Excel Computing Task: Statistical Data Analysis and Interpretation
VerifiedAdded on 2023/06/14
|13
|2064
|398
Practical Assignment
AI Summary
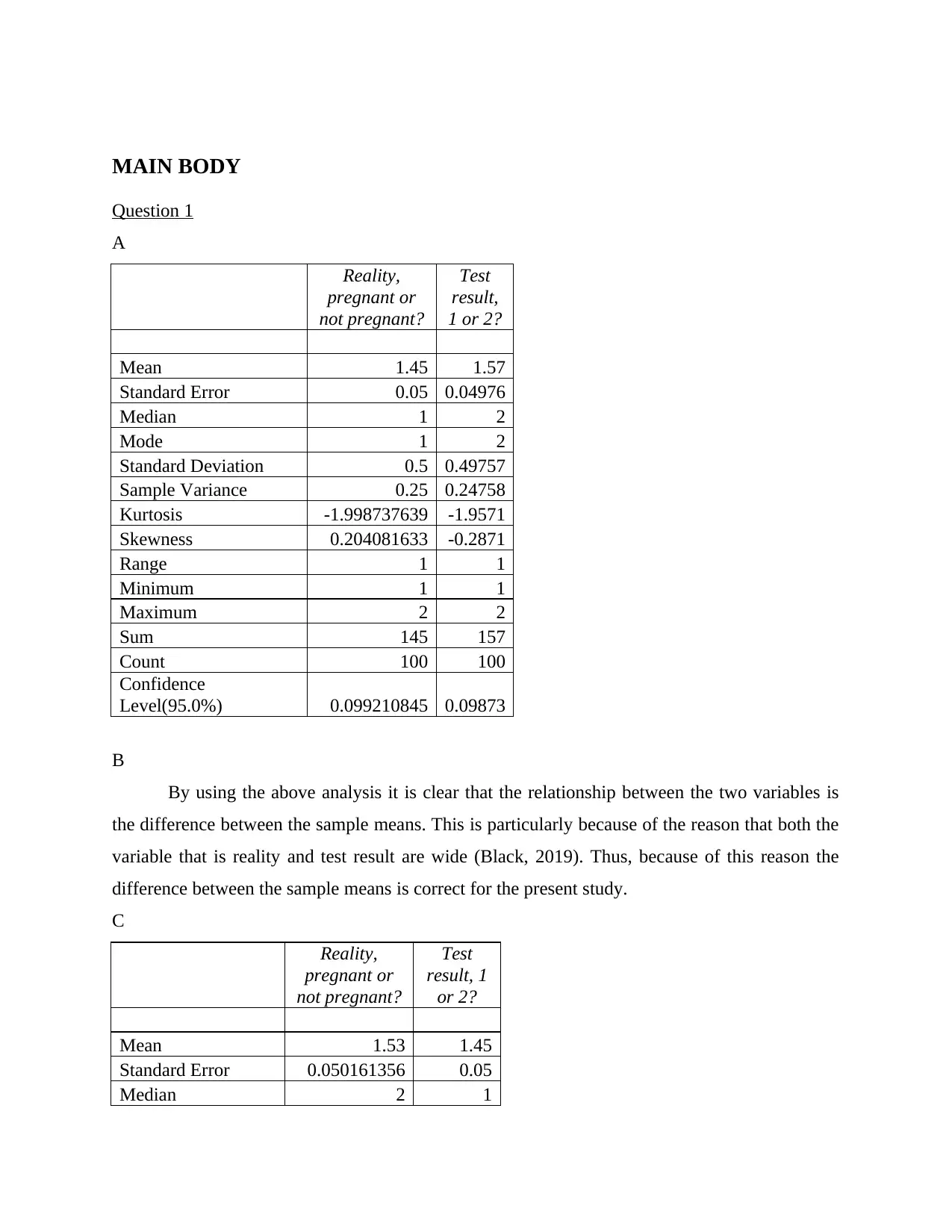
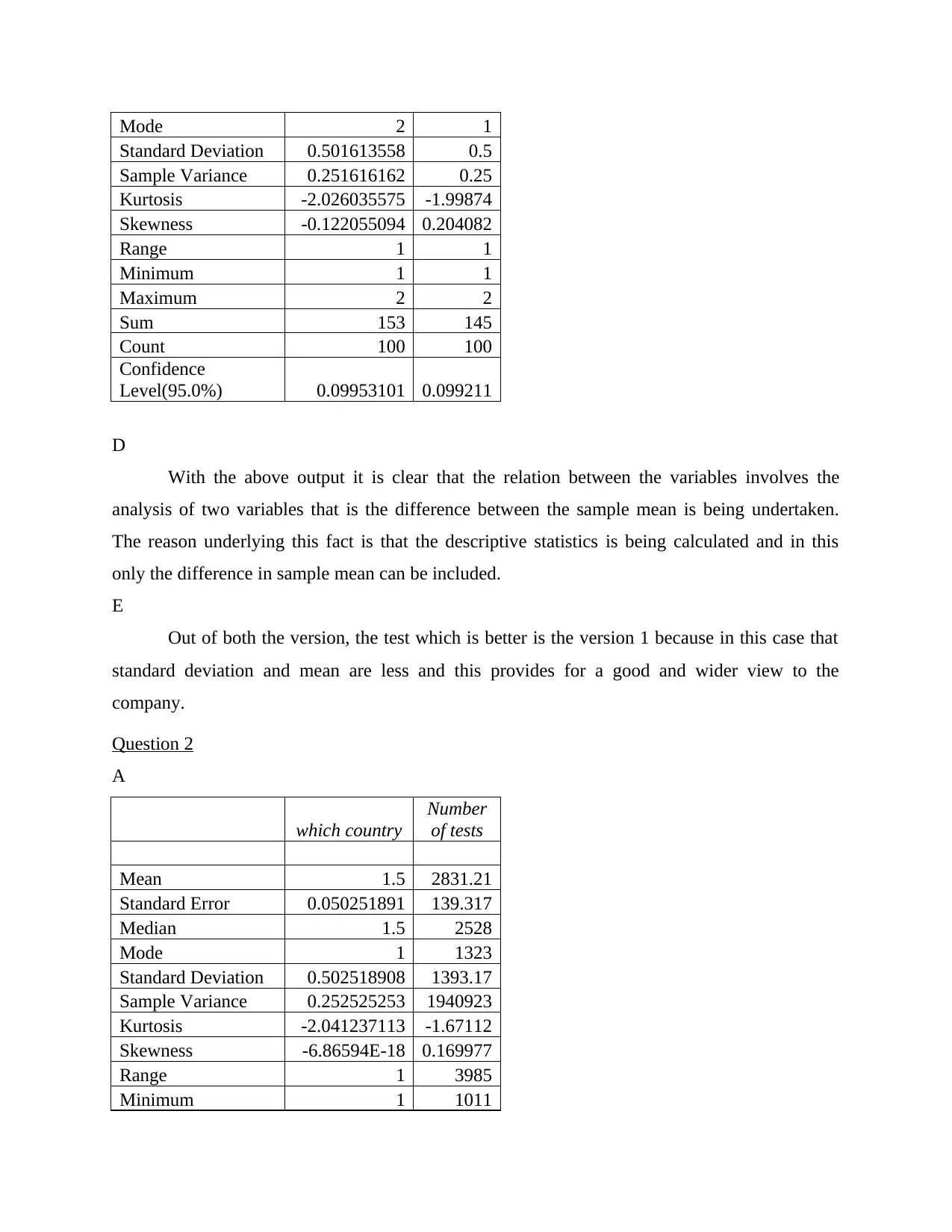
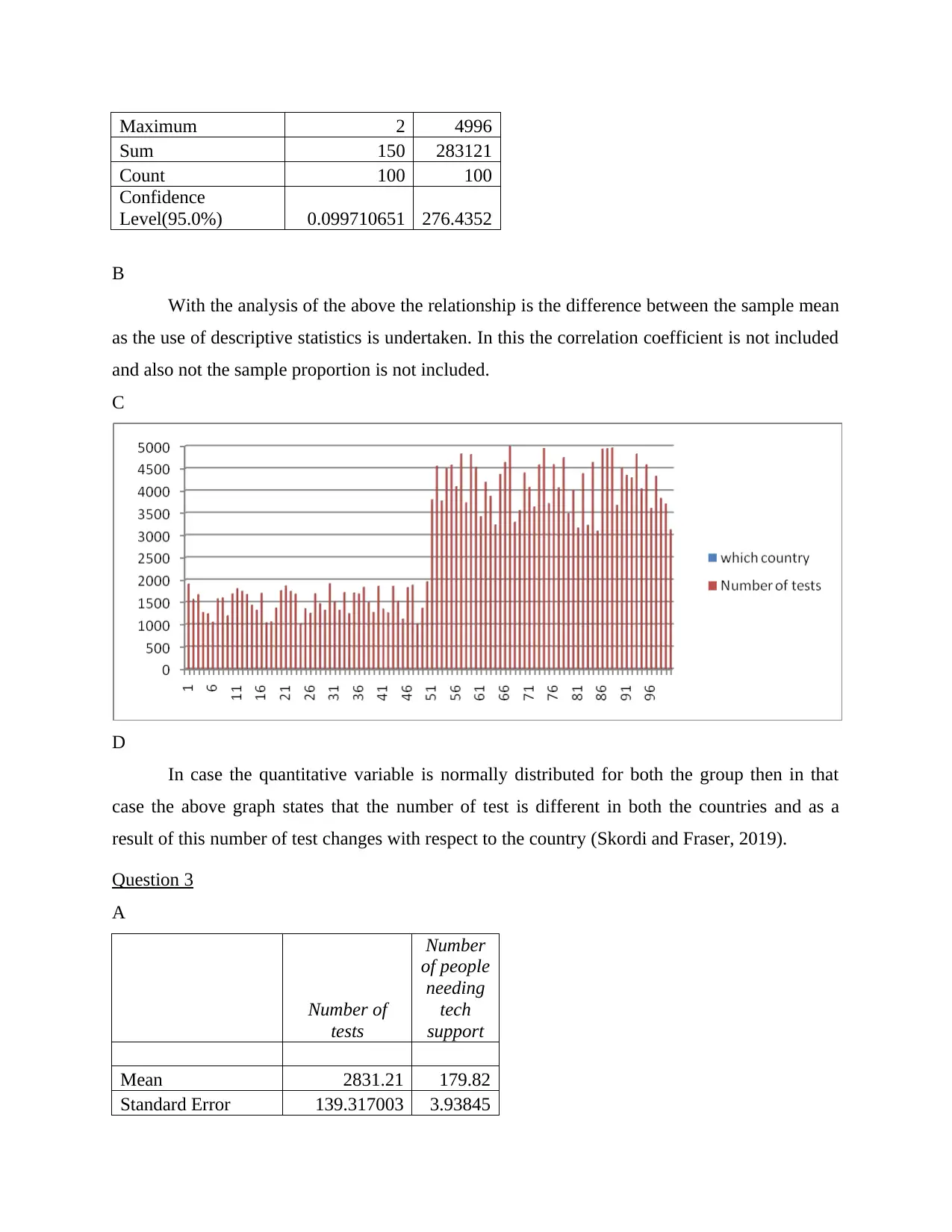
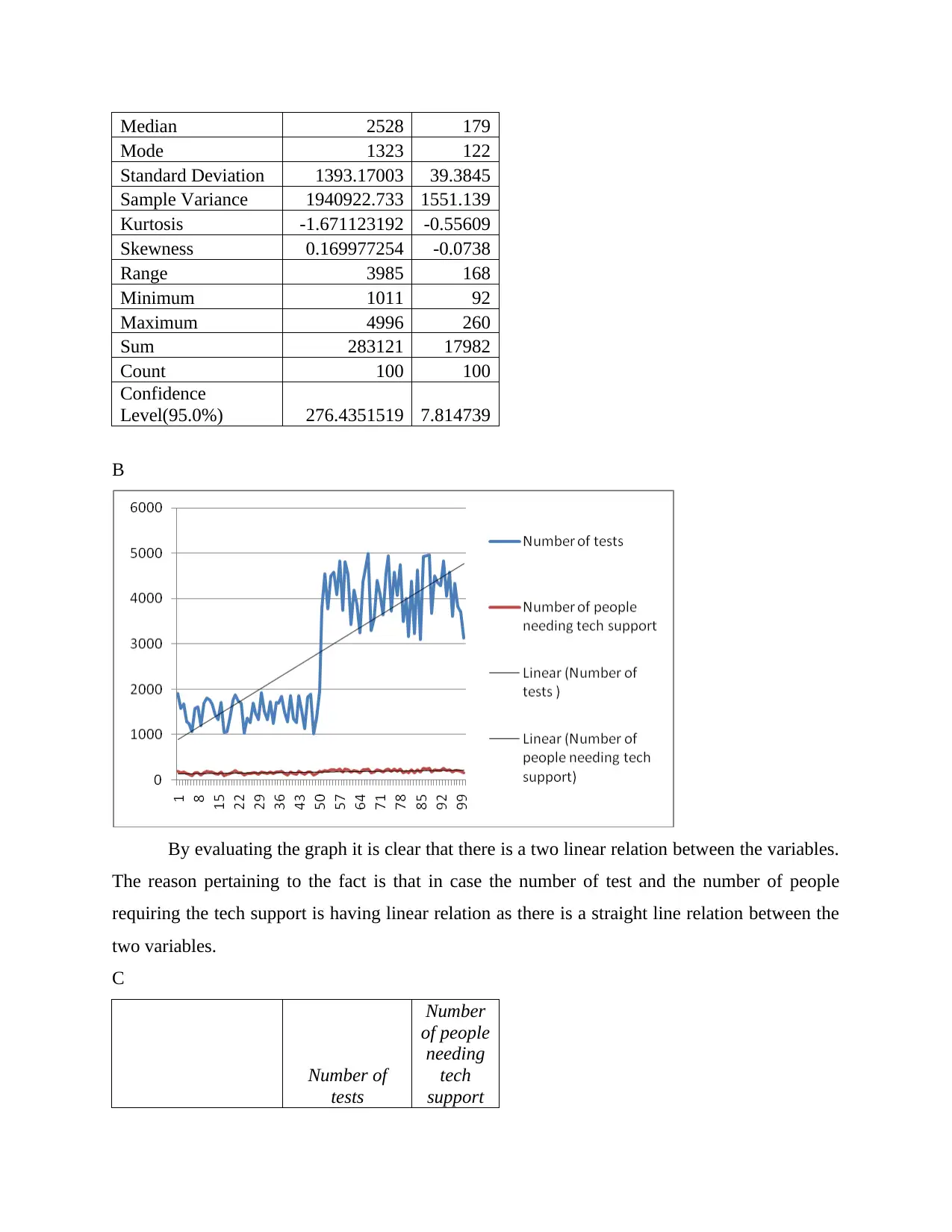
This document presents a solved Excel computing task involving statistical analysis and interpretation. The task covers a range of statistical concepts, including descriptive statistics, regression analysis, and confidence intervals. It involves analyzing data related to pregnancy tests, country-wise test numbers, and tech support needs. The solution provides detailed calculations, interpretations, and conclusions based on the Excel outputs. Regression analysis is used to explore relationships between variables, and confidence intervals are calculated to assess the reliability of estimates. The document also includes a reflection on a video tutorial about analyzing satisfaction survey data in Excel, highlighting the use of regression lines and related statistical measures. This assignment showcases the application of Excel in statistical analysis and provides insights into interpreting statistical results.




1 out of 13
Related Documents






Your All-in-One AI-Powered Toolkit for Academic Success.
+13062052269
info@desklib.com
Available 24*7 on WhatsApp / Email
![[object Object]](/_next/static/media/star-bottom.7253800d.svg)
Copyright © 2020–2026 A2Z Services. All Rights Reserved. Developed and managed by ZUCOL.