, the
clustering algorithm does not efficient for those who does
not have good domain knowledge and in certain cases it
does not provide efficient solutions for all the problems.
In order to overcome these disadvantages a new model of
clustering algorithm has been proposed. The name of this
clustering algorithm is DBSCAN. The efficiency of the
proposed DBSCAN is experimented on the real data set
of SEQUOIA 2000 benchmark. The comparison of the
DBSCAN is done with the other clustering algorithm
CLARANS. The result of the experiment indicates that
the DBSCAN is more successful in finding the clusters of
arbitrary shape compared to CLARANS. DBSACN is 100
times efficient than the CLARANS.
Keywords: Critique, Article, Journal, Database,
Clustering technique, Density based Algorithm
1 Introduction
A critique of an article is just not the criticism of the
article but the critical analysis of the article in a specific
style for the given article. This style helps in the
identification, evaluation and response to the author’s
idea depicting both the positive and the negative
approaches of it. The entire idea of the critique is to make
sure that the journal that has been presented, depicts the
proper view of the topic and if the article focuses on all
the relevant information that is proposed in the article,
then it would be declared that the article is justified to its
terms. In this critical analysis for the article, “A Density
Based Algorithm for Discovering Clusters” by Martin
Ester, Hans-Peter Kriegel, Jiirg Sander, Xiaowei Xu this
would be applicable for clarifying the justification for the
journal article. This would be done with the following
processes (Shirkhorshidi et al. 2014). The critique would
begin with justifying the situation that has been in vogue
before the article was presented regarding the topic of the
article (Aghabozorgi, Shirkhorshidi and Wah 2015). Then
it would present the importance of the paper and describe
in brief about the sketch that the article presents about
solving the problem in the journal. It would then focus on
the article and researches that has started inflowing after
the article under critical analysis has been presented. The
paper would then follow the article for the unresolved
questions it has yet to answer, if any, about the subject
(Shirkhorshidi et al. 2014). The algorithm used in the
DBSCAN retrieves all the points reachable from the p
wrt, Eps and Minpts. In case if p is the core point the
procedures results to cluster wrt. In case if p is the
broader point no point can be density reachable from p to
DBSCAN.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

Figure 1: Density Based Clustering Basic Idea
(Source: Sajana, Rani and Narayana 2016)
Finally, the critique would conclude with describing any
other important fact that the article has put up. In the
previous papers the introduction about the management
of the spatial data has been mentioned in an efficient
manner (Aghabozorgi, Shirkhorshidi and Wah 2015). The
basic knowledge about the spatial data and the related
terms are required to understand the significance of the
content in the paper and to measure the gap between
already researched article and the proposed research
model. In knowledge discovery database, there are
several tasks. However, this article deals with the class
identification which includes the grouping of data from
classes into a subclass. Clustering algorithms are helpful
in the identification of class. The essential requirements
desirable in the clustering algorithm are- the algorithm
can be handled with the little domain knowledge, the
algorithm can discover the arbitrary shape and is efficient
to store large amount of data.
The performance evaluation taken place in the article
has not taken into account the point objects that are also a
part of database. The objects are of different sizes and
nature residing in spatial database. They are characterized
as per their density and behavior. These data are not only
arranged in a sequential form; they can be in any form of
arrangement. These pose challenges for clustering
algorithm to discover clusters and noises. Although there
are clustering algorithms, still there are loopholes in these
algorithms. The large sized spatial database is still a
major factor in cluster algorithms as the objects in spatial
database are increasing day by day and so its
arrangement. Hence, the arrangement of objects should
be evaluated to discover clusters and noise. The large
sized spatial database is arranged randomly and hence
clustering algorithms require more improved feature to
discover clusters and noises.
The article presents evaluation of clusters in spatial
database through notions based on density. This is
essential as density determines the objects in database in
a detailed way where it will help to discover clusters and
noises. The object in a cluster forms are arranged in a
spatial database where density is determined through
neighboring objects in the spatial database. The density
determination is helpful in discovering clusters and noises
in spatial database. The different notions of clusters based
on density are defines to understand how the clusters are
discovered. These definitions help to understand that
objects in a cluster form in spatial database are analyzed
through distances between the objects and its neighboring
objects.
The article concludes that DBSCAN is far better than
CLARANS by a 100 factor. This 100 factors describes
the efficiency of discovering clusters in spatial databases.
However, DBSCAN suffers from several drawbacks that
are described in this article. Hence, it is advisable to take
into account the issues raised from DBSCAN algorithm.
Therefore, it shows that DBSCAN is far better and it can
be used for discovering clustering and noise in spatial
databases. The spatial databases which are large in size
are however not suitable for DBSCAN. Hence, there is a
need to determine the large sized spatial databases
evaluation with DBSCAN. This will open up more
detailed evaluation of DBSCAN and this should be
valuable to determine the loopholes in DBSCAN. The
CLARANS are not valuable up to a limit as it assumes
that main memory can have objects residing in the
memory in a clustered form. However, this assumption is
not the case in large sized spatial databases. The clusters
and noise are determined in spatial database to understand
the behavior of data in the real world. The clusters help to
evaluate the density of the objects in the database that in
return provides the valuable presentation of objects in real
space. The clusters and noise are important to be
evaluated in terms of its performance to get hold on the
objects in the databases. This will helps to present objects
in more sophisticated way in the real space.
2 Situation before publication of the paper
A cluster is usually a multiple and coordinated computer
or server appearing to the user or concerned applications
as a single server. There have been evidences in literature
about finding clusters in the spatial databases. There have
been evidences that the use of Knowledge Discovery in
Databases or KDD have been used in this purpose. There
are a number of applications that have been utilized for
managing a spatial data (Kumar and Reddy 2016). While
defining a spatial data, it can be said that it this data has a
relation to the space and the management of the spatial
data can be classified as Spatial Database Systems or
SDBS (Ozkok and Celik 2017). These data include the
huge amount of data that have been acquired from the
images from the satellites, the X-rays crystallography and
other automatic equipments that captures the data
obtained from space. The utilization of KDD process is
one of the chief discoveries that were noted in other
(Source: Sajana, Rani and Narayana 2016)
Finally, the critique would conclude with describing any
other important fact that the article has put up. In the
previous papers the introduction about the management
of the spatial data has been mentioned in an efficient
manner (Aghabozorgi, Shirkhorshidi and Wah 2015). The
basic knowledge about the spatial data and the related
terms are required to understand the significance of the
content in the paper and to measure the gap between
already researched article and the proposed research
model. In knowledge discovery database, there are
several tasks. However, this article deals with the class
identification which includes the grouping of data from
classes into a subclass. Clustering algorithms are helpful
in the identification of class. The essential requirements
desirable in the clustering algorithm are- the algorithm
can be handled with the little domain knowledge, the
algorithm can discover the arbitrary shape and is efficient
to store large amount of data.
The performance evaluation taken place in the article
has not taken into account the point objects that are also a
part of database. The objects are of different sizes and
nature residing in spatial database. They are characterized
as per their density and behavior. These data are not only
arranged in a sequential form; they can be in any form of
arrangement. These pose challenges for clustering
algorithm to discover clusters and noises. Although there
are clustering algorithms, still there are loopholes in these
algorithms. The large sized spatial database is still a
major factor in cluster algorithms as the objects in spatial
database are increasing day by day and so its
arrangement. Hence, the arrangement of objects should
be evaluated to discover clusters and noise. The large
sized spatial database is arranged randomly and hence
clustering algorithms require more improved feature to
discover clusters and noises.
The article presents evaluation of clusters in spatial
database through notions based on density. This is
essential as density determines the objects in database in
a detailed way where it will help to discover clusters and
noises. The object in a cluster forms are arranged in a
spatial database where density is determined through
neighboring objects in the spatial database. The density
determination is helpful in discovering clusters and noises
in spatial database. The different notions of clusters based
on density are defines to understand how the clusters are
discovered. These definitions help to understand that
objects in a cluster form in spatial database are analyzed
through distances between the objects and its neighboring
objects.
The article concludes that DBSCAN is far better than
CLARANS by a 100 factor. This 100 factors describes
the efficiency of discovering clusters in spatial databases.
However, DBSCAN suffers from several drawbacks that
are described in this article. Hence, it is advisable to take
into account the issues raised from DBSCAN algorithm.
Therefore, it shows that DBSCAN is far better and it can
be used for discovering clustering and noise in spatial
databases. The spatial databases which are large in size
are however not suitable for DBSCAN. Hence, there is a
need to determine the large sized spatial databases
evaluation with DBSCAN. This will open up more
detailed evaluation of DBSCAN and this should be
valuable to determine the loopholes in DBSCAN. The
CLARANS are not valuable up to a limit as it assumes
that main memory can have objects residing in the
memory in a clustered form. However, this assumption is
not the case in large sized spatial databases. The clusters
and noise are determined in spatial database to understand
the behavior of data in the real world. The clusters help to
evaluate the density of the objects in the database that in
return provides the valuable presentation of objects in real
space. The clusters and noise are important to be
evaluated in terms of its performance to get hold on the
objects in the databases. This will helps to present objects
in more sophisticated way in the real space.
2 Situation before publication of the paper
A cluster is usually a multiple and coordinated computer
or server appearing to the user or concerned applications
as a single server. There have been evidences in literature
about finding clusters in the spatial databases. There have
been evidences that the use of Knowledge Discovery in
Databases or KDD have been used in this purpose. There
are a number of applications that have been utilized for
managing a spatial data (Kumar and Reddy 2016). While
defining a spatial data, it can be said that it this data has a
relation to the space and the management of the spatial
data can be classified as Spatial Database Systems or
SDBS (Ozkok and Celik 2017). These data include the
huge amount of data that have been acquired from the
images from the satellites, the X-rays crystallography and
other automatic equipments that captures the data
obtained from space. The utilization of KDD process is
one of the chief discoveries that were noted in other

journals before the publication of the journal under
critique. It is a process defined to be discovering the data
that are potentially useful in finding patterns amongst the
huge pile of database.
The trend detection in this process is done with the help
of various processes (Ferrari and De Castro 2015). There
are relatable proofs that there happens to be a major point
of difference between pattern detection by KDD and the
process of rational databases. The difference is that, the
attributes of the neighbouring objects of interests has a
prominent effect on the very object. The researches have
also found that the algorithms for detecting pattern in
spatial databases depends a whole lot on the processing of
the neighbourhood relations effectively (Khan et al.
2014). This is because, the relations of the neighbourhood
needs to be taken into consideration to investigate several
objects in the single run for a typical algorithm. Thus, the
journal article under critical review essentially puts
forwards the latest technology of finding patterns in the
spatial data, but there have been other discoveries made
on the same topic about pattern detection in the earlier
times as well as per literary sources. Therefore, it can be
said that the topic was implemented before, but the
journal under critique has put it a step forward in
specifying the technique in use. The paper has proposed a
new clustering algorithm which can be used for
maintaining the database in an efficient way. This
proposed algorithm has all the necessary requirements
needed for a good clustering algorithm. The comparison
of the proposed algorithm with the other clustering
algorithm indicates that the new algorithm is more
efficient than the previous ones.
3 Importance of the paper
The paper that is being critically reviewed and analysed
has focused on the topic of discovering clusters in a
spatial database with the use of density based algorithm is
one of the most important implementation of advanced
technology (Deng et al. 2015). Clustering algorithms are
also important for identifying a class. Although, it is
important that the clustering algorithm for spatial
database requires minimum knowledge about the specific
domain for determining and the discovery of clusters that
have arbitrary shapes and this would ensure that the
person handling the data has a good efficiency (Yuan et
al. 2017). The discovery of this new technique has
resulted in the findings that the clustering algorithms that
were in vogue since the previous times offer no feasible
solution according to the combination of these
requirements.
The paper presents the discovery of a new clustering
algorithm called DBSCAN that depends on the notions
that are based on the density of the cluster notions
designed for the discovery of clusters having an arbitrary
shape (Friedman et al. 2015). The paper also puts forward
the fact that the implementation of this new method
called DBSCAN requires only one of the input
parameters. This parameter supports the user in
determining an appropriate value for the cluster
identification process. The fact that this paper again
spotlights on that the evaluation and utilization of this
process have been clarified as effective with an
experimental evaluation of the sequential data as well as
the real data following the benchmark of SEQUIA 2000
and its real data (Ester et al. 1996). According to the
paper, the results of the experimental evaluation have
suggested that the DEBSCAN is a far effective process in
discovery of the clusters having a vague and arbitrary
shape than the previously implemented algorithm of
CLARANS. It also states the fact that DBSCAN has been
able to successfully outperform the previously utilized
algorithm of CLARANS by a long shot, almost by 100
terms as far as the efficiency of the algorithm is
concerned (Ahmed and Razak 2016). Therefore, it can be
stated that the purpose of this paper is evidently essential
and important since it puts forward a very mandatory
issue of implementing a new technology of the algorithm
called DBSCAN in identifying arbitrary clusters that is
much more effective than the traditional implantation of
the CLARANS algorithm utilized for the same task. The
significant work done by this paper is that it shows a
comparison between DBSCAN and CLARANS with
respect to the working principals and the effective results.
CLARANS assumes that all the clustered objects can
reside into the same space of the memory. This algorithm
also uses hierarchical algorithm. The hierarchical
algorithm decomposes the D. However, there is a
problem of using hierarchical algorithm as it is difficult to
derive the parameter for termination condition. The
automatic termination condition used in the signal
processing is proposed by Ejclustercan eliminate this
problem. The further experiments show that this
algorithm is helpful in discovering the non-convex
clusters. This approach is helpful in identification of the
pattern.
Another approach for identification of cluster is k-
dimensional point sets. In this method the data set is
splitted in to certain cells. However, in this system the
space and run time requirement is huge, which is not
desirable.
The importance of the paper lies on the identification
of the new cluster algorithm which will server efficiently
and will eliminate all the drawbacks of the existing
clustering algorithm. The clustering algorithm mainly
based on the hierarchical approach which requires the
domain knowledge of the application. In many cases the
application does not have the required knowledge. The
second drawback of the existing clustering algorithm is
that it does not provide the distinctive cluster space.
DBSCAN has helped to overcome these problems by
maintaining the partitioning algorithm. The success of the
DBSCAN is that it serves the clustering of the dataset
along with the effective identification of the class.
critique. It is a process defined to be discovering the data
that are potentially useful in finding patterns amongst the
huge pile of database.
The trend detection in this process is done with the help
of various processes (Ferrari and De Castro 2015). There
are relatable proofs that there happens to be a major point
of difference between pattern detection by KDD and the
process of rational databases. The difference is that, the
attributes of the neighbouring objects of interests has a
prominent effect on the very object. The researches have
also found that the algorithms for detecting pattern in
spatial databases depends a whole lot on the processing of
the neighbourhood relations effectively (Khan et al.
2014). This is because, the relations of the neighbourhood
needs to be taken into consideration to investigate several
objects in the single run for a typical algorithm. Thus, the
journal article under critical review essentially puts
forwards the latest technology of finding patterns in the
spatial data, but there have been other discoveries made
on the same topic about pattern detection in the earlier
times as well as per literary sources. Therefore, it can be
said that the topic was implemented before, but the
journal under critique has put it a step forward in
specifying the technique in use. The paper has proposed a
new clustering algorithm which can be used for
maintaining the database in an efficient way. This
proposed algorithm has all the necessary requirements
needed for a good clustering algorithm. The comparison
of the proposed algorithm with the other clustering
algorithm indicates that the new algorithm is more
efficient than the previous ones.
3 Importance of the paper
The paper that is being critically reviewed and analysed
has focused on the topic of discovering clusters in a
spatial database with the use of density based algorithm is
one of the most important implementation of advanced
technology (Deng et al. 2015). Clustering algorithms are
also important for identifying a class. Although, it is
important that the clustering algorithm for spatial
database requires minimum knowledge about the specific
domain for determining and the discovery of clusters that
have arbitrary shapes and this would ensure that the
person handling the data has a good efficiency (Yuan et
al. 2017). The discovery of this new technique has
resulted in the findings that the clustering algorithms that
were in vogue since the previous times offer no feasible
solution according to the combination of these
requirements.
The paper presents the discovery of a new clustering
algorithm called DBSCAN that depends on the notions
that are based on the density of the cluster notions
designed for the discovery of clusters having an arbitrary
shape (Friedman et al. 2015). The paper also puts forward
the fact that the implementation of this new method
called DBSCAN requires only one of the input
parameters. This parameter supports the user in
determining an appropriate value for the cluster
identification process. The fact that this paper again
spotlights on that the evaluation and utilization of this
process have been clarified as effective with an
experimental evaluation of the sequential data as well as
the real data following the benchmark of SEQUIA 2000
and its real data (Ester et al. 1996). According to the
paper, the results of the experimental evaluation have
suggested that the DEBSCAN is a far effective process in
discovery of the clusters having a vague and arbitrary
shape than the previously implemented algorithm of
CLARANS. It also states the fact that DBSCAN has been
able to successfully outperform the previously utilized
algorithm of CLARANS by a long shot, almost by 100
terms as far as the efficiency of the algorithm is
concerned (Ahmed and Razak 2016). Therefore, it can be
stated that the purpose of this paper is evidently essential
and important since it puts forward a very mandatory
issue of implementing a new technology of the algorithm
called DBSCAN in identifying arbitrary clusters that is
much more effective than the traditional implantation of
the CLARANS algorithm utilized for the same task. The
significant work done by this paper is that it shows a
comparison between DBSCAN and CLARANS with
respect to the working principals and the effective results.
CLARANS assumes that all the clustered objects can
reside into the same space of the memory. This algorithm
also uses hierarchical algorithm. The hierarchical
algorithm decomposes the D. However, there is a
problem of using hierarchical algorithm as it is difficult to
derive the parameter for termination condition. The
automatic termination condition used in the signal
processing is proposed by Ejclustercan eliminate this
problem. The further experiments show that this
algorithm is helpful in discovering the non-convex
clusters. This approach is helpful in identification of the
pattern.
Another approach for identification of cluster is k-
dimensional point sets. In this method the data set is
splitted in to certain cells. However, in this system the
space and run time requirement is huge, which is not
desirable.
The importance of the paper lies on the identification
of the new cluster algorithm which will server efficiently
and will eliminate all the drawbacks of the existing
clustering algorithm. The clustering algorithm mainly
based on the hierarchical approach which requires the
domain knowledge of the application. In many cases the
application does not have the required knowledge. The
second drawback of the existing clustering algorithm is
that it does not provide the distinctive cluster space.
DBSCAN has helped to overcome these problems by
maintaining the partitioning algorithm. The success of the
DBSCAN is that it serves the clustering of the dataset
along with the effective identification of the class.
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

4 Brief sketch of the solution proposed by the
paper
Data clustering plans to portion a database into gatherings
of articles in light of the closeness among these items.
Because of its unsupervised nature, the look for a decent
quality arrangement can turn into an unpredictable
procedure. Meta-learning brings the idea of finding out
about realizing; that is, the meta-information got from the
algorithm learning process permits the change of the
algorithm execution. Meta-learning has a noteworthy
crossing point with data mining in characterization issues,
in which it is ordinarily used to prescribe algorithms.
There is right now an extensive variety of clustering
algorithms, and choosing the best one for a given issue
can be a moderate and expensive process. In 1976, Rice
planned the Algorithm Selection Problem (ASP), which
proposes that the algorithm execution can be anticipated
in light of the basic attributes of the issue. The present
paper proposes better approaches to acquire meta-
information for clustering errands. In particular, two
commitments are investigated: (1) another way to deal
with portray clustering issues in view of the
comparability among articles; and (2) new methods to
join inside lists for positioning algorithms in light of their
execution on the issues. Examinations were led to assess
the suggestion quality. The outcomes demonstrate that the
new meta-learning gives great algorithm determination to
clustering assignments.
Density based algorithm OPTICS (requesting focuses to
distinguish the clustering structure) is presented by a few
researchers which figures an enlarged bunch requesting
for programmed and intelligent group examinations.
Consequently another algorithm DENCLUE (Density
based Clustering) proposed by a few researchers, models
the general point density logically as the total of influence
works the data focuses. This density based algorithm
gives a reduced scientific portrayal of discretionarily
formed groups in high dimensional datasets and is
essentially speedier than its partner algorithms. Both
DBSCAN and OPTICS investigate the area of a question,
and both rely upon spatial record structure, for example,
R*-tree or X-tree to effectively process the area inquiries.
Since the proficiency of noting these inquiries with these
records diminishes with increment in the quantity of
measurements, the two methods are wasteful for high-
dimensional data. A cross breed clustering algorithm
BRIDGE incorporates the k-means and DBSCAN. The
BRIDGE empowers the DBSCAN to deal with vast
databases and at the same time increment the execution of
kmeans by disposing of commotion. A few researchers
proposed a versatile density based clustering (ADBC)
algorithm that utilizations versatile procedure (in view of
spatial question dissemination) for neighbor choice to
enhance clustering exactness. The CUBN proposed by a
few researchers incorporates the density based and
distancebased clustering. It discovers fringe focuses
utilizing the disintegration task and after that begins
clustering the outskirt and the inward indicates agreeing
the nearest separate. The ST-DBSCAN algorithm has the
possibility to find bunches with non-spatial, spatial and
fleeting estimations of the items. The DBSCAN neglects
to recognize clamor purposes of changed density however
this algorithm relegates density factor to each group and
evacuates the lacunae.
New data mining fields are applying meta-learning
procedures to enhance the execution of new methods, for
example, outfits, mining data stream, mining huge data,
and among others. Regardless of the huge number of
works identified with the algorithm determination issue in
the meta-learning writing, there are as yet stupendous
difficulties to be overcome. The associations between
data mining and meta-learning have been generally
explored for administered undertakings, for example,
arrangement; nonetheless, there is no examination, for
example, about the best meta-ascribes to be extricated
from unsupervised learning issues. The expensive issue
portrayal and algorithm assessment forms, together with
the high-dimensional data sets, request better approaches
to describe and assess issues. At the end of the day, the
clustering issues have past known arrangements, and
these are utilized to measure the proposed arrangements.
This shared conviction among these works makes it
harder to broaden the meta-learning since true clustering
errands for the most part don't have from the earlier
known arrangements.
The works that handle the algorithm determination issue
by utilizing meta-learning frameworks in the clustering
setting have in like manner the utilization of outside
records to assess the algorithms. A few researchers
utilized 32 microarray data sets about disease quality
articulation as issues and 7 clustering algorithms. The
issues were described by 8 meta-qualities, including one
particular to the innovation utilized as a part of the
development of the microarray, and the algorithms were
assessed by an outer record in light of the fact that the
arrangement was at that point known. An accumulation of
35 data sets was portrayed by 13 meta-traits, some of
which were identified with the extent of existing bunches.
By utilizing an outer file, 7 algorithms were assessed by
shifting the similitude measure. With a relapse method
used to choose the algorithm, the work displayed great
outcomes. A few researchers connected meta-learning
procedures to build tenets to consequently choose
clustering algorithms for quality articulation data. The
tests planned to locate the best algorithm for run
extraction.
The group investigation of seismic occasions gives
imperative data about the ID of seismotectonic designs
introduce in a particular geographic district if the
similarity of the bunch properties are considered. This
data extricated from tremendous measure of seismic
occasions is useful for assessing provincial seismic risks,
determining consequential convulsions identified with
primary shakes, ascent of seismic exercises preceding a
vast quake and building observational tremor conjecture
procedure. Since IS exploits both the nearest neighbors
(NNs) and reverse nearest neighbors (RNNs) which will
be clarified in detail in the accompanying segment, it
outflanks different methods to profoundly touchy to
nearby density changes.
paper
Data clustering plans to portion a database into gatherings
of articles in light of the closeness among these items.
Because of its unsupervised nature, the look for a decent
quality arrangement can turn into an unpredictable
procedure. Meta-learning brings the idea of finding out
about realizing; that is, the meta-information got from the
algorithm learning process permits the change of the
algorithm execution. Meta-learning has a noteworthy
crossing point with data mining in characterization issues,
in which it is ordinarily used to prescribe algorithms.
There is right now an extensive variety of clustering
algorithms, and choosing the best one for a given issue
can be a moderate and expensive process. In 1976, Rice
planned the Algorithm Selection Problem (ASP), which
proposes that the algorithm execution can be anticipated
in light of the basic attributes of the issue. The present
paper proposes better approaches to acquire meta-
information for clustering errands. In particular, two
commitments are investigated: (1) another way to deal
with portray clustering issues in view of the
comparability among articles; and (2) new methods to
join inside lists for positioning algorithms in light of their
execution on the issues. Examinations were led to assess
the suggestion quality. The outcomes demonstrate that the
new meta-learning gives great algorithm determination to
clustering assignments.
Density based algorithm OPTICS (requesting focuses to
distinguish the clustering structure) is presented by a few
researchers which figures an enlarged bunch requesting
for programmed and intelligent group examinations.
Consequently another algorithm DENCLUE (Density
based Clustering) proposed by a few researchers, models
the general point density logically as the total of influence
works the data focuses. This density based algorithm
gives a reduced scientific portrayal of discretionarily
formed groups in high dimensional datasets and is
essentially speedier than its partner algorithms. Both
DBSCAN and OPTICS investigate the area of a question,
and both rely upon spatial record structure, for example,
R*-tree or X-tree to effectively process the area inquiries.
Since the proficiency of noting these inquiries with these
records diminishes with increment in the quantity of
measurements, the two methods are wasteful for high-
dimensional data. A cross breed clustering algorithm
BRIDGE incorporates the k-means and DBSCAN. The
BRIDGE empowers the DBSCAN to deal with vast
databases and at the same time increment the execution of
kmeans by disposing of commotion. A few researchers
proposed a versatile density based clustering (ADBC)
algorithm that utilizations versatile procedure (in view of
spatial question dissemination) for neighbor choice to
enhance clustering exactness. The CUBN proposed by a
few researchers incorporates the density based and
distancebased clustering. It discovers fringe focuses
utilizing the disintegration task and after that begins
clustering the outskirt and the inward indicates agreeing
the nearest separate. The ST-DBSCAN algorithm has the
possibility to find bunches with non-spatial, spatial and
fleeting estimations of the items. The DBSCAN neglects
to recognize clamor purposes of changed density however
this algorithm relegates density factor to each group and
evacuates the lacunae.
New data mining fields are applying meta-learning
procedures to enhance the execution of new methods, for
example, outfits, mining data stream, mining huge data,
and among others. Regardless of the huge number of
works identified with the algorithm determination issue in
the meta-learning writing, there are as yet stupendous
difficulties to be overcome. The associations between
data mining and meta-learning have been generally
explored for administered undertakings, for example,
arrangement; nonetheless, there is no examination, for
example, about the best meta-ascribes to be extricated
from unsupervised learning issues. The expensive issue
portrayal and algorithm assessment forms, together with
the high-dimensional data sets, request better approaches
to describe and assess issues. At the end of the day, the
clustering issues have past known arrangements, and
these are utilized to measure the proposed arrangements.
This shared conviction among these works makes it
harder to broaden the meta-learning since true clustering
errands for the most part don't have from the earlier
known arrangements.
The works that handle the algorithm determination issue
by utilizing meta-learning frameworks in the clustering
setting have in like manner the utilization of outside
records to assess the algorithms. A few researchers
utilized 32 microarray data sets about disease quality
articulation as issues and 7 clustering algorithms. The
issues were described by 8 meta-qualities, including one
particular to the innovation utilized as a part of the
development of the microarray, and the algorithms were
assessed by an outer record in light of the fact that the
arrangement was at that point known. An accumulation of
35 data sets was portrayed by 13 meta-traits, some of
which were identified with the extent of existing bunches.
By utilizing an outer file, 7 algorithms were assessed by
shifting the similitude measure. With a relapse method
used to choose the algorithm, the work displayed great
outcomes. A few researchers connected meta-learning
procedures to build tenets to consequently choose
clustering algorithms for quality articulation data. The
tests planned to locate the best algorithm for run
extraction.
The group investigation of seismic occasions gives
imperative data about the ID of seismotectonic designs
introduce in a particular geographic district if the
similarity of the bunch properties are considered. This
data extricated from tremendous measure of seismic
occasions is useful for assessing provincial seismic risks,
determining consequential convulsions identified with
primary shakes, ascent of seismic exercises preceding a
vast quake and building observational tremor conjecture
procedure. Since IS exploits both the nearest neighbors
(NNs) and reverse nearest neighbors (RNNs) which will
be clarified in detail in the accompanying segment, it
outflanks different methods to profoundly touchy to
nearby density changes.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

In the mean time, since this new neighborhood
relationship is symmetric, the researchers' new proposed
strategy can haphazardly choose any protest begin group
development. In the meantime, not at all like the
conventional DBSCAN algorithm, the researchers'
proposed algorithm requires just a single parameter: the
quantity of k-nearest neighbors rather than two
parameters. The issues of trouble to distinguish the
adjoining groups of various densities, affectability to the
info focuses, reliance on two parameters are altogether
understood by the new relationship called the influence
space. Researchers utilize the influence space (IS) to get a
superior estimation of the areas density dispersion to
fathom this lack. The distinguishing proof of outskirt
focuses depend on another idea called center density
reachable. The new idea depends on the normal for fringe
focuses that they don't add to the extension system of
density reachable chains of items. In this paper, this new
idea is advanced in light of the influence. Researchers
utilized 160 misleadingly produced data sets portrayed by
9 meta-characteristics; the tests assessed two algorithms
for positioning forecast: a neural network and a relapse
system.
A few researchers constructed a meta-learning framework
with 30 issues and 10 meta-properties; 5 clustering
algorithms were assessed by utilizing an outer measure.
The positioning was worked with 9 clustering algorithms
by utilizing a blunder rate on the grounds that the protest
marks were known ahead of time. Three estimation
systems were tried to anticipate the execution of the
algorithms, and fthis classifiers were assessed in a
positioning suggestion errand.
As per the paper, the DBSCAN system provides
appropriate solution to the problems previously faced due
to the traditional algorithm implementation for finding
patterns in the clusters of spatial database. It states that
the Clustering algorithms have two basic algorithm types,
which are partitioning algorithm and hierarchical
algorithm (Chakraborty and Nagwani 2014). The working
structures of these two algorithms would be discussed as
below:
Partitioning Algorithm: This clustering algorithm
builds a database with D of ‘n’ objects. It further
traverses it into the set comprising of ‘k’ clusters.
Therefore, ‘k’ forms as a parameter of input type in
these algorithms. Naturally, it requires some
knowledge of the domain, but it is unavailable in most
cases.
Hierarchical algorithm: In this algorithm, it can be
seen that ‘D’ has been disintegrated hierarchically
which is represented by dendograms, that helps in the
disintegration of the ‘D’ iteratively into much smaller
subsets until they consist of a single object. Each node
of the tree created as a result is the representation of a
cluster formed of D.
The paper further describes about the various
researches that have been conducted to provide solution
to the problem of the approach based on density that aids
in identifying the clustering patterns in the k-dimensional
point sets.
The paper proposes that this problem would be solved
by the application of the algorithm called DBSCAN or
Density Based Spatial Clustering of Application with
Noise. This algorithm is proposed to identify noises and
clusters in a spatial database according to the specific
definitions, such as, definition 5 and definition 6 (Hou,
Gao and Li 2016). Although, for the correct
implementation of this algorithm, it is necessary know the
perfect parameters for the MinPts and the Eps for every
cluster. It is also required that at least one of the points
from the corresponding clusters be known. It would then
be possible that all the points can be retrieved that are
reachable form a given point according to their
corresponding densities with the help of appropriate
parameters (Zhao et al. 2015). However, it is quite a
difficult process since there are very low chances that all
the clusters of the databases can be accessible given the
information advancement every passing day.
The algorithm as the DBSCAN suggests follows in the
way of arbitrarily pointing ‘p’ that can retrieve all points
that are reachable by its density with respect to the
MinPts and Eps based on the distance from ‘p’. The
implementation suggests that, if ‘p’ is taken as the core
point, this would further produce a cluster in accordance
with Eps and MinPts. If it is further seen that ‘p’ forms a
border point, then the immediate next two points would
be reachable by density from ‘p’. DBSCAN forms the
base with ‘p’ and manages to visit the next points of the
database (Schubert et al. 2017). The journal describes that
for the effective global implementation, the global values
of Eps and MinPts are taken.
In addition, the paper also suggests a heuristic method
that would be effective in determining the parameters of
MinPts and Eps of the least dense cluster in the spatial
database. Therefore, is quite clear a fact that the paper is
able to suggest the matters of finding patterns of the
arbitrary database by using the noise and clustering
algorithms.
5 Subsequent research and systems that flowed
from this paper
There have been researches about various other
algorithms to find out the pattern in arbitrary clustering of
spatial database. This paper has inspired to research about
the implementation of newer systems and algorithms to
find out the unresolved factors that the paper fails to
discuss (Nasibov et al. 2015). Therefore, it can be said
that this paper has been inspiring many researchers to put
forward new ideas and propose new algorithm that would
be effective in bringing out wholesome results.
Thus, this inspired in the inventions of latest
algorithms of DBCLASD or Distribution Based
Clustering of Large Spatial Databases, STING or
Statistical Information Grid-based Method, BIRCH or
relationship is symmetric, the researchers' new proposed
strategy can haphazardly choose any protest begin group
development. In the meantime, not at all like the
conventional DBSCAN algorithm, the researchers'
proposed algorithm requires just a single parameter: the
quantity of k-nearest neighbors rather than two
parameters. The issues of trouble to distinguish the
adjoining groups of various densities, affectability to the
info focuses, reliance on two parameters are altogether
understood by the new relationship called the influence
space. Researchers utilize the influence space (IS) to get a
superior estimation of the areas density dispersion to
fathom this lack. The distinguishing proof of outskirt
focuses depend on another idea called center density
reachable. The new idea depends on the normal for fringe
focuses that they don't add to the extension system of
density reachable chains of items. In this paper, this new
idea is advanced in light of the influence. Researchers
utilized 160 misleadingly produced data sets portrayed by
9 meta-characteristics; the tests assessed two algorithms
for positioning forecast: a neural network and a relapse
system.
A few researchers constructed a meta-learning framework
with 30 issues and 10 meta-properties; 5 clustering
algorithms were assessed by utilizing an outer measure.
The positioning was worked with 9 clustering algorithms
by utilizing a blunder rate on the grounds that the protest
marks were known ahead of time. Three estimation
systems were tried to anticipate the execution of the
algorithms, and fthis classifiers were assessed in a
positioning suggestion errand.
As per the paper, the DBSCAN system provides
appropriate solution to the problems previously faced due
to the traditional algorithm implementation for finding
patterns in the clusters of spatial database. It states that
the Clustering algorithms have two basic algorithm types,
which are partitioning algorithm and hierarchical
algorithm (Chakraborty and Nagwani 2014). The working
structures of these two algorithms would be discussed as
below:
Partitioning Algorithm: This clustering algorithm
builds a database with D of ‘n’ objects. It further
traverses it into the set comprising of ‘k’ clusters.
Therefore, ‘k’ forms as a parameter of input type in
these algorithms. Naturally, it requires some
knowledge of the domain, but it is unavailable in most
cases.
Hierarchical algorithm: In this algorithm, it can be
seen that ‘D’ has been disintegrated hierarchically
which is represented by dendograms, that helps in the
disintegration of the ‘D’ iteratively into much smaller
subsets until they consist of a single object. Each node
of the tree created as a result is the representation of a
cluster formed of D.
The paper further describes about the various
researches that have been conducted to provide solution
to the problem of the approach based on density that aids
in identifying the clustering patterns in the k-dimensional
point sets.
The paper proposes that this problem would be solved
by the application of the algorithm called DBSCAN or
Density Based Spatial Clustering of Application with
Noise. This algorithm is proposed to identify noises and
clusters in a spatial database according to the specific
definitions, such as, definition 5 and definition 6 (Hou,
Gao and Li 2016). Although, for the correct
implementation of this algorithm, it is necessary know the
perfect parameters for the MinPts and the Eps for every
cluster. It is also required that at least one of the points
from the corresponding clusters be known. It would then
be possible that all the points can be retrieved that are
reachable form a given point according to their
corresponding densities with the help of appropriate
parameters (Zhao et al. 2015). However, it is quite a
difficult process since there are very low chances that all
the clusters of the databases can be accessible given the
information advancement every passing day.
The algorithm as the DBSCAN suggests follows in the
way of arbitrarily pointing ‘p’ that can retrieve all points
that are reachable by its density with respect to the
MinPts and Eps based on the distance from ‘p’. The
implementation suggests that, if ‘p’ is taken as the core
point, this would further produce a cluster in accordance
with Eps and MinPts. If it is further seen that ‘p’ forms a
border point, then the immediate next two points would
be reachable by density from ‘p’. DBSCAN forms the
base with ‘p’ and manages to visit the next points of the
database (Schubert et al. 2017). The journal describes that
for the effective global implementation, the global values
of Eps and MinPts are taken.
In addition, the paper also suggests a heuristic method
that would be effective in determining the parameters of
MinPts and Eps of the least dense cluster in the spatial
database. Therefore, is quite clear a fact that the paper is
able to suggest the matters of finding patterns of the
arbitrary database by using the noise and clustering
algorithms.
5 Subsequent research and systems that flowed
from this paper
There have been researches about various other
algorithms to find out the pattern in arbitrary clustering of
spatial database. This paper has inspired to research about
the implementation of newer systems and algorithms to
find out the unresolved factors that the paper fails to
discuss (Nasibov et al. 2015). Therefore, it can be said
that this paper has been inspiring many researchers to put
forward new ideas and propose new algorithm that would
be effective in bringing out wholesome results.
Thus, this inspired in the inventions of latest
algorithms of DBCLASD or Distribution Based
Clustering of Large Spatial Databases, STING or
Statistical Information Grid-based Method, BIRCH or

Balanced Iterative Reducing and Clustering using
Hierarchies, WaveCluster, DENCLUE or DENsity based
CLUstEring, CLIQUE or r Clustering In QUE, CURE or
Clustering Using Representatives, and many others that
serve various purposes in the evaluation of patterns in
spatial data (Kieu, Bhaskar and Chung 2015). Amongst
these, DENCLUE has been the most effective in finding
solutions in dense clusters of a spatial database.
A cluster is typically a numerous and composed PC or
server appearing to the client or concerned applications as
a solitary server.
There are two basic types of clustering algorithm-
hierarchy and partitioning. Partitioning algorithm
conducts a partition of database. It starts with the initial
partition of the algorithm. For this some of the domain
knowledge is required, which may not be available for the
many applications. The gravity centre of the cluster is
used to identify the each cluster.
A few authors investigated the density which is
identified with the distinguishing proof of the idea of the
K – dimensional point set. The informational index is
apportioned to the part of the no covering cells. The cells
can be thought to be high recurrence which is identified
with the cluster fall in the "valley "of the histogram.
Mulling over the strategy it can be expressed that the
most critical division id the preparing of the information
which predominantly needs a noteworthy concentration
point which is identified with the part of the entrance
point. It can be expressed here that the angle which is
identified with the focal point of the execution it can be
expressed that the approach can be thought to be
especially subject to the extent of the cell. Since the
information is especially tremendous it can be expressed
that the extent of the cell would be gigantic.
The main problem of the hierarchy clustering is that it
is difficult to derive appropriate parameter for the
termination condition. Here set of database small enough
for separation of all natural clusters and equally it is large
enough for so that no cluster can be divided into parts.
6 Unresolved open questions
Though the journal article has been effective in
providing information about the problems that has been
faced during the acquiring of data from the spatial
databases by clustering and noise method, it has some
loopholes in answering all the questions regarding the
spatial database. It is not to be forgotten that the
implementation was not successful in answering all its
questions put forward by the spatial database problems. It
had failed to answer the questions about digging deep
into clusters and finding its density, since the
implemented algorithm is only able to yield the MinPts
and Eps values of the thinnest areas or the least dense
areas of the cluster (Sajana, Rani and Narayana 2016).
However, later in the paper itself it is mentioned about
the fact that algorithms that are immensely popular in
finding out or addressing these problems often fail to
produce effective details when implemented on a large
spatial database. The main reason of reorganization of the
cluster within the each cluster is that there are typical
density points which have considerably high cluster than
others. The noise within the density is lower than the
density of any other clusters.
The paper has provided the solutions of the clustering
problems faced in the clustering dataset and the
elimination of the noise method. However, this paper has
some of the drawbacks and does not provide all the
answers regarding all the questions. The main object of
focus is spatial database. The implementation of the
DBSCAN has failed to provide the solutions to all the
probems related to the spatial database. The problem
regarding the cluster digging and determination of the
density of the cluster is not solved with this algorithm.
This algorithm only solves the problem of determination
of the thinnest areas and least dense areas of the clusters.
However, the justification of this drawback has been
given to the end of the paper, where it has been stated that
many algorithms has answered the solutions for
determination of the density of the cluster, however, each
of them has failed to provide an effective solution
desirable for clustering algorithm. The reorganization of
the cluster among each cluster is that there is high density
cluster points than others. The nose within the density is
lower than the other points of the density.
The article helps to get understanding of how the
clusters and noises are discovered and the major role
played by clustering algorithms. The CLARANS and
DBSCAN are two algorithms discussed in the paper that
provides clustering algorithm for identification of classes
in spatial database. However, both the algorithms face
some challenges where DBSCAN is more effective than
CLARANS in providing identification of clusters and
their discovery. The paper justifies the DBSCAN
efficiency and effectiveness through performance
evaluation but it has loopholes in providing justification
for large sized spatial database. The paper finally presents
open questions that are unanswered by the author. The
paper does not provide brief solution for existing
problems related to spatial database. The clusters are not
deeply analyzed and evaluation of density are not
effectively presented to get the deep understanding of
clusters in large sized spatial databases. The only area
which the author appropriately described is the analysis
of values of MinPts and Eps of the areas which are least
dense in the cluster. The major question unanswered by
the author is that the implementation of clustering
algorithms failure to determine in large sized spatial
database. This is the major unresolved question which is
left unanswered.
The author has presented some valid points that are the
plus point in the paper and shows proper justification for
those points. The author briefly describes clusters and
noise in spatial database through different tables, pictures
and algorithm structures. The author has done and
Hierarchies, WaveCluster, DENCLUE or DENsity based
CLUstEring, CLIQUE or r Clustering In QUE, CURE or
Clustering Using Representatives, and many others that
serve various purposes in the evaluation of patterns in
spatial data (Kieu, Bhaskar and Chung 2015). Amongst
these, DENCLUE has been the most effective in finding
solutions in dense clusters of a spatial database.
A cluster is typically a numerous and composed PC or
server appearing to the client or concerned applications as
a solitary server.
There are two basic types of clustering algorithm-
hierarchy and partitioning. Partitioning algorithm
conducts a partition of database. It starts with the initial
partition of the algorithm. For this some of the domain
knowledge is required, which may not be available for the
many applications. The gravity centre of the cluster is
used to identify the each cluster.
A few authors investigated the density which is
identified with the distinguishing proof of the idea of the
K – dimensional point set. The informational index is
apportioned to the part of the no covering cells. The cells
can be thought to be high recurrence which is identified
with the cluster fall in the "valley "of the histogram.
Mulling over the strategy it can be expressed that the
most critical division id the preparing of the information
which predominantly needs a noteworthy concentration
point which is identified with the part of the entrance
point. It can be expressed here that the angle which is
identified with the focal point of the execution it can be
expressed that the approach can be thought to be
especially subject to the extent of the cell. Since the
information is especially tremendous it can be expressed
that the extent of the cell would be gigantic.
The main problem of the hierarchy clustering is that it
is difficult to derive appropriate parameter for the
termination condition. Here set of database small enough
for separation of all natural clusters and equally it is large
enough for so that no cluster can be divided into parts.
6 Unresolved open questions
Though the journal article has been effective in
providing information about the problems that has been
faced during the acquiring of data from the spatial
databases by clustering and noise method, it has some
loopholes in answering all the questions regarding the
spatial database. It is not to be forgotten that the
implementation was not successful in answering all its
questions put forward by the spatial database problems. It
had failed to answer the questions about digging deep
into clusters and finding its density, since the
implemented algorithm is only able to yield the MinPts
and Eps values of the thinnest areas or the least dense
areas of the cluster (Sajana, Rani and Narayana 2016).
However, later in the paper itself it is mentioned about
the fact that algorithms that are immensely popular in
finding out or addressing these problems often fail to
produce effective details when implemented on a large
spatial database. The main reason of reorganization of the
cluster within the each cluster is that there are typical
density points which have considerably high cluster than
others. The noise within the density is lower than the
density of any other clusters.
The paper has provided the solutions of the clustering
problems faced in the clustering dataset and the
elimination of the noise method. However, this paper has
some of the drawbacks and does not provide all the
answers regarding all the questions. The main object of
focus is spatial database. The implementation of the
DBSCAN has failed to provide the solutions to all the
probems related to the spatial database. The problem
regarding the cluster digging and determination of the
density of the cluster is not solved with this algorithm.
This algorithm only solves the problem of determination
of the thinnest areas and least dense areas of the clusters.
However, the justification of this drawback has been
given to the end of the paper, where it has been stated that
many algorithms has answered the solutions for
determination of the density of the cluster, however, each
of them has failed to provide an effective solution
desirable for clustering algorithm. The reorganization of
the cluster among each cluster is that there is high density
cluster points than others. The nose within the density is
lower than the other points of the density.
The article helps to get understanding of how the
clusters and noises are discovered and the major role
played by clustering algorithms. The CLARANS and
DBSCAN are two algorithms discussed in the paper that
provides clustering algorithm for identification of classes
in spatial database. However, both the algorithms face
some challenges where DBSCAN is more effective than
CLARANS in providing identification of clusters and
their discovery. The paper justifies the DBSCAN
efficiency and effectiveness through performance
evaluation but it has loopholes in providing justification
for large sized spatial database. The paper finally presents
open questions that are unanswered by the author. The
paper does not provide brief solution for existing
problems related to spatial database. The clusters are not
deeply analyzed and evaluation of density are not
effectively presented to get the deep understanding of
clusters in large sized spatial databases. The only area
which the author appropriately described is the analysis
of values of MinPts and Eps of the areas which are least
dense in the cluster. The major question unanswered by
the author is that the implementation of clustering
algorithms failure to determine in large sized spatial
database. This is the major unresolved question which is
left unanswered.
The author has presented some valid points that are the
plus point in the paper and shows proper justification for
those points. The author briefly describes clusters and
noise in spatial database through different tables, pictures
and algorithm structures. The author has done and
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

appreciable job in briefly describing the clusters and
noises in a structural form.
7 Other interesting points of the paper
There have been several other topics that have been
found to be interesting in this regard. These are the
explanations of the algorithms of the cluster and noise
described in table formats, pictorial forms and other
detailed algorithm structures depicted in a detailed
manner (Ding et al. 2015). The journal article
successfully clarifies each of these explanations with the
detailed structural representations.
The evaluation of the performance of the DBSCAN is
determined by the comparison of this algorithm another
clustering algorithm. The other clustering algorithm is
CLARANS. It is the first clustering algorithm designed
for the purpose KDD. The comparison is done with the
classic density based clustering algorithm. DBSCAN is
implemented in C++, which is based on the
implementation of R* tree. The experiments have been
run on the HP 735/100 workstation. Database used in this
experiment is based on the SEQUOIA 2000 benchmark.
In order to determine the efficiency three synthetic
sample of database is used. DBSCAN and CLARANS are
different types of algorithm. The measurement of the
classification accuracy is different for both the algorithm.
The accuracy of both the algorithm is determined by the
visual perception. From the experiment it can be seen that
CLARANS has certain advantages.
DBSCAN can discover all the clusters and can detect
the noise points from all the sample database. There is no
different notion in case of CLARANS.
Figure 2: Density Based Clustering
(Source: Hou, Ga and Li 2016)
The database used in this experiments is based on
SEQUIOA 2000 benchmark. This kind of datasets are
related to the Earth Science task. In the database, there
are four types of dataset-point data, raster data, directed
graph data and polygon data. It contains names of
landmarks geographic information. The size of point data
set is 2.1M bytes. In CLARANS the run time of the data
set is very fast. In case of DBSCAN the data sub set is
used, which contains 2% to 20% of data from the original
dataset.
Again, there are some specific points that are only
introduced in this paper but further explanations can be
found from other contemporary of later papers. In spite of
this, the authors of this paper have done a significant job
in developing and publishing the concepts that were
previously discussed and later further researched on.
Some of these concepts are also discussed in this
particular report. The authors Schubert et al. (2017)
discussed that in the KDD process, data mining is an
useful tool that uses data analysis applications and
discovery algorithms that, in spite of their computational
limitations, can produce enumerations of data patterns.
Hou, Ga and Li (2016) also made some significant
progress in the study of density-based clustering
algorithm, namely DBSCAN that is also a focal point of
this particular paper. As per the authors, DBSCAN
requires two input parameters that are designated as Eps
and MinPts and both of their values are greater than 0.
However, it is completely up to the user to determine and
use required values for these two parameters. Another use
of DBSCAN is that it can be used to discover arbitrary
shape clusters as well as distinguish noise. One other use
of DBSCAN is that it is very efficient for large spatial
databases if spatial access methods are utilized.
noises in a structural form.
7 Other interesting points of the paper
There have been several other topics that have been
found to be interesting in this regard. These are the
explanations of the algorithms of the cluster and noise
described in table formats, pictorial forms and other
detailed algorithm structures depicted in a detailed
manner (Ding et al. 2015). The journal article
successfully clarifies each of these explanations with the
detailed structural representations.
The evaluation of the performance of the DBSCAN is
determined by the comparison of this algorithm another
clustering algorithm. The other clustering algorithm is
CLARANS. It is the first clustering algorithm designed
for the purpose KDD. The comparison is done with the
classic density based clustering algorithm. DBSCAN is
implemented in C++, which is based on the
implementation of R* tree. The experiments have been
run on the HP 735/100 workstation. Database used in this
experiment is based on the SEQUOIA 2000 benchmark.
In order to determine the efficiency three synthetic
sample of database is used. DBSCAN and CLARANS are
different types of algorithm. The measurement of the
classification accuracy is different for both the algorithm.
The accuracy of both the algorithm is determined by the
visual perception. From the experiment it can be seen that
CLARANS has certain advantages.
DBSCAN can discover all the clusters and can detect
the noise points from all the sample database. There is no
different notion in case of CLARANS.
Figure 2: Density Based Clustering
(Source: Hou, Ga and Li 2016)
The database used in this experiments is based on
SEQUIOA 2000 benchmark. This kind of datasets are
related to the Earth Science task. In the database, there
are four types of dataset-point data, raster data, directed
graph data and polygon data. It contains names of
landmarks geographic information. The size of point data
set is 2.1M bytes. In CLARANS the run time of the data
set is very fast. In case of DBSCAN the data sub set is
used, which contains 2% to 20% of data from the original
dataset.
Again, there are some specific points that are only
introduced in this paper but further explanations can be
found from other contemporary of later papers. In spite of
this, the authors of this paper have done a significant job
in developing and publishing the concepts that were
previously discussed and later further researched on.
Some of these concepts are also discussed in this
particular report. The authors Schubert et al. (2017)
discussed that in the KDD process, data mining is an
useful tool that uses data analysis applications and
discovery algorithms that, in spite of their computational
limitations, can produce enumerations of data patterns.
Hou, Ga and Li (2016) also made some significant
progress in the study of density-based clustering
algorithm, namely DBSCAN that is also a focal point of
this particular paper. As per the authors, DBSCAN
requires two input parameters that are designated as Eps
and MinPts and both of their values are greater than 0.
However, it is completely up to the user to determine and
use required values for these two parameters. Another use
of DBSCAN is that it can be used to discover arbitrary
shape clusters as well as distinguish noise. One other use
of DBSCAN is that it is very efficient for large spatial
databases if spatial access methods are utilized.
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser
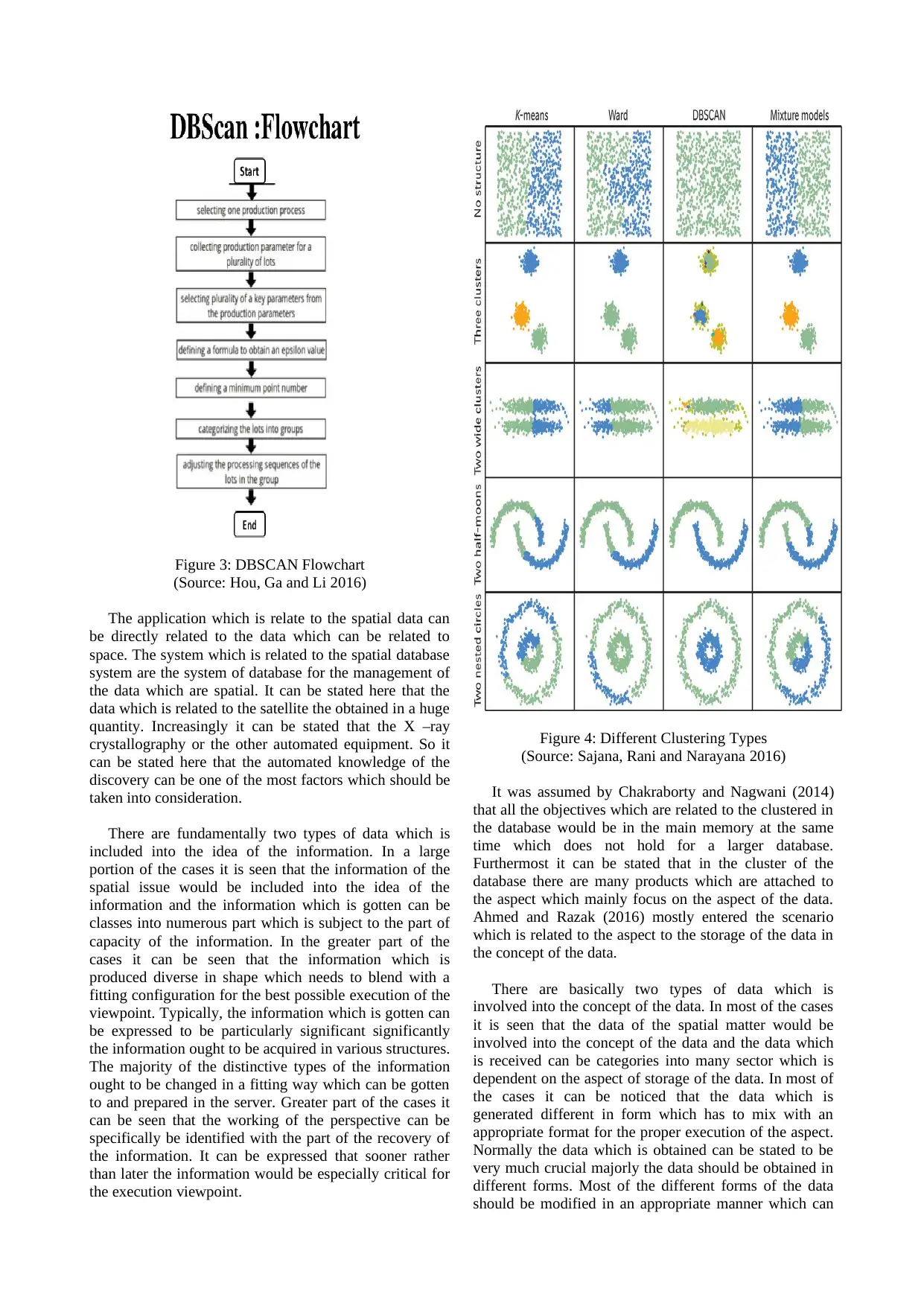
Figure 3: DBSCAN Flowchart
(Source: Hou, Ga and Li 2016)
The application which is relate to the spatial data can
be directly related to the data which can be related to
space. The system which is related to the spatial database
system are the system of database for the management of
the data which are spatial. It can be stated here that the
data which is related to the satellite the obtained in a huge
quantity. Increasingly it can be stated that the X –ray
crystallography or the other automated equipment. So it
can be stated here that the automated knowledge of the
discovery can be one of the most factors which should be
taken into consideration.
There are fundamentally two types of data which is
included into the idea of the information. In a large
portion of the cases it is seen that the information of the
spatial issue would be included into the idea of the
information and the information which is gotten can be
classes into numerous part which is subject to the part of
capacity of the information. In the greater part of the
cases it can be seen that the information which is
produced diverse in shape which needs to blend with a
fitting configuration for the best possible execution of the
viewpoint. Typically, the information which is gotten can
be expressed to be particularly significant significantly
the information ought to be acquired in various structures.
The majority of the distinctive types of the information
ought to be changed in a fitting way which can be gotten
to and prepared in the server. Greater part of the cases it
can be seen that the working of the perspective can be
specifically be identified with the part of the recovery of
the information. It can be expressed that sooner rather
than later the information would be especially critical for
the execution viewpoint.
Figure 4: Different Clustering Types
(Source: Sajana, Rani and Narayana 2016)
It was assumed by Chakraborty and Nagwani (2014)
that all the objectives which are related to the clustered in
the database would be in the main memory at the same
time which does not hold for a larger database.
Furthermost it can be stated that in the cluster of the
database there are many products which are attached to
the aspect which mainly focus on the aspect of the data.
Ahmed and Razak (2016) mostly entered the scenario
which is related to the aspect to the storage of the data in
the concept of the data.
There are basically two types of data which is
involved into the concept of the data. In most of the cases
it is seen that the data of the spatial matter would be
involved into the concept of the data and the data which
is received can be categories into many sector which is
dependent on the aspect of storage of the data. In most of
the cases it can be noticed that the data which is
generated different in form which has to mix with an
appropriate format for the proper execution of the aspect.
Normally the data which is obtained can be stated to be
very much crucial majorly the data should be obtained in
different forms. Most of the different forms of the data
should be modified in an appropriate manner which can
(Source: Hou, Ga and Li 2016)
The application which is relate to the spatial data can
be directly related to the data which can be related to
space. The system which is related to the spatial database
system are the system of database for the management of
the data which are spatial. It can be stated here that the
data which is related to the satellite the obtained in a huge
quantity. Increasingly it can be stated that the X –ray
crystallography or the other automated equipment. So it
can be stated here that the automated knowledge of the
discovery can be one of the most factors which should be
taken into consideration.
There are fundamentally two types of data which is
included into the idea of the information. In a large
portion of the cases it is seen that the information of the
spatial issue would be included into the idea of the
information and the information which is gotten can be
classes into numerous part which is subject to the part of
capacity of the information. In the greater part of the
cases it can be seen that the information which is
produced diverse in shape which needs to blend with a
fitting configuration for the best possible execution of the
viewpoint. Typically, the information which is gotten can
be expressed to be particularly significant significantly
the information ought to be acquired in various structures.
The majority of the distinctive types of the information
ought to be changed in a fitting way which can be gotten
to and prepared in the server. Greater part of the cases it
can be seen that the working of the perspective can be
specifically be identified with the part of the recovery of
the information. It can be expressed that sooner rather
than later the information would be especially critical for
the execution viewpoint.
Figure 4: Different Clustering Types
(Source: Sajana, Rani and Narayana 2016)
It was assumed by Chakraborty and Nagwani (2014)
that all the objectives which are related to the clustered in
the database would be in the main memory at the same
time which does not hold for a larger database.
Furthermost it can be stated that in the cluster of the
database there are many products which are attached to
the aspect which mainly focus on the aspect of the data.
Ahmed and Razak (2016) mostly entered the scenario
which is related to the aspect to the storage of the data in
the concept of the data.
There are basically two types of data which is
involved into the concept of the data. In most of the cases
it is seen that the data of the spatial matter would be
involved into the concept of the data and the data which
is received can be categories into many sector which is
dependent on the aspect of storage of the data. In most of
the cases it can be noticed that the data which is
generated different in form which has to mix with an
appropriate format for the proper execution of the aspect.
Normally the data which is obtained can be stated to be
very much crucial majorly the data should be obtained in
different forms. Most of the different forms of the data
should be modified in an appropriate manner which can
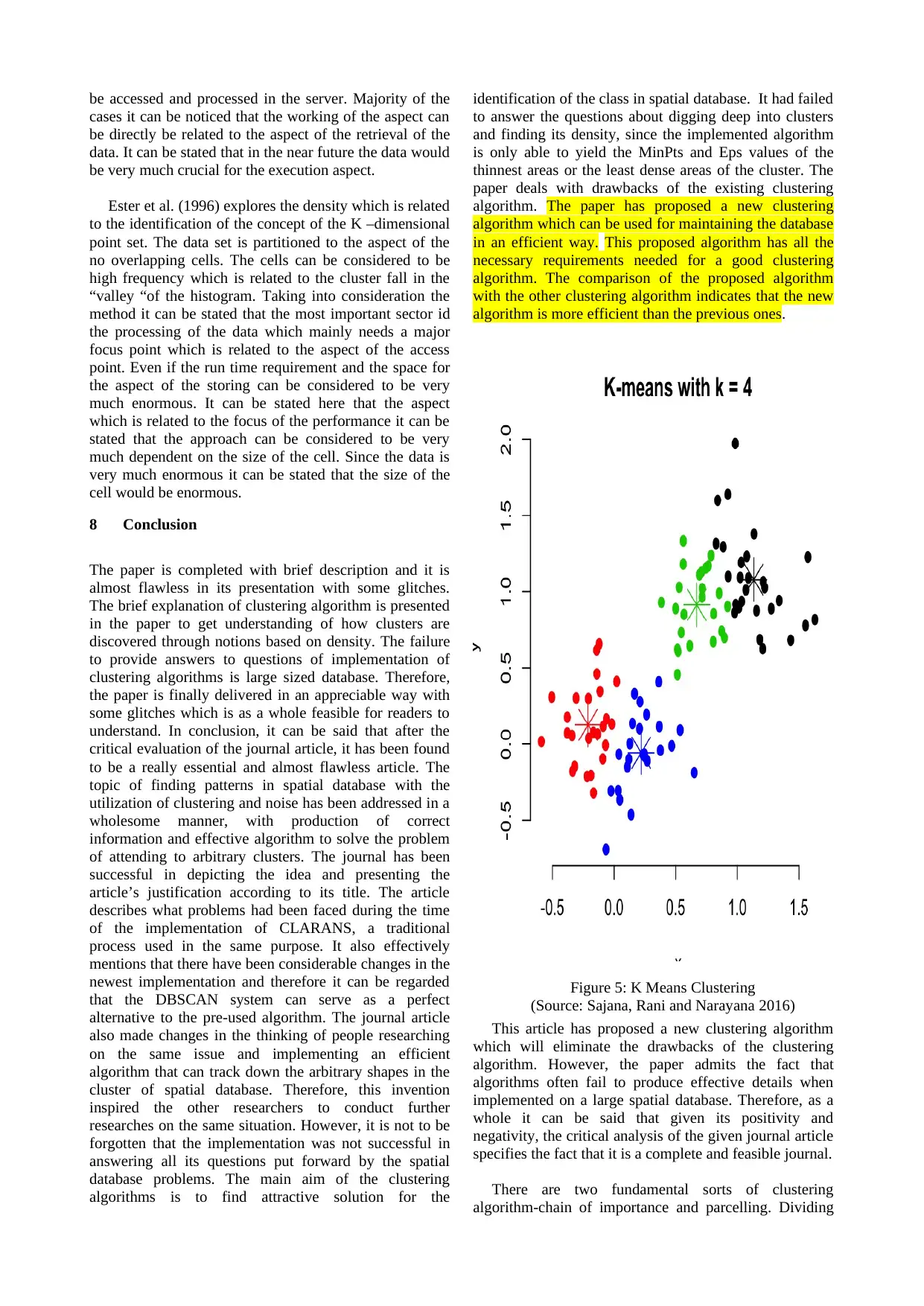
be accessed and processed in the server. Majority of the
cases it can be noticed that the working of the aspect can
be directly be related to the aspect of the retrieval of the
data. It can be stated that in the near future the data would
be very much crucial for the execution aspect.
Ester et al. (1996) explores the density which is related
to the identification of the concept of the K –dimensional
point set. The data set is partitioned to the aspect of the
no overlapping cells. The cells can be considered to be
high frequency which is related to the cluster fall in the
“valley “of the histogram. Taking into consideration the
method it can be stated that the most important sector id
the processing of the data which mainly needs a major
focus point which is related to the aspect of the access
point. Even if the run time requirement and the space for
the aspect of the storing can be considered to be very
much enormous. It can be stated here that the aspect
which is related to the focus of the performance it can be
stated that the approach can be considered to be very
much dependent on the size of the cell. Since the data is
very much enormous it can be stated that the size of the
cell would be enormous.
8 Conclusion
The paper is completed with brief description and it is
almost flawless in its presentation with some glitches.
The brief explanation of clustering algorithm is presented
in the paper to get understanding of how clusters are
discovered through notions based on density. The failure
to provide answers to questions of implementation of
clustering algorithms is large sized database. Therefore,
the paper is finally delivered in an appreciable way with
some glitches which is as a whole feasible for readers to
understand. In conclusion, it can be said that after the
critical evaluation of the journal article, it has been found
to be a really essential and almost flawless article. The
topic of finding patterns in spatial database with the
utilization of clustering and noise has been addressed in a
wholesome manner, with production of correct
information and effective algorithm to solve the problem
of attending to arbitrary clusters. The journal has been
successful in depicting the idea and presenting the
article’s justification according to its title. The article
describes what problems had been faced during the time
of the implementation of CLARANS, a traditional
process used in the same purpose. It also effectively
mentions that there have been considerable changes in the
newest implementation and therefore it can be regarded
that the DBSCAN system can serve as a perfect
alternative to the pre-used algorithm. The journal article
also made changes in the thinking of people researching
on the same issue and implementing an efficient
algorithm that can track down the arbitrary shapes in the
cluster of spatial database. Therefore, this invention
inspired the other researchers to conduct further
researches on the same situation. However, it is not to be
forgotten that the implementation was not successful in
answering all its questions put forward by the spatial
database problems. The main aim of the clustering
algorithms is to find attractive solution for the
identification of the class in spatial database. It had failed
to answer the questions about digging deep into clusters
and finding its density, since the implemented algorithm
is only able to yield the MinPts and Eps values of the
thinnest areas or the least dense areas of the cluster. The
paper deals with drawbacks of the existing clustering
algorithm. The paper has proposed a new clustering
algorithm which can be used for maintaining the database
in an efficient way. This proposed algorithm has all the
necessary requirements needed for a good clustering
algorithm. The comparison of the proposed algorithm
with the other clustering algorithm indicates that the new
algorithm is more efficient than the previous ones.
Figure 5: K Means Clustering
(Source: Sajana, Rani and Narayana 2016)
This article has proposed a new clustering algorithm
which will eliminate the drawbacks of the clustering
algorithm. However, the paper admits the fact that
algorithms often fail to produce effective details when
implemented on a large spatial database. Therefore, as a
whole it can be said that given its positivity and
negativity, the critical analysis of the given journal article
specifies the fact that it is a complete and feasible journal.
There are two fundamental sorts of clustering
algorithm-chain of importance and parcelling. Dividing
cases it can be noticed that the working of the aspect can
be directly be related to the aspect of the retrieval of the
data. It can be stated that in the near future the data would
be very much crucial for the execution aspect.
Ester et al. (1996) explores the density which is related
to the identification of the concept of the K –dimensional
point set. The data set is partitioned to the aspect of the
no overlapping cells. The cells can be considered to be
high frequency which is related to the cluster fall in the
“valley “of the histogram. Taking into consideration the
method it can be stated that the most important sector id
the processing of the data which mainly needs a major
focus point which is related to the aspect of the access
point. Even if the run time requirement and the space for
the aspect of the storing can be considered to be very
much enormous. It can be stated here that the aspect
which is related to the focus of the performance it can be
stated that the approach can be considered to be very
much dependent on the size of the cell. Since the data is
very much enormous it can be stated that the size of the
cell would be enormous.
8 Conclusion
The paper is completed with brief description and it is
almost flawless in its presentation with some glitches.
The brief explanation of clustering algorithm is presented
in the paper to get understanding of how clusters are
discovered through notions based on density. The failure
to provide answers to questions of implementation of
clustering algorithms is large sized database. Therefore,
the paper is finally delivered in an appreciable way with
some glitches which is as a whole feasible for readers to
understand. In conclusion, it can be said that after the
critical evaluation of the journal article, it has been found
to be a really essential and almost flawless article. The
topic of finding patterns in spatial database with the
utilization of clustering and noise has been addressed in a
wholesome manner, with production of correct
information and effective algorithm to solve the problem
of attending to arbitrary clusters. The journal has been
successful in depicting the idea and presenting the
article’s justification according to its title. The article
describes what problems had been faced during the time
of the implementation of CLARANS, a traditional
process used in the same purpose. It also effectively
mentions that there have been considerable changes in the
newest implementation and therefore it can be regarded
that the DBSCAN system can serve as a perfect
alternative to the pre-used algorithm. The journal article
also made changes in the thinking of people researching
on the same issue and implementing an efficient
algorithm that can track down the arbitrary shapes in the
cluster of spatial database. Therefore, this invention
inspired the other researchers to conduct further
researches on the same situation. However, it is not to be
forgotten that the implementation was not successful in
answering all its questions put forward by the spatial
database problems. The main aim of the clustering
algorithms is to find attractive solution for the
identification of the class in spatial database. It had failed
to answer the questions about digging deep into clusters
and finding its density, since the implemented algorithm
is only able to yield the MinPts and Eps values of the
thinnest areas or the least dense areas of the cluster. The
paper deals with drawbacks of the existing clustering
algorithm. The paper has proposed a new clustering
algorithm which can be used for maintaining the database
in an efficient way. This proposed algorithm has all the
necessary requirements needed for a good clustering
algorithm. The comparison of the proposed algorithm
with the other clustering algorithm indicates that the new
algorithm is more efficient than the previous ones.
Figure 5: K Means Clustering
(Source: Sajana, Rani and Narayana 2016)
This article has proposed a new clustering algorithm
which will eliminate the drawbacks of the clustering
algorithm. However, the paper admits the fact that
algorithms often fail to produce effective details when
implemented on a large spatial database. Therefore, as a
whole it can be said that given its positivity and
negativity, the critical analysis of the given journal article
specifies the fact that it is a complete and feasible journal.
There are two fundamental sorts of clustering
algorithm-chain of importance and parcelling. Dividing
⊘ This is a preview!⊘
Do you want full access?
Subscribe today to unlock all pages.
Trusted by 1+ million students worldwide

algorithm leads a parcel of database. It begins with the
underlying allotment of the algorithm. For this a portion
of the space learning is required, which may not be
accessible for the numerous applications. The gravity
focus of the cluster is utilized to distinguish the each
cluster. Apportioning algorithm applies a twostage
approach. It initially decides the k delegates for
minimization of the goal work. The second step is
allocating each cluster question its delegates. The second
step ought to be guaranteed that each parcelling ought to
be proportional to a voronoi outline and there ought to be
a voronoi cell for every one of the segment. Hierarchical
algorithms make the hierarchical deterioration of the
given database. The portrayal of hierarchical database is
spoken to by dendrogram. Dendrogram is a tree that parts
the database in iterative way. The tree parts the database
into littler subsets. In every progressive system, every
node speaks to the subset of the tree. The dendrogram can
be made from the surrenders over to the root. It is called
agglomerative approach. If there should be an occurrence
of disruptive approach, the roots are down to the leaves
by combining or partitioning the cluster in every
progression. K as info does not required in the
hierarchical approach. The end of the condition depends
when the combining or the division procedure is ended.
Agglomerative approach is one of the case of the end
condition.
Figure 6: Text Document Clustering Using K Means
(Source: Sajana, Rani and Narayana 2016)
The proposed cluster algorithm is useful to offer an
answer that incorporates all these attractive characteristics
of the clustering algorithm. The clustering algorithms are
examined and their working principals are assessed. The
meaning of the cluster has been introduced in the idea of
the density of the database. The adequacy of the
DBSCAN is assessed significant examination with the
real clustering algorithm. The examinations are done on
the SEQUOIA 2000 benchmark. Based on the trials the
summery of the exploration is made and the conceivable
future heading of this investigation has been produced.
The primary issue of the chain of command clustering is
that it is hard to infer suitable parameter for the end
condition. Here arrangement of database is sufficiently
little for detachment of every regular cluster and similarly
it is sufficiently vast for with the goal that no cluster can
be partitioned into parts. From the analysis, it is realized
that Spatial Database Systems (SDBS) are utilized for
administration of databases that contain spatial
information i.e. spatially broadened protests in 2D or 3D
or some other high dimensional element space. This sort
of database is for the most part used to store satellite
pictures and information, crystallography and others. An
essential prerequisite for this kind of database framework
is information revelation since the measure of the
information going into the database increments
ceaselessly.
9 References
Aghabozorgi, S., Shirkhorshidi, A.S. and Wah, T.Y.,
2015. Time-series clustering–A decade
review. Information Systems, 53, pp.16-38.
Ahmed, K.N. and Razak, T.A., 2016. An Overview of
Various Improvements of DBSCAN Algorithm in
Clustering Spatial Databases. International Journal of
Advanced Research in Computer and Communication
Engineering, 5(2).
Chakraborty, S. and Nagwani, N.K., 2014. Analysis and
study of Incremental DBSCAN clustering
algorithm. arXiv preprint arXiv:1406.4754.
Deng, Z., Hu, Y., Zhu, M., Huang, X. and Du, B., 2015.
A scalable and fast OPTICS for clustering trajectory
big data. Cluster Computing, 18(2), pp.549-562.
Ding, R., Wang, Q., Dang, Y., Fu, Q., Zhang, H. and
Zhang, D., 2015. Yading: fast clustering of large-scale
time series data. Proceedings of the VLDB
Endowment, 8(5), pp.473-484.
Ester, M., Kriegel, H.P., Sander, J. and Xu, X., 1996,
August. A density-based algorithm for discovering
clusters in large spatial databases with noise. In Kdd
(Vol. 96, No. 34, pp. 226-231).
Ferrari, D.G. and De Castro, L.N., 2015. Clustering
algorithm selection by meta-learning systems: A new
distance-based problem characterization and ranking
combination methods. Information Sciences, 301,
pp.181-194.
Friedman, A., Keselman, M.D., Gibb, L.G. and Graybiel,
A.M., 2015. A multistage mathematical approach to
automated clustering of high-dimensional noisy
data. Proceedings of the National Academy of
Sciences, 112(14), pp.4477-4482.
Hou, J., Gao, H. and Li, X., 2016. DSets-DBSCAN: A
parameter-free clustering algorithm. IEEE
Transactions on Image Processing, 25(7), pp.3182-
3193.
Khan, K., Rehman, S.U., Aziz, K., Fong, S. and
Sarasvady, S., 2014, February. DBSCAN: Past, present
underlying allotment of the algorithm. For this a portion
of the space learning is required, which may not be
accessible for the numerous applications. The gravity
focus of the cluster is utilized to distinguish the each
cluster. Apportioning algorithm applies a twostage
approach. It initially decides the k delegates for
minimization of the goal work. The second step is
allocating each cluster question its delegates. The second
step ought to be guaranteed that each parcelling ought to
be proportional to a voronoi outline and there ought to be
a voronoi cell for every one of the segment. Hierarchical
algorithms make the hierarchical deterioration of the
given database. The portrayal of hierarchical database is
spoken to by dendrogram. Dendrogram is a tree that parts
the database in iterative way. The tree parts the database
into littler subsets. In every progressive system, every
node speaks to the subset of the tree. The dendrogram can
be made from the surrenders over to the root. It is called
agglomerative approach. If there should be an occurrence
of disruptive approach, the roots are down to the leaves
by combining or partitioning the cluster in every
progression. K as info does not required in the
hierarchical approach. The end of the condition depends
when the combining or the division procedure is ended.
Agglomerative approach is one of the case of the end
condition.
Figure 6: Text Document Clustering Using K Means
(Source: Sajana, Rani and Narayana 2016)
The proposed cluster algorithm is useful to offer an
answer that incorporates all these attractive characteristics
of the clustering algorithm. The clustering algorithms are
examined and their working principals are assessed. The
meaning of the cluster has been introduced in the idea of
the density of the database. The adequacy of the
DBSCAN is assessed significant examination with the
real clustering algorithm. The examinations are done on
the SEQUOIA 2000 benchmark. Based on the trials the
summery of the exploration is made and the conceivable
future heading of this investigation has been produced.
The primary issue of the chain of command clustering is
that it is hard to infer suitable parameter for the end
condition. Here arrangement of database is sufficiently
little for detachment of every regular cluster and similarly
it is sufficiently vast for with the goal that no cluster can
be partitioned into parts. From the analysis, it is realized
that Spatial Database Systems (SDBS) are utilized for
administration of databases that contain spatial
information i.e. spatially broadened protests in 2D or 3D
or some other high dimensional element space. This sort
of database is for the most part used to store satellite
pictures and information, crystallography and others. An
essential prerequisite for this kind of database framework
is information revelation since the measure of the
information going into the database increments
ceaselessly.
9 References
Aghabozorgi, S., Shirkhorshidi, A.S. and Wah, T.Y.,
2015. Time-series clustering–A decade
review. Information Systems, 53, pp.16-38.
Ahmed, K.N. and Razak, T.A., 2016. An Overview of
Various Improvements of DBSCAN Algorithm in
Clustering Spatial Databases. International Journal of
Advanced Research in Computer and Communication
Engineering, 5(2).
Chakraborty, S. and Nagwani, N.K., 2014. Analysis and
study of Incremental DBSCAN clustering
algorithm. arXiv preprint arXiv:1406.4754.
Deng, Z., Hu, Y., Zhu, M., Huang, X. and Du, B., 2015.
A scalable and fast OPTICS for clustering trajectory
big data. Cluster Computing, 18(2), pp.549-562.
Ding, R., Wang, Q., Dang, Y., Fu, Q., Zhang, H. and
Zhang, D., 2015. Yading: fast clustering of large-scale
time series data. Proceedings of the VLDB
Endowment, 8(5), pp.473-484.
Ester, M., Kriegel, H.P., Sander, J. and Xu, X., 1996,
August. A density-based algorithm for discovering
clusters in large spatial databases with noise. In Kdd
(Vol. 96, No. 34, pp. 226-231).
Ferrari, D.G. and De Castro, L.N., 2015. Clustering
algorithm selection by meta-learning systems: A new
distance-based problem characterization and ranking
combination methods. Information Sciences, 301,
pp.181-194.
Friedman, A., Keselman, M.D., Gibb, L.G. and Graybiel,
A.M., 2015. A multistage mathematical approach to
automated clustering of high-dimensional noisy
data. Proceedings of the National Academy of
Sciences, 112(14), pp.4477-4482.
Hou, J., Gao, H. and Li, X., 2016. DSets-DBSCAN: A
parameter-free clustering algorithm. IEEE
Transactions on Image Processing, 25(7), pp.3182-
3193.
Khan, K., Rehman, S.U., Aziz, K., Fong, S. and
Sarasvady, S., 2014, February. DBSCAN: Past, present
Paraphrase This Document
Need a fresh take? Get an instant paraphrase of this document with our AI Paraphraser

and future. In Applications of Digital Information and
Web Technologies (ICADIWT), 2014 Fifth
International Conference on the (pp. 232-238). IEEE.
Kieu, L.M., Bhaskar, A. and Chung, E., 2015. A modified
Density-Based Scanning Algorithm with Noise for
spatial travel pattern analysis from Smart Card AFC
data. Transportation Research Part C: Emerging
Technologies, 58, pp.193-207.
Kumar, K.M. and Reddy, A.R.M., 2016. A fast DBSCAN
clustering algorithm by accelerating neighbor searching
using Groups method. Pattern Recognition, 58, pp.39-
48.
Nasibov, E., Atilgan, C., Berberler, M.E. and Nasiboglu,
R., 2015. Fuzzy joint points based clustering
algorithms for large data sets. Fuzzy Sets and
Systems, 270, pp.111-126.
Ozkok, F.O. and Celik, M., 2017. A New Approach to
Determine Eps Parameter of DBSCAN
Algorithm. International Journal of Intelligent Systems
and Applications in Engineering, 5(4), pp.247-251.
Sajana, T., Rani, C.S. and Narayana, K.V., 2016. A
survey on clustering techniques for big data
mining. Indian Journal of Science and
Technology, 9(3).
Schubert, E., Sander, J., Ester, M., Kriegel, H.P. and Xu,
X., 2017. DBSCAN Revisited, Revisited: Why and
How You Should (Still) Use DBSCAN. ACM
Transactions on Database Systems (TODS), 42(3),
p.19.
Shirkhorshidi, A.S., Aghabozorgi, S., Wah, T.Y. and
Herawan, T., 2014, June. Big data clustering: a review.
In International Conference on Computational Science
and Its Applications (pp. 707-720). Springer, Cham.
Yuan, G., Sun, P., Zhao, J., Li, D. and Wang, C., 2017. A
review of moving object trajectory clustering
algorithms. Artificial Intelligence Review, 47(1),
pp.123-144.
Zhao, Q., Shi, Y., Liu, Q. and Fränti, P., 2015. A grid-
growing clustering algorithm for geo-spatial
data. Pattern Recognition Letters, 53, pp.77-84.
Web Technologies (ICADIWT), 2014 Fifth
International Conference on the (pp. 232-238). IEEE.
Kieu, L.M., Bhaskar, A. and Chung, E., 2015. A modified
Density-Based Scanning Algorithm with Noise for
spatial travel pattern analysis from Smart Card AFC
data. Transportation Research Part C: Emerging
Technologies, 58, pp.193-207.
Kumar, K.M. and Reddy, A.R.M., 2016. A fast DBSCAN
clustering algorithm by accelerating neighbor searching
using Groups method. Pattern Recognition, 58, pp.39-
48.
Nasibov, E., Atilgan, C., Berberler, M.E. and Nasiboglu,
R., 2015. Fuzzy joint points based clustering
algorithms for large data sets. Fuzzy Sets and
Systems, 270, pp.111-126.
Ozkok, F.O. and Celik, M., 2017. A New Approach to
Determine Eps Parameter of DBSCAN
Algorithm. International Journal of Intelligent Systems
and Applications in Engineering, 5(4), pp.247-251.
Sajana, T., Rani, C.S. and Narayana, K.V., 2016. A
survey on clustering techniques for big data
mining. Indian Journal of Science and
Technology, 9(3).
Schubert, E., Sander, J., Ester, M., Kriegel, H.P. and Xu,
X., 2017. DBSCAN Revisited, Revisited: Why and
How You Should (Still) Use DBSCAN. ACM
Transactions on Database Systems (TODS), 42(3),
p.19.
Shirkhorshidi, A.S., Aghabozorgi, S., Wah, T.Y. and
Herawan, T., 2014, June. Big data clustering: a review.
In International Conference on Computational Science
and Its Applications (pp. 707-720). Springer, Cham.
Yuan, G., Sun, P., Zhao, J., Li, D. and Wang, C., 2017. A
review of moving object trajectory clustering
algorithms. Artificial Intelligence Review, 47(1),
pp.123-144.
Zhao, Q., Shi, Y., Liu, Q. and Fränti, P., 2015. A grid-
growing clustering algorithm for geo-spatial
data. Pattern Recognition Letters, 53, pp.77-84.
1 out of 11
Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Unlock your academic potential
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.