Statistical Analysis of Company Revenue and Employee Salaries
VerifiedAdded on 2019/11/20
|10
|1716
|326
Homework Assignment
AI Summary
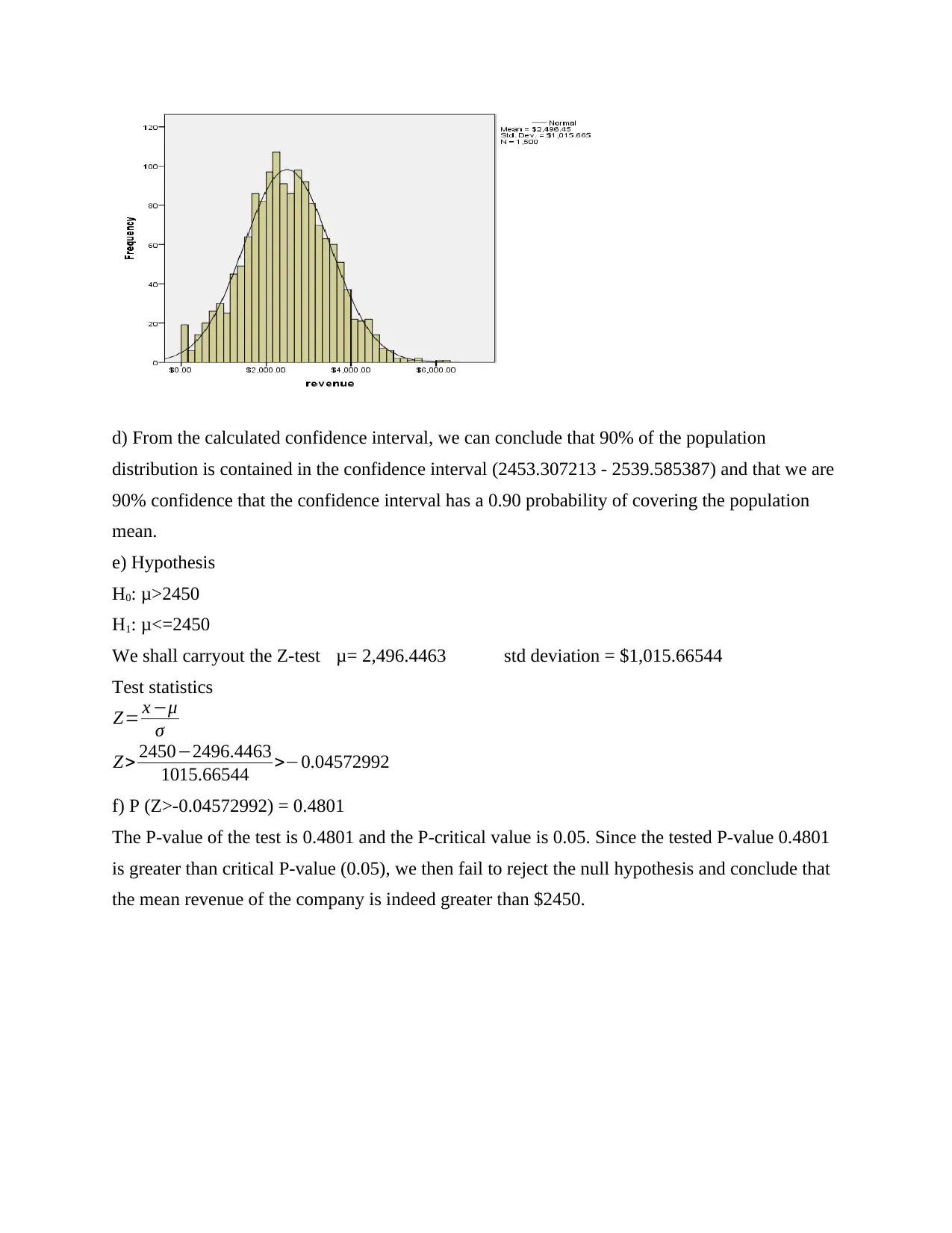
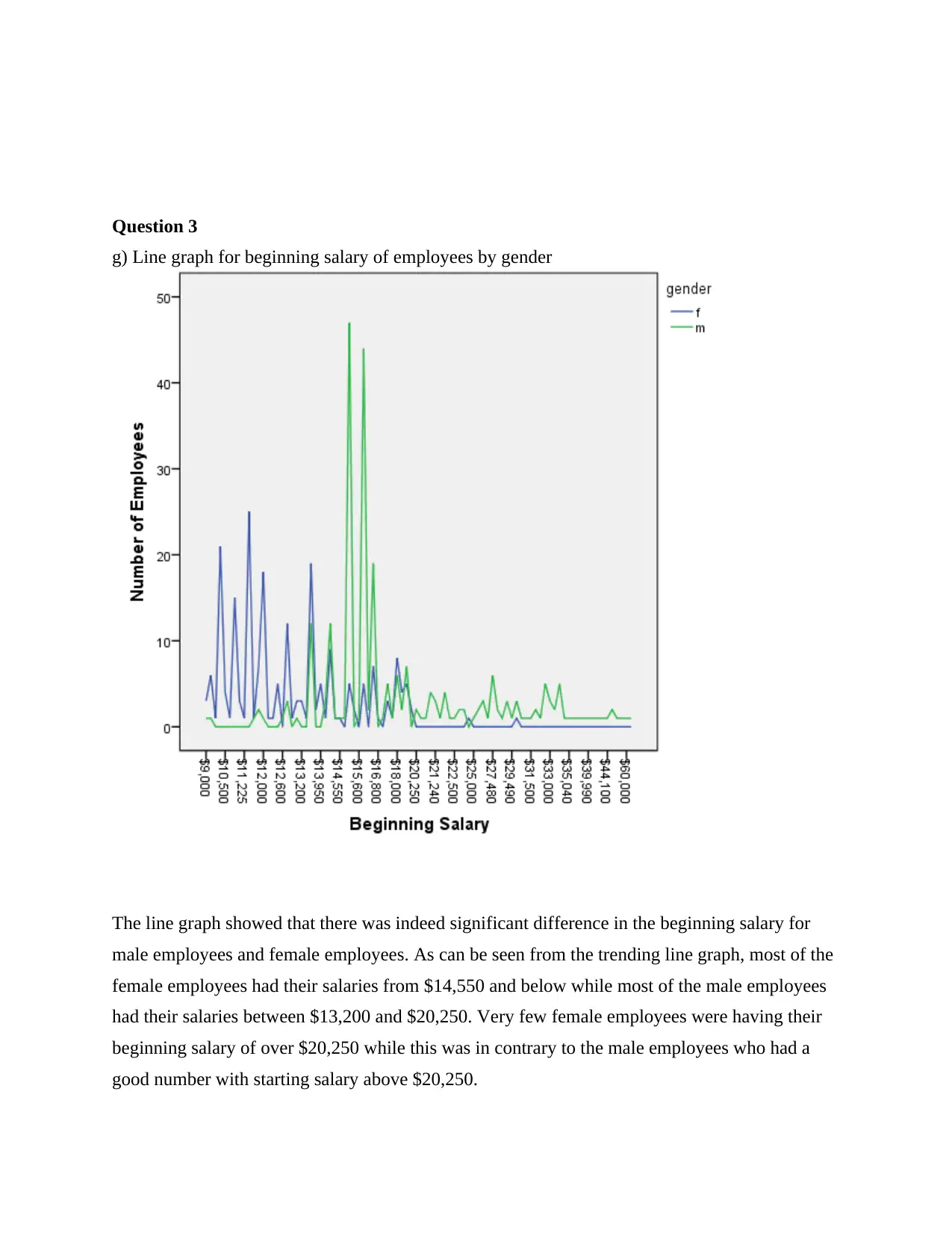
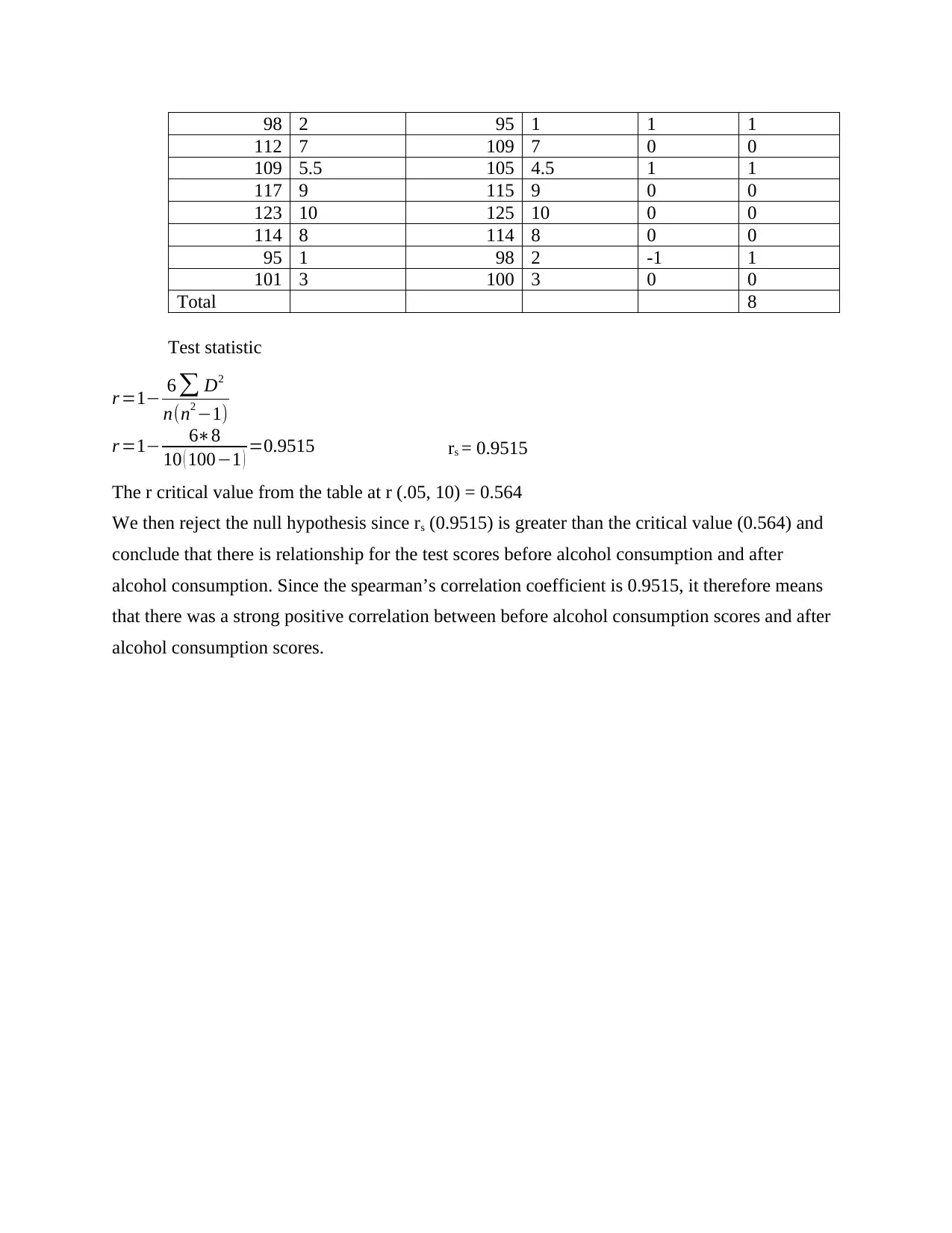
This statistics assignment presents a comprehensive analysis of various statistical concepts. Question 1 focuses on descriptive statistics, constructing confidence intervals, and hypothesis testing related to company revenue. Question 2 explores hypothesis testing using proportions, analyzing the age of arsonists. Question 3 delves into comparing salaries, utilizing line graphs and t-tests to determine salary differences between genders, and calculating confidence intervals. Question 4 covers probability calculations using z-scores and the central limit theorem, including sampling distributions. Question 5 differentiates between parameters and statistics, explaining the law of large numbers and the central limit theorem. Finally, Question 6 investigates the impact of alcohol consumption on test scores using both a paired t-test and a non-parametric test (Spearman’s Rank Correlation), providing interpretations and conclusions for each analysis. The assignment demonstrates practical applications of statistical methods and their interpretations.







1 out of 10
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.