Econometrics Assignment: Regression Analysis and Statistical Inference
VerifiedAdded on 2021/12/08
|28
|4390
|481
Homework Assignment
AI Summary
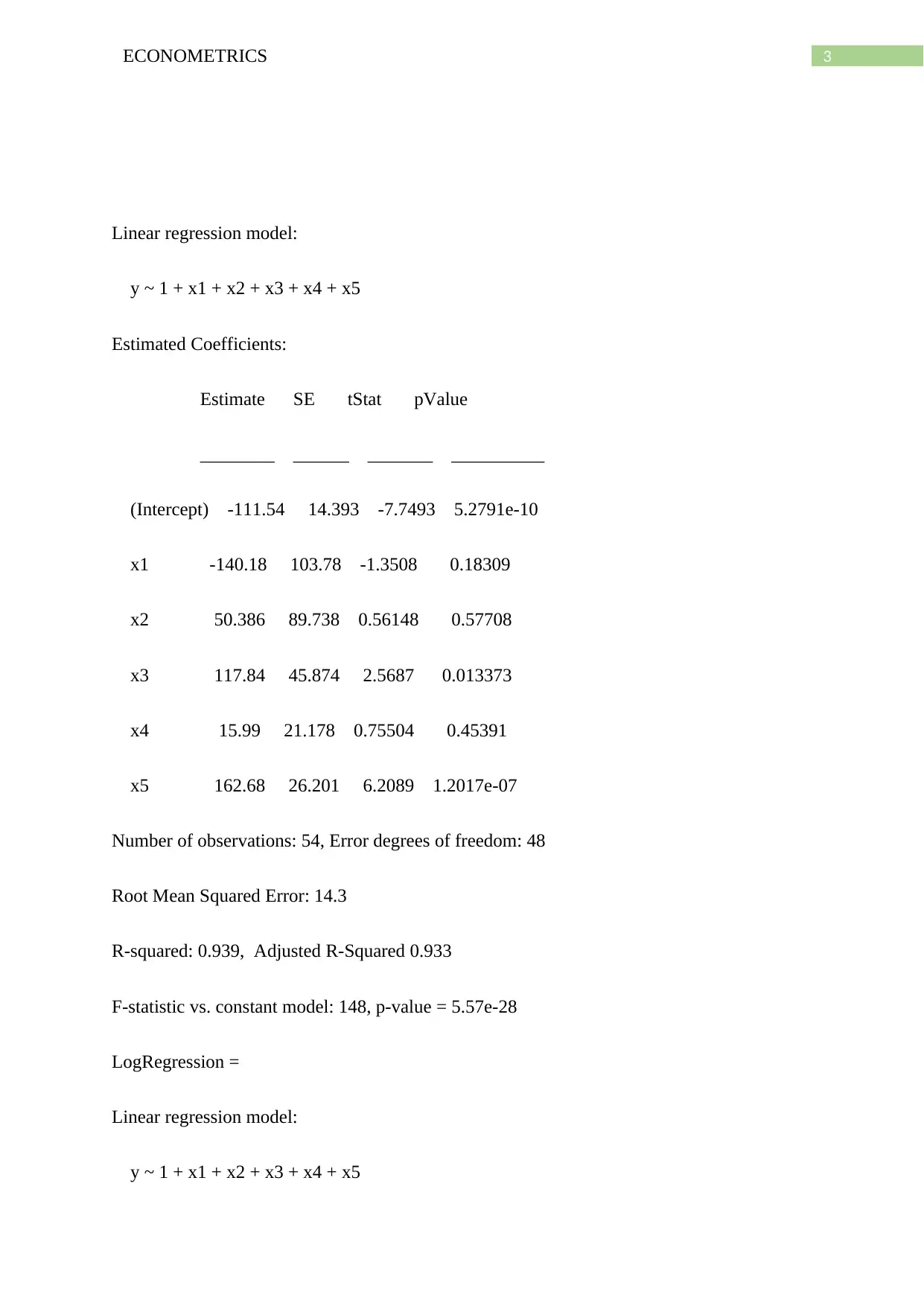
This econometrics assignment presents three distinct problems. The first involves predicting bear weight using linear and logarithmic regression models, analyzing variables like head length, neck circumference, and chest circumference, and applying backward elimination to refine the models. The second problem focuses on wage analysis, exploring the relationship between hourly wage and variables such as experience, education, and looks, using linear regression and coefficient tests. The third part generates independent and identically distributed random variables, calculates their correlation, and visualizes the data through a scatter plot, demonstrating the concept of independence and probability. The assignment utilizes MATLAB for data manipulation, model fitting, and statistical analysis, providing detailed outputs and interpretations of the results.











1 out of 28
Related Documents





Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.