Epidemiology Assignment: Depression Treatment Data Analysis, 2018
VerifiedAdded on 2023/06/03
|7
|2457
|122
Homework Assignment
AI Summary
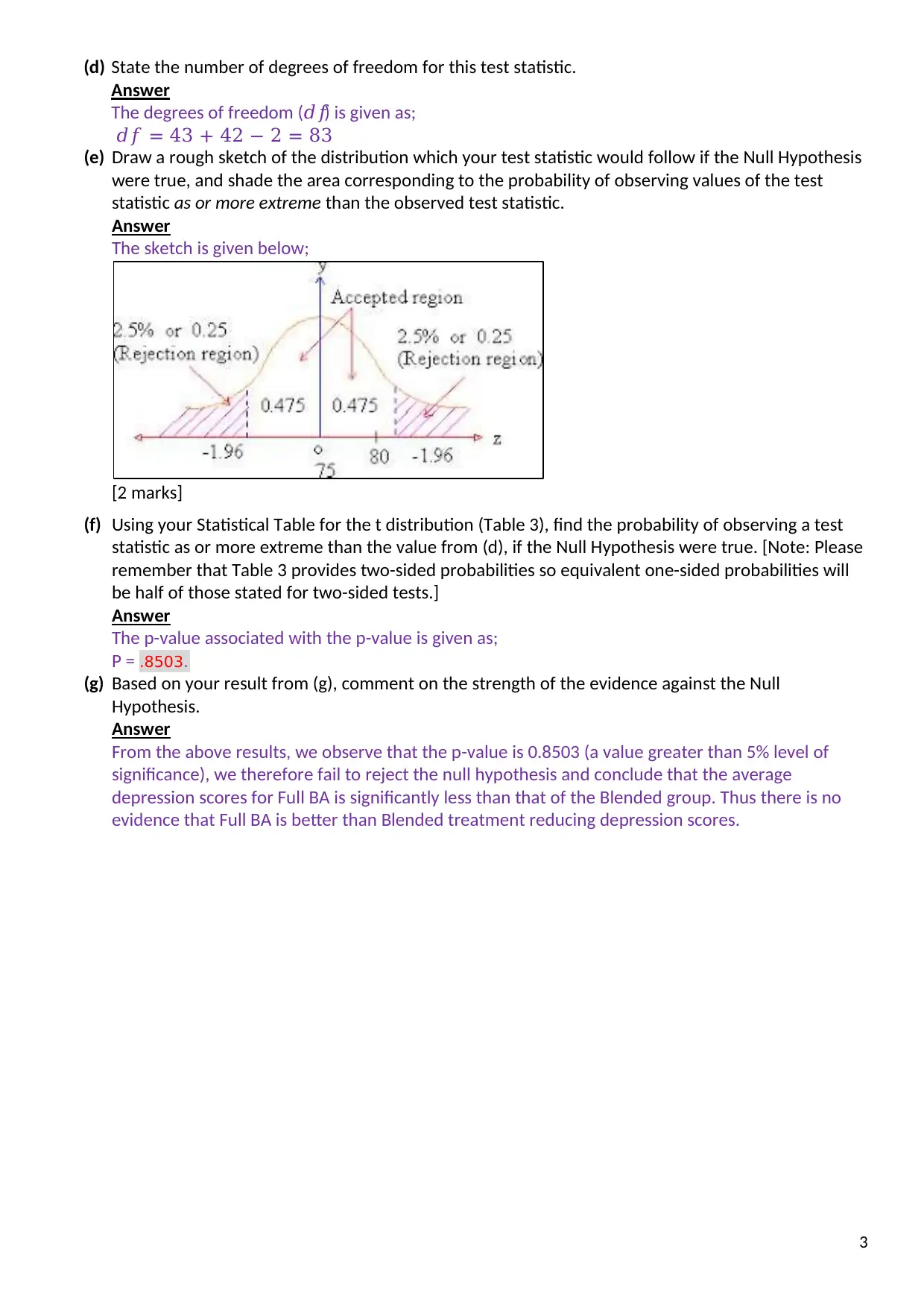
This assignment solution delves into the epidemiological analysis of depression treatment data from a randomized controlled trial comparing blended and full behavioral activation treatments. It covers hypothesis testing, including null and alternative hypotheses, calculation of test statistics (t-test and chi-square), degrees of freedom, and p-values. The analysis assesses the effectiveness of different treatment approaches, drop-out rates, and potential threats to the generalizability of the study results. Stata outputs are included for verification. The assignment examines whether there is a significant difference in depression scores between treatment groups, assesses the association between treatment allocation and study dropouts, and evaluates potential biases in the study due to participant attrition. This document is available on Desklib, a platform offering a range of study resources for students.






1 out of 7
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2025 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.