Econometrics: Comprehensive Analysis of Linear Regression Techniques
VerifiedAdded on 2022/02/17
|22
|4508
|19
Report
AI Summary
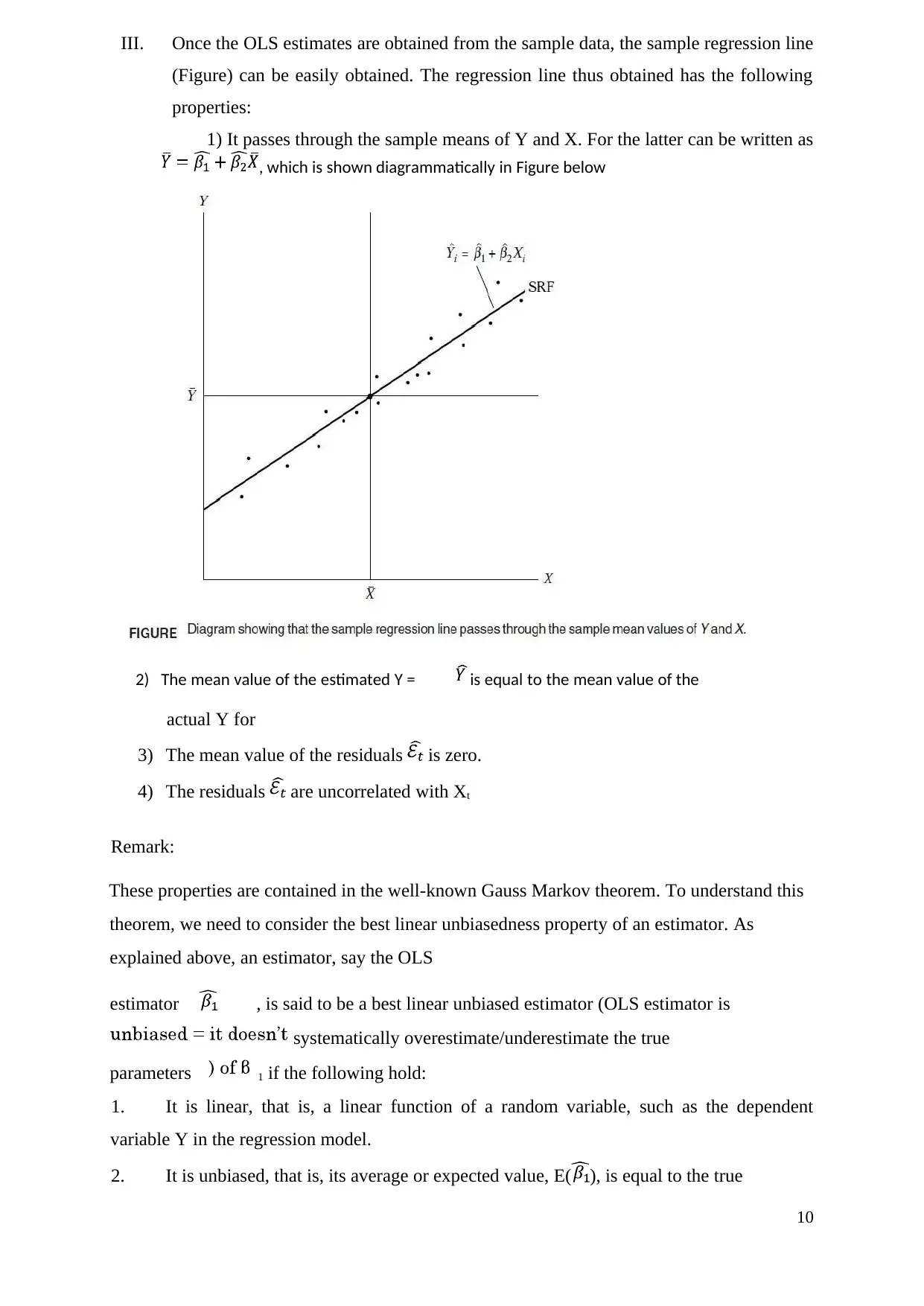
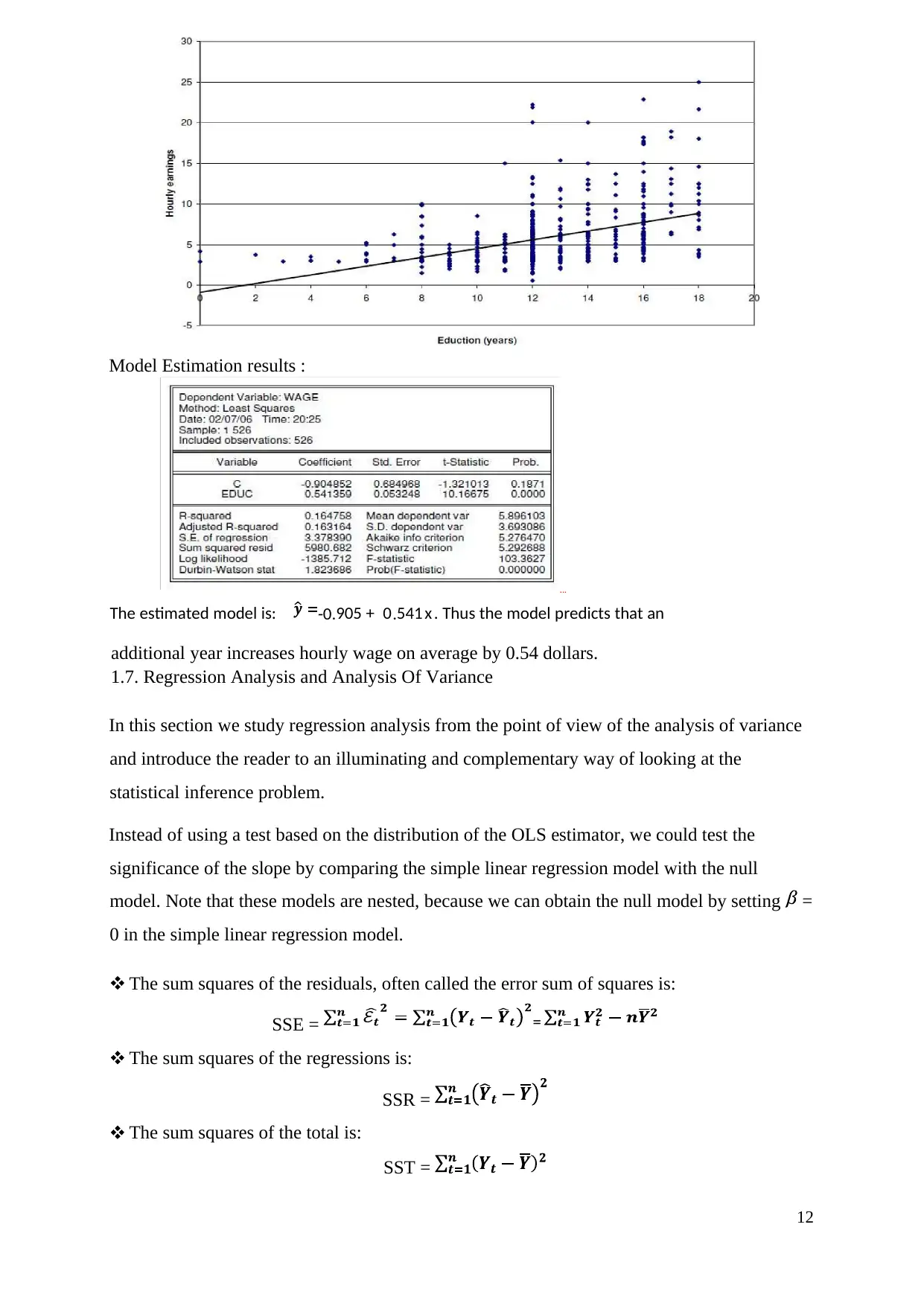
This report provides a comprehensive overview of linear regression within the field of econometrics. It begins by defining regression and its purpose, then explores various data types including cross-sectional, time series, and panel data. Key statistical concepts such as arithmetic mean, variance, covariance, and the coefficient of linear correlation are introduced. The core of the report focuses on simple linear regression, detailing its purposes, the model, and the estimation of parameters using Ordinary Least Squares (OLS). The report explains descriptive analysis and the OLS method, along with the properties of least-square estimators. Furthermore, it connects regression analysis with the analysis of variance and discusses the coefficient of determination, R-squared, and adjusted R-squared. Finally, the report touches upon confidence intervals and significance tests for regression parameters, offering a thorough introduction to linear regression techniques and applications in econometrics.






1 out of 22
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.