Enterprise BI Project: Health News Analysis using WEKA
VerifiedAdded on 2023/06/05
|69
|5378
|174
Project
AI Summary
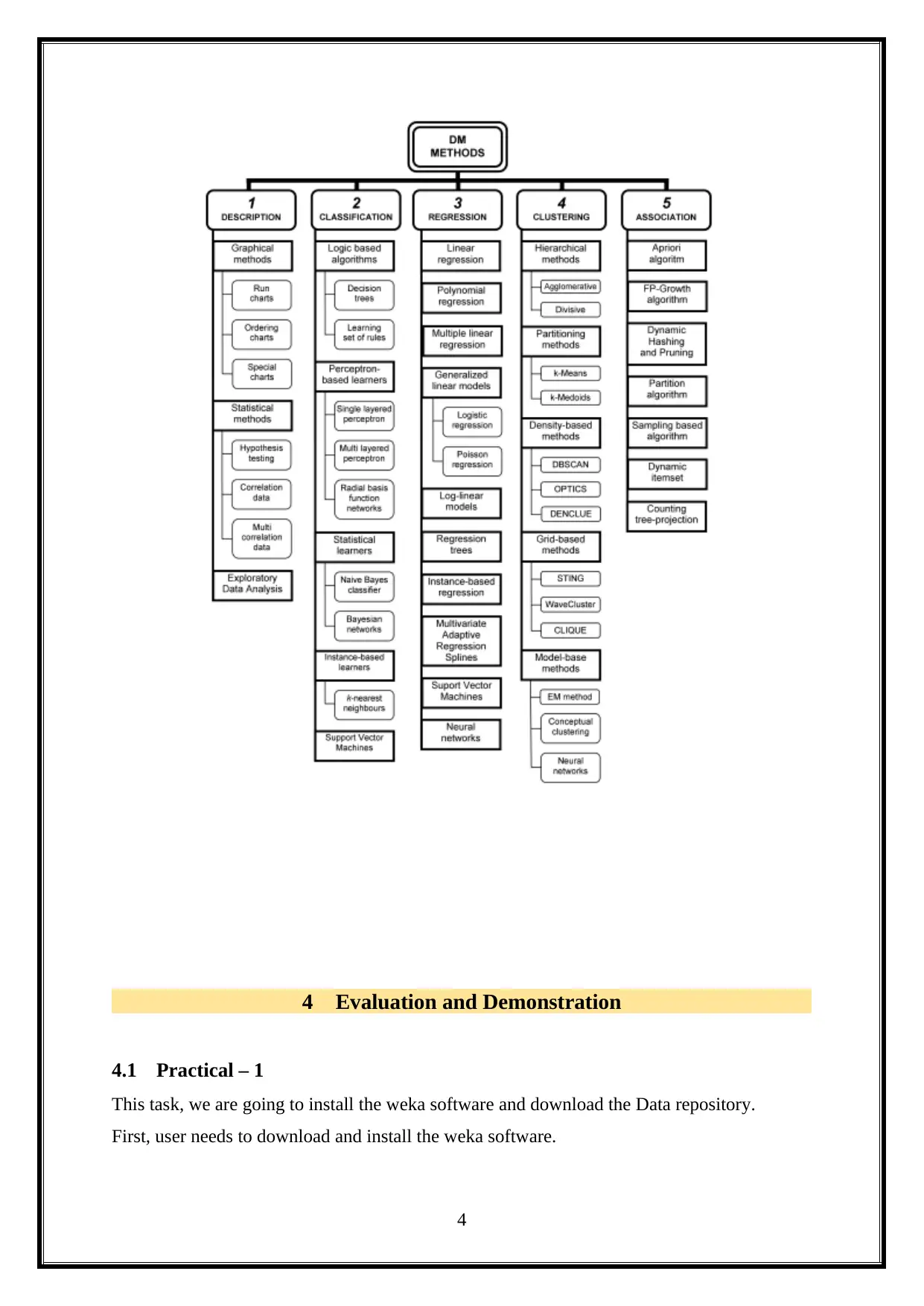
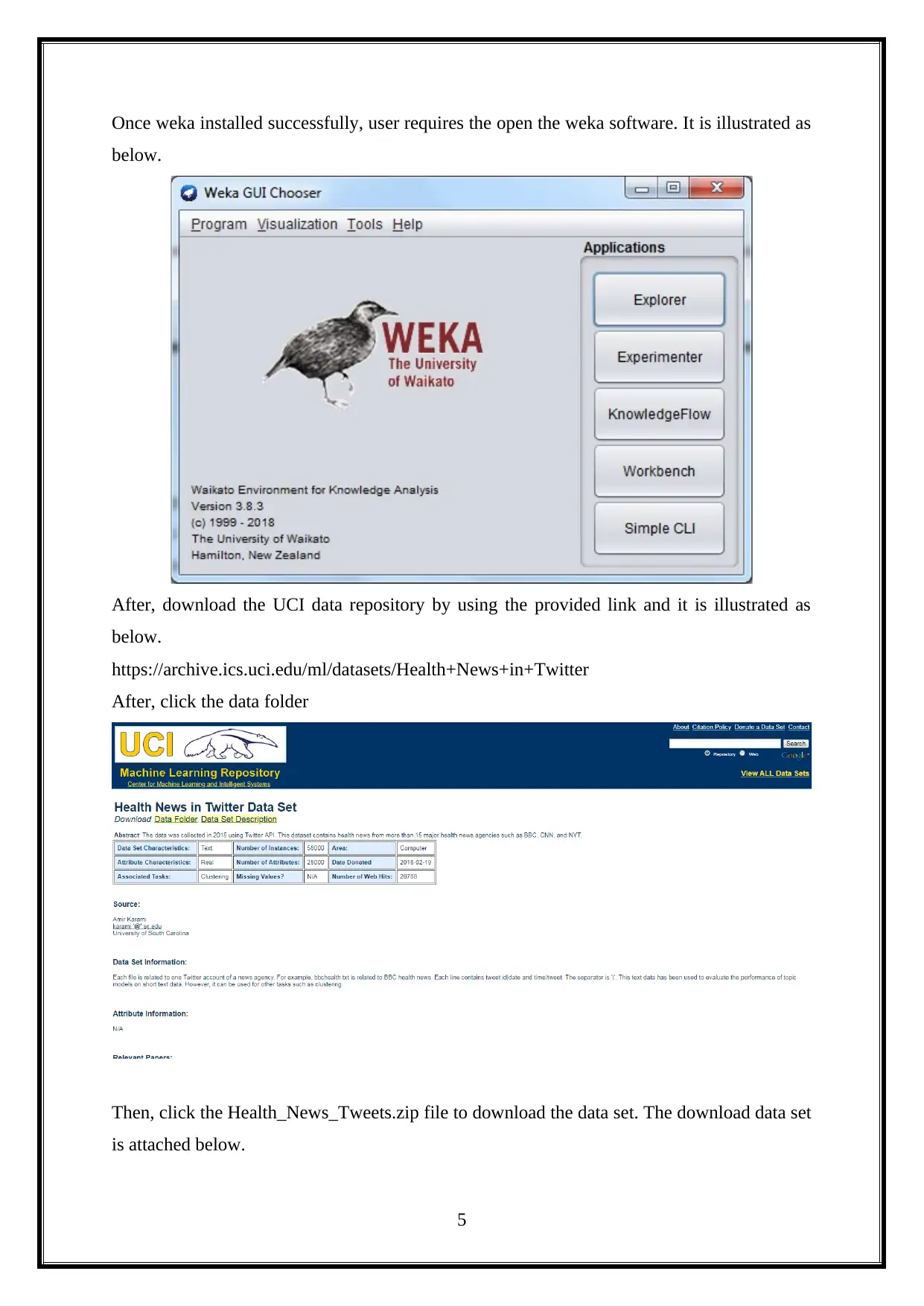
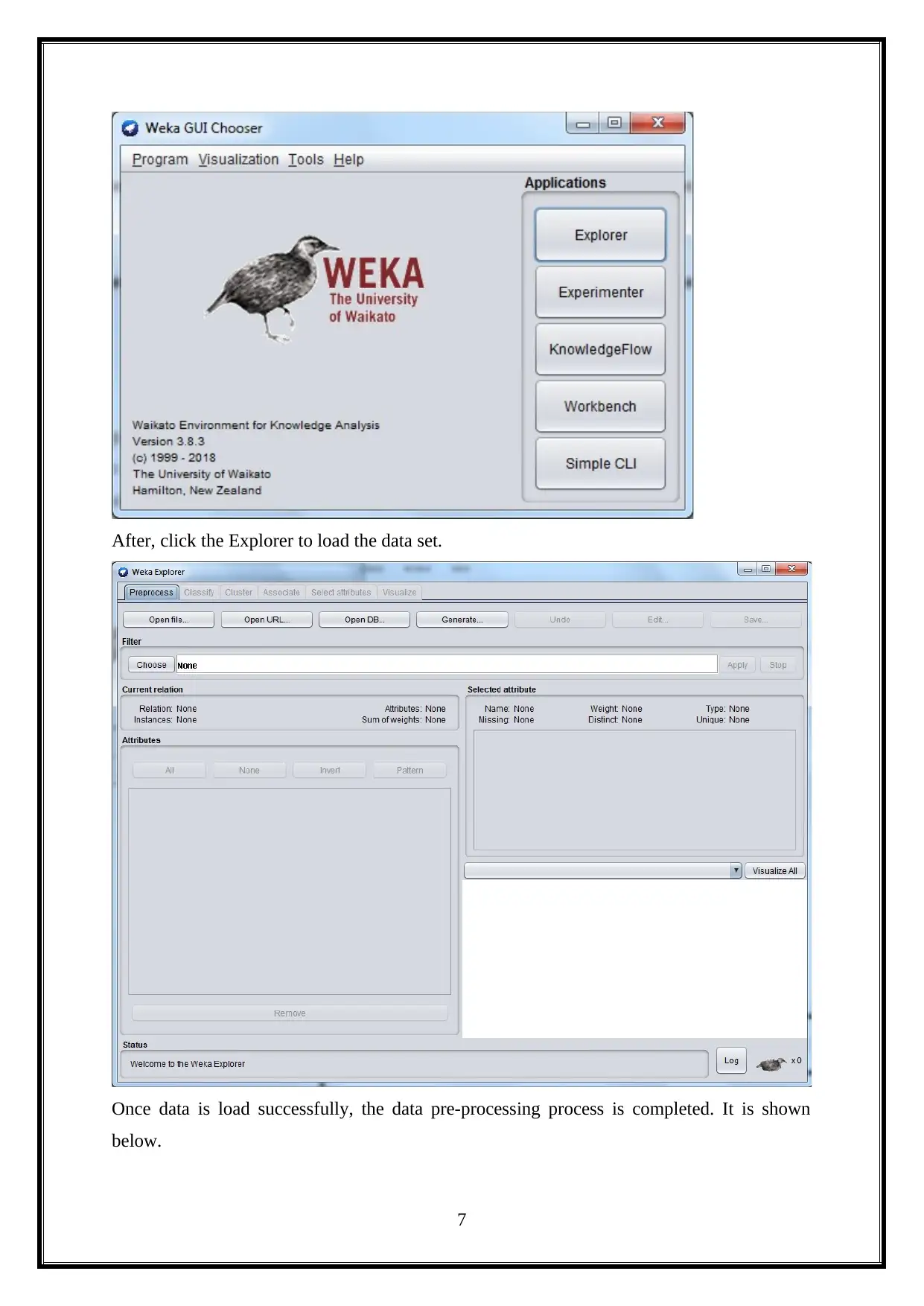
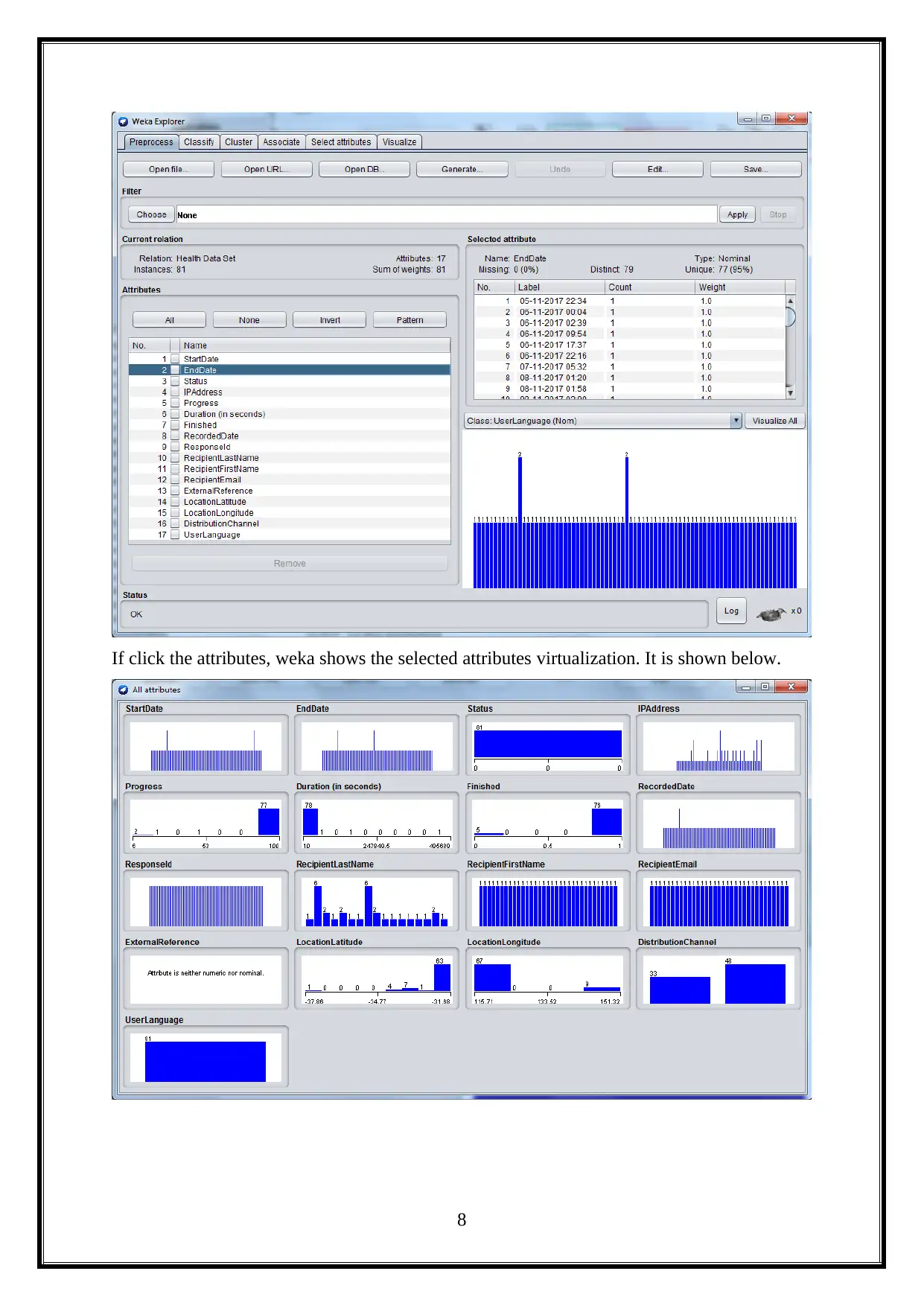
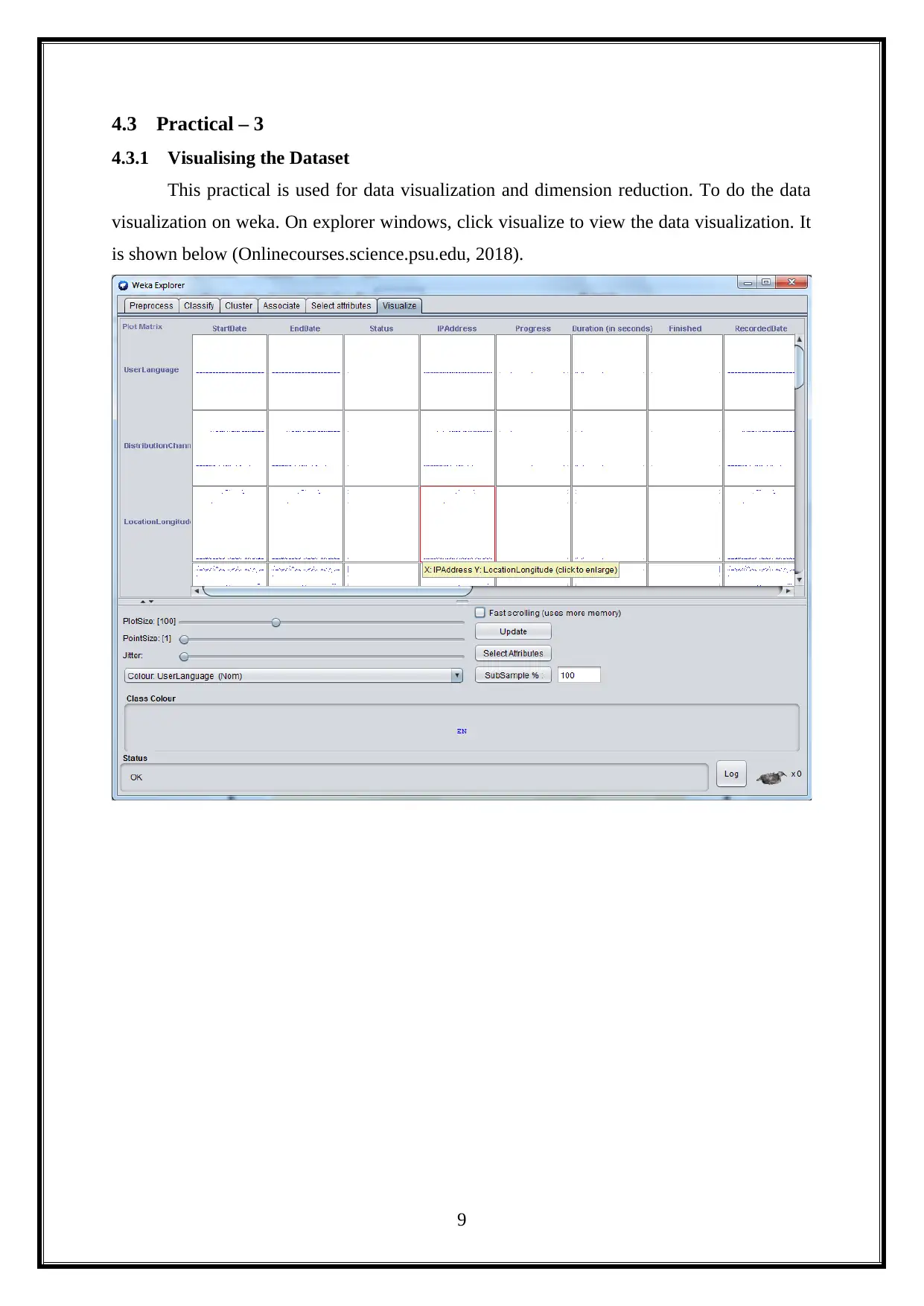
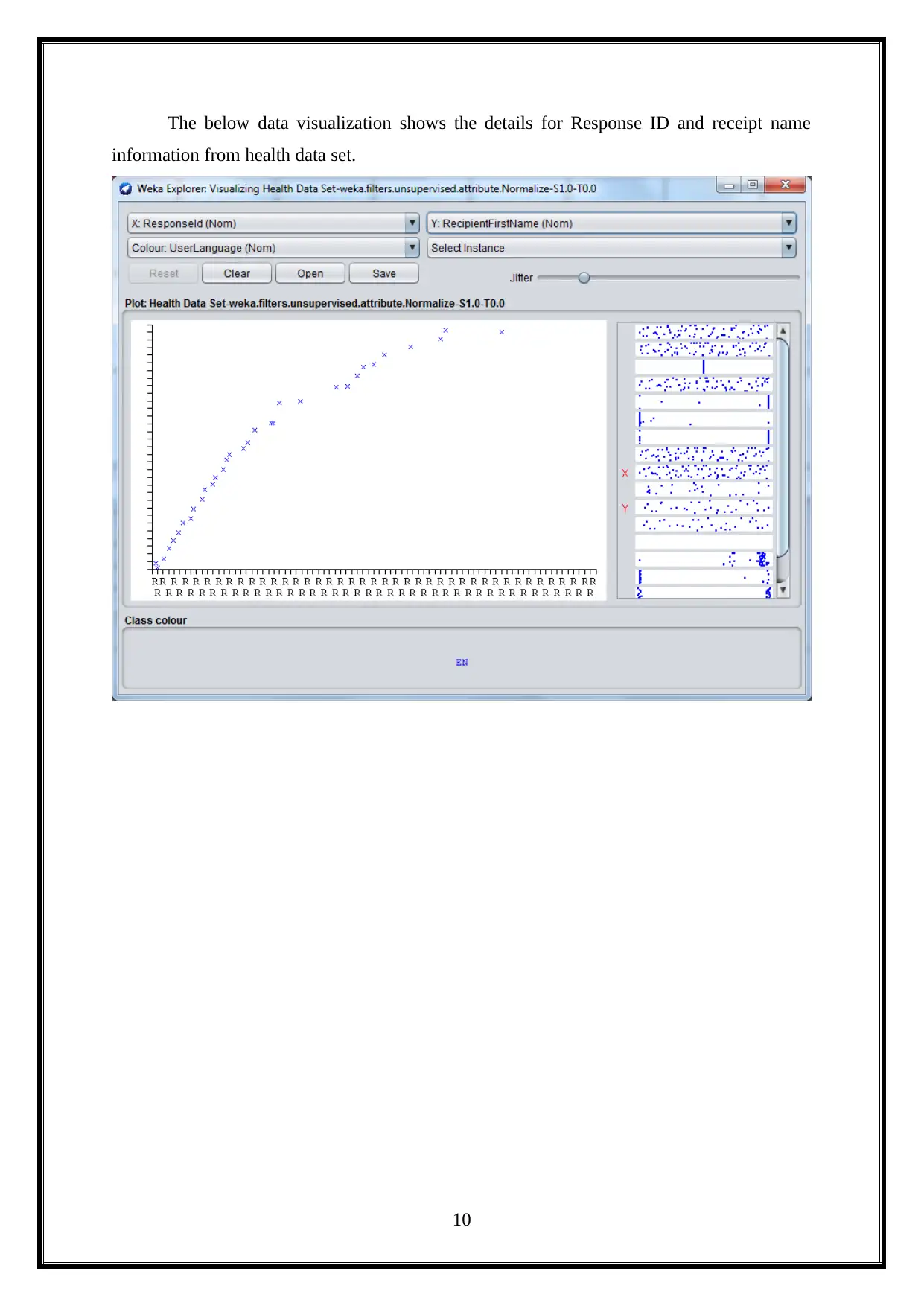
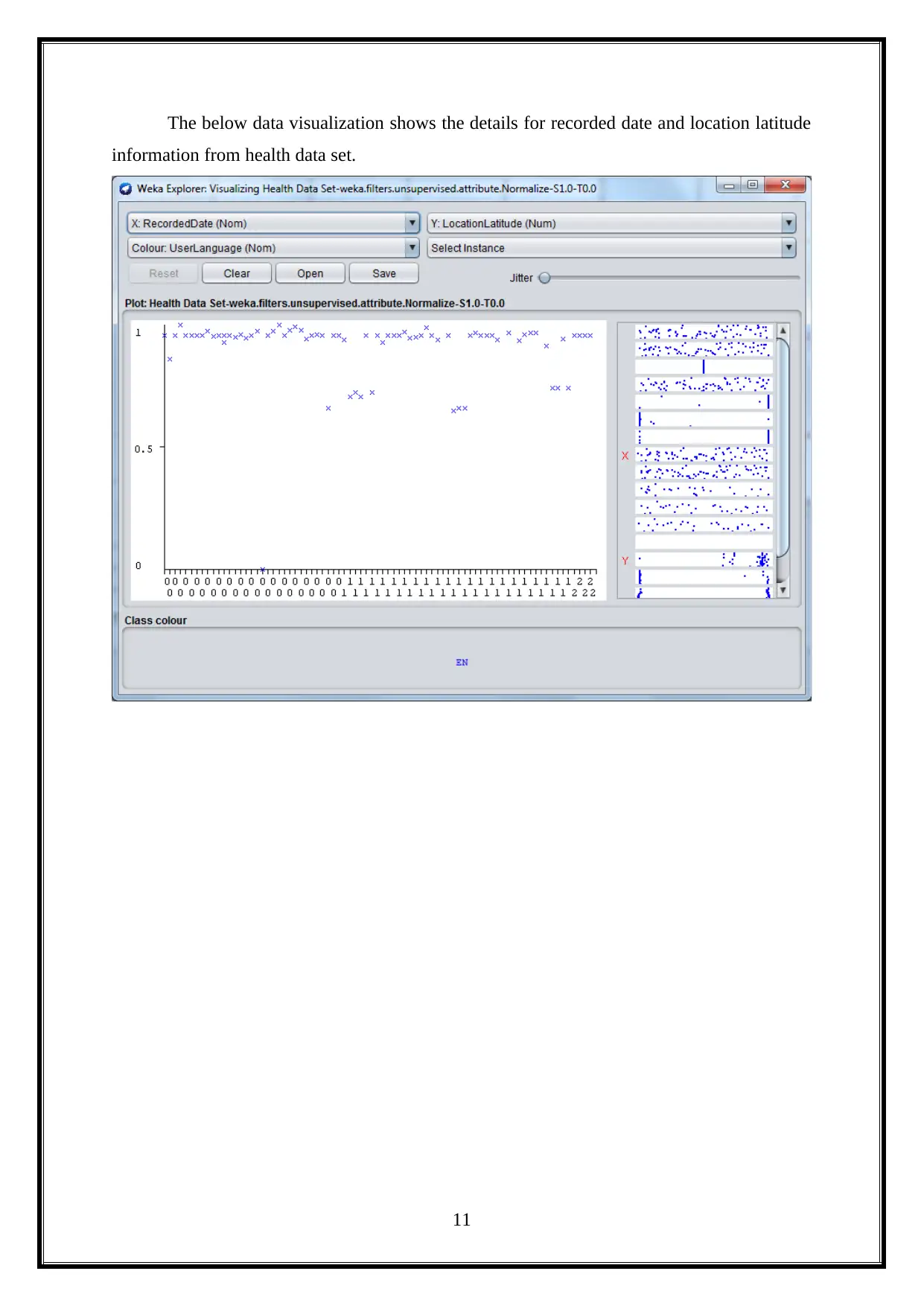
This project provides an opportunity to utilize data mining and machine learning methods for knowledge discovery in a dataset, exploring applications for business intelligence. It analyzes a health news dataset using WEKA, dividing the project into ten practical sections. The first practical involves installing WEKA and downloading a data repository. The second focuses on data pre-processing. The third covers data visualization and dimension reduction. The fourth implements clustering algorithms like K-Means, both manually and using WEKA. The fifth performs supervised mining with classification algorithms. The sixth evaluates performance using WEKA Experimenter and Knowledge Flow. The seventh predicts time series using WEKA's package manager. The eighth focuses on text mining, and the final practical explores image analytics in WEKA. Each practical is analyzed and demonstrated in detail.





1 out of 69
Related Documents




Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.